ChatBI の会話を開始する前に、分析対象のデータを定義するためのデータセットを作成する必要があります。データセットは、データソースのテーブルまたはローカルファイルにすることができます。
前提条件
ChatBI を使用するリージョンと同じリージョンに、サーバーレスリソースグループが必要です。
注意事項
-
データソースからのデータセットの場合、ChatBI は Hologres、MaxCompute、StarRocks、MySQL のみをサポートします。
-
ローカルファイルからのデータセットの場合、
xls、xlsx、csv形式のみがサポートされています。最大 10 個のファイルをアップロードでき、各ファイルのサイズは 1 GB を超えることはできません。
データセットの作成
-
ChatBI ページに移動します。
Alibaba Cloud にログインし、ChatBI インテリジェントデータインサイトページを開きます。データセットやサーバーレスリソースグループなど、ご利用の DataWorks リソースのリージョンに一致するアクセスポイントを選択します。
-
左側のナビゲーションウィンドウで Dataset をクリックしてデータセットページに移動します。次に、Create Dataset をクリックします。
-
Create Dataset ページで、次のパラメーターを構成します。
-
データセットタイプが Data Source の場合:
パラメーター
説明
Basic Information
Name
データセットのカスタム名を入力します。
Type
データセットのタイプ。有効な値:
-
Data Source
-
Local File
この例では、Data Source が選択されています。
Data Source Type
データソースのタイプ。有効な値:
-
Hologres
-
MaxCompute
-
StarRocks
-
MySQL
データソース情報
構成パラメーターはデータソースタイプによって異なります。
たとえば、Hologres を選択した場合は、Region、Hologres Instance、Database Name を構成する必要があります。
Resource Group
このリソースグループは、データソースにアクセスし、後続の会話でクエリを実行するために使用されます。
Test Network Connectivity
選択した DataWorks サーバーレスリソースグループとデータソース間の接続を検証します。
Select Destination Table
ターゲットテーブルの選択
Basic Information を構成した後、Next をクリックして Select Destination Table ステップに進みます。
To Be Selected リストで、ターゲットデータテーブルを選択し、
 アイコンをクリックして Selected リストに追加します。
アイコンをクリックして Selected リストに追加します。 -
-
データセットタイプが Local File の場合:
パラメーター
説明
Basic Information
Name
データセットのカスタム名を入力します。
Type
データセットのタイプ。有効な値:
-
データソース
-
ローカルファイル
この例では、Local File が選択されています。
ローカルファイルのアップロード
xls、xlsx、csv形式のローカルファイルをアップロードできます。最大 10 個のファイルをアップロードでき、各ファイルのサイズは 1 GB を超えることはできません。 -
-
-
データセットを構成した後、Next をクリックして Data Insight ステップに進みます。ChatBI はデータセットを自動的にスキャンしてその特徴を特定し、後続の会話での分析精度を向上させます。
-
データインサイトのプロセスには時間がかかる場合があります。Completed をクリックして、後でデータセットの詳細ページで結果を表示できます。
データセットの表示
-
左側のナビゲーションウィンドウで Dataset をクリックしてデータセットページに移動します。
