Data Integration を使用すると、MySQL ソースから Elasticsearch 宛てに、データベース全体をリアルタイムで同期できます。本トピックでは、MySQL をソース、Elasticsearch をデスティネーションとして、完全同期と増分同期(変更データキャプチャ:CDC)を組み合わせたリアルタイム同期タスクの設定方法を説明します。
前提条件
データソース
リソースグループ: サーバーレスリソースグループ を購入済みです。
ネットワーク接続性: リソースグループとデータソース間のネットワーク接続が確立済みです。詳細については、「ネットワーク接続ソリューションの概要」をご参照ください。
タスクの設定
ステップ 1:同期タスクの作成
Data Integration ページに移動します。
DataWorks コンソール にログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、Go to Data Integration をクリックします。
左側のナビゲーションウィンドウで、Synchronization Task をクリックします。ページ上部で、Create Synchronization Task をクリックし、タスク情報を設定します:
Source Type: ソースとして
MySQLを選択します。Destination Type: デスティネーションとして
Elasticsearchを選択します。Specific Type:
Real-time synchronization for an entire databaseを選択します。Synchronization Mode:
Schema Migration: デスティネーションに一致するインデックス構造(インデックスやフィールドマッピングなど)を自動的に作成しますが、データは含みません。
Full Synchronization(任意): 指定されたソーステーブルからすべての既存データをデスティネーションにコピーします。
Incremental Sync(任意): 完全同期完了後、ソースからデスティネーションへ、データの変更(挿入、更新、削除)を継続的にキャプチャして同期します。
ステップ 2:データソースおよび計算リソースの設定
Source には、ご利用の
MySQLデータソースを選択します。Destination には、ご利用のElasticsearchデータソースを選択します。
ステップ 3:同期ソリューションの設定
2. デスティネーションインデックスのマッピング
操作 | 説明 | ||||||||||||
Refresh | システムが選択したソーステーブルを自動的に一覧表示しますが、デスティネーションインデックスの属性を確認するには、マッピングをリフレッシュする必要があります。
| ||||||||||||
Custom Mapping Rule for Destination Index Name(任意) | システムにはデフォルトのインデックス命名ルールがあります:
この機能は、以下のシナリオをサポートします:
| ||||||||||||
