本ドキュメントは、training-nv-pytorch 25.10 コンテナイメージのリリースノートです。
新機能
主な特徴
-
amd64 および aarch64 のマルチアーキテクチャをサポートし。
-
megatron-core を 0.14.0 に、transformer_engine を 2.4 にアップグレードし、最新のコミュニティ機能を取り込みました。
-
vLLM を 0.11.0 にアップグレードし、最新のコミュニティ機能を取り込みました。
バグ修正
本リリースではバグ修正はありません。
構成内容
|
Aarch64 アーキテクチャ |
Amd64 アーキテクチャ |
|
|
ユースケース |
トレーニング / 推論 |
トレーニング / 推論 |
|
フレームワーク |
PyTorch |
PyTorch |
|
要件 |
NVIDIA ドライバー >= 575 |
NVIDIA ドライバー >= 575 |
|
コアコンポーネント |
Ubuntu:24.04 CUDA:12.8 Python:3.12.7+gc torch:2.8.0.9+nv25.3 accelerate:1.7.0+ali deepspeed:0.16.9+ali diffusers:0.34.0 flash_attn:2.8.3 flash_attn_3:3.0.0b1 flashinfer-python:0.2.5 gdb:15.0.50.20240403-git grouped_gemm:1.1.4 megatron-core:0.14.0 mmcv:2.1.0 mmdet:3.3.0 mmengine:0.10.3 opencv-python-headless:4.11.0.86 peft:0.16.0 pytorch-dynamic-profiler:0.24.11 pytorch-triton:3.4.0 ray:2.50.1 timm:1.0.20 transformer_engine:2.4.0+3cd6870c transformers:4.56.1+ali ultralytics:8.3.96 vllm:0.11.0 |
Ubuntu:24.04 CUDA:12.8 Python:3.12.7+gc torch:2.8.0.9+nv25.3 accelerate:1.7.0+ali deepspeed:0.16.9+ali diffusers:0.34.0 flash_attn:2.8.3 flash_attn_3:3.0.0b1 flashinfer-python:0.2.5 gdb:15.0.50.20240403-git grouped_gemm:1.1.4 megatron-core:0.14.0 mmcv:2.1.0 mmdet:3.3.0 mmengine:0.10.3 opencv-python-headless:4.11.0.86 peft:0.16.0 perf:5.4.30 pytorch-dynamic-profiler:0.24.11 ray:2.50.1 timm:1.0.20 transformer_engine:2.4.0+3cd6870c transformers:4.56.1+ali triton:3.4.0 ultralytics:8.3.96 vllm:0.11.0 |
アセット
25.10
-
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.10-serverless
VPC イメージ
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}は、ACS がアクティブ化されているリージョン (cn-beijing、cn-wulanchabu など) を示します。{image:tag}は、イメージの名前とタグを示します。
