DataWorks では、単一テーブルのリアルタイムデータ統合タスクにおいて、文字列置換コンポーネントを使用して指定したフィールド内の文字列を置換できます。
ステップ 1:データ統合タスクの設定
データソースを作成します。 詳細については、「データソース管理」をご参照ください。
データ統合タスクを作成します。 詳細については、「単一テーブルのリアルタイム同期タスクの設定」をご参照ください。
説明単一テーブルのリアルタイムデータ統合タスクでは、ソースコンポーネントと送信先コンポーネントの間にデータ処理コンポーネントを追加できます。 詳細については、「サポートされているデータソースと同期ソリューション」をご参照ください。
ステップ 2:文字列置換コンポーネントの追加
単一テーブルのリアルタイム同期タスクで、データ処理 スイッチを有効にし、+Add Node をクリックして、Replace String コンポーネントを選択します。
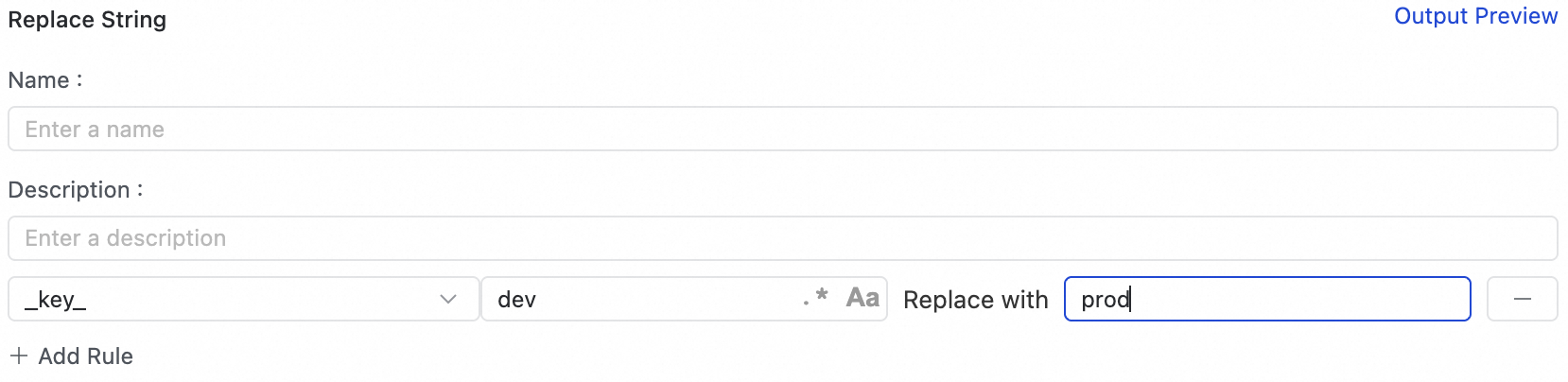
ルールを設定します。
[ルールの追加] をクリックして、次のパラメーターを使用して 1 つ以上のルールを設定します。
フィールド名:上流ノードからテキストフィールドを選択します。
元の文字列:置換対象の文字列です。 正規表現マッチングが無効な場合、
\t(タブ文字)、\n(改行)、\u0001(Unicode 文字) などの Java エスケープ文字がサポートされます。新しい文字列:置換後の文字列です。 正規表現マッチングが無効な場合、
\t(タブ文字)、\n(改行)、\u0001(Unicode 文字) などの Java エスケープ文字がサポートされます。
説明Regular matching:正規表現を使用したマッチングを有効にします。 このオプションを有効にすると、元の文字列は Class Pattern で定義されている正規表現ルールをサポートします。 新しい文字列では、
$の後に数字を付けて、式からキャプチャグループを参照できます。 たとえば、フィールドにno.9526が含まれている場合、[元の文字列] をno.([0-9]+)に、[新しい文字列] を$1に設定できます。 これにより、フィールドの内容は9526に変更されます。Case Sensitive:元の文字列の検索で、大文字と小文字を区別するようにします。
次のステップ
Data Source コンポーネントと 文字列置換 コンポーネントを設定した後、Preview Data Output をクリックして、ノードのデータ出力を表示し、要件を満たしているかを確認します。