-
ターゲットデータセットカードを見つけてクリックし、データセットの詳細ページを開きます。
-
データセットの詳細ページの上部には、タイプ、作成者、テーブルまたはファイルの数などの基本情報が表示されます。左側にはテーブルまたはファイルのリストがあり、右側には選択したアイテムの詳細とデータプレビューが表示されます。最大 20 件のデータレコードをプレビューできます。
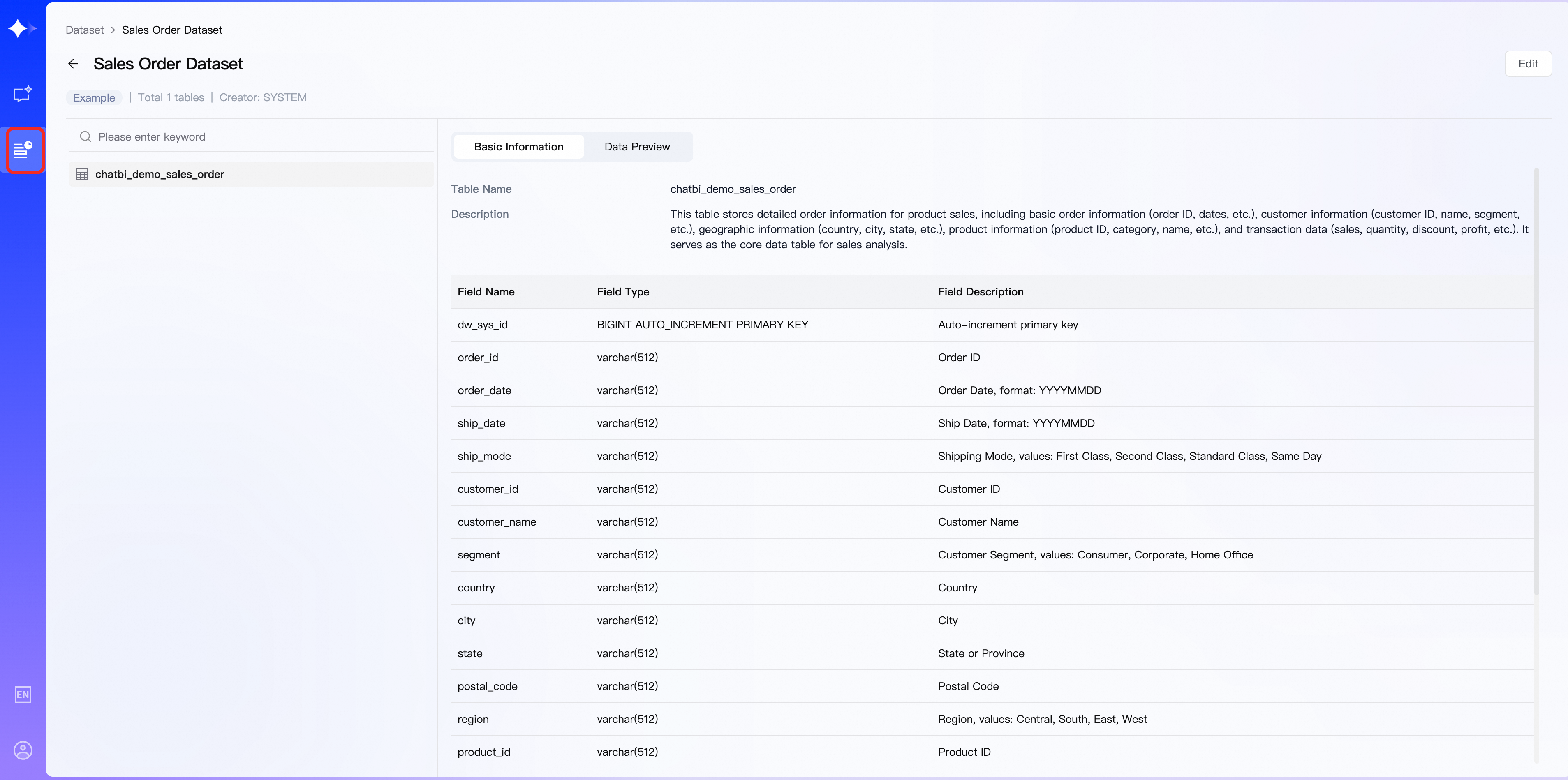
データセットの編集
-
左側のナビゲーションウィンドウで Dataset をクリックしてデータセットページに移動します。
-
データセットの編集ページは、2 つの方法で開くことができます。
-
ターゲットデータセットカードにカーソルを合わせ、右上隅にある
 > Edit をクリックします。
> Edit をクリックします。 -
ターゲットデータセットカードをクリックして詳細ページに移動し、右上隅にある Edit ボタンをクリックします。
-
-
データセットの構成を変更します。パラメーターの詳細については、「データセットの作成」をご参照ください。
説明既存のデータセットを編集する場合、[タイプ] および [データソースタイプ] パラメーターは変更できません。
-
データセットの編集が完了したら、[次へ] をクリックして [データインサイト] ステップに進み、データセットでデータインサイトを再実行します。
データセットの削除
-
左側のナビゲーションウィンドウで Dataset をクリックしてデータセットページに移動します。
-
ターゲットデータセットカードにカーソルを合わせ、右上隅にある
> Delete をクリックします。データセットを削除すると、関連付けられた会話とチャートはデータを表示できなくなります。
次のステップ:データセットからの会話の開始
-
データセットから会話を開始するには、2 つの方法があります。
-
左側のナビゲーションウィンドウで Dataset をクリックしてデータセットページに移動します。ターゲットデータセットカードにカーソルを合わせ、右上隅にある
 アイコンをクリックしてチャットを開始します。
アイコンをクリックしてチャットを開始します。 -
左側のナビゲーションウィンドウで [新規チャット] をクリックして ChatBI セッションウィンドウを開きます。セッションウィンドウで、Select Dataset をクリックします。

-
-
Chat ページで、要件や質問を入力してデータ分析を開始します。詳細については、「ChatBI の会話」をご参照ください。
質問のヒント
ChatBI の分析の質は、質問の方法によって決まります。以下のヒントは、より正確で価値のあるデータ分析結果を得るのに役立ちます。
明確な分析目標の定義
良い分析の質問には、明確な主題、具体的なメトリック、定義されたディメンションが含まれている必要があります。
|
適切な形式の質問 |
曖昧な質問 |
|
2025年の華東リージョンにおける月次売上動向 |
売上高を見せてください |
|
過去 7 日間の日次新規ユーザーとその前年比成長率 |
最近のユーザーグロースはどうですか? |
|
返品率による製品カテゴリトップ 10 と返品理由の分布 |
返品は多いですか? |
時間範囲とフィルター条件の使用
質問で時間範囲とフィルター条件を指定すると、ChatBI がより正確な SQL を生成し、不要な全表スキャンを回避するのに役立ちます。
-
時間範囲の指定:たとえば、「2025年第4四半期の各製品ラインの売上総利益」は、「各製品ラインの売上総利益」よりも正確で、クエリされるデータ量を削減します。
-
フィルターディメンションの指定:たとえば、「華北リージョンの VIP 顧客の平均取引額の分布」は、「平均取引額はいくらですか」よりもターゲットが絞られています。
-
ビジネス用語の使用:質問する際は、データテーブルの実際のフィールド値やナレッジベースで定義されたビジネス用語を使用します。たとえば、「完了した注文」の代わりに
status='completed'を使用すると、ChatBI がデータを正確に照合するのに役立ちます。
