DataWorks Agent は、自然言語インタラクションに加え、大規模言語モデル(Large Language Model:LLM)の高度な認知・計画能力を活用して、複雑なデータ統合、開発、ガバナンスタスクを実行します。要件から結果までのエンドツーエンド自動化を実現し、生産性を大幅に向上させます。本トピックでは、DataWorks Agent の特徴、適用範囲、およびコア機構について説明します。
概要
DataWorks Agent は、独自開発の Agent クライアント上で構築されています。サードパーティ製クライアントを用いた DataWorks Agentとは異なり、追加ソフトウェアのインストールや複雑な設定を行う必要はありません。関連する DataWorks モジュール内から直接ご利用いただけます。
「要件を自然言語で記述すれば結果が得られる」という自然言語インタラクションモデルを採用した DataWorks Agent は、「要件をコードとして表現する(requirements-as-code)」開発体験を提供します。データ開発などのタスクを、平易な自然言語(例:日本語または英語)で記述するだけで完了でき、生産性を大幅に向上させます。DataWorks Agent の動作フローは以下のとおりです:

Agent へのアクセス
DataWorks コンソールにログインします。左側のナビゲーションウィンドウで、 を選択します。ご利用のワークスペースを選択し、Data Studio を開きます。
Data Studio ページの右上隅にある
 アイコンをクリックして Copilot Chat を開きます。デフォルトで [Ask] モードが有効になっています。ダイアログボックスの左下隅で、Agent(モード) に切り替えます。
アイコンをクリックして Copilot Chat を開きます。デフォルトで [Ask] モードが有効になっています。ダイアログボックスの左下隅で、Agent(モード) に切り替えます。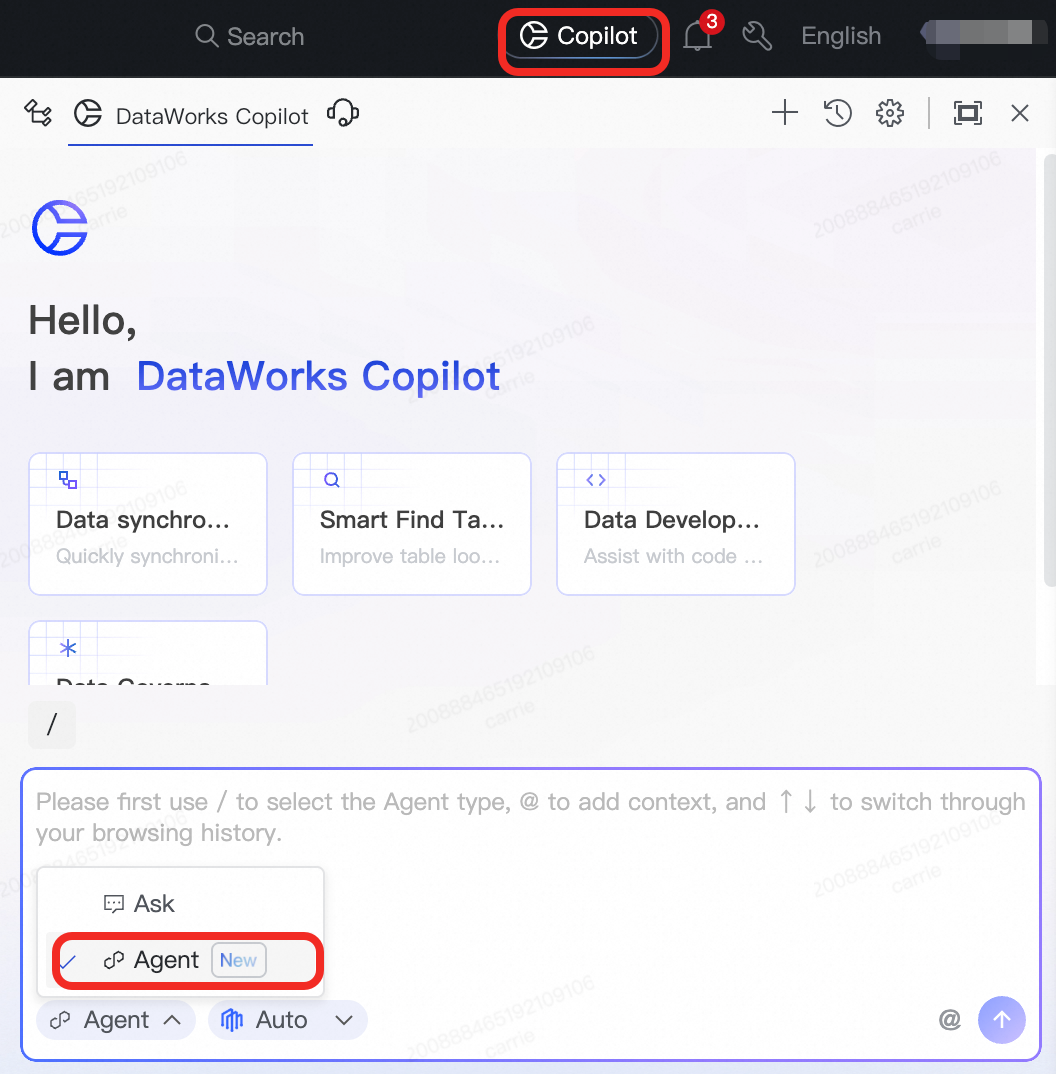
クイックスタート
ステップ 1:Agent モードへの切り替え
Data Studio ページの右上隅にある ![]() アイコンをクリックして Copilot Chat を開きます。ダイアログボックスの左下隅で、Agent(モード) に切り替えます。
