完全同期および増分同期タスクの管理
同期タスクを構成した後、 ページでタスクの一覧を確認できます。さまざまな条件に基づいてタスクをフィルターし、以下の操作を実行できます。
操作 | 説明 |
開始 | 操作 列で、Commit and Run をクリックして同期タスクを開始します。 |
編集 | ビジネス要件の変更に応じて、完全同期および増分同期タスクにテーブルを追加または削除できます。操作 列で、 をクリックすると、テーブルの追加または削除が可能な構成ページが開きます。編集が完了したら、Commit and Run をクリックします。タスクをコミットすると、システムは現在のテーブル一覧と前回の成功実行時のテーブル一覧を比較します。新しいテーブルが検出された場合、そのテーブルは同期プロセスに追加されます。詳細については、「実行中の同期ソリューションにソーステーブルを追加または削除する」をご参照ください。 ワンクリックリアルタイム同期を使用している場合、新しいテーブルにはまず Full Initialization が必要です。初期化が完了すると、システムはそのテーブルを Real-time Data Synchronization タスクに追加して開始します。
説明 Real-time Data Synchronization タスクが開始位置をリセットして実行されると、新しいテーブルの変更データが追加されます。このとき、タスクの開始時刻は新しいテーブルの Full Initialization 開始時刻にリセットされます。たとえば、同期タスクが 8:00 に開始され、9:00 にもまだ実行中であるとします。9:00 に新しいテーブルが追加された場合、そのテーブルの Full Initialization は 9:00 に開始され、1 時間かけて 10:00 に完了します。その後、実行中の Real-time Data Synchronization タスクは停止し、開始位置を 9:00 にリセットして増分データの追加を開始します。これにより、9:00 から 10:00 の間にすべてのテーブルで発生した増分データの変更が、ターゲットの Hologres テーブルに再同期されます。このプロセスにより、最終的なデータ整合性が保証されます。 すべてのテーブルを初期化する必要がある場合は、Rerun 機能を使用してください。
|
Rerun | ソースデータが破損している場合やデータリンクに問題が発生しているなどの特殊なケースでは、すべてのソーステーブルに対して完全同期および増分同期の初期化を強制的に実行できます。操作 列で、 をクリックします。この操作により、ソースデータがターゲットテーブルに再移行され、データ整合性を迅速に復旧できます。 データベース全体のデータを復旧するために Rerun が必要となる一般的なシナリオは以下のとおりです。 リアルタイムタスクが長期間失敗しており、バイナリログがパージされたため、増分データを復旧できなくなっている。 さまざまな理由により、ターゲットテーブルに新しいカラムが存在しない。 さまざまな理由により、ターゲットテーブルのデータが欠落している、または不正確である。
