この Topic では、EMR on ECS Spark 環境で Iceberg REST を使用して Data Lake Formation (DLF) カタログにアクセスする方法について説明します。
前提条件
バージョン要件:EMR V5.12.0 以降を実行する EMR クラスターが作成されていること。Spark3 コンポーネントが選択されており、Spark3 が JDK 11 を使用していること。
リージョン要件:EMR クラスターと DLF が同じリージョンにあること。EMR クラスターの VPC が DLF ホワイトリストに追加されていること。
権限要件:Resource Access Management (RAM) ユーザーの場合、データ操作を実行する前に必要な権限を付与してください。詳細については、「データ権限付与管理」をご参照ください。
依存パッケージのダウンロード
ロールへの DLF 権限の付与
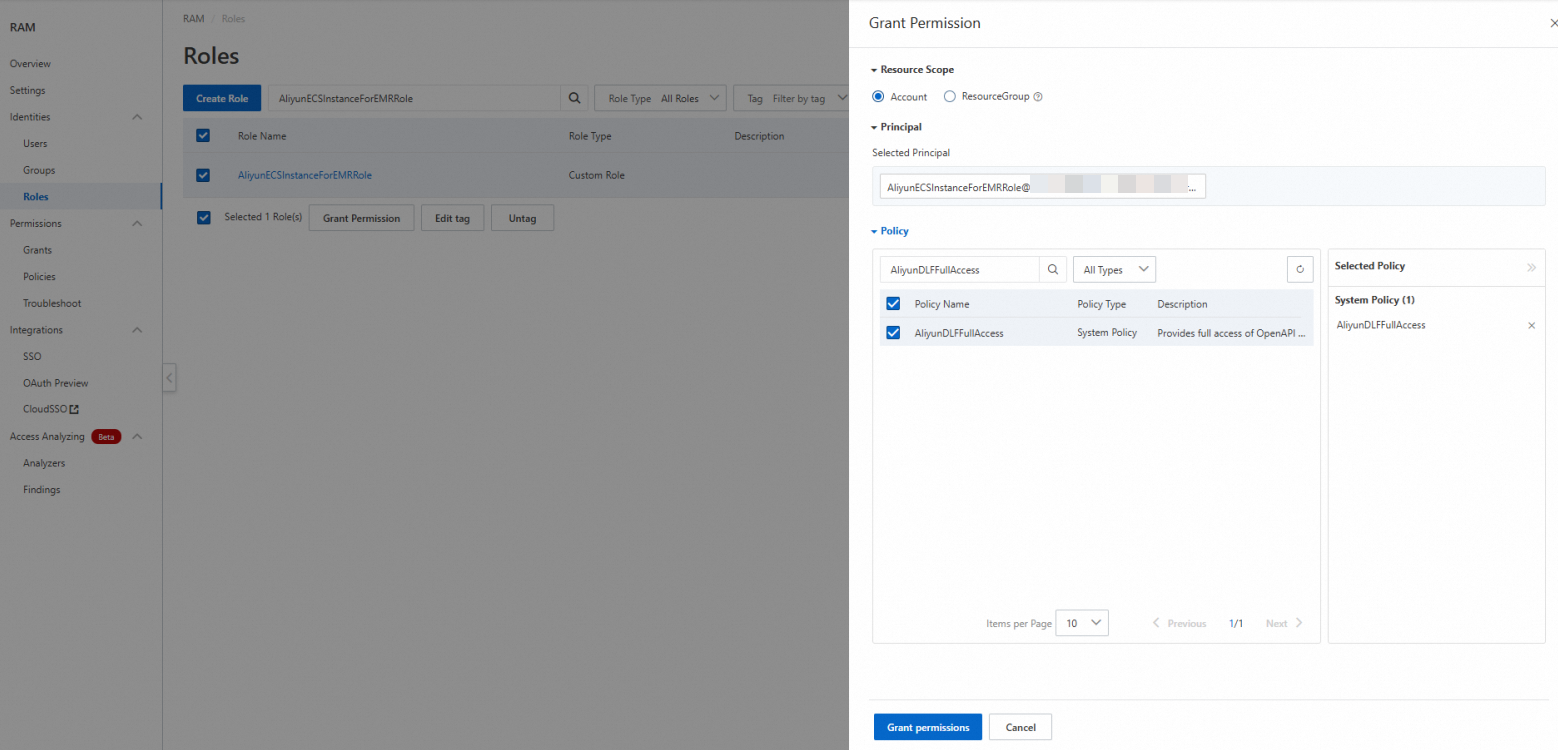
AliyunECSInstanceForEMRRole ロールに権限を付与します。(EMR プロダクトの統合が完了した後は、このステップをスキップできます。)
RAM コンソールに Alibaba Cloud アカウントまたは RAM 管理者としてログインします。
をクリックし、AliyunECSInstanceForEMRRole ロールを見つけます。
[操作] 列で、[権限の追加] をクリックします。
[アクセスポリシー] セクションで、AliyunDLFFullAccess を検索して選択し、[権限の追加を確認] をクリックします。
DLF コンソールで AliyunECSInstanceForEMRRole ロールに権限を付与します。
DLF コンソールにログインします。
[カタログ] ページで、カタログ名をクリックして詳細を表示します。
[権限] タブをクリックし、[権限付与] をクリックします。
[権限付与] ページで、次のパラメーターを設定し、[OK] をクリックします。
[ユーザー/ロール]:[RAM ユーザー/RAM ロール] を選択します。
[認証オブジェクトの選択]:ドロップダウンリストから [AliyunECSInstanceForEMRRole] を選択します。
説明ドロップダウンリストに AliyunECSInstanceForEMRRole がない場合は、ユーザー管理ページに移動して [同期] をクリックしてください。
[プリセット権限タイプ]:[データ編集者] を選択します。
カタログへの接続
依存関係の設定
ダウンロードした 4 つの依存パッケージを $SPARK_HOME/jars ディレクトリに追加します。
セッションの開始
ターミナルで spark-sql コマンドを実行します。必要に応じてパラメーターを置き換えてください。
${regionID}:実際のリージョン (例:cn-hangzhou)。
${catalogName}:DLF で作成したカタログの名前。
spark-sql \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.iceberg_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.iceberg_catalog.catalog-impl=org.apache.iceberg.rest.RESTCatalog \
--conf spark.sql.catalog.iceberg_catalog.uri=http://${regionID}-vpc.dlf.aliyuncs.com/iceberg \
--conf spark.sql.catalog.iceberg_catalog.warehouse=${catalogName} \
--conf spark.sql.catalog.iceberg_catalog.io-impl=org.apache.iceberg.rest.DlfFileIO \
--conf spark.sql.catalog.iceberg_catalog.rest.auth.type=sigv4 \
--conf spark.sql.catalog.iceberg_catalog.rest.auth.sigv4.delegate-auth-type=none \
--conf spark.sql.catalog.iceberg_catalog.rest.signing-region=${regionID} \
--conf spark.sql.catalog.iceberg_catalog.client.credentials-provider=org.apache.iceberg.rest.credentials.DlfEcsTokenCredentialsProvider \
--conf spark.sql.catalog.iceberg_catalog.rest.signing-name=DlfNext \
--master localデータの読み書き
