DataWorks のデータ資産ガバナンスプラグインは、DataStudio に組み込まれた AI 駆動のツールです。リアルタイムでコードの問題を特定・修正し、コードの品質とデータセキュリティの両方を向上させます。
概要
データ開発の問題診断機能は、リアルタイム構文診断 (LSP) と開発ヘルスチェックという 2 つのコア機能を統合しています。これらの機能が連携して、コードの品質を保証します。
機能 | リアルタイム構文診断 (LSP) | 開発ヘルスチェック |
主な責務 | リアルタイムの構文チェックと静的コード解析。 | データ標準、セキュリティ、パフォーマンスの問題に対するルールベースのチェック。 |
トリガー | コード編集中にリアルタイムでトリガーされます。 |
|
解決される問題 | SQL 構文エラー、不正な関数使用など。 | この機能は、不適切なパーティションの使用、プロジェクト間の書き込み、JOIN 列の型の不一致などの問題をカバーする組み込みルールライブラリを提供します。また、DataWorks Copilot を利用したカスタムルールライブラリもサポートしています。 |
修正方法 | DataWorks Copilot による修正支援。 | AI による修正提案とクイック修正を提供します。 |
コードに構文エラーがある場合、リアルタイム構文診断 (LSP) のみがトリガーされます。開発ヘルスチェックは、すべての構文エラーを解決した後にのみ実行されます。
チェックに失敗しても、コードの実行には影響しません。
利用可能なリージョン
詳細スキャンは、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深セン)、中国 (成都)、中国 (香港)、およびシンガポールのリージョンでのみサポートされています。
詳細スキャン以外の機能は、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (ウランチャブ)、中国 (深セン)、中国 (成都)、中国 (香港)、シンガポール、マレーシア (クアラルンプール)、インドネシア (ジャカルタ)、ドイツ (フランクフルト)、米国 (シリコンバレー)、および米国 (バージニア) のリージョンでのみサポートされています。
クイックスタート
以下の手順に従って、5 分以内にコードの問題診断と修正のコアワークフローを体験してください。
品質チェック機能の有効化
DataWorks の DataStudio に移動し、左側のナビゲーションウィンドウの下部にある
 > Setup をクリックし、Setup ページの User タブに移動します。
> Setup をクリックし、Setup ページの User タブに移動します。Data Governance>DataStudio Governance Check Module EnablementとLspSetting>SyntaxErrorEnableの両方が選択されている (デフォルトで有効) ことを確認します。説明DataStudio Governance Check Module Enablement はデータ資産ガバナンスプラグインのチェック機能を制御し、SyntaxErrorEnable はリアルタイム構文診断機能を制御します。これらは異なるレベルのコード品質チェックを担当しており、完全な問題診断機能を利用するには両方を有効にする必要があります。
