このトピックでは、DataWorks の E-MapReduce(EMR)Hive ノードを使用して、同期後に Object Storage Service(OSS)バケットに格納されている ods_user_info_d_emr テーブルと ods_raw_log_d_emr テーブルのデータを処理し、目的のユーザープロファイルデータを取得する方法について説明します。 ods_user_info_d_emr テーブルには基本的なユーザー情報が格納され、ods_raw_log_d_emr テーブルには Web サイトアクセスログが格納されます。
前提条件
必要なデータが同期されています。 詳細については、「データの同期」をご参照ください。
ステップ 1:ワークフローを設計する
ワークフロー内のノード間の依存関係については、「データの同期」をご参照ください。
DataStudio ページの [スケジュール済みワークフロー] ペインで、ワークフローをダブルクリックします。 ワークフローの構成タブで、[ノードの作成] をクリックし、[EMR Hive] をキャンバスにドラッグします。 [ノードの作成] ダイアログボックスで、[名前] パラメーターを構成し、[確認] をクリックします。
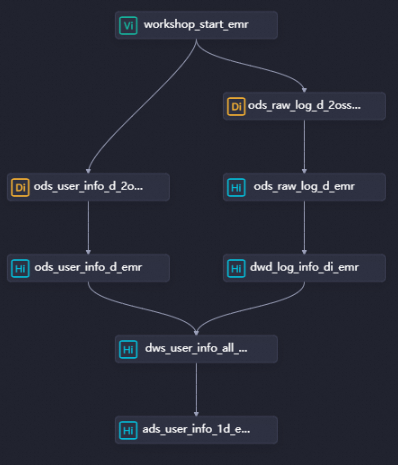
dwd_log_info_di_emr、dws_user_info_all_di_emr、および ads_user_info_1d_emr という名前の 3つの EMR Hive ノードを作成する必要があります。 次に、次の図に示すようにノードの依存関係を設定します。
dwd_log_info_di_emr: 生の OSS ログデータをクレンジングするために使用されます。
dws_user_info_all_di_emr: クレンジングされた OSS ログデータと基本的なユーザー情報を集約するために使用されます。
ads_user_info_1d_emr: ユーザープロファイルデータを生成するために使用されます。
ステップ 2:関数の作成
関数を使用して、同期されたログデータを元の形式から目的の形式に変換できます。 このトピックの例では、IP アドレスを地域に変換するために使用される関数コードパッケージが提供されています。 関数コードパッケージをオンプレミスマシンにダウンロードし、コードパッケージを DataWorks の関数として登録すると、関数を呼び出すことができます。
リソースのアップロード
ip2region-emr.jar パッケージをダウンロードします。
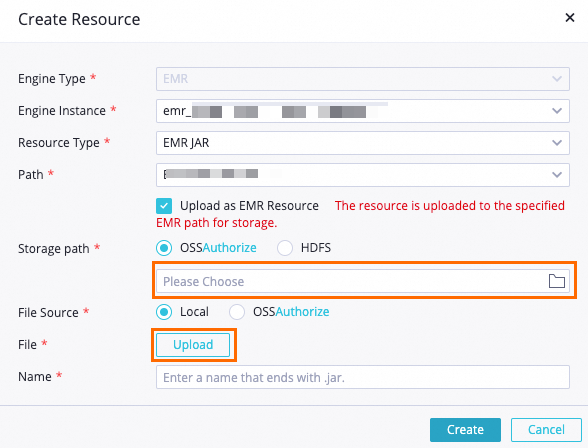
[DataStudio] ページで、WorkShop という名前のワークフローを見つけ、[EMR] を右クリックし、 を選択します。 [リソースの作成] ダイアログボックスで、パラメーターを構成し、[作成] をクリックします。
主なパラメーター:
[ストレージパス]: 環境準備中に作成した EMR クラスタに指定した OSS バケットを選択します。
