このガイドでは、DataWorks OpenAPI (2024-05-18) を使用して、データテーブルとフィールドのデータリネージをプログラムでクエリする方法について説明します。自動化された大規模なリネージ分析のために、API 呼び出しの例と SDK コードを提供します。
データリネージとは
四半期売上が大幅に増加したことを示すビジネスレポートを確認しているとします。データアナリストやマネージャーとして、次のような疑問が生じるかもしれません。
-
この「売上」指標は どのように計算 されているのか?
-
その 生のビジネスデータ のソースは何か?注文テーブルから来ているのか、それとも支払いトランザクションテーブルから来ているのか?
-
データは、生の段階から最終レポートに至るまで、クレンジング、変換、集計など、どのような 処理ステップ を経たのか?
-
この指標のデータが不正確な場合、どのダウンストリームの レポートやアプリケーション が影響を受けるのか?
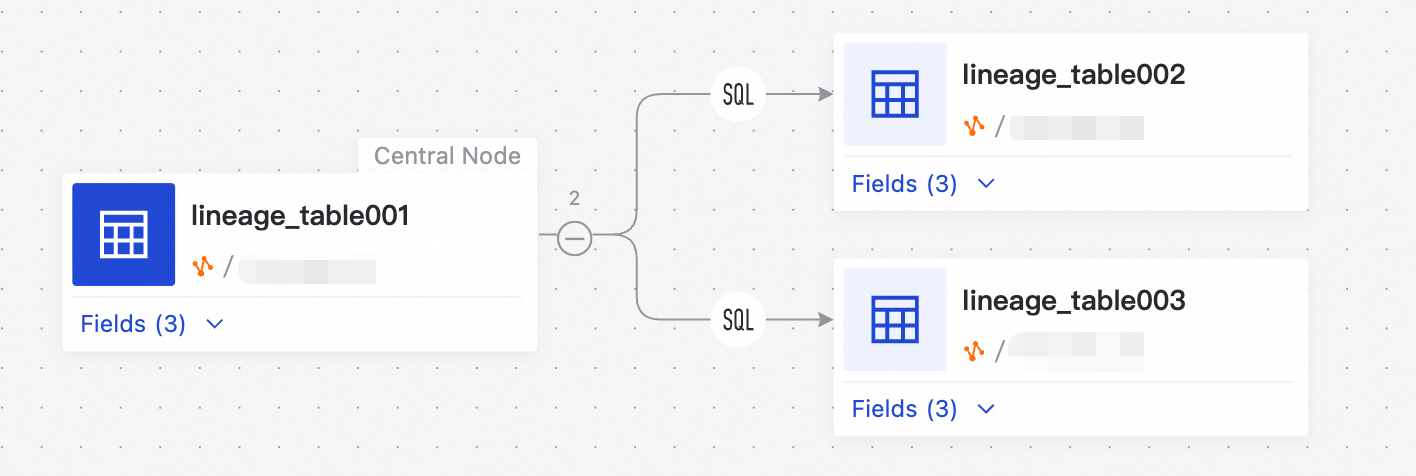
明確なデータリネージには、以下の主要な利点があります。
-
データ追跡とトラブルシューティング
データの異常やエラーを発見した場合、データリネージをアップストリームにたどることで、問題の原因となった計算ロジックやソースデータを迅速に特定できます。これにより、トラブルシューティングの時間が大幅に短縮されます。 -
影響分析
データテーブルの構造、フィールド、または計算ロジックを変更する必要がある場合、ダウンストリームのリネージを分析して、どのデータやビジネスレポートが影響を受けるかを正確に評価できます。これにより、変更による予期せぬ結果を回避できます。 -
データガバナンスと信頼
明確なデータリネージは、データ資産管理、データ標準の実装、データ品質監視の基盤です。データライフサイクルを透過的にし、ステークホルダーのデータに対する信頼を高めます。 -
コスト最適化と資産インベントリ
データリネージを分析することで、ダウンストリームのコンシューマーがいないデータテーブルや計算タスクを特定できます。これにより、データウェアハウスのコストを最適化し、廃止された資産を整理できます。
DataWorks では、システムが MaxCompute SQL や EMR Spark タスクなど、さまざまな計算タスクによって生成されたデータリネージを自動的に解析・記録します。 DataWorks OpenAPI を使用すると、このリネージ情報にプログラムでアクセスし、リネージ分析機能を独自のデータ管理プラットフォームや自動化された O&M ワークフローに統合できます。
前提条件:エンティティ ID の取得
データリネージをクエリするには、まず対象のデータテーブルまたはフィールドの一意な識別子が必要です。この識別子は エンティティ ID と呼ばれ、メタデータおよびリネージ関連の API 呼び出しに必須のパラメーターです。
エンティティ ID は、以下の 2 つの方法のいずれかで取得できます。
1. コンソールからのエンティティ ID の取得
少数の既知のテーブルやフィールドの場合、最も速い方法は、コンソールから手動で ID をコピーすることです。
テーブルのエンティティ ID の取得
-
DataWorks コンソールで、[データマップ] モジュールに移動します。
-
対象のテーブルを検索し、その詳細ページに移動します。
-
左側の Table Basic Information パネルで、Entity ID を見つけてコピーします。
エンティティ ID の形式は
maxcompute-table:::<project_name>::<table_name>です。
フィールドのエンティティ ID の取得
-
対象のテーブルの詳細ページで、[リネージ] タブに移動し、[フィールドリネージ] を選択します。
-
フィールドリネージグラフで、目的のフィールドノードをクリックします。
-
右側にフィールドの詳細パネルが表示されます。パネルで、Entity ID を見つけてコピーします。
エンティティ ID の形式は
maxcompute-column:::<project_name>::<table_name>::<field_name>です。
2. API によるエンティティ ID の一括取得
複数のエンティティ ID を取得する必要がある場合、手動操作は手間がかかります。この場合、OpenAPI を使用して一括クエリを実行します。
-
テーブル ID の一括取得:
ListTablesAPI を呼び出します。詳細については、「データマップ内のデータテーブルのリストのクエリ」をご参照ください。 -
フィールド ID の一括取得:
ListColumnsAPI を呼び出します。詳細については、「データマップ内のデータテーブルのフィールドリストのクエリ」をご参照ください。
ListLineages API によるデータリネージのクエリ
エンティティ ID を取得した後、主要な ListLineages API を使用して、そのアップストリームおよびダウンストリームのリネージ関係をクエリできます。
1. 主要な API パラメーター
ListLineages API の主要なリクエストパラメーターを次の表に示します。OpenAPI ポータルで API をオンラインでデバッグできます。
|
パラメーター |
タイプ |
説明 |
|
|
String |
このパラメーターを使用して ダウンストリームリネージをクエリ します。ソース (アップストリーム) のエンティティ ID を渡して、そのすべてのダウンストリームリネージをクエリします。 |
|
|
String |
このパラメーターを使用して アップストリームリネージをクエリ します。宛先 (ダウンストリーム) のエンティティ ID を渡して、そのすべてのアップストリームリネージをクエリします。 |
|
|
String |
|
|
|
String |
|
|
|
Boolean |
レスポンスに詳細なリネージ関係情報を含めるかどうかを指定します。完全なコンテキストを取得するには、このパラメーターを |
-
SrcEntityIdとDstEntityIdの両方を指定すると、API は指定されたアップストリームエンティティとダウンストリームエンティティ間のリネージ関係を返します。 -
SrcEntityIdとDstEntityIdが同じ場合、API はエンティティが自身を指すリネージ関係を返します。
2. 呼び出し例
MaxCompute テーブルがあり、その エンティティ ID が maxcompute-table:::test_project::test_table であるとします。
例 1:ダウンストリームリネージのクエリ
このテーブルのすべてのダウンストリームテーブルをクエリするには、これを ソース として指定します。
-
SrcEntityId:maxcompute-table:::test_project::test_table -