問題のあるサンプルコードの作成
MaxCompute ODPS SQL ノードを作成し、エラーを含む次のサンプルコードをエディターに貼り付けます。
-- 例:SQL でテーブルを作成 CREATE TABLE IF NOT EXISTS my_partitioned_table ( id STRING, name STRING, value BIGINT ) PARTITIONED BY (ds STRING) LIFECYCLE 365; -- 例:構文エラー SELEC name FROM my_partitioned_table;LSP 構文問題の特定
LSP はリアルタイムで問題を検出します。
SELECに赤い波線が表示され、構文エラーを示します。ページ左下の アイコンをクリックし、[問題] パネルでコードの問題を表示します。
アイコンをクリックし、[問題] パネルでコードの問題を表示します。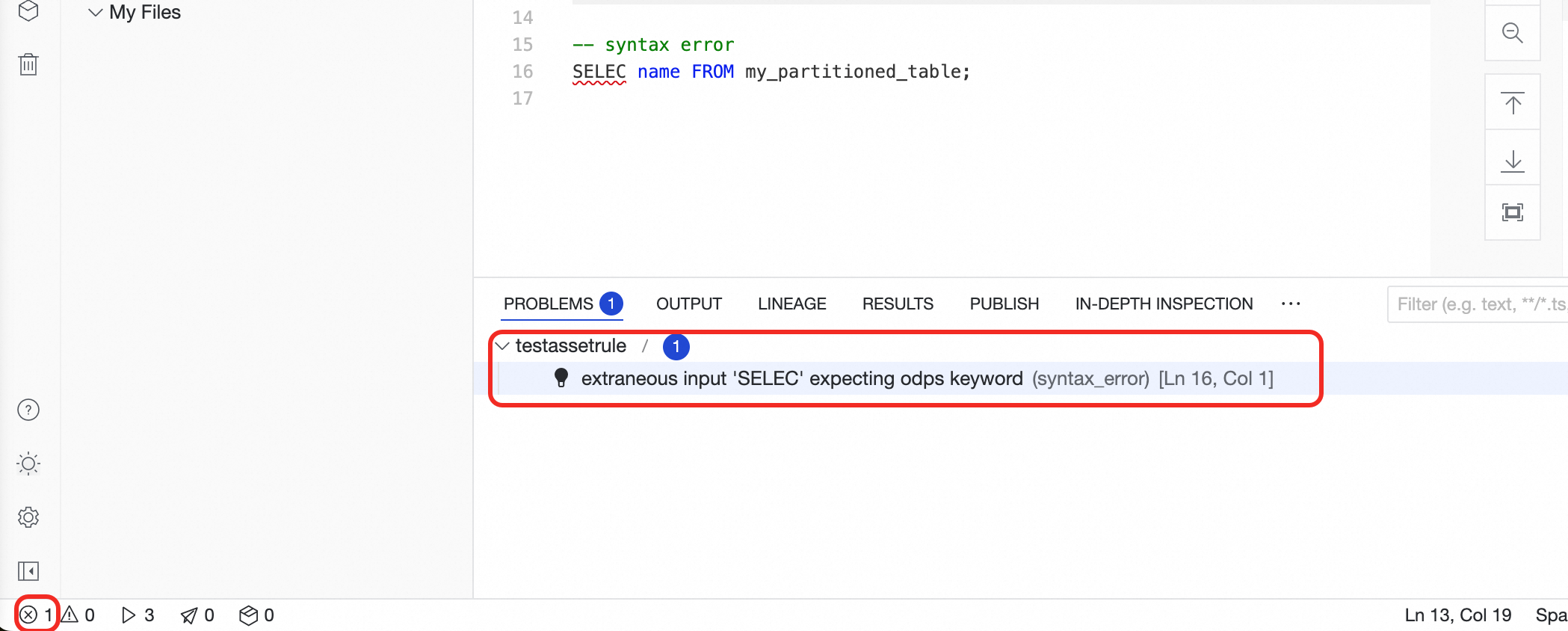
LSP 構文問題の修正
赤い下線が引かれた
SELECにカーソルを合わせ、表示される電球アイコンをクリックし、DataWorks Copilot を使用してSELECTにクイック修正します。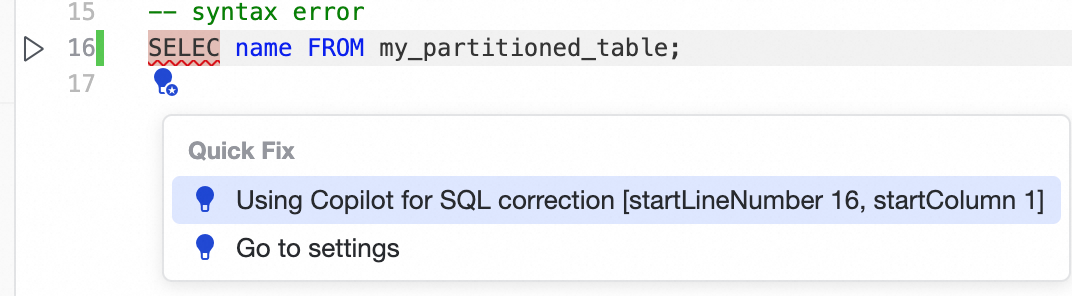
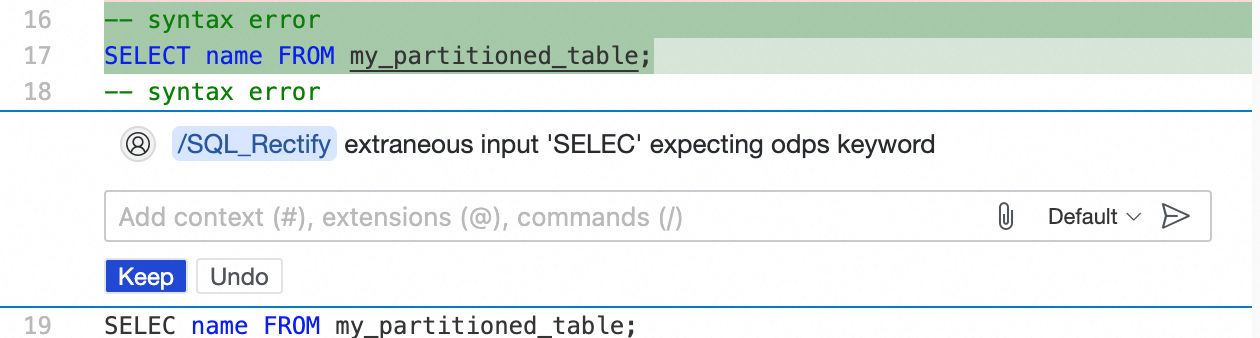
ガバナンスルールの問題の特定
[保存] をクリックすると、エディターはデータ資産ガバナンスプラグインの有効なルールに基づいてコードの問題をチェックします。この場合、
CREATE TABLE は許可されていませんとパーティションテーブルのクエリにはパーティションフィルターを含める必要がありますという 2 つの組み込み開発ヘルスチェックルールがトリガーされます。[問題] パネルが自動的に表示されない場合は、ページ左下の
 アイコンをクリックして [問題] パネルを開きます。
アイコンをクリックして [問題] パネルを開きます。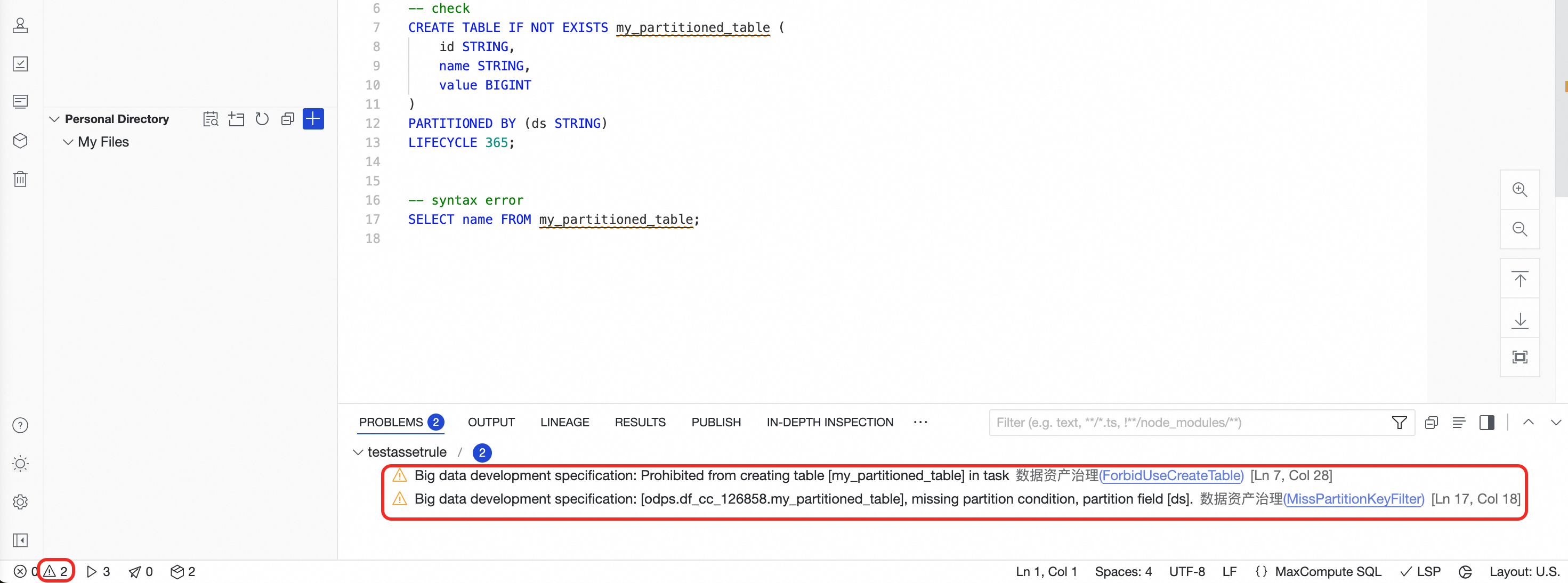
ガバナンスルールの問題の修正
my_partitioned_table にカーソルを合わせて [クイック修正] をクリックするか、[問題] パネルのハイパーリンクをクリックします。修正提案が生成された後、それが最適化の要件を満たしていることを確認し、提案を適用します。
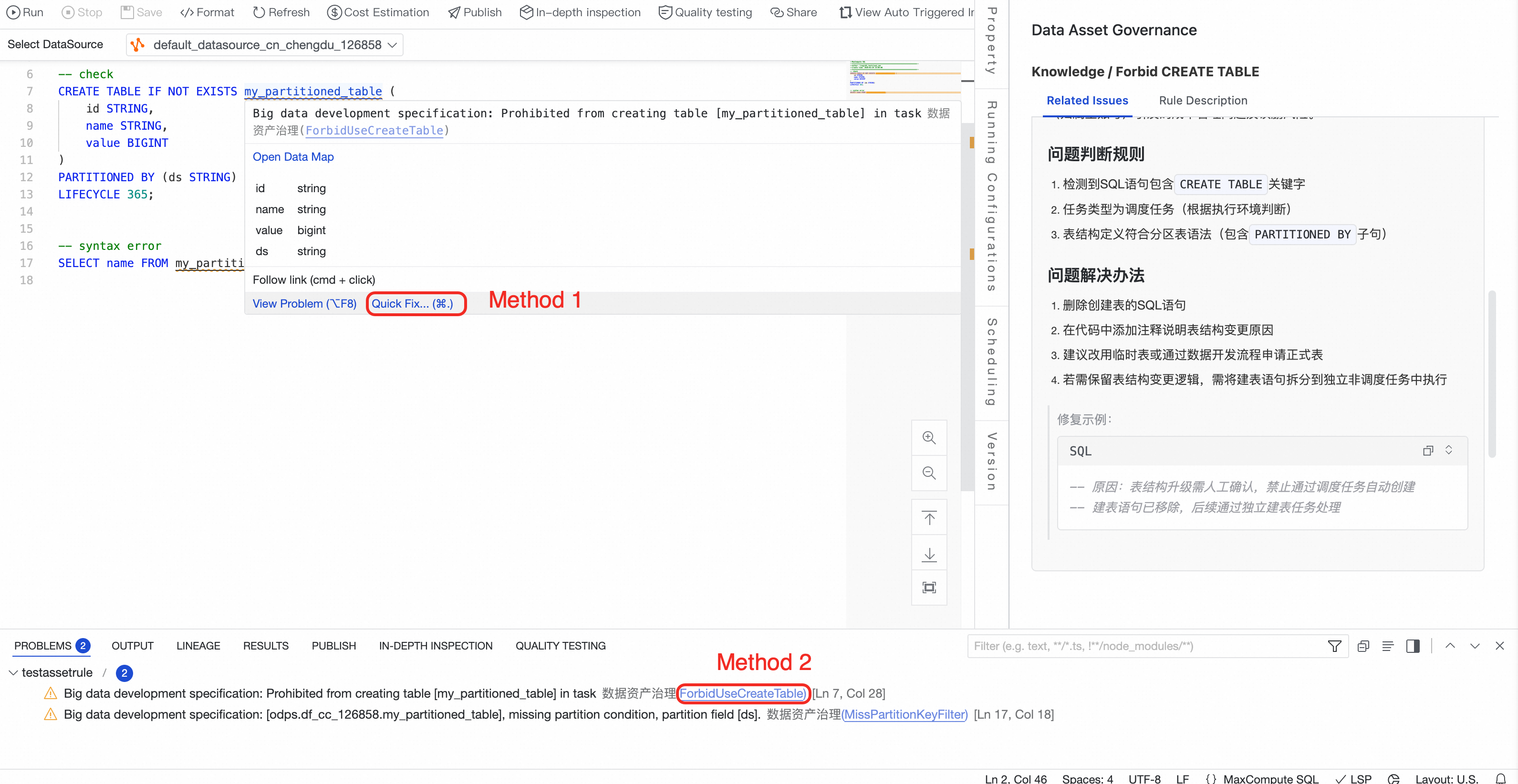
この例では、クイック修正を使用して 2 番目の SQL ステートメントを修正します。
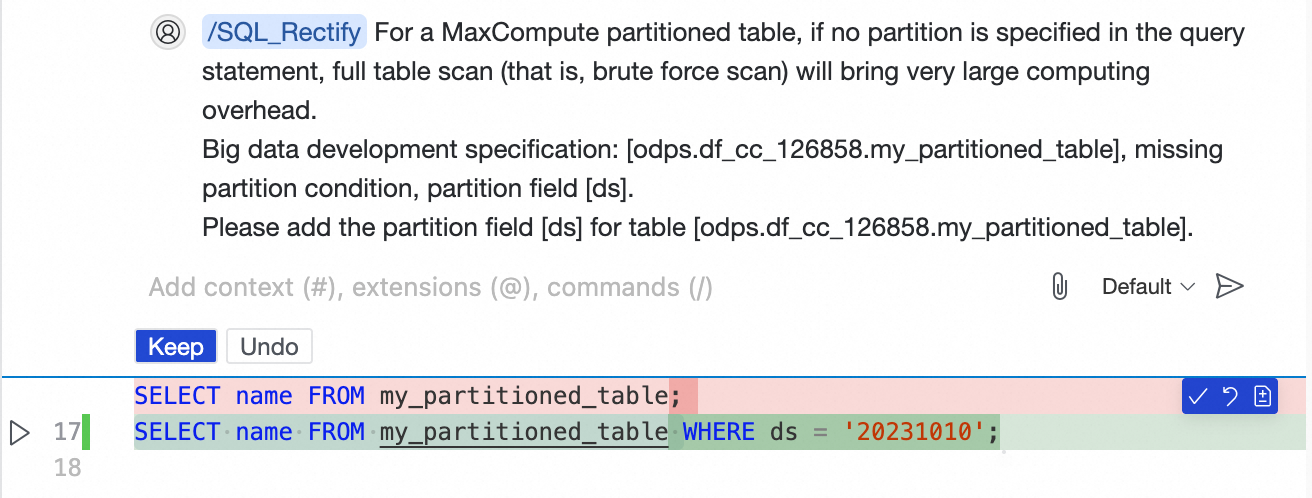
単一ファイルの詳細スキャンの開始
問題を修正した後、単一ノードのコードに対して詳細スキャンを実行できます。たとえば、