[ファイル]: ダウンロードした ip2region-emr.jar パッケージを選択します。
ビジネス要件に基づいて他のパラメーターを構成するか、デフォルト値を使用します。
ツールバーの
 アイコンをクリックして、リソースを開発環境の EMR プロジェクトにコミットします。
アイコンをクリックして、リソースを開発環境の EMR プロジェクトにコミットします。
関数の登録
[DataStudio] ページで、WorkShop という名前のワークフローを見つけ、[EMR] を右クリックし、[関数の作成] を選択します。
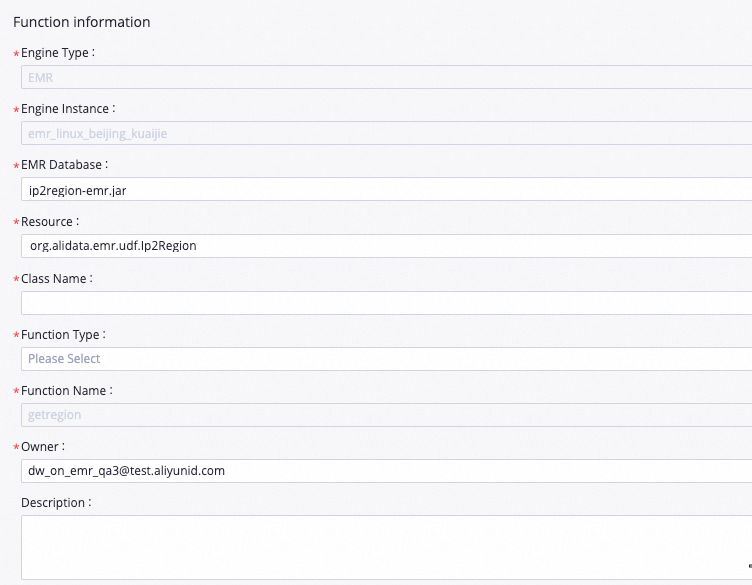
[関数の作成] ダイアログボックスで、[名前] パラメーターを getregion に設定し、[作成] をクリックします。 表示されるタブで、パラメーターを構成します。
主なパラメーター:
[リソース]: 値を ip2region-emr.jar に設定します。
[クラス名]: 値を org.alidata.emr.udf.Ip2Region に設定します。
ビジネス要件に基づいて他のパラメーターを構成するか、デフォルト値を使用します。
ツールバーの
アイコンをクリックして、関数を開発環境の EMR プロジェクトにコミットします。
ステップ 3: EMR Hive ノードの構成
dwd_log_info_di_emr ノードの作成
1. ノードコードの編集
dwd_log_info_di_emr ノードをダブルクリックして、ノード構成タブに移動します。 構成タブで、次の文を入力します。
ワークスペースの DataStudio に複数の EMR コンピューティングエンジンが関連付けられている場合は、ビジネス要件に基づいて [EMR コンピューティングエンジンを選択] する必要があります。 ワークスペースの DataStudio に EMR コンピューティングエンジンが 1 つだけ関連付けられている場合は、コンピューティングエンジンを選択する必要はありません。
-- ODS レイヤーにテーブルを作成します。
CREATE TABLE IF NOT EXISTS dwd_log_info_di_emr (
ip STRING COMMENT 'IPアドレス',
uid STRING COMMENT 'ユーザーID',
`time` STRING COMMENT 'yyyymmddhh:mi:ss 形式の時間',
status STRING COMMENT 'サーバーから返される状態コード',
bytes STRING COMMENT 'クライアントに返されるバイト数',
region STRING COMMENT 'IPアドレスに基づいて取得される地域',
method STRING COMMENT 'HTTPリクエストタイプ',
url STRING COMMENT 'URL',
protocol STRING COMMENT 'HTTPのバージョン番号',
referer STRING COMMENT 'ソースURL',
device STRING COMMENT '端末タイプ',
identity STRING COMMENT 'アクセスタイプ。クローラー、フィード、ユーザー、または不明のいずれかになります。'
