本トピックでは、MaxCompute の単一テーブルから ApsaraDB for ClickHouse へデータを一括同期する手順を例を用いて説明し、データソースの構成、ネットワーク接続、および一括同期タスクの構成に関するベストプラクティスを紹介します。
ApsaraDB for ClickHouse の概要
ApsaraDB for ClickHouse は、オンライン分析処理(OLAP)向けに設計された列指向データベースです。Data Integration では、ApsaraDB for ClickHouse から他の宛先へのデータ同期および他のソースから ApsaraDB for ClickHouse へのデータ同期がサポートされています。本トピックでは、MaxCompute の単一テーブルから ApsaraDB for ClickHouse へデータを一括同期するエンドツーエンドの例を示します。
制限事項
単一テーブルの一括同期は、ApsaraDB for ClickHouse のみでサポートされています。
前提条件
MaxCompute データソースおよび ApsaraDB for ClickHouse データソース。詳細については、「データソースの構成」をご参照ください。
リソースグループとデータソース間のネットワーク接続。詳細については、「ネットワーク接続ソリューション」をご参照ください。
操作手順
本トピックでは、DataStudio(新バージョン) の UI を使用した一括同期タスクの構成方法を説明します。
ノードの作成とタスクの構成
本トピックでは、コードレス UI を使用したノードの作成および構成に関する一般的な手順の詳細は説明しません。該当情報については、「コードレス UI でのノードの構成」をご参照ください。
ソースおよび宛先の構成
データソースおよびリソースセクションで、ソースをご利用の MaxCompute データソースに、宛先をご利用の ApsaraDB for ClickHouse データソースに設定します。その後、リソースグループを選択して接続性をテストします。
ソース(MaxCompute)パラメーターの構成
ソース MaxCompute テーブルの主なパラメーターについて以下に説明します。
パラメーター | 説明 |
Tunnel Resource Group | デフォルトでは、パブリック伝送リソースが使用されます。ご契約済みの専用トンネルクォータをお持ちの場合は、ドロップダウンリストから選択できます。 |
Table | 同期対象の MaxCompute テーブルを選択します。標準の DataWorks ワークスペースを使用している場合、開発環境および本番環境の両方に、同一の名前およびテーブルスキーマを持つ MaxCompute テーブルが存在することを確認してください。
|
Filtering Method | Partition FilteringおよびData Filterをサポートしています。
|
Partition | Filtering MethodをPartitionに設定した場合、このパラメーターは必須です。パーティション列の値を入力します。
|
If partitions do not exist, | 指定されたパーティションが存在しない場合に適用するポリシーを指定します。有効な値は以下のとおりです。
|
宛先(ApsaraDB for ClickHouse)パラメーターの構成
宛先 ApsaraDB for ClickHouse テーブルの主なパラメーターについて以下に説明します。
パラメーター | 説明 |
Table | データを同期する ApsaraDB for ClickHouse テーブルを選択します。ApsaraDB for ClickHouse データソースのテーブルスキーマは、開発環境および本番環境で同一であることを推奨します。 説明 ここに表示されるのは、開発環境の ApsaraDB for ClickHouse データソースからのテーブル一覧です。開発環境および本番環境のテーブル定義が異なる場合、タスクの構成は正常に完了したように見えても、本番環境への公開後に「テーブルまたはカラムが存在しない」というエラーによりタスクが失敗する可能性があります。 |
Primary or Unique Key Conflict Handling |
|
Statement Run Before Writing | 必要に応じて、データ同期タスクの前後で SQL 文を実行できます。たとえば、日次同期の前に、対応する日次パーティションをクリアする文を実行することで、新規データの書き込み前に空の状態を保証できます。 |
Statement Run After Writing | |