パーティションテーブルのクエリにはパーティションフィルターを含める必要がありますルールのみを修正した後、[詳細検査] をクリックします。エディターはファイルの詳細スキャンを実行し、未解決のタスク内で CREATE TABLE は許可されていませんの問題を表示します。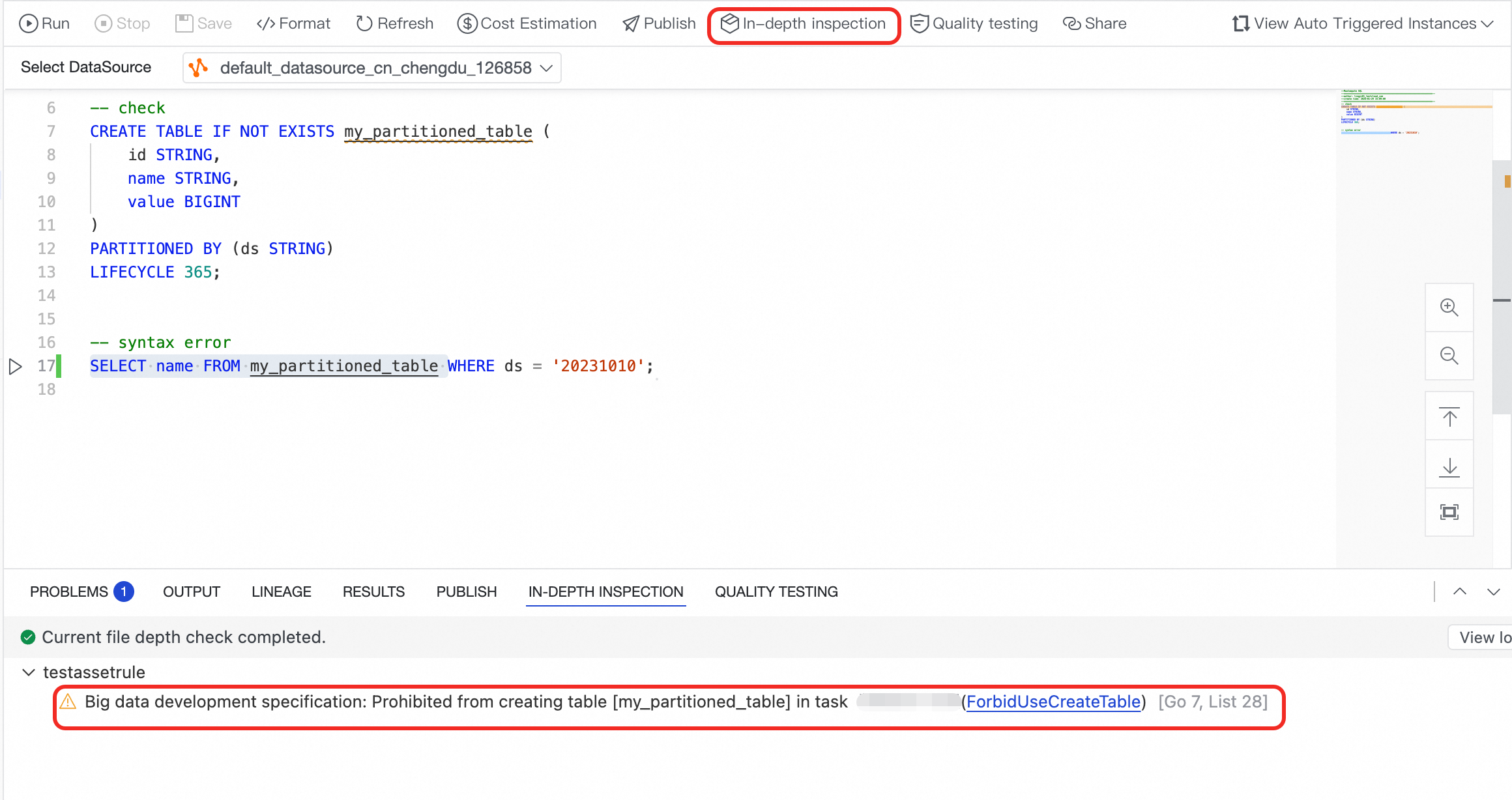
コア機能
構成設定
プリファレンスに基づいて問題診断機能を構成します。すべての構成設定は、現在ログインしているアカウントにのみ適用されます。
DataWorks ワークスペースリストページに移動し、対象のワークスペースを見つけて、[操作] > [クイックアクセス] > [DataStudio] をクリックします。
左側のナビゲーションウィンドウの下部にある
> Setup をクリックし、Setup ページの User タブに移動します。
構成パス | 設定名 | 説明 | 有効な値 | デフォルト値 | 影響 |
Data Studio |
| データ資産ガバナンスプラグインを有効にする |
|
| ノードを保存する際に、データ標準、セキュリティ、パフォーマンスの問題をチェックするかどうかを制御します。 |
LspSetting |
| リアルタイム構文診断を有効にする |
|
| コード編集中に構文エラーをリアルタイムで表示するかどうかを制御します。 |
LspSetting |
| 構文エラーの重要度レベル |
|
| エディターに表示される構文エラーの重要度レベル (赤い波線 (Error) や黄色い波線 (Warning) など) を制御します。 |
組み込みルールライブラリの管理
データ資産ガバナンスプラグインのチェック動作は、ルールライブラリによって駆動されます。ルールライブラリは、組み込みルールとカスタムルールに分かれています。必要に応じて特定のルールを有効または無効にできます。
ルールライブラリの管理は、現在の Alibaba Cloud アカウントにのみ適用されます。
DataStudio ページの左側のナビゲーションウィンドウで、ガバナンスアイコン
 をクリックして、データ資産ガバナンスプラグインの構成を開きます。
をクリックして、データ資産ガバナンスプラグインの構成を開きます。Data Asset Governance プラグインパネルの [組み込みルールライブラリ] セクションで、対象のガバナンスルールを見つけ、その横にあるトグルアイコンをクリックしてルールを有効化または無効化します。
有効 (デフォルト):ノードを保存する際にルールがチェックされます。
無効:ノードを保存する際にルールはチェックされません。
カスタムルールライブラリ
組み込みルールがチームの特定のビジネスロジックやコーディング標準を満たせない場合、データ資産ガバナンスプラグインはカスタムルールライブラリを提供します。自然言語による説明と正常/異常例を使用して、新しいチェックルールを定義できます。
サポートされるカスタムルールシナリオ
チェックディメンション | 主なチェック内容 | 主な価値 | サポート範囲 |
コードテキスト | SQL スクリプトなど、ノード内の生のコード。 | コードスタイル、禁止キーワード、ベストプラクティスをチェックします。 | すべてのタスクタイプ |