)
PARTITIONED BY (
dt STRING
);
ALTER TABLE dwd_log_info_di_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
set hive.vectorized.execution.enabled = false;
INSERT OVERWRITE TABLE dwd_log_info_di_emr PARTITION (dt='${bizdate}')
SELECT ip
, uid
, tm
, status
, bytes
, getregion(ip) AS region -- ユーザー定義関数(UDF)を使用して、IPアドレスに基づいて地域を取得します。
, regexp_substr(request, '(^[^ ]+ )') AS method -- 正規表現を使用して、リクエストから 3 つのフィールドを抽出します。
, regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url
, regexp_extract(request, '.* ([^ ]+$)') AS protocol
, regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer -- 正規表現を使用して HTTP リファラーをクレンジングし、より正確な URL を取得します。
, CASE
WHEN lower (agent) RLIKE 'android' THEN 'android' -- agent パラメーターの値から端末とアクセスタイプを取得します。
WHEN lower(agent) RLIKE 'iphone' THEN 'iphone'
WHEN lower(agent) RLIKE 'ipad' THEN 'ipad'
WHEN lower(agent) RLIKE 'macintosh' THEN 'macintosh'
WHEN lower(agent) RLIKE 'windows phone' THEN 'windows_phone'
WHEN lower(agent) RLIKE 'windows' THEN 'windows_pc'
ELSE 'unknown'
END AS device
, CASE
WHEN lower(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler'
WHEN lower(agent) RLIKE 'feed'
OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed'
WHEN lower(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)'
AND agent RLIKE '^[Mozilla|Opera]'
AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user'