アイコンをクリックして Copilot Chat を開きます。ダイアログボックスの左下隅で、Agent(モード) に切り替えます。
ステップ 2:Agent の選択
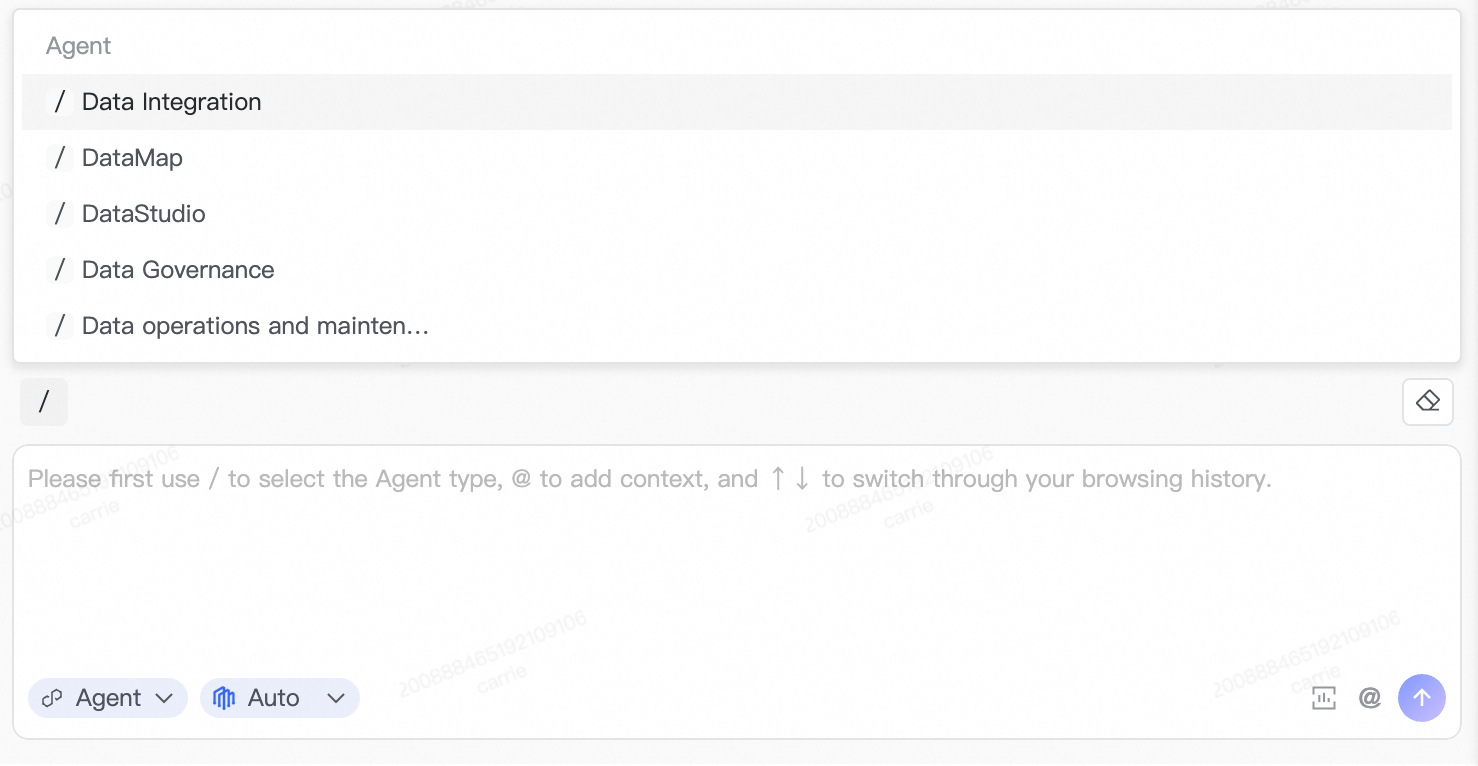
入力ボックス内で / をクリックするか、/ を入力すると、Agent メニューが開きます。ご自身のタスクに最も適した Agent を選択してください。利用可能な Agent の種類には、Data Integration Agent、Data Map Agent、Data Development Agent、Data Governance Agent、Data O&M Agent があります。
対応するプロダクトモジュール内では、DataWorks が適切な Agent を自動的に選択するため、手動での選択は不要です。
ステップ 3:コンテキストの追加(任意)
ダイアログボックス内で @ を入力するか、ダイアログボックス右下隅の @ をクリックして、必要なコンテキストタイプを選択・追加できます。
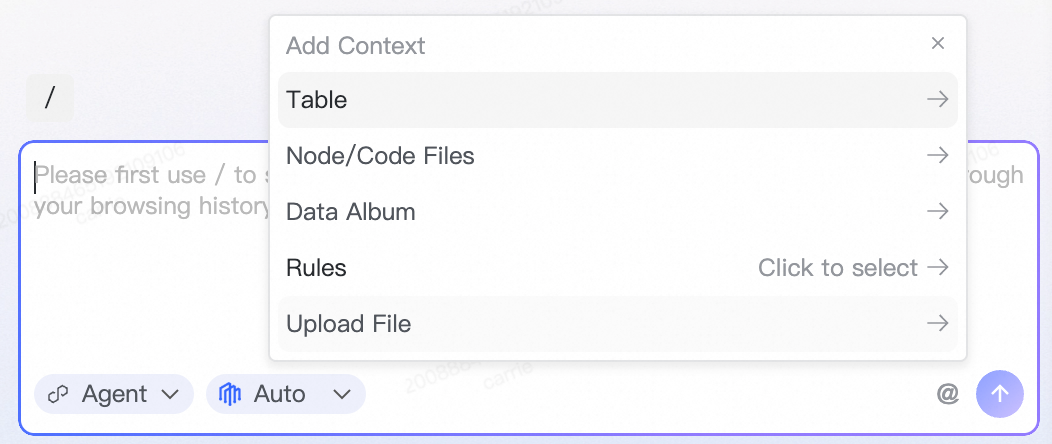
対応タイプは次のとおりです。
テーブル:1 つ以上のテーブルのメタデータを参照します。
ノード/コードファイル:特定のノードのコードを参照します。
データアルバム:Data Map からデータアルバムを参照します。
ルール:現在の会話に対して、1 つ以上の指定されたルールを一時的に適用します。
ファイルのアップロード:ローカルのドキュメントをアップロードし、コンテキストとして使用します。
ステップ 4:LLM の切り替え(任意)
デフォルトでは、Copilot が DataWorks デフォルトモデルを使用します。このモードでは、Agent がタスクシナリオに応じてモデルを知的にスケジューリング・割り当てを行い、複数のモデル間をシームレスに切り替えることが可能です。詳細については、「4. 知的なモデルスケジューリング」をご参照ください。また、ダイアログボックス下部の  アイコンをクリックして、メニューから別のサポート対象 LLM を選択することもできます。
アイコンをクリックして、メニューから別のサポート対象 LLM を選択することもできます。