重要 強制的な Rerun では、ソーステーブルのカラムがターゲットテーブルに同期されます。ターゲットテーブルにソースカラムが不足している場合、そのカラムが追加されます。 Rerun を実行する前に、実行中またはスケジュール済みの Incremental Merge タスクインスタンスとの競合がないか確認してください。同じビジネステーブル日付で同時に実行されると、パーティションまたはテーブルのデータが上書きされる可能性があります。 Incremental Merge タスクインスタンスのステータスは、DataWorks の Operation Center 内にある「自動トリガーされたインスタンスの表示」ページで確認できます。競合が発生した場合は、以下のいずれかの対応を行ってください。 Rerun 完了後、翌日のデータが生成されない場合や Incremental Merge タスクが自動的に再開されない場合は、手動で Incremental Merge インスタンスを確認・再開する必要があります。
|
Full Data Backfill | MaxCompute のターゲットテーブルのデータが欠落している、または不正確であり、完全データの再同期によるデータバックフィルが必要な場合に、この機能を使用します。 操作 列で、Backfill all data をクリックし、以下のパラメーターを設定します。 データバックフィルのビジネス日付を選択します。 パーティションテーブルの場合、プロセスは完全データを指定されたビジネス日付に対応する日付パーティションに同期します。 バックフィルの対象となるテーブルを選択します。 左側の選択ボックスで完全同期を行うテーブルを選択し、 アイコンをクリックして右側に移動させます。 アイコンをクリックして右側に移動させます。 OK をクリックして Full Data Backfill 操作を開始します。
重要 一度に選択できるビジネステーブル日付は 1 日のみです。複数日分のデータをバックフィルするには、Full Data Backfill 操作を複数回実行する必要があります。 このプロセスでは、ソーステーブルとターゲットテーブルの共通カラム、および完全同期および増分同期タスクで定義された追加カラムがコピーされます。 Full Data Backfill を開始する前に、指定したビジネステーブル日付が実行中またはスケジュール済みの Incremental Merge タスクインスタンスと競合しないか確認してください。同じビジネステーブル日付で同時に実行されると、パーティションまたはテーブルのデータが上書きされる可能性があります。 Incremental Merge タスクインスタンスのステータスは、DataWorks の Operation Center 内にある「自動トリガーされたインスタンスの表示」ページで確認できます。競合が発生した場合は、以下のいずれかの対応を行ってください。
|
停止 | 実行中のタスクについては、操作 列で Stop をクリックして停止できます。 |
タスク実行の詳細の確認
タスク名をクリックして、その実行の詳細を確認します。
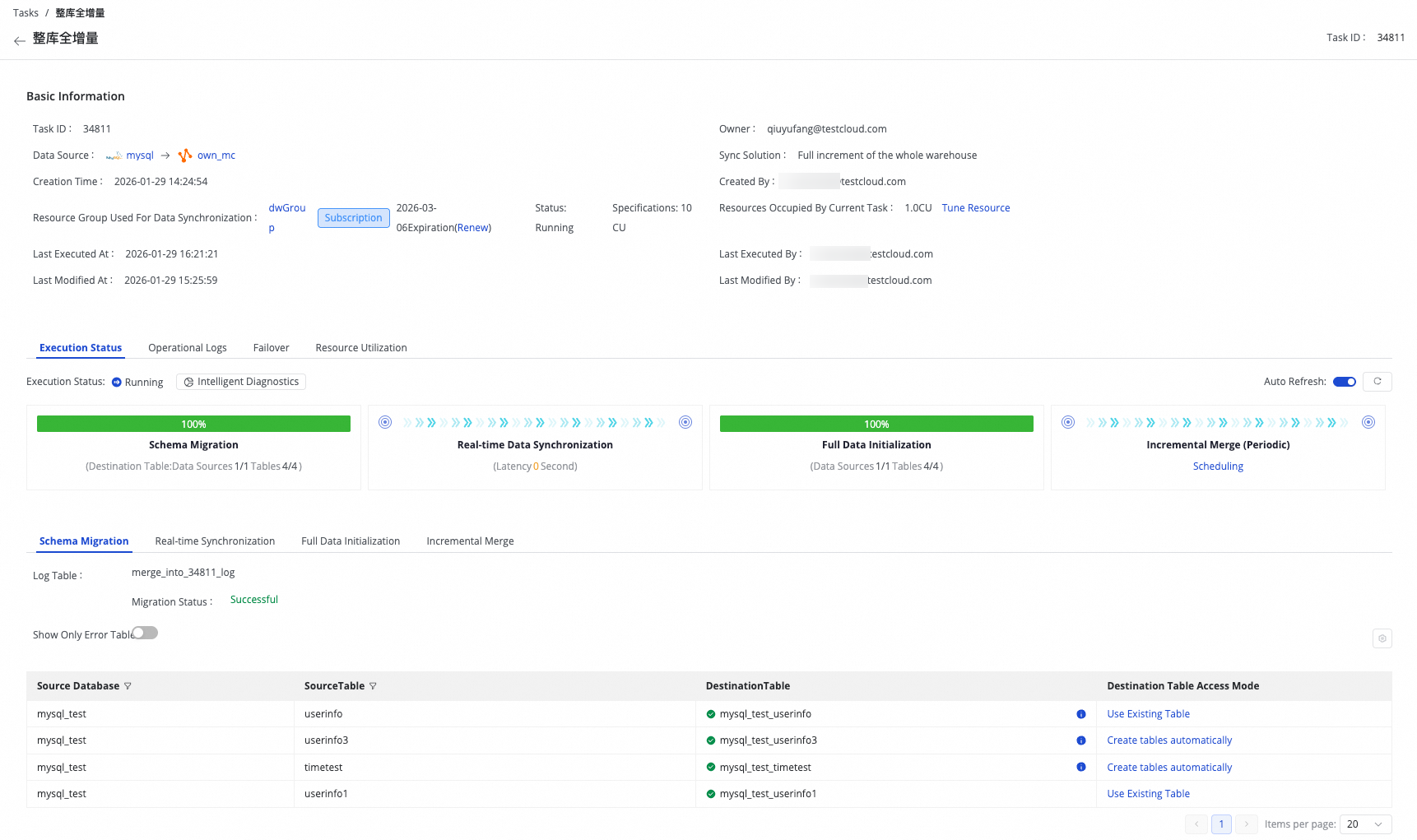
タスクリストページでは、各タスクの基本情報および現在の実行ステータスを確認できます。
タスク実行のステータスには、Schema Migration、Full Initialization、Real-time Data Synchronization、および Incremental Merge の 4 つの段階があります。プログレスバーを使用して、現在の段階および各段階で生成されたサブタスクの実行詳細を確認できます。
Incremental Merge タスクはスケジュールドタスクです。その名前をクリックすると、Operation Center に移動し、対応する定期インスタンスを確認できます。