NeedAttachRelationship:true
名前に "report" を含むダウンストリームテーブルのみを検索するには、DstEntityName パラメーターを追加します。
-
DstEntityName:report
例 2:アップストリームリネージのクエリ
どのテーブルやタスクがこのテーブルを生成するかを判断するには、これを 宛先 として指定します。
-
DstEntityId:maxcompute-table:::test_project::test_table -
NeedAttachRelationship:true
SrcEntityName パラメーターを使用して、アップストリームソースをフィルタリングすることもできます。
3. API レスポンス
ListLineages の呼び出しが成功すると、リネージ関係のリストが返されます。各リネージ関係には、ソースエンティティ、宛先エンティティ、およびそれらの関連付けに関する情報が含まれます。
単一のリネージ関係のサンプルレスポンス (JSON):
{
"SrcEntity": {
"Id": "maxcompute-table:::test_project::table_from",
"Name": "table_from",
"Attributes": {
"rawEntityId": "maxcompute-table:::test_project::table_from"
}
},
"DstEntity": {
"Id": "maxcompute-table:::test_project::table_to",
"Name": "table_to",
"Attributes": {
"project": "test_project",
"region": "cn-shanghai",
"table": "table_to"
}
},
"Relationships": [
{
"Id": "123456789:maxcompute-table.test_project.table_from:maxcompute-table.test_project.table_to:maxcompute.SQL.76543xxx",
"CreateTime": 1681089163548,
"Task": {
"Id": "76543xxx",
"Type": "dataworks-sql",
"Attributes": {
"engine": "maxcompute",
"channel": "1st",
"taskInstanceId": "12345xxx",
"projectId": "123456",
"taskId": "76543xxx"
}
}
}
]
}レスポンスの解釈方法:
-
SrcEntityとDstEntity:それぞれリネージのアップストリームエンティティとダウンストリームエンティティを表します。これらのIdを使用して、GetTable または GetColumn API を呼び出し、より詳細なメタデータを取得できます。 -
Relationships:SrcEntityとDstEntityがどのように関連付けられているかを説明します。-
Task:このリネージ関係を作成したタスクを説明します。タスクが DataWorks のスケジュールされたタスクである場合、Task.AttributesにはtaskIdとtaskInstanceIdが含まれます。これらの ID を使用して GetTask API を呼び出し、詳細なタスク定義と実行ステータスを取得できます。
-
Java SDK ウォークスルー
次の例は、Java SDK を使用して完全なリネージクエリワークフローを実装する方法を示しています。
1. 前提条件
-
JDK バージョン:JDK 8 以降。
-
Maven 依存関係:プロジェクトの
pom.xmlファイルに次の依存関係を追加します。${latest.version}を SDK の最新バージョン番号に置き換えます。
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>dataworks_public20240518</artifactId>
<version>${latest.version}</version>
</dependency>2. 完全なコード例
次のコードは、クライアントを初期化し、指定されたテーブルのアップストリームおよびダウンストリームのリネージをクエリし、主要な情報を出力する方法を示しています。
import java.util.List;
import java.util.Map;
import com.aliyun.dataworks_public20240518.Client;
import com.aliyun.dataworks_public20240518.models.GetTableRequest;
import com.aliyun.dataworks_public20240518.models.GetTableResponse;
import com.aliyun.dataworks_public20240518.models.LineageEntity;
import com.aliyun.dataworks_public20240518.models.LineageRelationship;
import com.aliyun.dataworks_public20240518.models.LineageTask;
import com.aliyun.dataworks_public20240518.models.ListLineagesRequest;
import com.aliyun.dataworks_public20240518.models.ListLineagesResponse;
import com.aliyun.dataworks_public20240518.models.ListLineagesResponseBody.ListLineagesResponseBodyPagingInfo;
import com.aliyun.dataworks_public20240518.models.ListLineagesResponseBody.ListLineagesResponseBodyPagingInfoLineages;
import com.aliyun.dataworks_public20240518.models.Table;
import com.aliyun.tea.TeaException;
public class LineageQuerySample {
/**
* <b>description</b> :
* <p>認証情報を使用してクライアントを初期化します。</p>
*
* @return Client
* @throws Exception
*/
public static com.aliyun.dataworks_public20240518.Client createClient() throws Exception {
