DataHub は、ストリーミングデータを処理するための Alibaba Cloud プラットフォームです。データストリームをパブリッシュ、サブスクライブ、および配信して、データ分析やアプリケーションを構築できます。
プロダクト概要
DataHub は、Alibaba Cloud が提供するストリーミングデータ処理プラットフォームです。データストリームのパブリッシュ、サブスクライブ、配信というコア機能を使用して、ストリーミングデータ向けの分析やアプリケーションを構築できます。
主な機能
データ収集: DataHub は、モバイルデバイス、アプリケーション、Web サービス、センサーなどのさまざまなソースから大量のストリーミングデータを継続的に収集、保存、処理します。
リアルタイム処理: Web アクセスログやアプリケーションイベントなど、DataHub に書き込まれたストリーミングデータは、Flink などのコンピュートエンジンやカスタムアプリケーションで処理できます。この処理により、リアルタイムのチャート、アラートメッセージ、統計などのリアルタイムの結果が生成されます。
全体的なアーキテクチャ
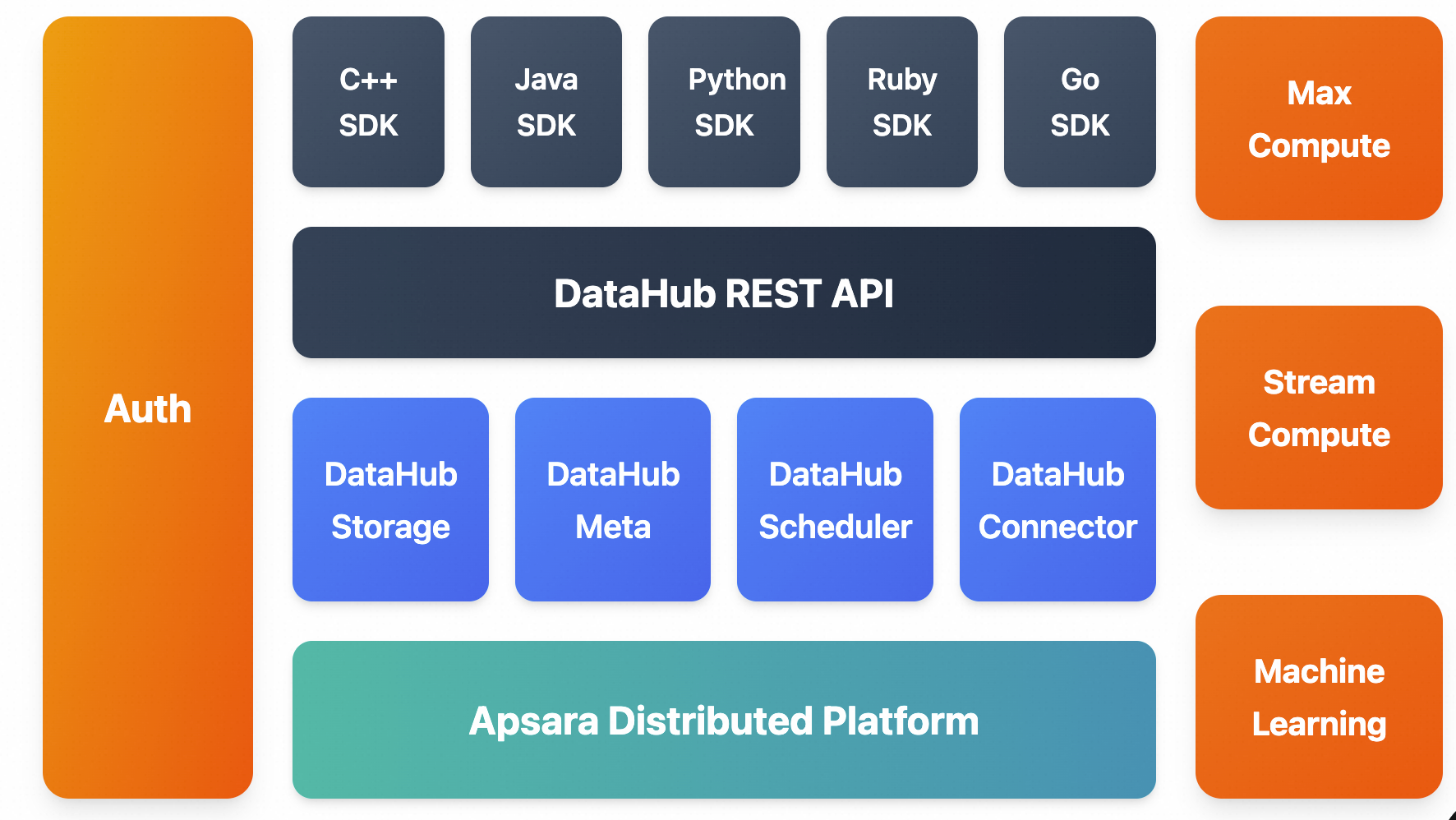
DataHub は、Alibaba Cloud 独自の分散プラットフォームである Apsara 上に構築されています。高可用性、低レイテンシー、高スケーラビリティ、高スループットを特徴としています。
統一された REST API を提供します。アプリケーションは、複数の言語に対応したソフトウェア開発キット (SDK) を使用して API とやり取りできます。
DataHub は、MaxCompute や Flink などの他のクラウドプロダクトやコンピュートエンジンともシームレスに連携します。これにより、SQL を使用してストリームデータ分析を行うことができます。
DataHub は、ストリーミングデータをさまざまなクラウドプロダクトに配信することもできます。現在、MaxCompute (旧 ODPS) および OSS への配信をサポートしています。
利点
高スループット: 単一の Shard で 1 日あたり最大 1 億 6000 万回の書き込みをサポートします。
タイムリー性: DataHub はさまざまなソースからのデータをリアルタイムで収集および処理するため、ビジネスニーズに迅速に対応できます。
使いやすさ
C++、Java、Python、Go などの言語用の SDK を提供します。
カスタムアクセスインターフェイスをサポートする RESTful API 仕様を提供します。