フィールド型マッピングの編集(任意) | システムは、ソース型 と デスティネーション型 の間でデフォルトのマッピングを提供します。表の右上隅にある Edit Mapping of Field Data Types をクリックすることで、ソースからデスティネーションへのフィールド型マッピングをカスタマイズできます。設定後、Apply and Refresh Mapping をクリックします。 フィールド型マッピングを編集する際は、変換ルールが正しいことを確認してください。誤ったルールは型変換失敗を引き起こし、不正なデータ(Dirty Data)を生成してタスク実行に影響を与える可能性があります。 | ||||||||||||
デスティネーションインデックスの編集(任意) | システムは、インデックス名マッピングルールを使用して、新しいデスティネーションインデックスを作成するか、同じ名前の既存のインデックスを再利用します。 DataWorks は、ソーステーブルスキーマに基づいてデスティネーションインデックス構造を自動的に生成します。ほとんどの場合、手動での介入は必要ありません。 デスティネーションインデックスのステータスが 作成予定 の場合、その構造に新しいフィールドを追加できます。次の手順を実行します:
| ||||||||||||
Value assignment | ソースフィールド名がデスティネーションのフィールド名と一致する場合は、自動的にマッピングされます。前項で追加した新規フィールドおよびデスティネーションインデックスのプロパティについては、手動で値を割り当てる必要があります。次の手順を実行します:
定数または変数を割り当てることができます。Value Type メニューでタイプを切り替えます。以下のオプションがサポートされています:
| ||||||||||||
ソース分割カラム | ソース分割カラムでは、ソーステーブルからフィールドを選択するか、Not Split を選択できます。同期タスク実行時に、このフィールドに基づいてタスクが複数のタスクに分割され、データを同時かつバッチ単位で読み取ります。 テーブルのプライマリキーをソース分割カラムとして使用します。文字列、浮動小数点、日付型はサポートされていません。 現在、ソース分割カラムは MySQL ソースのみでサポートされています。 | ||||||||||||
完全同期のスキップ | タスクで完全同期を有効化している場合、特定のテーブルについてこれを選択的に無効化できます。これは、そのテーブルの完全データが他の手段で既にデスティネーションに同期済みである場合に便利です。 | ||||||||||||
Full condition | 完全同期フェーズ中にソースデータにフィルターを適用します。 | ||||||||||||
Configure DML Rule | DML メッセージ処理により、ソースからキャプチャされた変更データ( |
 アイコンをクリックし、Manual Input および Built-in Variable のオプションを組み合わせることで、デスティネーションインデックス名を構築します。サポートされる変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。
アイコンをクリックし、Manual Input および Built-in Variable のオプションを組み合わせることで、デスティネーションインデックス名を構築します。サポートされる変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。





 アイコンをクリックし、Statement Used to Create Index を編集してフィールドを追加します。