ELSE 'unknown'
END AS identity
FROM (
SELECT SPLIT(col, '##@@')[0] AS ip
, SPLIT(col, '##@@')[1] AS uid
, SPLIT(col, '##@@')[2] AS tm
, SPLIT(col, '##@@')[3] AS request
, SPLIT(col, '##@@')[4] AS status
, SPLIT(col, '##@@')[5] AS bytes
, SPLIT(col, '##@@')[6] AS referer
, SPLIT(col, '##@@')[7] AS agent
FROM ods_raw_log_d_emr
WHERE dt = '${bizdate}'
) a;2. スケジューリングプロパティの構成
次の表に示すように dwd_log_info_di_emr ノードのスケジューリングプロパティを構成すると、dwd_log_info_di_emr ノードの祖先ノードである ods_raw_log_d_emr ノードが、スケジューリングシナリオで毎日 00:30 に OSS オブジェクト user_log.txt から EMR テーブル ods_raw_log_d_emr にデータを同期した後、dwd_log_info_di_emr ノードがトリガーされて ods_raw_log_d_emr テーブルのデータを処理し、処理されたデータを dwd_log_info_di_emr テーブルのデータタイムスタンプベースのパーティションに書き込みます。
セクション | 説明 | スクリーンショット |
スケジューリングパラメーター | [スケジューリングパラメーター] セクションの [パラメーターの追加] をクリックします。 テーブルに表示される行で、スケジューリングパラメーターとスケジューリングパラメーターの値を指定できます。
|
|
スケジュール | [再実行] パラメーターを [実行状態に関係なく許可] に設定します。 |
|
依存関係 | 生成されたテーブルが現在のノードの出力テーブルとして使用されていることを確認します。 出力テーブルには、 |
|
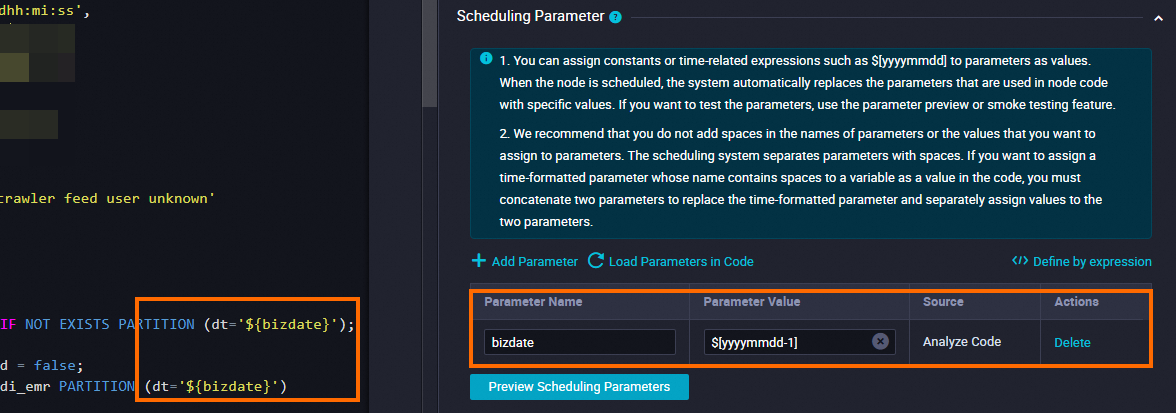

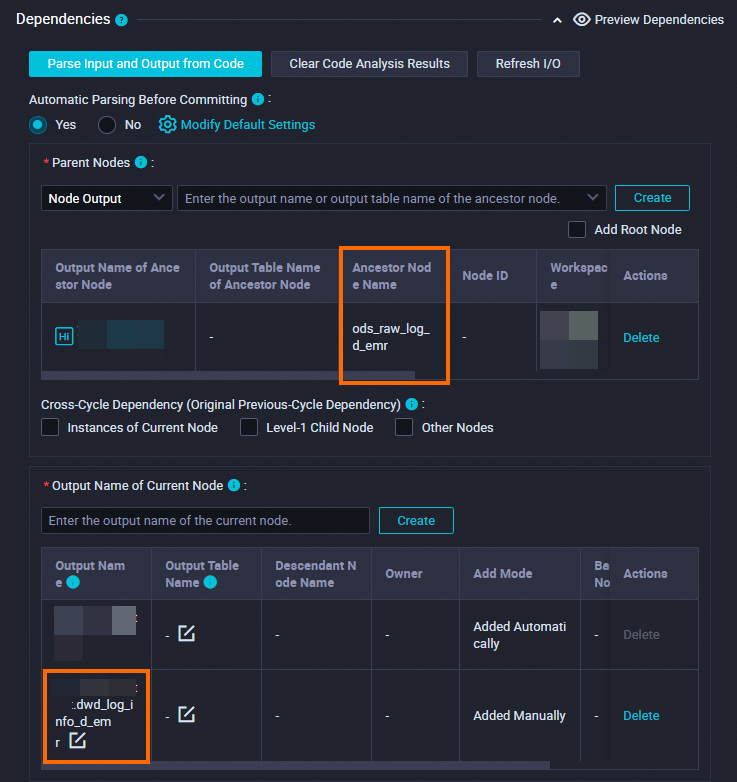
[スケジュール] セクションで、[スケジューリングサイクル] パラメーターを [日] に設定します。 現在のノードの [スケジュールされた時間] パラメーターを個別に構成する必要はありません。 現在のノードが毎日スケジュールされる時間は、ワークフローの [workshop_start_emr] ゼロロードノードのスケジューリング時間によって決まります。 現在のノードは、毎日 00:30 以降に実行されるようにスケジュールされています。
3. 構成の保存
この例では、ビジネス要件に基づいて他の必要な構成項目を構成できます。 構成が完了したら、ノードの構成タブの上部ツールバーにある ![]() アイコンをクリックして、ノードの構成を保存します。