com.aliyun.teaopenapi.models.Config config = new com.aliyun.teaopenapi.models.Config()
// AccessKey ID
.setAccessKeyId(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"))
// AccessKey Secret
.setAccessKeySecret(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET"));
// エンドポイントについては、https://api.aliyun.com/product/dataworks-public をご参照ください。
config.endpoint = "dataworks.cn-hangzhou.aliyuncs.com";
return new com.aliyun.dataworks_public20240518.Client(config);
}
public static void main(String[] args_) throws Exception {
Client client = LineageQuerySample.createClient();
// クエリ対象のテーブルのエンティティ ID。お使いの MaxCompute テーブルのエンティティ ID に置き換えてください。
String tableId = "maxcompute-table:::test_project::test_table";
try {
// 1. アップストリームリネージをクエリします。
ListLineagesRequest listLineagesRequest = new ListLineagesRequest()
.setDstEntityId(tableId)
.setNeedAttachRelationship(true)
.setPageNumber(1)
// デフォルトでは 10 件のレコードが返されます。最大値は 100 です。
.setPageSize(10);
// キーワードベースのあいまい一致と、アップストリームテーブル名のフィルタリングをサポートしています。
listLineagesRequest.setSrcEntityName("demo");
ListLineagesResponse listLineagesResponse = client.listLineages(listLineagesRequest);
String requestId = listLineagesResponse.getBody().getRequestId();
System.out.println("\nQuery upstream lineage");
// トラブルシューティングのためにリクエスト ID を出力します。
System.out.println(requestId);
ListLineagesResponseBodyPagingInfo pagingInfo = listLineagesResponse.getBody().getPagingInfo();
if (pagingInfo.getTotalCount() > 0 && pagingInfo.getLineages() != null) {
for (ListLineagesResponseBodyPagingInfoLineages lineage : pagingInfo.getLineages()) {
// 単一のリネージ関係を取得し、対応するアップストリームテーブルをクエリします。
LineageEntity srcEntity = lineage.getSrcEntity();
System.out.println("============================================");
System.out.println("ID: " + srcEntity.getId());
System.out.println("Name: " + srcEntity.getName());
// アップストリームテーブルの情報を取得します。
Table table = getTable(client, srcEntity.getId());
if (table != null) {
System.out.println("Comment: " + table.getComment());
System.out.println("Create Time: " + table.getCreateTime());
System.out.println("Modify Time: " + table.getModifyTime());
}
}
}
// 2. ダウンストリームリネージをクエリします。
listLineagesRequest = new ListLineagesRequest()
.setSrcEntityId(tableId)
.setNeedAttachRelationship(true)
.setPageNumber(1)
// デフォルトでは 10 件のレコードが返されます。最大値は 100 です。
.setPageSize(10);
listLineagesResponse = client.listLineages(listLineagesRequest);
requestId = listLineagesResponse.getBody().getRequestId();
System.out.println("\nQuery downstream lineage");
// トラブルシューティングのためにリクエスト ID を出力します。
System.out.println(requestId);
pagingInfo = listLineagesResponse.getBody().getPagingInfo();
if (pagingInfo.getTotalCount() > 0 && pagingInfo.getLineages() != null) {
for (ListLineagesResponseBodyPagingInfoLineages lineage : pagingInfo.getLineages()) {
// 単一のリネージ関係を取得し、対応するダウンストリームテーブルをクエリします。
LineageEntity dstEntity = lineage.getDstEntity();
System.out.println("============================================");
System.out.println("ID: " + dstEntity.getId());
System.out.println("Name: " + dstEntity.getName());