スケジュール設定 | リソースグループ、スケジュール、タイムアウト設定など。 | コンプライアンスに準拠したリソース使用量を確保し、スケジュール構成エラーを防ぎます。 | すべてのタスクタイプ |
ノードリネージ | タスクの上流および下流の依存関係。 | パイプラインへの影響を分析し、重要なノードへの変更によるリスクを防ぎます。 | すべてのタスクタイプ |
コード解析 | SQL で参照されるテーブル、関数、ビュー、その他のオブジェクト。 | 機密テーブルに対する操作や関数の誤用を特定し、権限コンプライアンスを確保します。 | すべての SQL ベースのタスクタイプ |
メタデータとリネージ | テーブル構造、列の詳細、テーブルレベルのリネージ。 | 列の変更による影響をチェックし、データモデルの一貫性を確保します。 | MaxCompute SQL、EMR Spark SQL、EMR Hive、および Hologres SQL |
データガバナンスメトリック | コスト、ストレージ、出力ヘルススコアなど (T+1 データ)。 | データコストと品質を監視し、継続的なガバナンスの最適化を推進します。 | すべての SQL ベースのタスクタイプ |
操作手順
DataStudio ページの左側のナビゲーションウィンドウで、ガバナンスアイコン
をクリックして、データ資産ガバナンスプラグインの構成を開きます。Data Asset Governance プラグインパネルの [カスタムルールライブラリ] セクションで、
[+]をクリックしてルールを作成します。たとえば、次のカスタムルールを作成します。重要AI Generation をクリックすると、Copilot 機能を使用して特定のガバナンスルールを生成できます。
Rule Name:
ファクトテーブルの UPDATE には WHERE 句が必須。重要度レベル:Warning レベルは開発フェーズでのみプロンプトを表示し、Error レベルはアラートをトリガーしてデプロイをブロックします。たとえば、
Warningを選択します。スコープ:ルールのノードスコープを選択します。たとえば、
MaxCompute > MaxCompute SQLを選択します。有効範囲:[個人]、[ワークスペース]、[テナント] レベルをサポートします。
重要テナントレベルはテナント管理者のみに表示されます。ワークスペースレベルはワークスペース管理者のみに表示されます。一般メンバーは個人レベルのオプションのみ表示できます。
Rule Description:
MaxCompute SQL の UPDATE 文をチェックします。ターゲットがファクトテーブル (テーブル名が _f で終わる) で、WHERE 句が含まれていない場合、高リスクの問題としてフラグを立てます。正常例:
UPDATE my_project.order_detail_f SET status='shipped' WHERE order_id='123';UPDATE my_project.order_detail_dim SET status='shipped';
異常例:
UPDATE my_project.order_detail_f SET status='expired';