アイコンをクリックして、ノードの構成を保存します。
dws_user_info_all_di_emr ノードの作成
1. ノードコードの編集
dws_user_info_all_di_emr ノードをダブルクリックして、ノード設定タブに移動します。設定タブに、次のステートメントを入力します。
ワークスペースの DataStudio に複数の EMR コンピューティングエンジンが関連付けられている場合は、ビジネス要件に基づいて [EMR コンピューティングエンジンを選択] する必要があります。 ワークスペースの DataStudio に EMR コンピューティングエンジンが 1 つだけ関連付けられている場合は、コンピューティングエンジンを選択する必要はありません。
-- DW レイヤーにテーブルを作成します。
CREATE TABLE IF NOT EXISTS dws_user_info_all_di_emr (
uid STRING COMMENT 'ユーザーID',
gender STRING COMMENT '性別',
age_range STRING COMMENT '年齢層',
zodiac STRING COMMENT '星座',
region STRING COMMENT 'IPアドレスに基づいて取得される地域',
device STRING COMMENT '端末タイプ',
identity STRING COMMENT 'アクセスタイプ。クローラー、フィード、ユーザー、または不明のいずれかになります。',
method STRING COMMENT 'HTTPリクエストタイプ',
url STRING COMMENT 'URL',
referer STRING COMMENT 'ソースURL',
`time` STRING COMMENT 'yyyymmddhh:mi:ss 形式の時間'
)
PARTITIONED BY (
dt STRING
);
ALTER TABLE dws_user_info_all_di_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
INSERT OVERWRITE TABLE dws_user_info_all_di_emr PARTITION (dt='${bizdate}')
SELECT COALESCE(a.uid, b.uid) AS uid
, b.gender
, b.age_range
, b.zodiac
, a.region
, a.device
, a.identity
, a.method
, a.url
, a.referer
, a.`time`
FROM (
SELECT *
FROM dwd_log_info_di_emr
WHERE dt = '${bizdate}'
) a
LEFT OUTER JOIN (
SELECT *
FROM ods_user_info_d_emr
WHERE dt = '${bizdate}'
) b
ON a.uid = b.uid;2. スケジューリングプロパティの構成