アイコンをクリックし、Statement Used to Create Index を編集してフィールドを追加します。ステップ 4:高度な設定
高度なパラメーターの設定
タスクを微調整し、カスタム同期要件を満たすために、Advanced Parameters タブで高度なパラメーターを変更します。
ページ右上隅の Advanced Settings をクリックして、高度なパラメーター設定ページに移動します。
記載されている説明に従って、パラメーター値を変更します。
AI を活用した設定も可能です。タスクの並列度の調整などの自然言語コマンドを入力すると、大規模言語モデルが推奨されるパラメーター値を生成します。その後、AI 生成のパラメーターを採用するかどうかを選択できます。
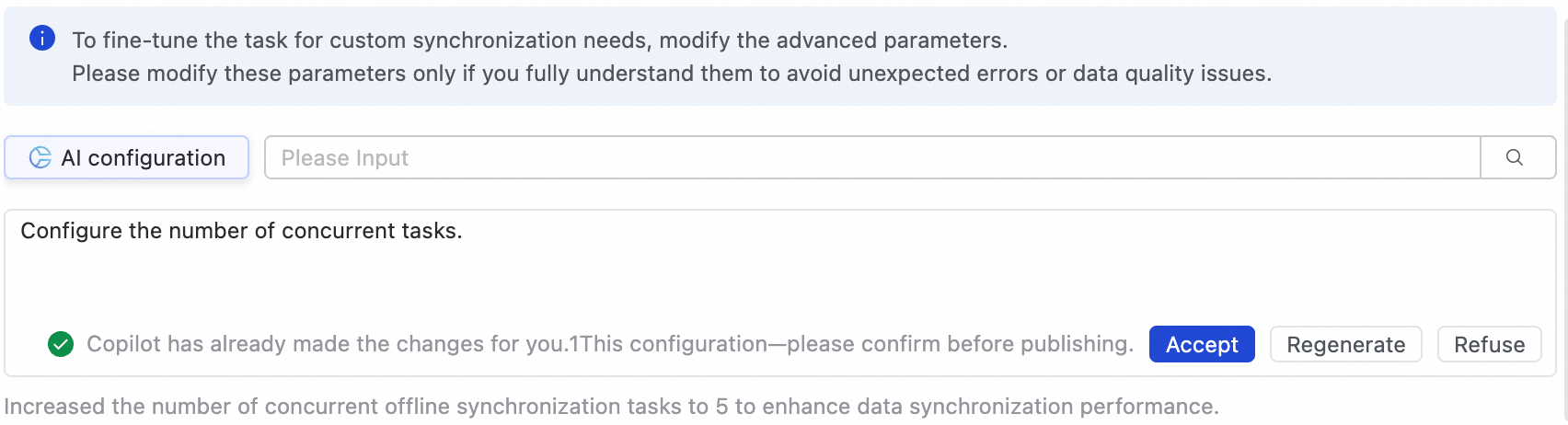
これらのパラメーターを変更する場合は、その目的を十分に理解している必要があります。誤った設定は、タスクの遅延、他のタスクをブロックする過剰なリソース消費、データ損失、その他の予期しない問題を引き起こす可能性があります。
ステップ 7:その他の設定
アラーム設定
1. アラームの追加
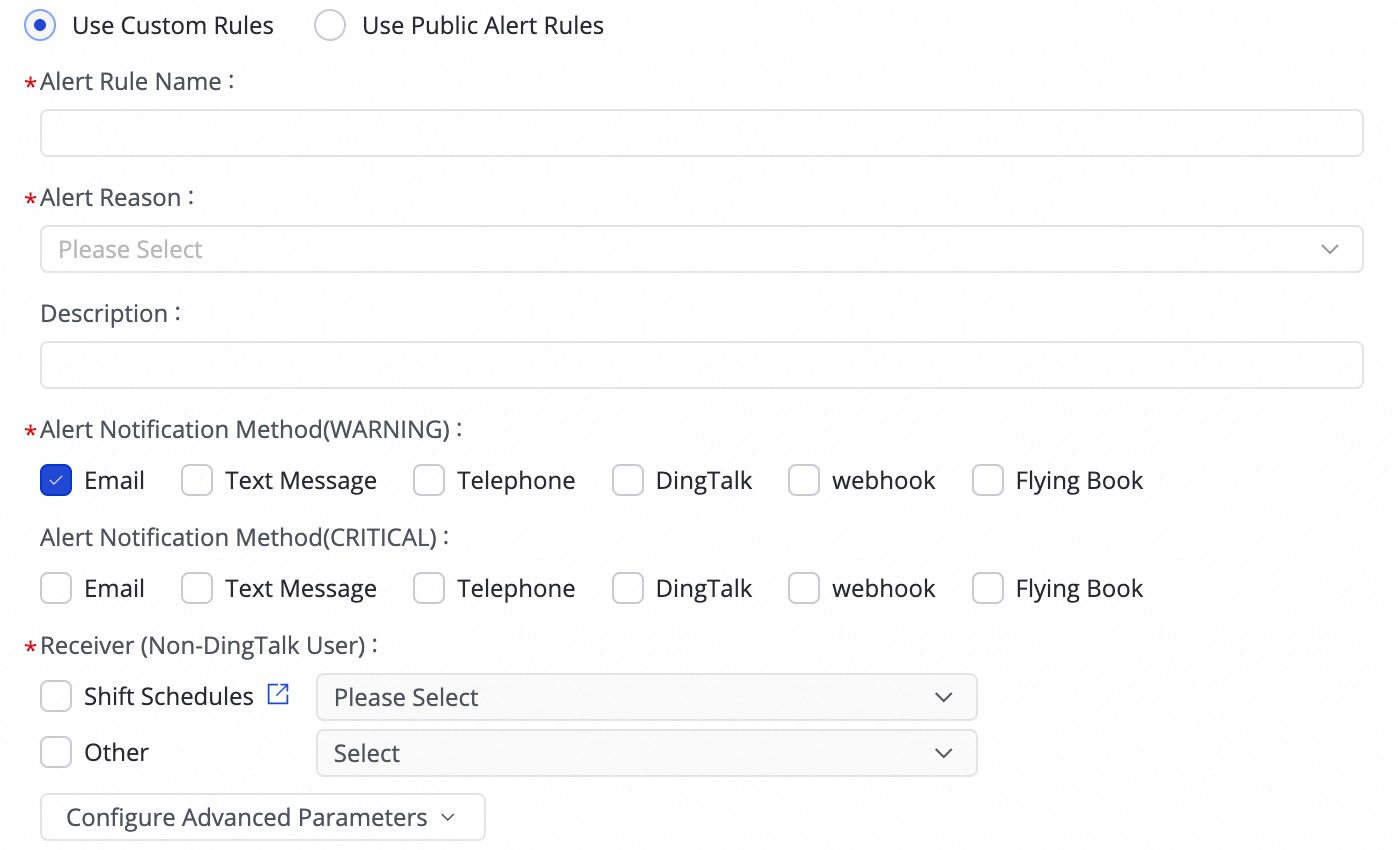
(1) Create Rule をクリックして、アラームルールを設定します。
Alert Reason を設定して、タスクの Business delay、フェイルオーバー、Task status、DDL Notification、Task Resource Utilization を監視します。指定されたしきい値に基づいて、CRITICAL または WARNING のアラームレベルを設定できます。
Configure Advanced Parameters を設定することで、アラームメッセージの送信間隔を制御し、アラート疲労およびメッセージのバックログを防止できます。
Business delay、Task status、または Task Resource Utilization をアラーム理由として選択した場合、復旧通知を有効化して、タスクが正常に戻った際に受信者に通知することもできます。
(2) アラームルールの管理
作成済みのアラームルールについては、アラームスイッチを使用して、アラームルールを有効にするかどうかを制御できます。アラームレベルに応じて、特定の受信者にアラームを送信します。
2. アラームの表示
タスクリストで を展開して、アラームイベントページに移動し、発生したアラーム情報を表示します。
リソースグループの設定
タスクで使用されるリソースグループおよびその設定は、インターフェイス右上隅の Configure Resource Group パネルで管理できます。
1. リソースグループの表示および切り替え
Configure Resource Group をクリックして、タスクに現在バインドされているリソースグループを表示します。
リソースグループを変更するには、ここから別の利用可能なリソースグループに切り替えます。
2. リソースの調整および「リソース不足」エラーのトラブルシューティング
タスクログに
Please confirm whether there are enough resources...というメッセージが表示される場合、現在のリソースグループの利用可能な計算ユニット(CU)が、タスクの起動または実行に十分ではありません。 Configure Resource Group パネルで、タスクが占有する CU 数を増やすことで、より多くの計算リソースを割り当てられます。