Iceberg テーブルには自動ストレージ解放メカニズムがありません。ストレージコストの急増を避けるため、「Spark プロシージャ」を参照して、期限切れのスナップショットとオーファンファイルを定期的にクリーンアップしてください。
データベースを指定しない場合、テーブルはカタログのデフォルトデータベースに作成されます。別のデータベースを作成して指定することもできます。
-- Iceberg カタログに切り替え
USE iceberg_catalog;
-- データベースを作成
CREATE DATABASE db;
-- 非パーティションテーブルを作成
CREATE TABLE iceberg_catalog.db.tbl (
id BIGINT NOT NULL COMMENT 'unique id',
data STRING
)
USING iceberg;
-- 非パーティションテーブルにデータを挿入
INSERT INTO iceberg_catalog.db.tbl VALUES
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie');
-- 非パーティションテーブルからすべてのデータをクエリ
SELECT * FROM iceberg_catalog.db.tbl;
-- 条件に基づいて非パーティションテーブルをクエリ
SELECT * FROM iceberg_catalog.db.tbl WHERE id = 2;
-- 非パーティションテーブルのデータを更新
UPDATE iceberg_catalog.db.tbl SET data = 'David' WHERE id = 3;
-- 再度クエリして更新を確認
SELECT * FROM iceberg_catalog.db.tbl WHERE id = 3;
-- 非パーティションテーブルからデータを削除
DELETE FROM iceberg_catalog.db.tbl WHERE id = 1;
-- 再度クエリして削除を確認
SELECT * FROM iceberg_catalog.db.tbl;
-- パーティションテーブルを作成
CREATE TABLE iceberg_catalog.db.part_tbl (
id BIGINT,
data STRING,
category STRING,
ts TIMESTAMP
)
USING iceberg
PARTITIONED BY (bucket(16, id), days(ts), category);
-- パーティションテーブルにデータを挿入
INSERT INTO iceberg_catalog.db.part_tbl VALUES
(100, 'Data1', 'A', to_timestamp('2025-01-01 12:00:00')),
(200, 'Data2', 'B', to_timestamp('2025-01-02 14:00:00')),
(300, 'Data3', 'A', to_timestamp('2025-01-01 15:00:00')),
(400, 'Data4', 'C', to_timestamp('2025-01-03 10:00:00'));
-- パーティションテーブルからすべてのデータをクエリ
SELECT * FROM iceberg_catalog.db.part_tbl;
-- bucket(16, id) = 0 のデータをクエリ
SELECT * FROM iceberg_catalog.db.part_tbl WHERE bucket(16, id) = 0;
-- days(ts) = '2025-01-01' のデータをクエリ
SELECT * FROM iceberg_catalog.db.part_tbl WHERE days(ts) = '2025-01-01';
-- 特定のカテゴリのデータをクエリ
SELECT * FROM iceberg_catalog.db.part_tbl WHERE category = 'A';
-- 複数の条件 (バケット + 日 + カテゴリ) を使用してクエリ
SELECT * FROM iceberg_catalog.db.part_tbl
WHERE bucket(16, id) = 0
AND days(ts) = '2025-01-01'
AND category = 'A';
-- カテゴリごとにデータエントリ数を集計してカウント
SELECT category, COUNT(*) AS count
FROM iceberg_catalog.db.part_tbl
GROUP BY category;
-- (任意) テストデータをクリーンアップ
TRUNCATE TABLE iceberg_catalog.db.tbl;
TRUNCATE TABLE iceberg_catalog.db.part_tbl;
-- (注意) データベースを削除
DROP DATABASE iceberg_catalog.db;