このドキュメントは、training-nv-pytorch 25.08 のリリースノートです。
主な特徴とバグ修正
主な特徴
-
transformers を 4.53.3+ali にアップグレードしました。
-
vllm を 0.10.0 に、ray を 2.48.0 にアップグレードしました。
バグ修正
このリリースでのバグ修正はありません。
内容
|
ユースケース |
トレーニング/推論 |
|
フレームワーク |
PyTorch |
|
要件 |
NVIDIA ドライバーバージョン >= 575 |
|
コアコンポーネント |
|
アセット
25.08
-
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.08-serverless
VPC イメージ
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}は、ACS がアクティブ化されているリージョン (cn-beijing、cn-wulanchabu など) を示します。{image:tag}は、イメージの名前とタグを示します。
現在、VPC 経由でプルできるイメージは、中国 (北京) リージョンのイメージのみです。
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.08-serverless イメージは、ACS 製品およびマルチテナントの Lingjun 環境向けです。このイメージはシングルテナントの Lingjun デプロイには対応していないため、このようなシナリオでは使用しないでください。
ドライバー要件
-
25.08 リリースは CUDA 12.8.0 をベースにしているため、NVIDIA ドライバーバージョン 575 以降が必要です。ただし、T4 などのデータセンター GPU で実行している場合は、NVIDIA ドライバーバージョン 470.57 (または R470 の後続リリース)、525.85 (または R525 の後続リリース)、535.86 (または R535 の後続リリース)、または 545.23 (または R545 の後続リリース) を使用できます。
-
CUDA ドライバー互換性パッケージは特定のドライバーのみをサポートします。したがって、R418、R440、R450、R460、R510、R520、R530、R545、R555、または R560 ドライバーは CUDA 12.8 と前方互換性がないため、アップグレードする必要があります。サポートされているドライバーの完全なリストについては、「CUDA Application Compatibility」をご参照ください。詳細については、「CUDA Compatibility and Upgrades」をご参照ください。
主な機能と拡張機能
PyTorch コンパイルの最適化
PyTorch 2.0 で導入されたコンパイル最適化機能は、1 つの GPU での小規模トレーニングに適しています。ただし、LLM トレーニングには、GPU メモリの最適化と、FSDP や DeepSpeed などの分散フレームワークが必要です。その結果、torch.compile() はトレーニングにメリットをもたらすことができず、デメリットが生じる可能性があります。
DeepSpeed フレームワークで通信の粒度を制御することで、コンパイラはより広範囲のコンパイル最適化のための完全な計算グラフを取得できます。
最適化された PyTorch:
PyTorch コンパイラのフロントエンドが最適化され、計算グラフでグラフの分割が発生した場合にコンパイルが確実に行われるようになりました。
