このドキュメントでは、DataWorks OpenAPI (2024-05-18) を使用して、データテーブルとフィールドのリネージをプログラムでクエリする方法を説明します。具体的な API 呼び出しの例と SDK コードを提供し、迅速な利用開始と、自動化されたバッチリネージ分析の実行を支援します。
データリネージとは
重要なビジネスレポートで、今四半期の売上が大幅に増加したとします。慎重なデータアナリストやマネージャーであれば、いくつかの疑問が頭に浮かぶでしょう:
この「売上」メトリックはどのように計算されていますか?
ソースとなるビジネスデータは何ですか?注文テーブルからですか、それとも支払いトランザクションテーブルからですか?
データはソースから最終レポートに至るまで、クリーニング、変換、集約など、どのような処理ステップを経ていますか?
このメトリックのデータにエラーがある場合、どの下流のレポートやアプリケーションに影響しますか?
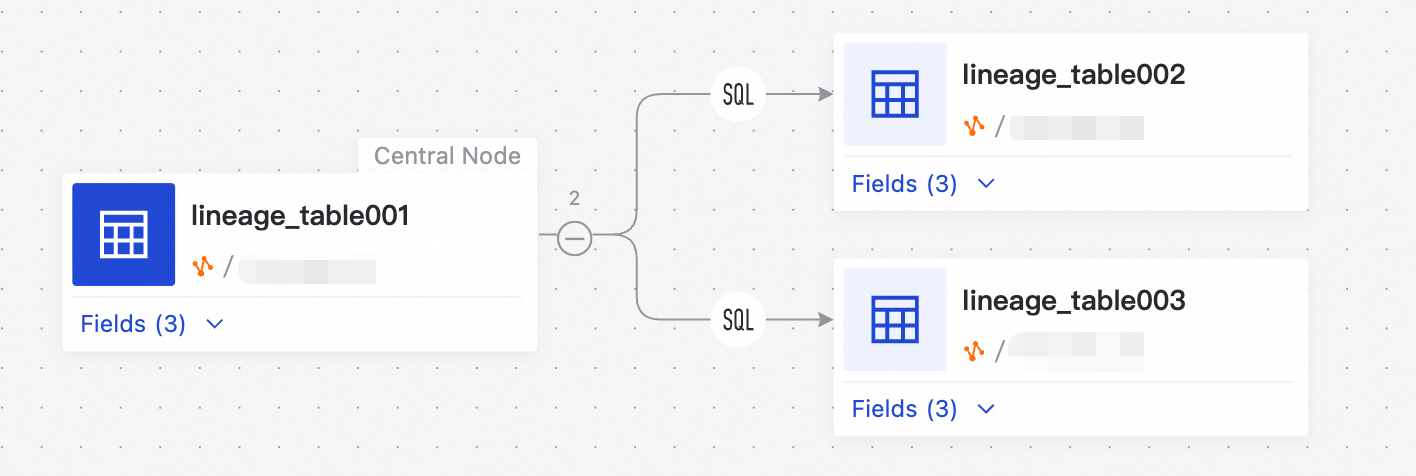
明確なデータリネージは不可欠です。これには、次のようなコアとなる利点があります:
データのトレーサビリティとトラブルシューティング
データの異常やエラーを発見した場合、リネージを上流にトレースすることで、問題の原因となった処理ステップやソースデータを迅速に特定できます。これにより、トラブルシューティングの時間が大幅に短縮されます。影響分析
テーブルスキーマ、フィールド、または計算ロジックを変更する必要がある場合、リネージを下流に分析できます。これにより、どの下流のデータやビジネスレポートが影響を受けるかを正確に評価できます。これは、1 つの変更が広範囲にわたる問題を引き起こすという未知のリスクを回避するのに役立ちます。データガバナンスと信頼性
明確なリネージは、データ資産管理、データ標準の実装、および Data Quality モニタリングの基盤です。これにより、データライフサイクル全体が透明になり、ビジネスユーザーのデータに対する信頼が高まります。コスト最適化と資産インベントリ
リネージを分析することで、下流のコンシューマーがいないデータテーブルやコンピューティングタスクを特定できます。これは、データウェアハウスのコスト最適化や、古い資産を非公開にするための根拠となります。
DataWorks は、MaxCompute SQL や EMR Spark などのさまざまなコンピューティングタスクによって生成されたデータリネージを自動的に解析し、記録します。DataWorks OpenAPI を使用すると、このリネージ情報にプログラムでアクセスできます。その後、リネージ分析を独自のデータ管理プラットフォームや自動化された O&M プロセスに統合できます。
事前準備:エンティティ ID の取得
リネージをクエリする前に、まずターゲットデータ (テーブルまたはフィールド) の一意の識別子を取得する必要があります。この識別子は エンティティ ID です。エンティティ ID は、メタデータおよびリネージ関連の API を呼び出すためのコアとなる認証情報です。
エンティティ ID は、次の 2 つの方法のいずれかで取得できます:
1. DataWorks インターフェイスからの ID 取得
少数の既知のテーブルやフィールドの場合、インターフェイスから ID をコピーするのが最も速い方法です。