Fluentd、Logstash、Flume などの一般的なクライアントプラグインを提供します。
厳密なスキーマを持つ構造化データ (TUPLE タイプの Topic を作成) と非構造化データ (BLOB タイプの Topic を作成) の両方をサポートします。
高可用性
サービスの可用性は 99.9% 以上です。
データの耐久性は 99.999% 以上です。
外部サービスに影響を与えることなく自動的にスケールします。
DataHub は冗長性のための自動バックアップをサポートしています。
動的スケーリング
各 Topic のデータストリームスループット容量は動的にスケールアップまたはスケールダウンでき、Topic あたり最大
256,000 Records/sのスループットに達します。高セキュリティ
エンタープライズグレードの多層セキュリティ保護とマルチユーザーリソースの隔離を提供します。
DataHub は複数の認証および権限付与メソッドをサポートしています。たとえば、ホワイトリストを構成したり、Resource Access Management (RAM) を使用して権限を付与したりできます。
シナリオ
ストリーミングデータ処理サービスとして、DataHub は他の Alibaba Cloud プロダクトと組み合わせて、完全なデータ処理ソリューションを構築できます。
ストリームコンピューティング (StreamCompute)
Real-time Compute for Apache Flink は、ストリーム処理のための SQL ライクな言語を提供する Alibaba Cloud のストリームコンピューティングエンジンです。DataHub は Flink とシームレスに統合し、データソースと出力先の両方として機能します。詳細については、「リアルタイムコンピューティング (ストリームコンピューティング)」をご参照ください。
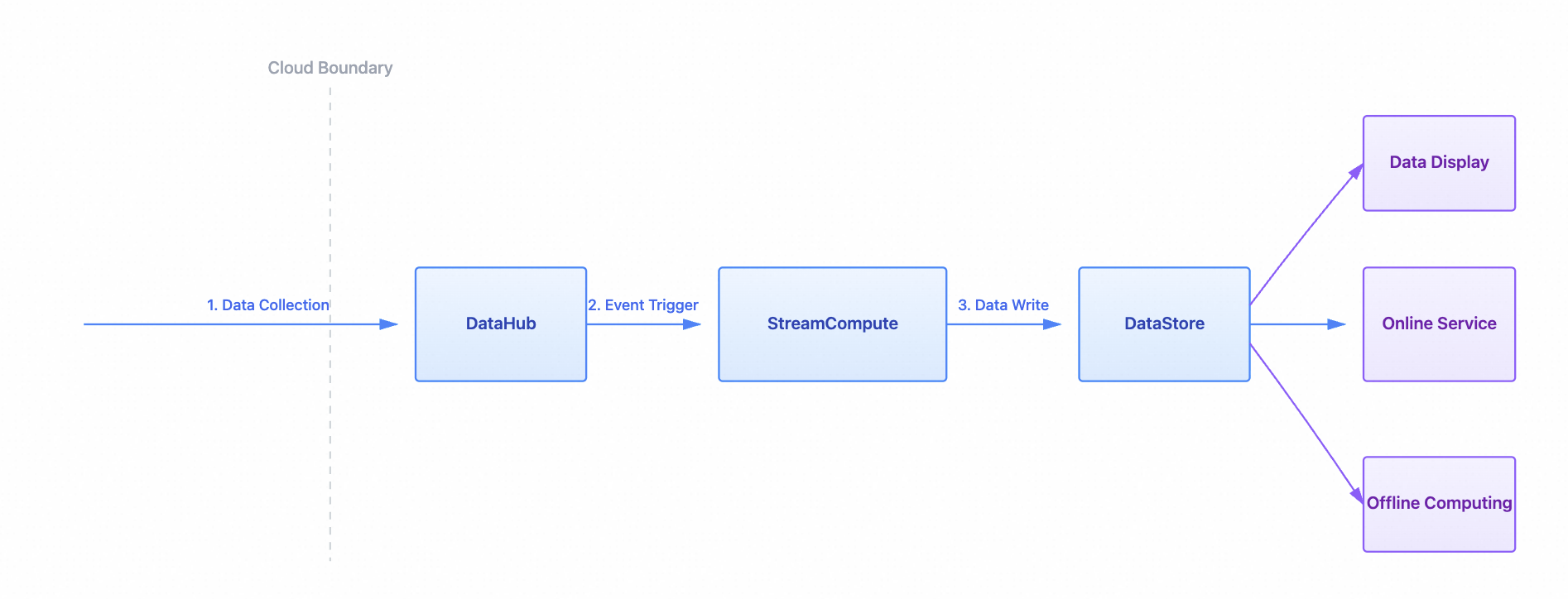
ストリーム処理アプリケーション
カスタムアプリケーションは DataHub のデータをサブスクライブし、リアルタイムで処理して結果を出力できます。あるアプリケーションからの結果を DataHub に送り返し、別のアプリケーションで処理させることができます。これにより、データ処理ワークフローの有向非循環グラフ (DAG) を構築できます。
ストリーミングデータのアーカイブ
ストリーミングデータは MaxCompute (旧 ODPS) にアーカイブできます。DataHub コネクタを作成し、必要な構成を指定して、DataHub からストリーミングデータを定期的にアーカイブする同期タスクを設定できます。