次の表に示すように、dws_user_info_all_di_emr ノードのスケジューリングプロパティを構成します。 dws_user_info_all_di_emr ノードの祖先ノードである ods_user_info_d_emr ノードと dwd_log_info_di_emr ノードがスケジューリングシナリオで毎日 00:30 に実行を完了すると、dws_user_info_all_di_emr ノードがトリガーされて ods_user_info_d_emr テーブルと dwd_log_info_di_emr テーブルを結合および処理し、処理されたデータを dws_user_info_all_di_emr テーブルに書き込みます。
セクション | 説明 | スクリーンショット |
スケジューリングパラメーター | [スケジューリングパラメーター] セクションの [パラメーターの追加] をクリックします。 テーブルに表示される行で、スケジューリングパラメーターとスケジューリングパラメーターの値を指定できます。
|
|
スケジュール | [再実行] パラメーターを [実行状態に関係なく許可] に設定します。 |
|
依存関係 | 生成されたテーブルが現在のノードの出力テーブルとして使用されていることを確認します。 出力テーブルには、 |
|
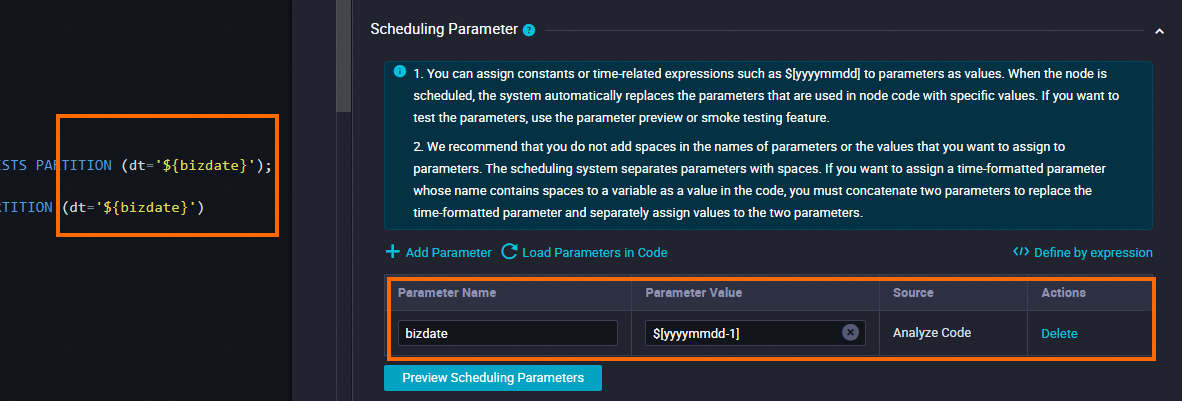
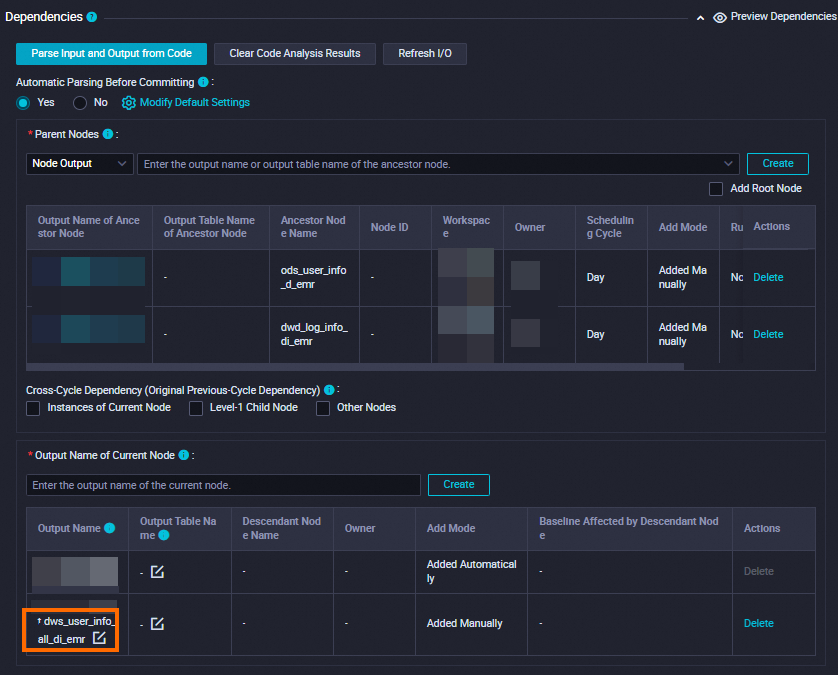
[スケジュール] セクションで、[スケジューリングサイクル] パラメーターを [日] に設定します。 現在のノードの [スケジュールされた時間] パラメーターを個別に構成する必要はありません。 現在のノードが毎日スケジュールされる時間は、ワークフローの [workshop_start_emr] ゼロロードノードのスケジューリング時間によって決まります。 現在のノードは、毎日 00:30 以降に実行されるようにスケジュールされています。
3. 構成の保存
この例では、ビジネス要件に基づいて他の必要な構成項目を構成できます。 構成が完了したら、ノードの構成タブの上部ツールバーにある ![]() アイコンをクリックして、ノードの構成を保存します。
アイコンをクリックして、ノードの構成を保存します。
ads_user_info_1d_emr ノードの作成
1. ノードコードの編集
[ads_user_info_1d_emr] ノードをダブルクリックして、ノードの構成タブに移動します。 構成タブで、次の文を入力します。
ワークスペースの DataStudio に複数の EMR コンピューティングエンジンが関連付けられている場合は、ビジネス要件に基づいて [EMR コンピューティングエンジンを選択] する必要があります。 ワークスペースの DataStudio に EMR コンピューティングエンジンが 1 つだけ関連付けられている場合は、コンピューティングエンジンを選択する必要はありません。
-- RPT レイヤーにテーブルを作成します。
CREATE TABLE IF NOT EXISTS ads_user_info_1d_emr (