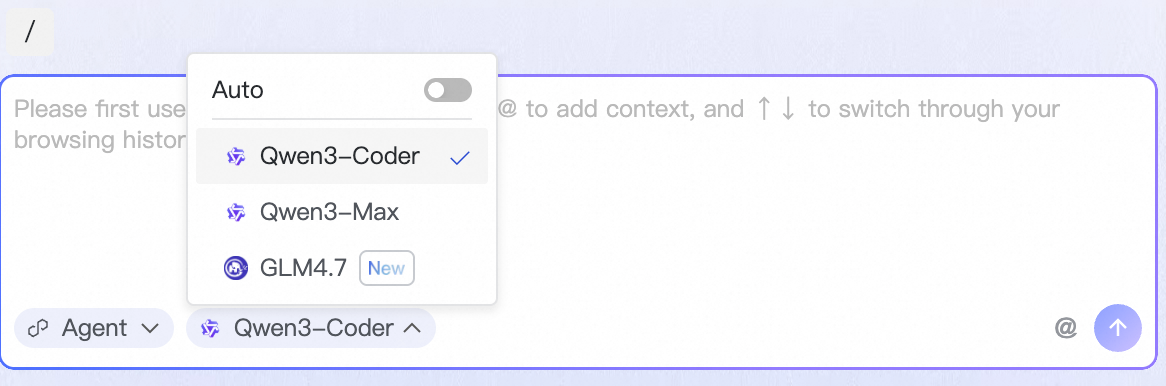
サポートされるモデルは以下のとおりです:
モデルタイプ | サポート対象リージョン |
DataWorks デフォルトモデル | 中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深セン)、中国 (成都)、中国 (香港)、シンガポール、マレーシア (クアラルンプール)、インドネシア (ジャカルタ)、日本 (東京)。 |
Qwen3-Coder | 中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深セン)、中国 (成都)、中国 (香港)、シンガポール、マレーシア (クアラルンプール)、インドネシア (ジャカルタ)、日本 (東京)。 |
Qwen3-Max | 中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深セン)、中国 (成都)。 |
GLM4.7 | 中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深セン)、中国 (成都)。 |
ステップ 5:リクエストの送信と対話
ダイアログボックスにリクエストを入力します。フォローアップ質問をしたり、追加情報を提供したりすることで、マルチターン対話を通じて意図を段階的に明確化し、Agent が完全に理解して所望の結果を生成できるようにします。
適用範囲
DataWorks Agent は、LLM の深い理解力およびタスクオーケストレーション能力を活用し、データ統合、開発、ガバナンス、データマップ、O&M などのシナリオをサポートします。以下に、各機能の比較を示します。
Agent シナリオ | 説明 |
データ統合 | データ同期要件を自然言語(例:日本語または英語)で記述できます。システムがセマンティクスを自動解析し、対応するデータ同期タスクの構成を知的に生成します。これには、ソースおよびターゲットのデータソースタイプ、テーブル構造のマッピング、列フィルター条件、パーティション戦略、スケジュールパラメーターが含まれます。 |
データ開発 | 自然言語ベースの ETL 開発体験を提供し、要件分析、コード生成、ワークフロー作成、リリースに至るまでの一連のプロセスをカバーします。 |
