このトピックでは、training-nv-pytorch 25.12 のリリースノートについて説明します。
主な特徴とバグ修正
主な特徴
vLLM を 0.12.0 に、flashinfer-python を 0.5.3 にアップグレードしました。
バグ修正
なし。
内容
イメージ名 | training-nv-pytorch | |
タグ | 25.12-cu130-serverless | 25.12-cu128-serverless |
シナリオ | トレーニング/推論 | |
フレームワーク | PyTorch | |
要件 | NVIDIA ドライバーリリース >= 580 | NVIDIA ドライバーリリース >= 575 |
サポートされているアーキテクチャ | amd64 & aarch64 | amd64 |
主要コンポーネント |
|
|
アセット
パブリックイメージ
CUDA 13.0.2 (ドライバー >= 580、amd64 & aarch64)
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.12-cu130-serverless
CUDA 12.8 (ドライバー >= 575、amd64)
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.12-cu128-serverless
VPC イメージ
VPC 内から ACS AI コンテナイメージのプルを高速化するには、アセット URI egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/{image:tag} を acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag} に置き換えます。
{region-id}:ご利用の ACS プロダクトが配置されている利用可能なリージョンのリージョン ID です。例:cn-beijing、cn-wulanchabu。{image:tag}:AI コンテナイメージの名前とタグです。例:inference-nv-pytorch:25.10-vllm0.11.0-pytorch2.8-cu128-20251028-serverless、training-nv-pytorch:25.10-serverless。
このイメージは ACS プロダクトおよび Lingjun マルチテナントプロダクトに適しています。Lingjun シングルテナントプロダクトには適していません。Lingjun シングルテナントシナリオでは使用しないでください。
ドライバー要件
25.12 リリースは、異なるドライバーバージョンに基づいて CUDA 12.8.0 と CUDA 13.0.2 をサポートします。CUDA 13.0.2 には NVIDIA ドライバーバージョン 580 以降が必要です。CUDA 12.8.0 には NVIDIA ドライバーバージョン 575 以降が必要です。サポートされているドライバーの完全なリストについては、CUDA アプリケーションの互換性のトピックをご参照ください。詳細については、「CUDA の互換性とアップグレード」をご参照ください。
主な特徴と機能強化
PyTorch コンパイルの最適化
PyTorch 2.0 で導入されたコンパイル最適化機能は、1 つの GPU での小規模なトレーニングに適しています。しかし、LLM トレーニングには GPU メモリの最適化と、FSDP や DeepSpeed などの分散フレームワークが必要です。その結果、torch.compile() はトレーニングにメリットをもたらさないか、またはマイナスの影響を与える可能性があります。
DeepSpeed フレームワークで通信の粒度を制御することで、コンパイラが完全な計算グラフを取得し、より広い範囲でのコンパイル最適化が可能になります。
最適化された PyTorch:
PyTorch コンパイラのフロントエンドが最適化され、計算グラフ内でグラフブレークが発生した場合でもコンパイルが保証されます。
モードマッチングと動的シェイプ機能が強化され、コンパイルされたコードが最適化されます。
上記の最適化により、8B LLM のトレーニング時に E2E スループットが 20% 向上します。
再計算による GPU メモリの最適化
異なるクラスターにデプロイされたモデルや、異なるパラメーターで構成されたモデルに対してパフォーマンステストを実行し、GPU メモリ使用率などのシステムメトリクスを収集することで、モデルの GPU メモリ消費量を予測・分析します。その結果に基づき、アクティベーション再計算レイヤーの最適な数を提案し、それを PyTorch に統合します。これにより、ユーザーは GPU メモリ最適化の恩恵を容易に受けることができます。現在、この機能は DeepSpeed フレームワークで使用できます。