Batch Insert Size (Bytes) | データは ApsaraDB for ClickHouse へバッチ単位で書き込まれます。これらのパラメーターは、1 回のバッチ書き込みにおける最大バイト数およびレコード数を定義します。キャッシュされたデータ量が指定されたバイト数またはレコード数のいずれかに達すると、バッチ書き込みがトリガーされます。 バッチサイズ(バイト)は 16777216(16 MB)に設定し、バッチサイズ(レコード)は単一レコードのサイズに基づいて大きな値に設定することを推奨します。これにより、バッチ書き込みは主にバイト数によってトリガーされます。 たとえば、単一レコードが 1 KB の場合、バッチサイズ(バイト)を 16777216(16 MB)に、バッチサイズ(レコード)を 20000(16 MB ÷ 1 KB = 16384 より大きい値)に設定できます。この場合、バッチサイズが 16 MB に達するたびに書き込みがトリガーされます。 |
Data Records Per Write | |
If a batch write fails | ApsaraDB for ClickHouse へのバッチ書き込み中に発生する例外の処理ポリシーを指定します。
|
フィールドマッピングの構成
ソースおよび宛先を選択した後、ソースカラムと宛先カラムのマッピングを指定する必要があります。Map Fields with the Same Name、Map Fields in the Same Line、Delete All Mappings、またはAuto Layoutを選択できます。
高度な設定
オフライン同期タスク向けの設定(例:Expected Maximum ConcurrencyおよびPolicy for Dirty Data Records)を構成できます。本チュートリアルでは、Policy for Dirty Data RecordsをDisallow Dirty Data Recordsに設定し、その他の設定はデフォルト値を使用します。詳細については、「コードレス UI の構成」をご参照ください。
タスクの構成および実行
一括同期ノードの編集ページ右側にあるRun Configurationをクリックし、デバッグ実行用のResource GroupおよびScript Parametersを構成した後、上部ツールバーのRunをクリックして、同期リンクが正常に動作するかどうかをテストします。
左側ナビゲーションバーの
 をクリックし、Personal Directory の右側にある新規アイコンをクリックして、新しい SQL ファイルを作成します。次の SQL 文を実行して、宛先テーブル内のデータを照会し、データが期待通りであることを確認します。説明
をクリックし、Personal Directory の右側にある新規アイコンをクリックして、新しい SQL ファイルを作成します。次の SQL 文を実行して、宛先テーブル内のデータを照会し、データが期待通りであることを確認します。説明この方法でデータを照会するには、DataWorks 内で ApsaraDB for ClickHouse をコンピューティングリソースとしてバインドする必要があります。
.sqlファイル編集ページの右側にある Run Configuration をクリックし、データソースの Type、Computing Resources、および Resource Group を指定してから、上部のツールバーで Run をクリックします。
SELECT * FROM <your_clickhouse_destination_table_name> LIMIT 20;
スケジュールの構成およびタスクの公開
オフライン同期タスクの右側にあるScheduling Settingsをクリックします。スケジュール実行用のスケジュール構成パラメーターを構成した後、上部ツールバーのPublishをクリックします。公開パネルで、画面上の指示に従って公開を完了します。
付録:メモリパラメーターの調整
同時実行数を増加させても同期スループットが大幅に向上しない場合、同期タスクのメモリパラメーターを手動で調整できます。以下の手順に従います。
オフライン同期タスクページの上部ツールバーにあるCode Editorをクリックして、タスクをコードレス UI からコードエディタに切り替えます。

スクリプトの JSON セグメントの
settingセクションに、jvmOptionパラメーターを追加します。このパラメーターの形式は-Xms${heapMem} -Xmx${heapMem} -Xmn${newMem}です。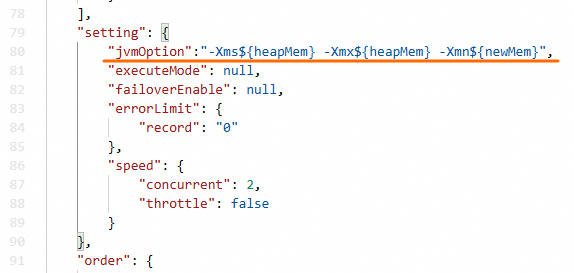
コードレス UI では、${heapMem} の値は、数式 768 MB + (同時実行レベル - 1) × 256 MB を用いて計算されます。コードエディタでは、${heapMem} をより大きな値に設定し、${newMem} を ${heapMem} の 3 分の 1 に設定することを推奨します。たとえば、同時実行レベルが 8 の場合、コードレス UI における ${heapMem} のデフォルト値は 2560 MB ですが、コードエディタではより大きな値(例:3072 MB)に設定できます。この場合、jvmOption パラメーターを -Xms3072m -Xmx3072m -Xmn1024m に設定できます。