推奨リソース設定については、「Data Integration 推奨 CU 数」をご参照ください。実際の状況に応じて設定を調整してください。
高度なパラメーター設定
カスタム同期要件に応じて、Configure を Advanced Settings 列でクリックして、高度なパラメーターを変更します。
インターフェイス右上隅の Advanced Settings をクリックして、高度なパラメーター設定ページに移動します。
プロンプトに従ってパラメーター値を変更します。各パラメーターの意味は、パラメーター名の後に説明されています。
問題(タスクの遅延、他のタスクをブロックする過剰なリソース消費、データ損失など)を防ぐため、パラメーターを変更する前に、その内容を十分に理解してください。
タスクの管理
タスクの編集
ページで、作成済みの同期タスクを見つけます。Operation 列で More をクリックし、Edit をクリックしてタスク情報を編集します。手順は、新規タスクの設定と同様です。
実行中でない タスクの場合、設定を直接変更し、保存して本番環境にデプロイすることで、変更を適用できます。
Running タスクの場合、Start immediately after deployment を選択せずに編集およびデプロイを行うと、アクションボタンが Apply Updates に変わります。このボタンをクリックすることで、変更が本番環境に反映されます。
[Apply Update] をクリックすると、システムは順次以下のアクションを実行します:Stop、Publish、Restart。
変更内容が テーブルの追加または既存テーブルの切り替え を含む場合:
更新の適用時にチェックポイントを選択することはできません。確認後、システムは新規テーブルに対して Schema Migration および Full Data Initialization を実行します。完全初期化が完了すると、他の元のテーブルとともに増分同期を開始します。
その他の情報を変更する場合:
更新の適用時にチェックポイントを選択できます。確認後、タスクは指定されたチェックポイントから再開されます。チェックポイントを指定しない場合、最後に記録されたチェックポイントから再開されます。
変更されていないテーブルには影響はありません。更新および再起動後、それらは最後に記録されたチェックポイントから再開されます。
タスクの表示
同期タスクを作成した後、同期タスクページで、作成済みのすべてのタスクおよびその基本情報を一覧表示できます。
操作列では、同期タスクを Start または Stop できます。「More」から、Edit や View などのその他の操作を実行できます。

実行中のタスクでは、Execution Overview で基本ステータスを確認できます。概要内の特定の領域をクリックすると、詳細な実行情報を表示できます。

MySQL から Elasticsearch へのリアルタイムデータベース同期タスクは、以下の 3 つのステップで構成されます:
スキーマ移行: デスティネーションインデックスの作成方法(既存インデックス/自動作成インデックス)を含みます。インデックスが自動作成される場合、DDL 文が表示されます。
完全データ初期化: 同期対象のテーブル、その進行状況、書き込まれた行数に関する情報を含みます。