E2E パフォーマンス効果の評価
クラウドネイティブ AI パフォーマンス評価・分析ツール CNP を使用して、包括的なエンドツーエンドのパフォーマンス比較を実施しました。主流のオープンソースモデルとフレームワーク構成を使用し、標準のベースイメージと比較しました。また、各最適化コンポーネントがモデル全体のトレーニングパフォーマンスに与える貢献度を評価するために、アブレーション実験も実施しました。
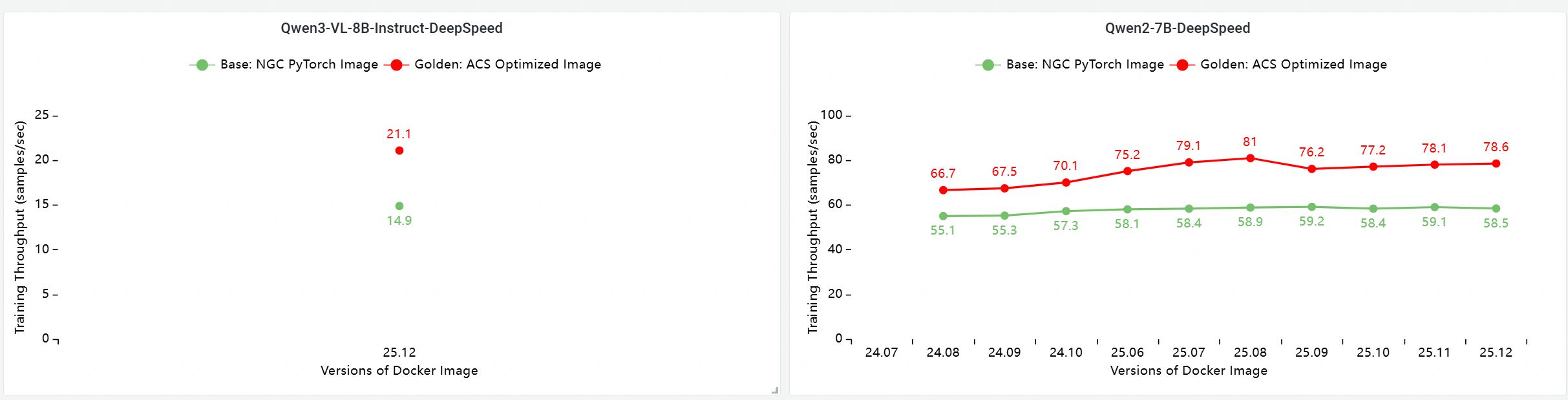
イメージ比較:ベースイメージと反復評価
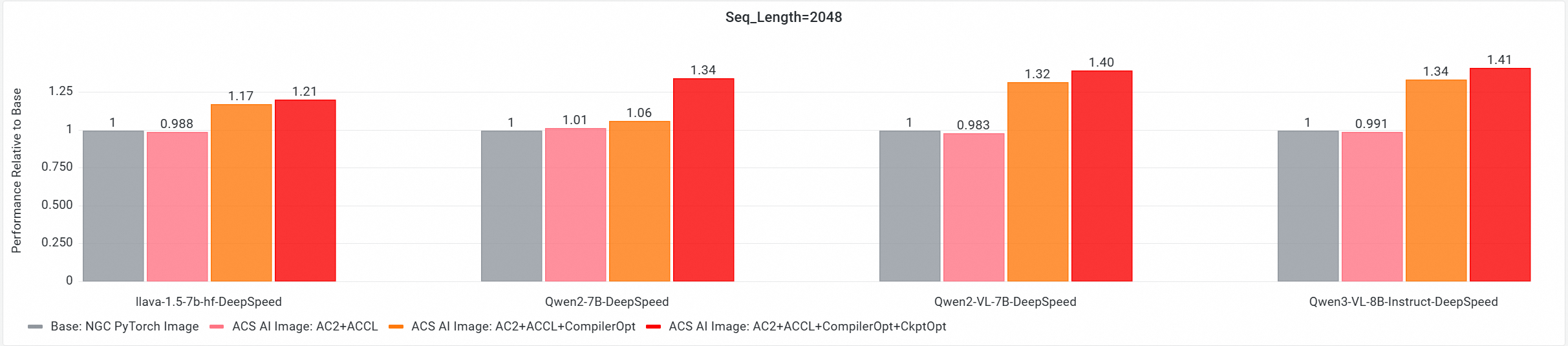
コア GPU コンポーネントの E2E パフォーマンス貢献度分析
以下のテストはバージョン 25.12 に基づいています。マルチノード GPU クラスターでのトレーニングにおける E2E パフォーマンスの評価と比較を示しています。比較項目は以下の通りです:
Base: NGC PyTorch イメージ
ACS AI Image: Base+ACCL: ACCL 通信ライブラリを使用するイメージです。
ACS AI Image: AC2+ACCL: 最適化が有効になっていない AC2 BaseOS を使用するイメージです。
ACS AI Image: AC2+ACCL+CompilerOpt: torch コンパイル最適化のみを有効にした AC2 BaseOS を使用するイメージです。
ACS AI Image: AC2+ACCL+CompilerOpt+CkptOpt: torch コンパイルと選択的勾配チェックポイント最適化の両方を有効にした AC2 BaseOS を使用するイメージです。
クイックスタート
以下の例は、Docker を使用して training-nv-pytorch イメージをプルする方法を示しています。
ACS で training-nv-pytorch イメージを使用するには、ワークロードを作成する際にコンソールの [Artifacts] ページから選択するか、YAML ファイルでイメージリファレンスを指定します。
1. イメージの選択
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. API を呼び出してコンパイラと GPU メモリ最適化のための再計算を有効化
コンパイル最適化の有効化
transformers Trainer API を使用します:

GPU メモリ最適化のための再計算の有効化
export CHECKPOINT_OPTIMIZATION=true
3. コンテナーの起動
このイメージには、ljperf という名前の組み込みモデルトレーニングツールが含まれています。以下の手順では、このツールを使用してコンテナーを起動し、トレーニングジョブを実行する方法を示します。
LLM クラス
# コンテナーを起動して中に入る
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# トレーニングデモを実行
ljperf benchmark --model deepspeed/llama3-8b 4. 推奨事項
イメージの変更には PyTorch や DeepSpeed などのライブラリが含まれます。これらを再インストールしないでください。
DeepSpeed 構成の `zero_optimization.stage3_prefetch_bucket_size` は空にするか、`auto` に設定してください。
このイメージに組み込まれている環境変数
NCCL_SOCKET_IFNAMEは、シナリオに応じて動的に調整する必要があります:単一の Pod がトレーニングまたは推論タスクのために 1、2、4、または 8 枚のカードをリクエストする場合、
NCCL_SOCKET_IFNAME=eth0を設定します。これはこのイメージのデフォルト構成です。単一の Pod がトレーニングまたは推論タスクのためにマシン上の全 16 枚のカードをリクエストする場合、High-Performance Network (HPN) を使用できます。
NCCL_SOCKET_IFNAME=hpn0を設定します。
既知の問題
CUDA 13.0.2 イメージ上で fa3 を直接コンパイルするとエラーが発生します。これは既知のコミュニティの問題です。