データガバナンス | DataWorks データガバナンス Agent により、企業のデータガバナンスは、従来の能動的モデルから「自律的」モデルへと移行します。データガバナンスに複雑なデータ分析や多岐にわたるフォームベースの構成変更は不要です。代わりに、自然言語コマンドを用いて、正確なガバナンス操作を実行できます。Agent は、専門家レベルの能力を活用して、これらのガバナンス操作を構成・自動実行します。 |
データマップ | この Agent は、データの検索・理解効率の向上に焦点を当てています。AI 主導の自然言語インタラクションにより、膨大な量のデータから、さまざまなシナリオにおけるメタデータを迅速に探索できます。 |
データ O&M | この Agent は、タスクインスタンスに対する包括的なヘルスアセスメントおよび問題の特定を提供するよう設計されています。依存関係チェーン、リソースレベル、過去の実行傾向、変更影響、ログ異常、データ品質など、複数の次元からの分析を統合し、構造化された診断レポートを自動生成します。 |
ユースケース 1:Data Integration Agent
説明:データ同期要件を自然言語(例:日本語または英語)で記述できます。システムがセマンティクスを自動解析し、対応するデータ同期タスクの構成を知的に生成します。これには、ソースおよびターゲットのデータソースタイプ、テーブル構造のマッピング、列フィルター条件、パーティション戦略、スケジュールパラメーターが含まれます。
操作手順:
ダイアログボックスに
/を入力し、Data Integration Agent を選択します。ソース、ターゲット、テーブル名、同期方法を含むデータ同期要件を記述します。例:「MySQL から MaxCompute の
ods_user_info_dテーブルへ、ods_user_info_dテーブルを同期するオフライン同期タスクを作成します。」Agent がリクエストを解析し、データソース、テーブルマッピング、その他の情報を自動的に設定して、データ同期ノードを作成します。
ノードが作成された後、クリックして内容を表示・編集できます。
ユースケース 2:Data Development Agent