Save をクリックすると、ルールが [詳細検査] で有効になります。
ルールが不要になった場合は、対象のカスタムガバナンスルールにカーソルを合わせ、その横にある無効化アイコン
 をクリックしてルールを無効にします。
をクリックしてルールを無効にします。
詳細スキャン
クイックスタートセクションで述べた単一ファイルのスキャンに加えて、バッチ詳細スキャンもサポートされています。
DataStudio ページの左側のナビゲーションウィンドウで、ガバナンスアイコン
をクリックして、データ資産ガバナンスプラグインの構成を開きます。Data Asset Governance プラグインパネルの [詳細検査] セクションで、バッチでスキャンするファイルと適用するルールを選択し、詳細スキャンを開始します。
重要バッチスキャンの範囲は、現在エディターで開いているファイルタブに限定されます。最大 5 つのファイルを選択できます。開いていないファイルは選択できません。
バッチスキャン中は、一度に 1 つの詳細スキャンしか実行できません。
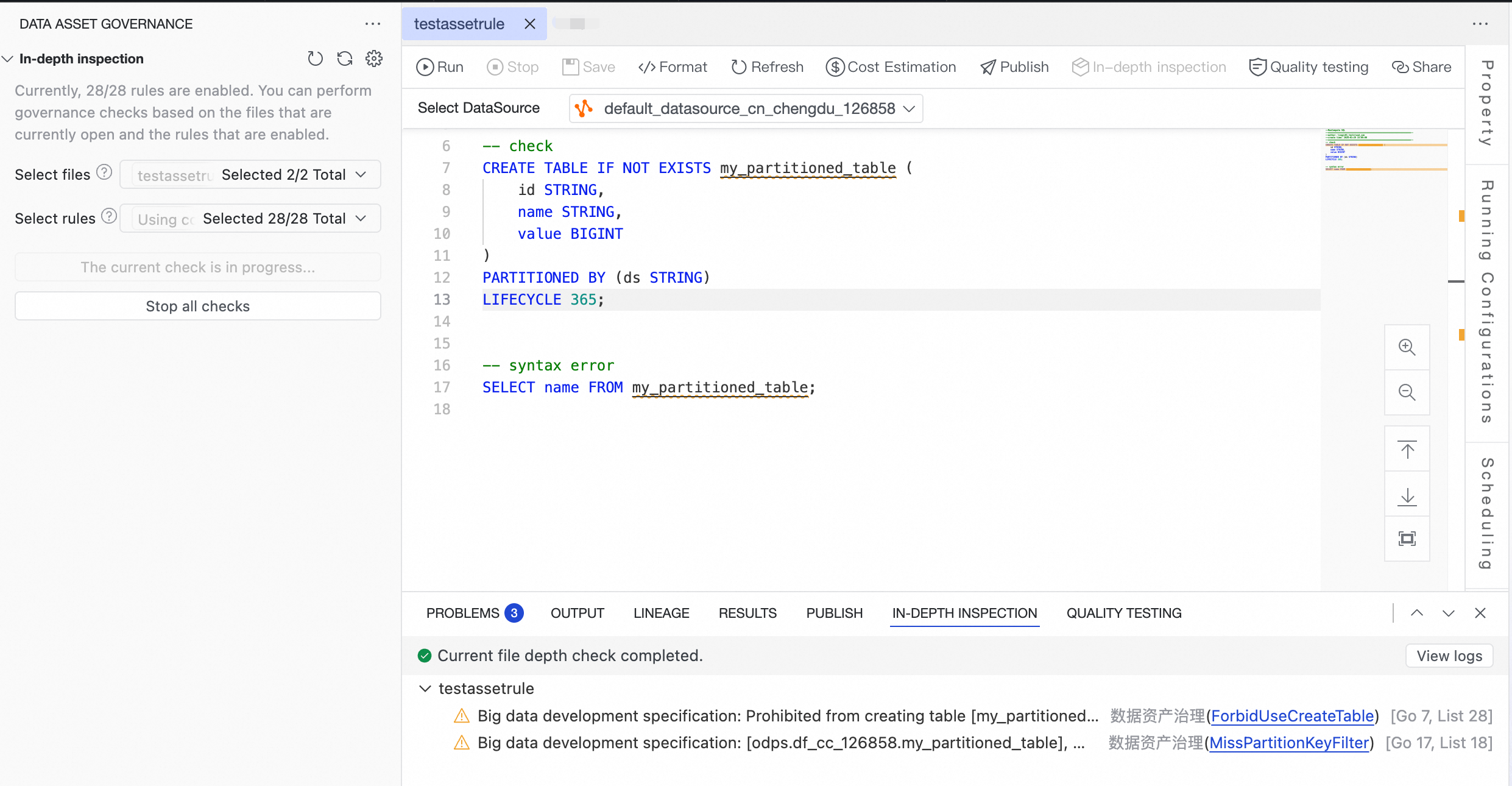
[詳細検査] 結果ペインで、右上隅にある View Log をクリックすると、大規模言語モデルによるチェックルールの詳細な判定プロセスを表示できます。
ガバナンスルールの詳細
Data Asset Governance プラグインパネルの [詳細検査] セクションの右上隅にある ![]() をクリックして、すべてのチェックルールの詳細を表示します。 次のセクションでは、データ資産ガバナンスプラグインのコア組み込みルールの一部について説明します。
をクリックして、すべてのチェックルールの詳細を表示します。 次のセクションでは、データ資産ガバナンスプラグインのコア組み込みルールの一部について説明します。
各ガバナンスルールに適用可能なノードタイプについては、「サポートされるノードタイプ」をご参照ください。
パーティションテーブルのクエリにはパーティションフィルターを含める必要がある
リスク説明:パーティションを指定せずに MaxCompute パーティションテーブルをクエリすると、フルテーブルスキャンがトリガーされ、大量の計算リソースを消費し、高額なコストが発生します。
不正なコード例:
SELECT user_id, order_amount FROM user_orders WHERE status = 'paid';正しいコード例:
SELECT user_id, order_amount FROM user_orders WHERE status = 'paid' AND pt = '${bizdate}'; -- パーティションフィルター条件を追加自動修正ロジック:クイック修正がサポートされています。システムは自動的に
WHERE句にAND pt = '${bizdate}'などのパーティション条件を追加します。
再実行が有効な INSERT INTO は許可されない
リスク説明:SQL タスクに
INSERT INTOロジックのみが含まれ、スケジュール設定で再実行が許可されている場合、再実行のたびにターゲットテーブルにデータが追加され、データ重複が発生しやすく、データの精度が損なわれる可能性があります。不正なコード例:
-- タスクプロパティを「再実行可能」に設定 INSERT INTO target_table SELECT * FROM source_table;正しいコード例:
-- タスクプロパティを「再実行可能」に設定 INSERT OVERWRITE TABLE target_table SELECT * FROM source_table;自動修正ロジック:クイック修正がサポートされています。システムは
INSERT INTOをINSERT OVERWRITEに変更し、再実行時にデータが追加されるのではなく上書きされるようにします。
JOIN 列の型は一致する必要がある
リスク説明:MaxCompute SQL では、
JOIN操作で列の型が一致しないと、暗黙的な型変換が発生し、計算エラー、パフォーマンスの低下、データ品質の問題につながる可能性があります。不正なコード例:
-- a.user_id は BIGINT、b.uid は STRING SELECT * FROM table_a a JOIN table_b b ON a.user_id = b.uid;正しいコード例:
-- a.user_id は BIGINT、b.uid は STRING です SELECT * FROM table_a a JOIN table_b b ON a.user_id = CAST(b.uid AS BIGINT);自動修正ロジック:クイック修正がサポートされています。システムは自動的に検出し、
CAST関数を使用して一方の列に明示的な型変換を適用し、もう一方の列の型と一致させます。
現在のプロジェクト外のテーブルへの INSERT
リスク説明:プロジェクト A のタスクからプロジェクト B のテーブルにデータを書き込むことは、高リスク操作です。これにより、プロジェクトの分離が損なわれ、不正なデータアクセスやデータ漏洩につながる可能性があります。
不正なコード例:
-- project_A 内のタスクで実行 INSERT INTO project_B.some_table SELECT * FROM my_table;正しいコード例:
-- 推奨されるアプローチ:データはテーブルの所有プロジェクト (project_B) に属するタスクによって書き込まれるべきです。 -- project_A でこの操作を避けてください。自動修正ロジック:自動修正はサポートされていません。ビジネス要件に基づいてデータ同期パイプラインを調整し、データがターゲットプロジェクト自身のタスクによって書き込まれるようにする必要があります。
定期タスクは開発環境のテーブルに書き込んではならない
リスク説明:本番環境の定期タスクが開発環境のテーブルにデータを書き込むと、データ保護レベルが低下し、データセキュリティリスクが生じます。
不正なコード例:
-- 本番環境 (PROD) のタスクで実行 INSERT OVERWRITE TABLE user_dev.temp_data SELECT * FROM user_prod.source_data;正しいコード例:
-- 本番タスクは本番環境のテーブルに書き込むべきです INSERT OVERWRITE TABLE user_prod.result_data SELECT * FROM user_prod.source_data;自動修正ロジック:自動修正はサポートされていません。データフローが環境分離基準に準拠するように、ターゲットテーブルを手動で変更する必要があります。
SQL での CREATE TABLE は許可されない
リスク説明:定期 SQL タスクで
CREATE TABLEを直接使用すると、テーブルの所有権が不明確になり (通常、テーブルはプライマリアカウントまたはスケジューリングアカウントによって所有されます)、管理コストが増加し、偶発的なデータ削除のリスクが生じます。不正なコード例:
CREATE TABLE my_temp_table (id INT); INSERT INTO my_temp_table VALUES (1);正しいコード例:
-- テーブルは DataWorks のテーブル管理モジュールで事前に作成し、SQL タスクで直接使用する必要があります。 INSERT INTO my_temp_table VALUES (1);自動修正ロジック:自動修正はサポートされていません。DataWorks のメタデータ管理でテーブルを作成するか、特定のシナリオでエラーを回避するために
CREATE TABLE IF NOT EXISTSを使用することを推奨します。
スケジューリングパラメーターの欠落チェッカー
リスク説明:定期スケジューリングタスクの主な目的は、時間ディメンションによってデータを増分処理することです。
WHERE条件にスケジューリングパラメーター (例:${bizdate}) が欠落している場合、タスクは毎日全データを処理したり、誤った日付範囲を処理したりする可能性があり、データの欠落、不整合、および大幅なリソースの浪費につながります。不正なコード例:
-- エラー:スケジューリングパラメーターが欠落しており、日次増分処理ができない INSERT OVERWRITE TABLE users_active_today PARTITION (pt = '${bizdate}') SELECT user_id FROM login_log; -- WHERE pt = '...' が欠落正しいコード例:
-- 正しい:スケジューリングパラメーターをフィルター条件として使用し、日次増分処理を実現 INSERT OVERWRITE TABLE users_active_today PARTITION (pt = '${bizdate}') SELECT user_id FROM login_log WHERE pt = '${bizdate}';自動修正ロジック:自動修正は完全にはサポートされていません。プラグインは欠落している可能性のあるスケジューリングパラメーターフィルターをハイライトしますが、ビジネスロジックの複雑さのため、実際の要件に基づいて正しいフィルター条件を手動で追加することを推奨します。
よくある質問
Q:これらのチェックはエディターのパフォーマンスやノードの保存速度に影響しますか?