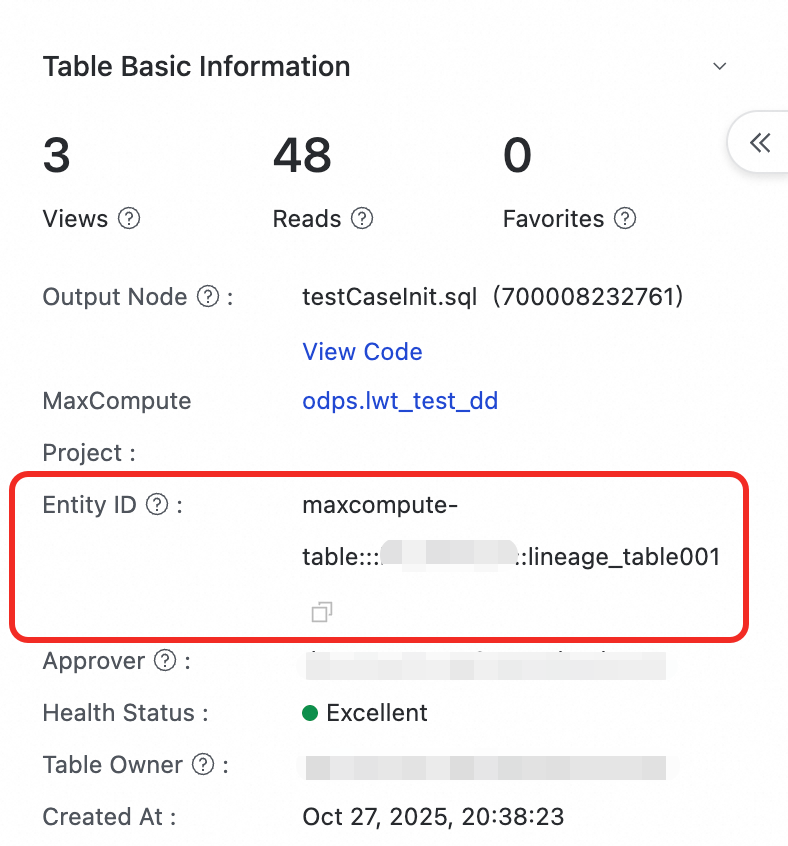
テーブルのエンティティ ID の取得
DataWorks の [データマップ] モジュールに移動します。
クエリしたいテーブルを検索し、その詳細ページを開きます。
左側の Table Basic Information パネルで Entity ID を見つけてコピーします。
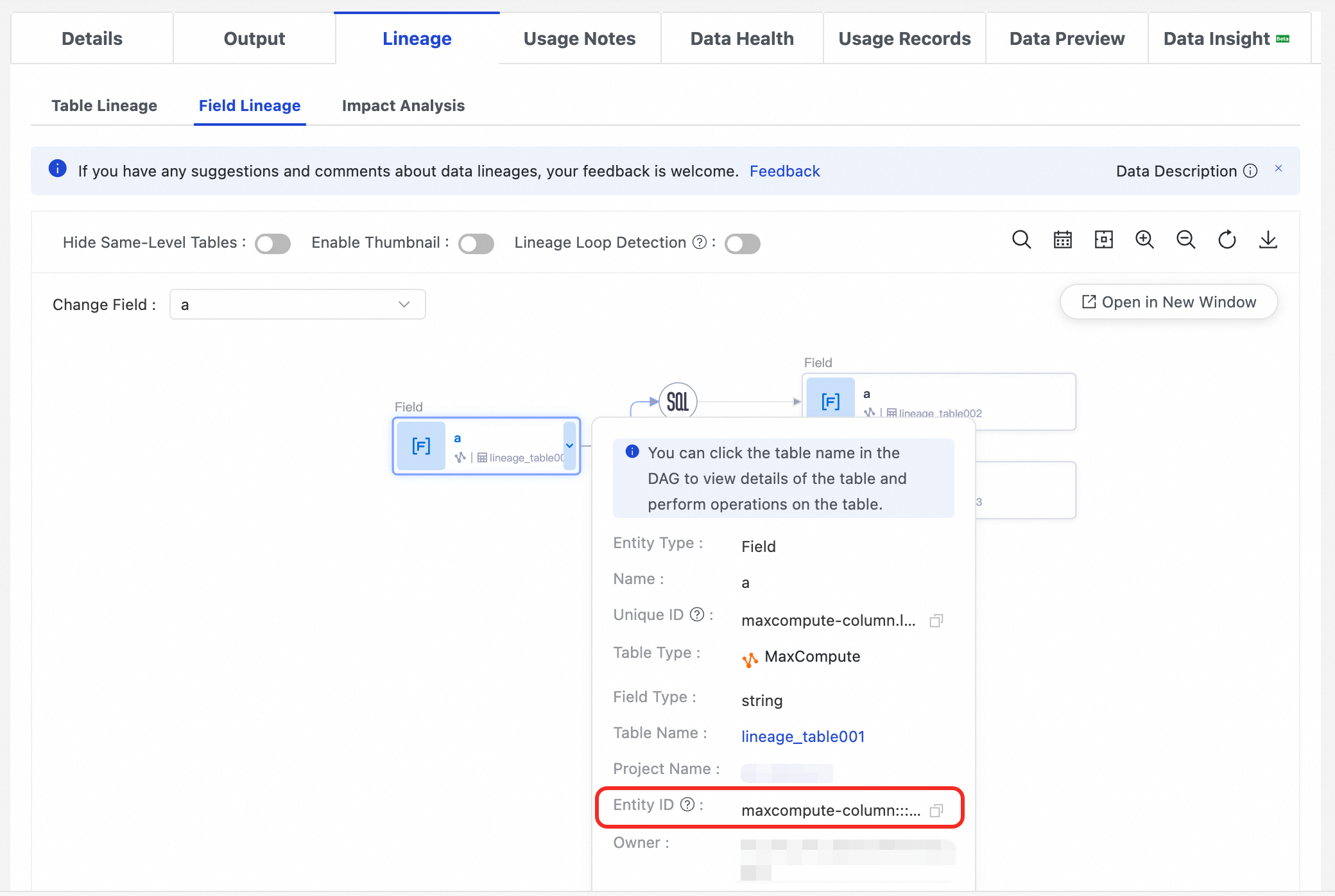
フィールドのエンティティ ID の取得
テーブルの詳細ページで、[リネージ情報] タブに切り替え、[フィールドリネージ] を選択します。
フィールドリネージグラフで、対象のフィールドノードをクリックします。
右側にフィールドの詳細パネルが表示されます。パネルで Entity ID を見つけてコピーします。
2. API を使用した ID の一括取得
多くのエンティティ ID を取得する必要がある場合、手動での操作は非効率です。この場合、OpenAPI を使用してバッチクエリを実行できます:
テーブル ID の一括取得:
ListTablesAPI を呼び出します。詳細については、「ListTables - データマップ内のテーブルのリストのクエリ」をご参照ください。フィールド ID の一括取得:
ListColumnsAPI を呼び出します。詳細については、「ListColumns - データマップテーブル内のフィールドのリストのクエリ」をご参照ください。
ListLineages API によるリネージのクエリ
エンティティ ID を取得すると、コア ListLineages API を使用して、その上流および下流のリネージをクエリできます。
1. コア API パラメーター
次の表に、ListLineages API の主要なリクエストパラメーターを示します。API は OpenAPI Portal でオンラインでテストできます。
パラメーター | 型 | 説明 |
| String | 下流リネージのクエリに使用します。ソース (上流) エンティティ ID を渡します。API はそのエンティティのすべての下流リネージを返します。 |
| String | 上流リネージのクエリに使用します。宛先 (下流) エンティティ ID を渡します。API はそのエンティティのすべての上流リネージを返します。 |
| String |
|
| String |
|
| Boolean | 応答に詳細なリネージ関係情報を含めるかどうかを指定します。完全なコンテキストを取得するには、これを |
SrcEntityIdとDstEntityIdの両方を指定した場合、API は指定された上流エンティティと下流エンティティ間のリネージ関係を返します。SrcEntityIdとDstEntityIdが同じ場合、API はそのエンティティの自己参照リネージ関係を返します。
2. 呼び出し例
エンティティ ID が maxcompute-table:::test_project::test_table である MaxCompute テーブルがあるとします。
例 1:テーブルの下流リネージのクエリ
このテーブルのすべての下流テーブルをクエリするには、これをソースとして設定する必要があります:
SrcEntityId:maxcompute-table:::test_project::test_tableNeedAttachRelationship:true
名前に "report" を含む下流テーブルのみを検索するには、DstEntityName パラメーターを追加します:
DstEntityName:report
例 2:テーブルの上流リネージのクエリ
どのテーブルまたはタスクがこのテーブルを生成したかを調べるには、これを宛先として設定する必要があります:
DstEntityId:maxcompute-table:::test_project::test_tableNeedAttachRelationship:true
SrcEntityName パラメーターを使用して上流ソースをフィルターすることもできます。
3. API 応答の理解
ListLineages の呼び出しが成功すると、リネージ関係のリストが返されます。各関係には、ソースエンティティ、宛先エンティティ、およびそれらの関連情報が含まれます。
単一のリネージ関係応答の例 (JSON):
{
"SrcEntity": {
"Id": "maxcompute-table:::test_project::table_from",
"Name": "table_from",
"Attributes": {
"rawEntityId": "maxcompute-table:::test_project::table_from"
}
},
"DstEntity": {
"Id": "maxcompute-table:::test_project::table_to",
"Name": "table_to",
"Attributes": {
"project": "test_project",
"region": "cn-shanghai",
"table": "table_to"
}
},
"Relationships": [
{
"Id": "123456789:maxcompute-table.test_project.table_from:maxcompute-table.test_project.table_to:maxcompute.SQL.76543xxx",
"CreateTime": 1761089163548,
"Task": {
"Id": "76543xxx",
"Type": "dataworks-sql",
"Attributes": {
"engine": "maxcompute",
"channel": "1st",
"taskInstanceId": "12345xxx",
"projectId": "123456",
"taskId": "76543xxx"
}
}
}
]
}応答の読み方:
SrcEntityとDstEntity:これらはリネージの上流エンティティと下流エンティティを表します。これらのIdを取得し、GetTable または GetColumn API を呼び出して、より詳細なメタデータを取得できます。Relationships:これはSrcEntityとDstEntityがどのように関連しているかを説明します。Task:これは、このリネージ関係を生成したタスクを説明します。タスクが DataWorks のスケジューリングタスクである場合、Task.AttributesにはtaskIdとtaskInstanceIdが含まれます。これらの ID を使用して GetTask API を呼び出し、タスクの詳細な定義と実行ステータスを取得できます。