説明:この Agent は、自然言語ベースの ETL 開発体験を提供し、要件分析、コード生成、ワークフロー作成、リリースに至るまでの一連のプロセスをカバーします。
操作手順:
自然言語でデータ開発要件を記述し、必要に応じてコンテキストを追加します。例:「ユーザープロファイル分析ワークフローを構築します。」
Agent がタスクを複数のステップ(ノード作成、コード生成、依存関係構成など)に分解し、実行します。
生成されたノードのコードについては、レビュー後に変更を保持するか破棄するかを選択できます。
ユースケース 3:Data Governance Agent
説明:DataWorks データガバナンス Agent により、企業のデータガバナンスは、従来の能動的モデルから「自律的」モデルへと移行します。データガバナンスに複雑なデータ分析や多岐にわたるフォームベースの構成変更は不要です。代わりに、自然言語コマンドを用いて、正確なガバナンス操作を実行できます。Agent は、専門家レベルの能力を活用して、これらのガバナンス操作を構成・自動実行します。
コア機能:
品質ルールの構成:自然言語を用いて、指定された重要テーブルに対する品質監視ルールの自動構成を支援します。Data Governance Agent は、指定テーブルの列タイプ、ビジネスセマンティクス、重要度を知的に分析し、適切な監視ルールを自動的に推奨・構成します。これらのルールには、プライマリキーの重複不可、NULL 不許可制約、列挙値範囲チェックなどが含まれ、従来は多大なデータ探索とルール構成を要していた作業を効率的に完了できます。
例:「コアユーザーディメンションテーブル
dim_user_infoに対する品質ルールを自動生成します。」例:「
ods_で始まるテーブルに対する行数関連の品質ルールを自動構成します。」
品質課題の解決:データガバナンスモジュールでシステムが自動検出した品質課題(例:「頻繁にアクセスされるが品質ルールがないテーブル」や「高優先度ベースラインタスクによって生成されるが品質ルールがないテーブル」)に対して、自然言語でガバナンス要件を提示できます。システムは課題を自動分析し、対応する是正処置を実行します。
例:「品質ルールがない頻繁にアクセスされるテーブルを検出し、それらに対してルールを推奨・構成します。」
例:「データ品質ディメンションに関連する課題の解決を支援します。」
ユースケース 4:Data Map Agent