uid STRING COMMENT 'ユーザーID',
region STRING COMMENT 'IPアドレスに基づいて取得される地域',
device STRING COMMENT '端末タイプ',
pv BIGINT COMMENT 'ページビュー数',
gender STRING COMMENT '性別',
age_range STRING COMMENT '年齢層',
zodiac STRING COMMENT '星座'
)
PARTITIONED BY (
dt STRING
);
ALTER TABLE ads_user_info_1d_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
INSERT OVERWRITE TABLE ads_user_info_1d_emr PARTITION (dt='${bizdate}')
SELECT uid
, MAX(region)
, MAX(device)
, COUNT(0) AS pv
, MAX(gender)
, MAX(age_range)
, MAX(zodiac)
FROM dws_user_info_all_di_emr
WHERE dt = '${bizdate}'
GROUP BY uid;2. スケジューリングプロパティの構成
dws_user_info_all_di_emr ノードが ods_user_info_d_emr テーブルと dwd_log_info_di_emr テーブルをマージした後、ads_user_info_1d_emr ノードをトリガーしてデータをさらに処理し、消費可能なデータを生成できます。
セクション | 説明 | スクリーンショット |
スケジューリングパラメーター | [スケジューリングパラメーター] セクションの [パラメーターの追加] をクリックします。 テーブルに表示される行で、スケジューリングパラメーターとスケジューリングパラメーターの値を指定できます。
|
|
スケジュール | [再実行] パラメーターを [実行状態に関係なく許可] に設定します。 |
|
依存関係 | 生成されたテーブルが現在のノードの出力テーブルとして使用されていることを確認します。 出力テーブルには、 |
|
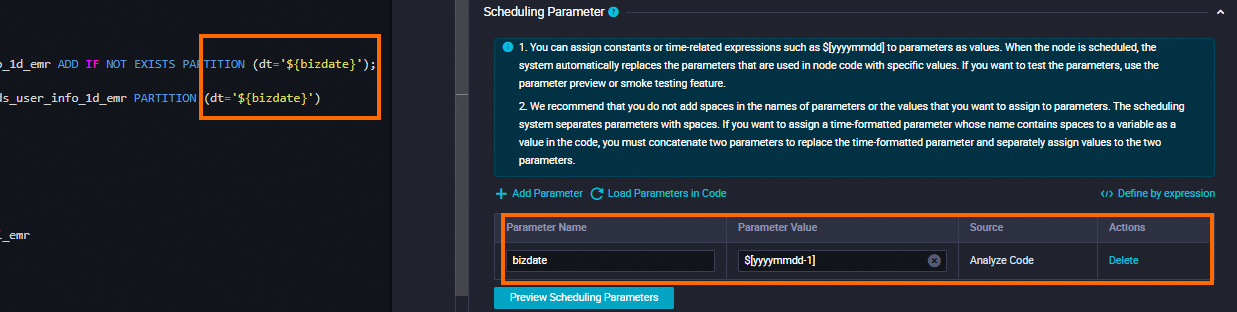
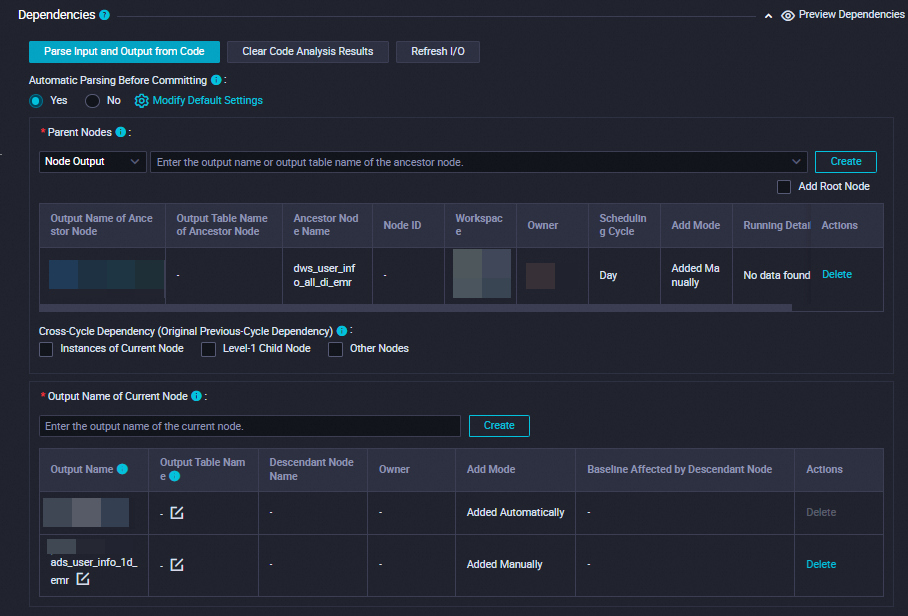
[スケジュール] セクションで、[スケジューリングサイクル] パラメーターを [日] に設定します。 現在のノードの [スケジュールされた時間] パラメーターを個別に構成する必要はありません。 現在のノードが毎日スケジュールされる時間は、ワークフローの [workshop_start_emr] ゼロロードノードのスケジューリング時間によって決まります。 現在のノードは、毎日 00:30 以降に実行されるようにスケジュールされています。
3. 構成の保存
この例では、ビジネス要件に基づいて他の必要な構成項目を構成できます。 構成が完了したら、ノードの構成タブの上部ツールバーにある ![]() アイコンをクリックして、ノードの構成を保存します。