リアルタイム同期: リアルタイム進行状況、DDL レコード、DML レコード、アラート情報などのリアルタイム同期統計を含みます。
同期タスクの再実行
一部の特殊なケースでは、ソースにテーブルを追加または削除する場合、または宛先テーブルのスキーマまたは名前を変更する場合、同期タスクの [操作] 列で [詳細] をクリックし、その後 [再実行] をクリックして、変更後にタスクを再実行できます。再実行プロセス中、同期タスクは、新しく追加されたテーブルから宛先へのデータのみ、またはスキーマまたは名前が変更された宛先テーブルへのマップされたソーステーブルからのデータのみを同期します。
タスクの構成を変更せずに同期タスクを再実行し、完全同期と増分同期を再度実行するには、「操作」列で「その他」をクリックし、次に[再実行]をクリックします。
タスクへのテーブルの追加または削除後に同期タスクを再実行するには、変更後に [完了] をクリックします。この場合、同期タスクの操作列に [更新を適用] が表示されます。[更新を適用] をクリックすると、同期タスクの再実行がトリガーされます。再実行プロセス中、同期タスクは新しく追加されたテーブルのデータを宛先に同期します。元のテーブルのデータは再度同期されません。
チェックポイントの再開
ユースケース
タスクの開始または再起動時にチェックポイントを手動でリセットすることは、以下のシナリオで有用です:
タスクの回復およびデータの継続: タスクが中断された場合、中断時刻を新しい開始チェックポイントとして手動で指定することで、正確にその時点からデータを再開できます。
データのトラブルシューティングおよびロールバック: 同期後に欠落または異常なデータが見つかった場合、問題が発生する前の時点までチェックポイントをロールバックして、問題のあるデータを再処理および修正できます。
主要なタスク構成変更: デスティネーションインデックス構造やフィールドマッピングなどのタスク構成を大幅に変更した後、新しい構成下でのデータ精度を確保するために、チェックポイントを特定の時点にリセットすることを推奨します。
手順
Start をクリックすると、ポップアップウィンドウで Whether to reset the site を選択します:
チェックポイントをリセットしない: タスクは最後の停止時刻(最後のチェックポイント)から再開されます。
チェックポイントをリセットして時刻を選択: タスクは指定された時刻から開始されます。選択した時刻が、ソースのバイナリログ(binlog)で利用可能な最も早い時刻よりも前になっていないことを確認してください。
チェックポイントが無効または存在しないというエラーが発生した場合、以下の解決策を試してください:
チェックポイントのリセット: リアルタイム同期タスクを開始する際に、チェックポイントをリセットし、ソースデータベースで利用可能な最も早い時刻を選択します。
ログ保持期間の調整: データベースのチェックポイントが期限切れになっている場合、データベース設定でログ保持期間(例:7 日間)を延長することを検討してください。
データの再同期: データが失われている場合、新しい完全同期を実行するか、欠落したデータを手動で同期するためにオフライン同期タスクを設定することを検討してください。
よくある質問
リアルタイムデータベース同期に関するよくある質問については、「Data Integration よくある質問」および「Data Integration のエラー」をご参照ください。