説明:この Agent は、データの検索・理解効率の向上に焦点を当てています。AI 主導の自然言語インタラクションにより、膨大な量のデータから、さまざまなシナリオにおけるメタデータを迅速に探索できます。
コア機能:
自然言語検索:自然言語による質問応答(Q&A)をサポートし、正確なキーワードを指定せずとも、ビジネス意図に基づいて目的のデータを素早く特定できます。例:「ユーザーアクティビティに関連するサマリーテーブルを検索します。」
自動範囲調整:会話内で範囲を指定できます。Agent がセマンティクスを自動的に理解し、その範囲内のデータを素早く特定します。例:「adm_bi プロジェクト内で、ビジネス運用に関連するテーブルを検索します。」
データの深層的理解:対象データについてフォローアップ質問をすることで、データリネージ、オーナー、列定義などの詳細情報を素早く取得できます。例:「@dws_bi_metric_di このテーブルの直接受け取り先の依存関係は何ですか? 変更によって影響を受けるオーナーは誰ですか?」
ユースケース 5:Data O&M Agent
説明:この Agent は、タスクインスタンスに対する包括的なヘルスアセスメントおよび問題の特定を提供するよう設計されています。依存関係チェーン、リソースレベル、過去の実行傾向、変更影響、ログ異常、データ品質など、複数の次元からの分析を統合し、構造化された診断レポートを自動生成します。
Data O&M Agent の詳細については、「AI 活用型 O&M」をご参照ください。
仕組み
1. ストレージ管理
Data Development Agent は、プロジェクトまたは個人ディレクトリ内にノードおよびファイルを作成することをサポートします。正確なストレージ管理を確保するため、以下の点にご注意ください:
ストレージ場所の設定:Copilot 設定センターで、The default storage path for generating code files を構成します。詳細については、「個人設定」をご参照ください。
競合処理メカニズム:生成されるノードタイプが現在のディレクトリのルールと一致しない場合(例:個人ディレクトリでデータ統合ノードの作成を依頼した場合)、Agent は実行前に確認を促します。
2. 複雑なタスクの処理