複雑なリクエストのステップへの分割
複雑な分析の場合は、リクエストを一連の簡単なステップバイステップの質問に分割します。
-
ステップ 1:概要の把握:全体的な傾向を理解するために、大まかな質問から始めます。例:「2025年の月別全体売上動向」。
-
ステップ 2:アノマリーの特定:アノマリーを見つけたら、ターゲットを絞ったフォローアップ質問をします。例:「3月の売上減少の理由を製品カテゴリ別に分析してください」。
-
ステップ 3:アトリビューション分析の実行:主要な発見の原因をさらに調査します。例:「3月に最も減少が大きかった電子機器カテゴリのサブカテゴリはどれですか?」。
マルチターン対話テクニックの使用
ChatBI は、同じ会話内での連続したマルチターン対話の質問をサポートしています。以下のテクニックは、マルチターン分析をより効率的に実行するのに役立ちます。
-
詳細についてのフォローアップ質問:前のターンの結果に基づいて構築します。たとえば、最初に「リージョン別の売上ランキング」を質問し、次に「ランキングトップのリージョンの月次売上詳細」をフォローアップします。
-
命令の修正:分析結果が期待どおりでない場合は、次のターンで必要な調整を指定できます。たとえば、「上記の結果を月別ではなく四半期別に要約してください」や「テストデータを除外し、公式の注文のみを表示してください」などです。
-
可視化の切り替え:同じデータを異なる方法で表示するようにリクエストできます。たとえば、「上記のデータを円グラフで表示してください」や「降順でソートしてください」などです。
不正確な結果への対処
ChatBI が不正確な結果を返した場合は、次の方法をお試しください。
-
テーブルのマッチングを確認する:分析結果の「ターゲットテーブルの特定」ステップで、ChatBI が正しいデータテーブルを選択したことを確認します。ChatBI が間違ったテーブルを照合した場合は、質問でテーブル名を指定できます。例:「ods_order_detail テーブルに基づいてカテゴリ別の売上を分析してください」。
-
質問を洗練させる:より正確なビジネス用語と明確なメトリック定義を使用して質問を言い換えます。たとえば、「アクティブユーザーは何人いますか?」を「過去 30 日間にログインアクティビティがあったユニークユーザー数をカウントしてください」に変更します。
-
ナレッジベースを改善する:特定の種類の質問で一貫して不正確な結果が得られる場合は、管理者が対応する質問テンプレート、用語、またはビジネスロジックをナレッジベースに追加することを推奨します。ChatBI は、ナレッジベースの情報を優先して、そのような質問を理解し、処理します。
-
生成された SQL を確認する:「実行計画の生成」ステップで SQL コードを展開し、クエリロジックが正しいかどうかを確認します。問題がある場合は、SQL をコピーして手動で修正し、実行できます。また、修正した SQL を質問テンプレートとしてナレッジベースに追加することもできます。
データソースの構成
MySQL
-
全表スキャンのリスク:ChatBI が質問に基づいて生成する SQL は、全表スキャンを実行する可能性があります。テーブルに大量のデータ (数百万行以上) が含まれている場合、データベースに高い負荷がかかる可能性があります。本番環境への影響を避けるため、データセットのデータソースとして読み取り専用レプリカまたはセカンダリデータベースを使用することを強く推奨します。
-
インデックスの最適化:時間、ステータス、カテゴリ列など、頻繁にクエリされるフィルターフィールドにインデックスを作成して、ChatBI が生成する SQL の実行を高速化します。
-
フィールドの命名:
order_amountやcustomer_nameなど、明確なビジネス上の意味を持つ英語のフィールド名を使用し、フィールドコメントを追加します。ChatBI は、フィールド名とコメントに依存してテーブル構造を理解します。適切な命名は、ターゲットテーブルのマッチングと SQL 生成の精度を大幅に向上させることができます。 -