現在、VPC 経由でプルできるイメージは、中国 (北京) リージョンのイメージのみです。
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.10-serverless イメージは、ACS および Lingjun マルチテナント製品タイプに対応しています。このイメージは、Lingjun シングルテナント製品タイプには対応していません。Lingjun シングルテナントシナリオでは、このイメージを使用しないでください。
ドライバー要件
-
25.10 リリースは CUDA 12.8.0 に基づいており、NVIDIA ドライバーバージョン 575 以降が必要です。ただし、データセンター GPU (T4 やその他のデータセンター GPU) で実行している場合は、R470 (470.57 以降)、R525 (525.85 以降)、R535 (535.86 以降)、または R545 (545.23 以降) シリーズのドライバーも使用できます。
-
R418、R440、R450、R460、R510、R520、R530、R555、および R560 ドライバーシリーズは、CUDA 12.8 との前方互換性がないため、アップグレードする必要があります。サポートされているドライバーの完全なリストについては、CUDA Application Compatibility をご参照ください。詳細については、CUDA Compatibility and Upgrades をご参照ください。
主な機能と機能強化
PyTorch コンパイルの最適化
PyTorch 2.0 で導入されたコンパイル最適化機能は、1 つの GPU での小規模トレーニングに適しています。ただし、LLM トレーニングには、GPU メモリの最適化と、FSDP や DeepSpeed などの分散フレームワークが必要です。その結果、torch.compile() はトレーニングにメリットをもたらすことができず、デメリットが生じる可能性があります。
DeepSpeed フレームワークで通信の粒度を制御することで、コンパイラはより広範囲のコンパイル最適化のための完全な計算グラフを取得できます。
最適化された PyTorch:
PyTorch コンパイラのフロントエンドが最適化され、計算グラフでグラフの分割が発生した場合にコンパイルが確実に行われるようになりました。
モードマッチングと動的シェイプ機能が強化され、コンパイル済みコードが最適化されました。
上記の最適化後、8B LLM をトレーニングする場合の E2E スループットが 20% 向上しました。
再計算のための GPU メモリの最適化
さまざまなクラスターにデプロイされたモデル、またはさまざまなパラメーターで構成されたモデルのパフォーマンステストを実行し、GPU メモリ使用率などのシステムメトリックを収集することで、モデルの GPU メモリ消費量を予測および分析します。結果に基づいて、最適なアクティベーション再計算レイヤー数を提案し、PyTorch に統合します。これにより、ユーザーは GPU メモリの最適化を簡単に利用できます。現在、この機能は DeepSpeed フレームワークで使用できます。
E2E パフォーマンス評価
クラウドネイティブ AI パフォーマンスベンチマークツール CNP を使用して、主流のオープンソースモデルとフレームワーク構成を用いて、本イメージと標準ベースイメージとの包括的なエンドツーエンドパフォーマンス比較を行いました。また、各最適化コンポーネントのパフォーマンスへの貢献度を評価するためのアブレーションスタディも実施しました。
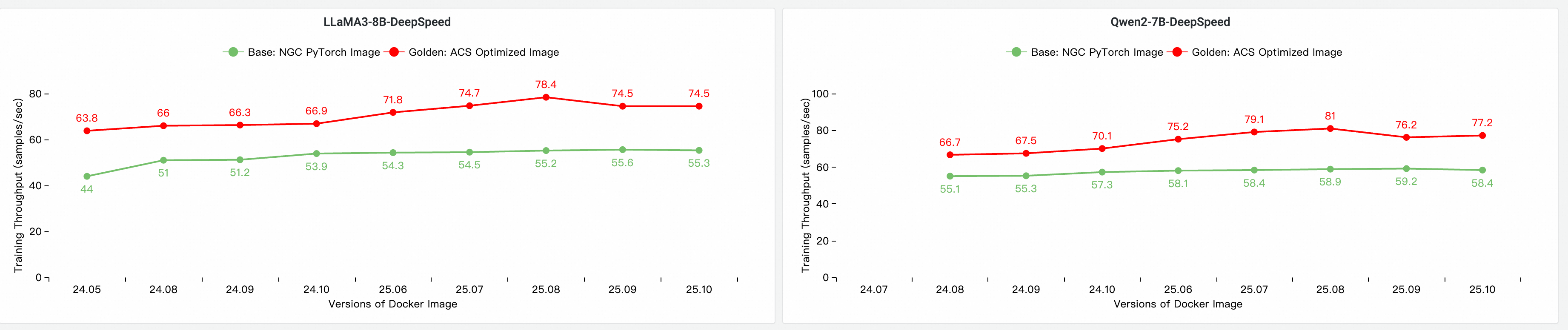
イメージ比較:ベースイメージと本イメージ