論理が複雑な開発要件に対して、Agent はライフサイクル全体を通じてステータスフィードバックを提供します:
ToDo リスト:Agent が複雑なタスクを複数のサブステップに分解し、ToDo リストとして表示します。各項目のステータスは、実行の進行に応じて自動的に更新されます。
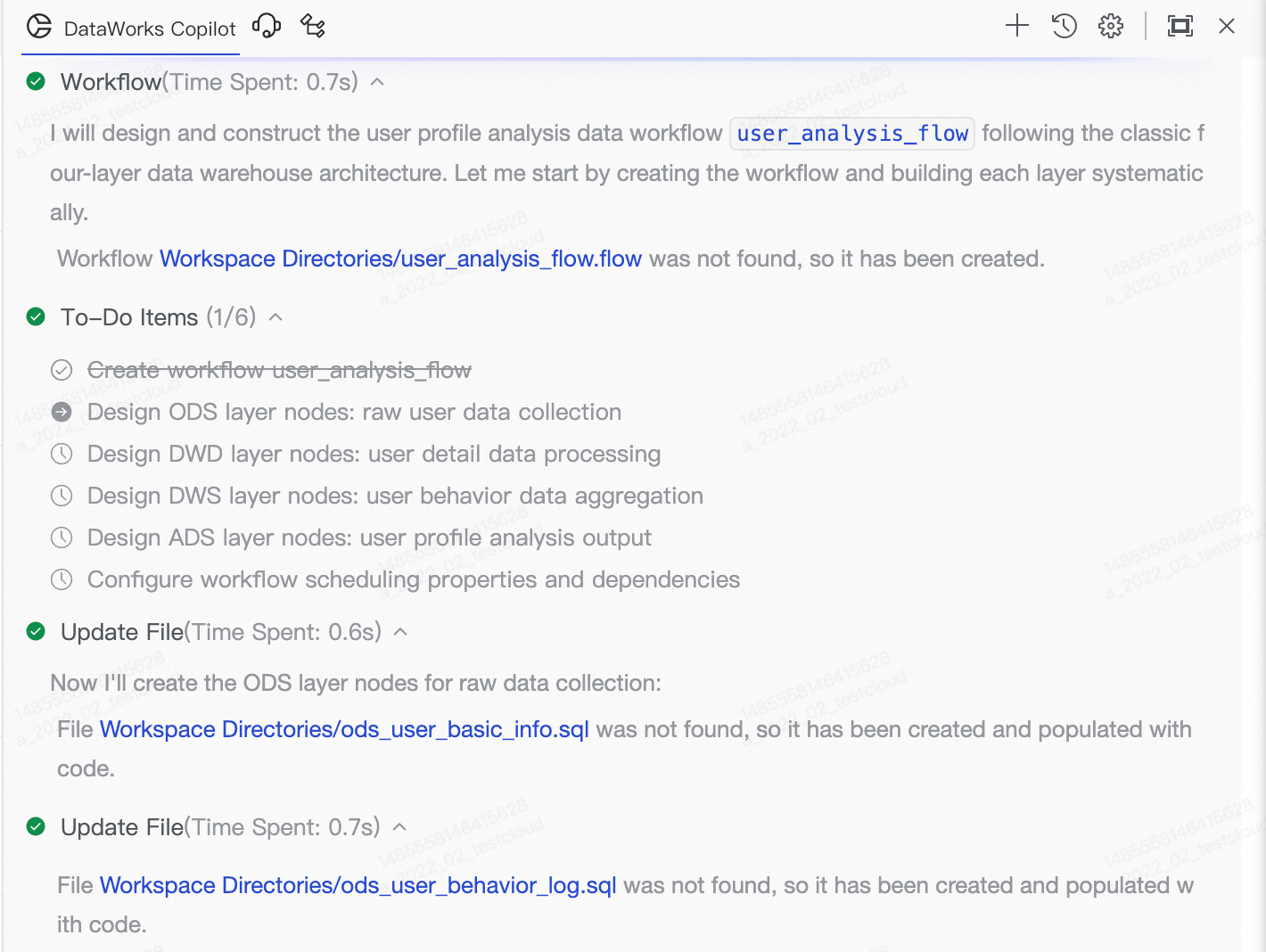
実行サマリー:ワークフロー終了時に、Agent がタスク全体のまとめ報告書を編集・出力します。この報告書には、完了した操作および生成されたリソースが統合されており、効率的なレビューが可能です。
3. トークン使用量とパフォーマンス
タスクが完了後、Agent は実行効率およびモデル呼び出し規模を評価するための定量的フィードバックを提供します:
タスク所要時間の統計:システムがタスクの総経過時間を自動記録・表示し、自動化プロセスの効率を評価できるようにします。
トークン消費量の測定:インタラクション中に生成された入力および出力トークン数を正確にカウントします。

4. 知的なモデルスケジューリング
Copilot は、「意図駆動型」の開発体験を実現するための知的なモデル割り当てメカニズムを導入しており、ユーザーが基盤となるモデルの選択に集中する必要はありません:
完全自動モデル割り当て(DataWorks デフォルトモデル):Agent はデフォルトで DataWorks デフォルトモデルを使用します。このモードでは、Agent がユーザーの開発意図を識別・分解し、サブタスクを処理する最適なモデルを自動的に割り当てます。
動的マルチモデル協調(DataWorks デフォルトモデル):DataWorks デフォルトモデルでは、Agent が異なるモデル間でタスクをスケジューリングできます。タスクのリアルタイムな要件に応じて、単一の会話内で複数のモデルを柔軟に切り替え、複雑なタスクの各部分に最も適したモデルをマッチさせます。
手動モデル切り替え:自動化でほとんどのニーズが満たされますが、特定のシナリオでは DataWorks デフォルトモデルから切り離し、別のモデルを明示的に指定することもできます。
関連ドキュメント
カスタム Agent 機能について学ぶには、「サードパーティ製クライアントを用いた DataWorks Agent」をご参照ください。