A:リアルタイム構文診断 (LSP) はエディターのパフォーマンスにわずかな影響を与えますが、許容範囲内です。データ資産ガバナンスプラグインは保存時にトリガーされ、コードの複雑さとルール数に応じて保存時間がわずかに増加します。顕著な遅延が発生した場合は、ネットワークを確認するか、テクニカルサポートにお問い合わせください。
Q:この機能は無料ですか?DataWorks Copilot は必須ですか?
A:問題診断機能は DataWorks の組み込み機能であり、無料です。ただし、DataWorks Copilot からの修正提案を使用する場合、「DataWorks Copilot の課金」で指定された課金ルールが適用されます。Copilot を使用せずに手動で問題を修正することもできます。
Q:機能を有効にしているのに、コードの問題が検出されないのはなぜですか?
A:以下の手順でトラブルシューティングを行ってください。
メインスイッチの確認:[設定項目] > [ユーザー] > [拡張] で、
DataStudio Governance Check Module EnablementとSyntaxErrorEnableの両方が有効になっていることを確認します。ルールスイッチの確認:[ルールライブラリ] に移動し、適用したいルールが有効になっていることを確認します。
ノードタイプの確認:現在のノードタイプが対象ルールの適用範囲内であるかを確認します。
ネットワークの問題:ブラウザの開発者ツールで失敗したネットワークリクエストがないか確認します。ネットワークの問題により、LSP サービスまたはガバナンスサービスがロードに失敗した可能性があります。
Q:LSP またはガバナンスプラグインサービスが利用できない場合はどうなりますか?
A:バックエンドサービスが一時的に利用できない場合、問題診断機能はサイレントに失敗します。リアルタイムの構文プロンプトや保存時のガバナンス問題は表示されませんが、通常のコード編集および保存操作には影響しません。ページをリフレッシュして、再度チェックをトリガーすることを推奨します。
付録:用語集
用語 | 英語 | 説明 |
ライブスキャン | Live Scan | 保存時に現在アクティブなノードで実行される、迅速で軽量なチェック。現在、パフォーマンスを考慮して、組み込みの高効率ルールのみが適用されます。 |
詳細スキャン | Deep Scan | 指定された範囲 (単一ノード、個人ノード、ワークスペース、またはフォルダ) 内のすべてのノードに対して手動でトリガーされる、包括的で時間のかかるチェック。カスタム AI ルールを含むすべてのルールが適用されます。 |
カスタム AI チェッカー | Custom AI Checker | ユーザーが特定の形式 (自然言語と例など) で定義し、大規模言語モデルによって駆動されるチェックルール。 |
[問題] パネル | Problems Panel | VS Code でコードの問題を一元的に表示するための、ネイティブまたはプラグイン提供の UI エリア。 |
クイック修正 | Quick Fix | 検出された問題に対してプラグインが提供するクリック可能なアクションで、コードや構成を自動的に修正します。 |