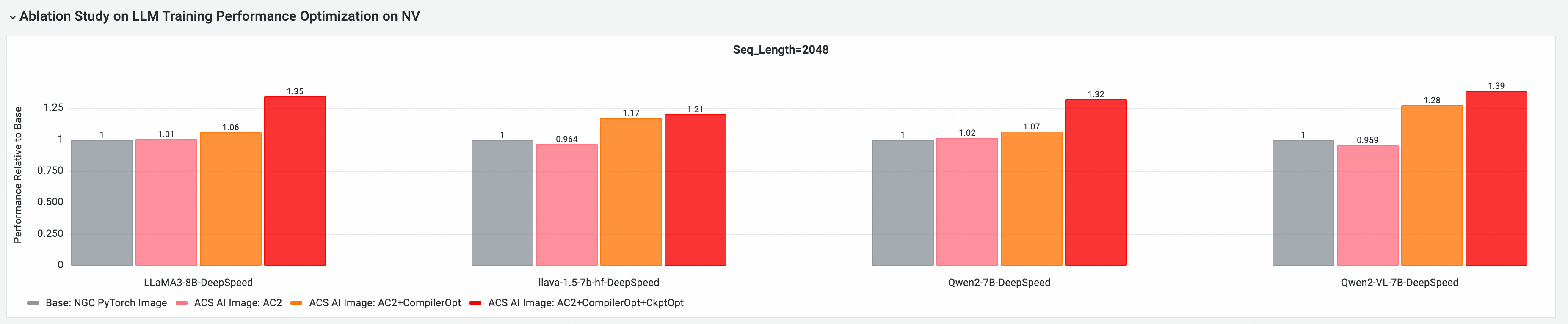
コア GPU コンポーネントの E2E パフォーマンスへの貢献度
バージョン 25.10 に基づき、マルチノード GPU クラスタ上でテストを実行し、エンドツーエンドのトレーニングパフォーマンスを評価および比較しました。比較した構成は次のとおりです。
-
Base:標準 NGC PyTorch イメージ。
-
ACS AI Image (AC2):AC2 BaseOS を使用し、最適化を有効にしていない本イメージ。
-
ACS AI Image (AC2+CompilerOpt):AC2 BaseOS を使用し、torch compile 最適化のみを有効にした本イメージ。
-
ACS AI Image (AC2+CompilerOpt+CkptOpt):AC2 BaseOS を使用し、torch compile と選択的勾配チェックポインティングの両方の最適化を有効にした本イメージ。
クイックスタート
以下の例は、Docker を使用して training-nv-pytorch イメージをプルする方法を示しています。
ACS で training-nv-pytorch イメージを使用するには、コンソールでワークロードを作成する際に **[Artifact Center]** ページから選択するか、YAML ファイルでイメージを指定してください。
1. イメージのプル
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. 最適化の有効化
-
コンパイラ最適化の有効化
transformers Trainer API を使用する場合:
training_args = TrainingArguments( bf16=True, gradient_checkpointing=True, torch_compile=True ) -
勾配チェックポインティング最適化の有効化
export CHECKPOINT_OPTIMIZATION=true
3. コンテナの起動
モデルトレーニングツール ljperf がイメージに組み込まれており、ここではこれを使用してコンテナの起動とトレーニングタスクの実行手順を説明します。
LLM の例
# コンテナを起動して内部に入ります
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# トレーニングデモを実行します
ljperf benchmark --model deepspeed/llama3-8b 4. 推奨事項
-
このイメージには、PyTorch や DeepSpeed などのライブラリに対して独自の変更が加えられています。これらのパッケージを再インストールすると、最適化が上書きされるため、再インストールしないでください。
-
DeepSpeed 構成では、
zero_optimization.stage3_prefetch_bucket_sizeパラメータを空のままにするか、autoに設定してください。 -
このイメージに組み込まれている環境変数
NCCL_SOCKET_IFNAMEは、使用シナリオに基づいて動的に調整する必要があります。-
単一の Pod がトレーニングまたは推論タスクのために 1、2、4、または 8 個の GPU を要求する場合、
NCCL_SOCKET_IFNAME=eth0を設定する必要があります。これは、このイメージのデフォルト設定です。 -
単一の Pod がトレーニングまたは推論タスクのためにマシン上のすべての 16 個の GPU を要求する場合、High-Performance Network (HPN) を使用するために
NCCL_SOCKET_IFNAME=hpn0を設定してください。
-