Java SDK 実践チュートリアル
次の例では、Java SDK を使用して、リネージクエリの完全なプロセスを示します。
1. 環境の準備
JDK バージョン:JDK 8 以降のバージョンがインストールされていることを確認してください。
Maven 依存関係:プロジェクトの
pom.xmlファイルに次の依存関係を追加します。${latest.version}を最新の SDK バージョン番号 に置き換えてください。
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>dataworks_public20240518</artifactId>
<version>${latest.version}</version>
</dependency>2. 完全なコード例
次のコードは、クライアントを初期化し、指定されたテーブルの上流および下流のリネージをクエリし、主要な情報を出力する方法を示しています。
import java.util.List;
import java.util.Map;
import com.aliyun.dataworks_public20240518.Client;
import com.aliyun.dataworks_public20240518.models.GetTableRequest;
import com.aliyun.dataworks_public20240518.models.GetTableResponse;
import com.aliyun.dataworks_public20240518.models.LineageEntity;
import com.aliyun.dataworks_public20240518.models.LineageRelationship;
import com.aliyun.dataworks_public20240518.models.LineageTask;
import com.aliyun.dataworks_public20240518.models.ListLineagesRequest;
import com.aliyun.dataworks_public20240518.models.ListLineagesResponse;
import com.aliyun.dataworks_public20240518.models.ListLineagesResponseBody.ListLineagesResponseBodyPagingInfo;
import com.aliyun.dataworks_public20240518.models.ListLineagesResponseBody.ListLineagesResponseBodyPagingInfoLineages;
import com.aliyun.dataworks_public20240518.models.Table;
import com.aliyun.tea.TeaException;
public class LineageQuerySample {
/**
* 説明