// ダウンストリームテーブルの情報を取得します。
Table table = getTable(client, dstEntity.getId());
if (table != null) {
System.out.println("Comment: " + table.getComment());
System.out.println("Create Time: " + table.getCreateTime());
System.out.println("Modify Time: " + table.getModifyTime());
}
// リネージ関係を解析します。
List<LineageRelationship> relationships = lineage.getRelationships();
if (relationships != null) {
for (LineageRelationship relationship : relationships) {
System.out.println("\n\tRelationshipId: " + relationship.getId());
System.out.println("\tRelationshipCreateTime: " + relationship.getCreateTime());
// タスク詳細を解析します。
LineageTask task = relationship.getTask();
Map<String, String> attributes = task.getAttributes();
// DataWorks のスケジュールされたタスクの場合、属性からタスク ID とタスクインスタンス ID を取得できます。
if (attributes != null && attributes.containsKey("taskId") && attributes.containsKey("taskInstanceId")) {
System.out.println("\tTaskId: " + attributes.get("taskId"));
System.out.println("\tTaskInstanceId: " + attributes.get("taskInstanceId"));
}
}
}
}
}
} catch (TeaException error) {
// 本番環境では、堅牢な例外処理を実装してください。
// エラーメッセージ
System.out.println(error.getMessage());
// 診断 URL
System.out.println(error.getData().get("Recommend"));
com.aliyun.teautil.Common.assertAsString(error.message);
} catch (Exception _error) {
TeaException error = new TeaException(_error.getMessage(), _error);
// 本番環境では、堅牢な例外処理を実装してください。
// エラーメッセージ
System.out.println(error.getMessage());
// 診断 URL
System.out.println(error.getData().get("Recommend"));
com.aliyun.teautil.Common.assertAsString(error.message);
}
}
public static Table getTable(Client client, String tableId) {
// ID を指定してテーブル情報をクエリします。
GetTableRequest getTableRequest = new GetTableRequest()
.setId(tableId)
.setIncludeBusinessMetadata(true);
try {
GetTableResponse getTableResponse = client.getTable(getTableRequest);
return getTableResponse.getBody().getTable();
} catch (Exception e) {
System.out.println(e.getMessage());
}
return null;
}
}Python SDK ウォークスルー
次の例は、Python SDK を使用して完全なリネージクエリワークフローを実装する方法を示しています。
1. 前提条件
-
Python バージョン:Python 3.6 以降。
-
SDK のインストール:pip を使用して DataWorks Python SDK をインストールします。
${latest.version}を SDK の最新バージョン番号に置き換えます。
pip install alibabacloud_dataworks_public20240518==${latest.version}2. 完全なコード例
次のコードは、クライアントを初期化し、指定されたテーブルのアップストリームおよびダウンストリームのリネージをクエリし、主要な情報を出力する方法を示しています。
# -*- coding: utf-8 -*-
import os
import sys
from alibabacloud_dataworks_public20240518.client import Client as dataworks_public20240518Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_dataworks_public20240518 import models as dataworks_public_20240518_models
from alibabacloud_tea_util import models as util_models
from alibabacloud_tea_util.client import Client as UtilClient
class LineageQuerySample:
@staticmethod
def create_client():
"""AccessKey を使用してクライアントを初期化します。"""
config = open_api_models.Config(
# AccessKey ID
access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
# AccessKey Secret
access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET')
)