アイコンをクリックして、ノードの構成を保存します。
ステップ 4:ワークフローをコミットする
ワークフローを構成した後、ワークフローが期待どおりに実行できるかどうかをテストします。 テストが成功したら、ワークフローをコミットし、ワークフローがデプロイされるのを待ちます。
ワークフローの構成タブで、
 アイコンをクリックしてワークフローを実行します。
アイコンをクリックしてワークフローを実行します。ワークフローのすべてのノードの横に
 アイコンが表示されたら、
アイコンが表示されたら、 アイコンをクリックしてワークフローをコミットします。
アイコンをクリックしてワークフローをコミットします。[コミット] ダイアログボックスで、コミットするノードを選択し、説明を入力して、[I/O の不整合アラートを無視] を選択します。 次に、[確認] をクリックします。
ワークフローがコミットされたら、ワークフロー内のノードをデプロイできます。
ワークフローの構成タブの右上隅にある [デプロイ] をクリックします。 [デプロイタスクの作成] ページが表示されます。
デプロイするノードを選択し、[デプロイ] をクリックします。 [デプロイタスクの作成] ダイアログボックスで、[デプロイ] をクリックします。
ステップ 5:本番環境でノードを実行する
ある日にノードをデプロイすると、ノードに対して生成されたインスタンスは次の日に実行されるようにスケジュールできます。 [データバックフィル] 機能を使用して、デプロイされているワークフロー内のノードのデータをバックフィルできます。これにより、ノードを本番環境で実行できるかどうかを確認できます。 詳細については、「データのバックフィルとデータバックフィルインスタンスの表示(新バージョン)」をご参照ください。
ノードをデプロイした後、右上隅にある [オペレーションセンター] をクリックします。
ワークフローの構成タブの上部ツールバーにある [オペレーションセンター] をクリックして、[オペレーションセンター] ページに移動することもできます。
オペレーションセンターページの左側のナビゲーションペインで、 を選択します。 [自動トリガーノード] ページで、workshop_start_emr ゼロロードノードの名前をクリックします。
右側のノードの有向非巡回グラフ(DAG)で、workshop_start_emr ノードを右クリックし、 を選択します。
[データバックフィル] パネルで、データをバックフィルするノードを選択し、[データタイムスタンプ] パラメーターを構成して、[送信してリダイレクト] をクリックします。
データバックフィルページで、すべての SQL ノードが正常に実行されるまで [更新] をクリックします。
次のステップ
定期的なスケジューリングシナリオでノードによって生成されたテーブルデータがビジネス要件を満たしていることを確認するために、監視ルールを構成して、ノードによって生成されたテーブルデータの品質を監視できます。 詳細については、「データ品質の監視」をご参照ください。