利用シーン:オンラインビジネスデータの注文分析や顧客管理など、データ量が最大数千万行のビジネスデータベースクエリシナリオに適しています。
Hologres
-
パーティションテーブルの設計:パーティションテーブルを使用し、日付や月などの時間でパーティション分割することを推奨します。パーティションテーブルをクエリする場合、ChatBI が生成する SQL は自動的にパーティションプルーニングを実行できるため、スキャンされるデータ量が大幅に削減され、クエリ範囲が広すぎることによるクエリのタイムアウトを防ぐのに役立ちます。
-
テーブルとカラムのコメント: Hologres では、テーブルとカラムに
COMMENTを追加できます。 ChatBI はこれらのコメントを読み取り、データのセマンティクスを理解します。 各テーブルとキーフィールドに、そのビジネス上の意味を記述する中国語のコメントを追加することをお勧めします。 -
行と列のハイブリッドストレージ:主に集計分析を伴う ChatBI のクエリシナリオでは、クエリパフォーマンスを向上させるためにカラムナストレージを使用することを推奨します。
-
利用シーン:リアルタイムおよびニアリアルタイムのデータ分析シナリオに適しています。数億行のデータに対するインタラクティブなクエリをサポートし、特にリアルタイムダッシュボードやリアルタイムメトリック分析に適しています。
MaxCompute
-
パーティションプルーニング:MaxCompute は大規模データ処理エンジンであり、1 回のクエリで大量のデータをスキャンする可能性があります。パーティションテーブルを使用し、日付やリージョンなど、頻繁に使用されるフィルターディメンションをパーティションキーとして使用することを強く推奨します。ChatBI が SQL を生成する際、パーティション条件を使用して不要な全表スキャンを削減しようとします。
-
クエリ応答時間:MaxCompute はオフラインバッチ処理エンジンであり、クエリ応答時間は通常、データ量とクエリの複雑さに応じて数秒から数分かかります。秒単位の応答が必要な場合は、Hologres または StarRocks を使用することを推奨します。
-
SQL 方言の違い:MaxCompute は独自の SQL 方言を使用しており、一部の関数と構文は標準 SQL とは異なります。ChatBI は MaxCompute SQL 構文に適応し、準拠した SQL を自動的に生成します。生成された SQL クエリがエラーを返す場合は、ナレッジベースに質問テンプレートを追加して、正しい SQL 生成をガイドできます。
-
利用シーン:既存データの傾向分析や包括的なユーザー行動分析など、テラバイトからペタバイト規模の大規模なオフラインデータ分析シナリオに適しています。
StarRocks
-
MPP アーキテクチャの特徴:StarRocks は超並列処理 (MPP) アーキテクチャを使用し、多次元分析と複雑な集計クエリに優れています。ChatBI の多次元分析の質問は、通常 StarRocks で良好なパフォーマンスを発揮します。
-
マテリアライズドビュー:特定の集計クエリが頻繁に行われる場合は、StarRocks でマテリアライズドビューを作成して高速化することを推奨します。ChatBI は自動的にマテリアライズドビューを使用してクエリパフォーマンスを向上させます。
-
データモデリング:StarRocks は、Duplicate Key、Aggregate、Unique Key、Primary Key モデルなど、さまざまなデータモデルをサポートしています。ChatBI 分析シナリオでは、Duplicate Key モデルは柔軟な多次元分析に適しており、Aggregate モデルは固定メトリックのクエリシナリオに適しています。実際の分析ニーズに基づいて適切なモデルを選択してください。
-
利用シーン:リアルタイムの多次元分析およびアドホッククエリシナリオに適しています。数億行のデータ量に対して秒単位のクエリ応答をサポートし、特にユーザー行動分析やリアルタイムレポートに適しています。