# エンドポイントについては、https://api.aliyun.com/product/dataworks-public をご参照ください。
config.endpoint = 'dataworks.cn-hangzhou.aliyuncs.com'
return dataworks_public20240518Client(config)
@staticmethod
def get_table(client, table_id):
"""エンティティ ID を指定してテーブル情報を取得します。"""
get_table_request = dataworks_public_20240518_models.GetTableRequest(
id=table_id,
include_business_metadata=True
)
try:
response = client.get_table(get_table_request)
return response.body.table
except Exception as e:
print(e)
return None
@staticmethod
def main():
client = LineageQuerySample.create_client()
# クエリ対象のテーブルのエンティティ ID。お使いの MaxCompute テーブルのエンティティ ID に置き換えてください。
table_id = 'maxcompute-table:::test_project::test_table'
runtime = util_models.RuntimeOptions()
try:
# 1. アップストリームリネージをクエリします。
upstream_request = dataworks_public_20240518_models.ListLineagesRequest(
dst_entity_id=table_id,
need_attach_relationship=True,
page_number=1,
# デフォルトでは 10 件のレコードが返されます。最大値は 100 です。
page_size=10,
# キーワードベースのあいまい一致と、アップストリームテーブル名のフィルタリングをサポートしています。
src_entity_name='demo'
)
upstream_response = client.list_lineages_with_options(upstream_request, runtime)
print('\nQuery upstream lineage')
print(upstream_response.body.request_id)
paging_info = upstream_response.body.paging_info
if paging_info.total_count > 0 and paging_info.lineages:
for lineage in paging_info.lineages:
src_entity = lineage.src_entity
print('============================================')
print(f'ID: {src_entity.id}')
print(f'Name: {src_entity.name}')
table = LineageQuerySample.get_table(client, src_entity.id)
if table:
print(f'Comment: {table.comment}')
print(f'Create Time: {table.create_time}')
print(f'Modify Time: {table.modify_time}')
# 2. ダウンストリームリネージをクエリします。
downstream_request = dataworks_public_20240518_models.ListLineagesRequest(
src_entity_id=table_id,
need_attach_relationship=True,
page_number=1,
page_size=10
)
downstream_response = client.list_lineages_with_options(downstream_request, runtime)
print('\nQuery downstream lineage')
print(downstream_response.body.request_id)
paging_info = downstream_response.body.paging_info
if paging_info.total_count > 0 and paging_info.lineages:
for lineage in paging_info.lineages:
dst_entity = lineage.dst_entity
print('============================================')
print(f'ID: {dst_entity.id}')
print(f'Name: {dst_entity.name}')
table = LineageQuerySample.get_table(client, dst_entity.id)
if table:
print(f'Comment: {table.comment}')
print(f'Create Time: {table.create_time}')
print(f'Modify Time: {table.modify_time}')
# リネージ関係を解析します。
if lineage.relationships:
for relationship in lineage.relationships:
print(f'\n\tRelationshipId: {relationship.id}')
print(f'\tRelationshipCreateTime: {relationship.create_time}')
task = relationship.task
attributes = task.attributes
if attributes and 'taskId' in attributes and 'taskInstanceId' in attributes:
print(f'\tTaskId: {attributes["taskId"]}')
print(f'\tTaskInstanceId: {attributes["taskInstanceId"]}')
except Exception as error:
# 本番環境では、堅牢な例外処理を実装してください。
print(error)
UtilClient.assert_as_string(str(error))
if __name__ == '__main__':
LineageQuerySample.main()