モードマッチングと動的シェイプ機能が強化され、コンパイル済みコードが最適化されました。
上記の最適化後、8B LLM をトレーニングする場合の E2E スループットが 20% 向上しました。
再計算のための GPU メモリの最適化
さまざまなクラスターにデプロイされたモデル、またはさまざまなパラメーターで構成されたモデルのパフォーマンステストを実行し、GPU メモリ使用率などのシステムメトリックを収集することで、モデルの GPU メモリ消費量を予測および分析します。結果に基づいて、最適なアクティベーション再計算レイヤー数を提案し、PyTorch に統合します。これにより、ユーザーは GPU メモリの最適化を簡単に利用できます。現在、この機能は DeepSpeed フレームワークで使用できます。
ACCL
ACCL は、Alibaba Cloud が Lingjun 向けに提供する、独自の HPN 通信ライブラリです。GPU アクセラレーションシナリオ向けの ACCL-N を提供します。ACCL-N は、NCCL をベースにカスタマイズされた HPN ライブラリです。NCCL と完全に互換性があり、NCCL のいくつかのバグを修正しています。ACCL-N は、より高いパフォーマンスと安定性も提供します。
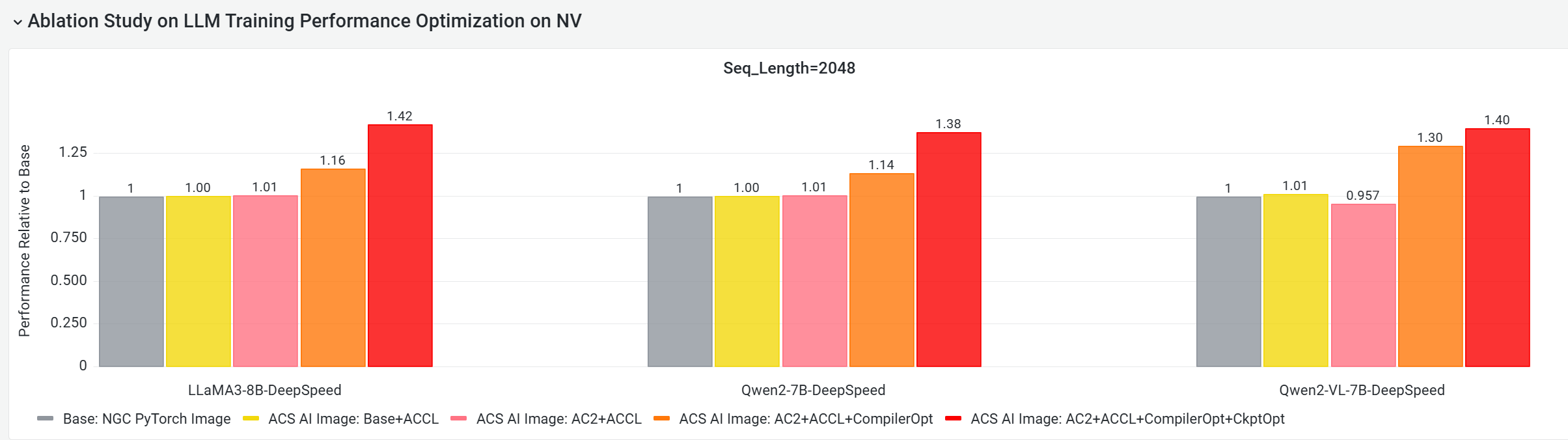
E2E パフォーマンスゲイン評価
CNP クラウドネイティブ AI パフォーマンス分析ツールを使用し、主流のオープンソースモデルとフレームワーク構成を用いて、このイメージのエンドツーエンドのパフォーマンスを標準のベースイメージと比較しました。アブレーションスタディを通じて、各最適化コンポーネントがモデル全体のトレーニングパフォーマンスにどの程度貢献しているかをさらに評価しました。
コア GPU コンポーネントの E2E パフォーマンス貢献度分析
マルチノード GPU クラスターで実施した以下のテストでは、これらの構成の E2E トレーニングパフォーマンスを比較しています:
-
Base: NGC PyTorch イメージ。
-
ACS AI Image: Base+ACCL: ACCL 通信ライブラリを使用するイメージ。
-
ACS AI Image: AC2+ACCL: AC2 BaseOS 上のイメージで、ACCL を使用し、他の最適化は行われていないもの。
-
ACS AI Image: AC2+ACCL+CompilerOpt: AC2 BaseOS 上のイメージで、
torch.compile()最適化のみが有効化されているもの。 -
ACS AI Image: AC2+ACCL+CompilerOpt+CkptOpt: AC2 BaseOS 上のイメージで、
torch.compile()と選択的勾配チェックポイント最適化の両方が有効化されているもの。
クイックスタート
以下に、Docker を使用して training-nv-pytorch イメージをプルする方法を示します。
ACS で training-nv-pytorch イメージを使用するには、コンソールでワークロードを作成する際にコンテナレジストリページから選択するか、YAML ファイルで指定します。
1. イメージのプル
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. 最適化の有効化
-
コンパイルの最適化を有効化
transformers Trainer API の場合:
training_args = TrainingArguments( bf16=True, gradient_checkpointing=True, torch_compile=True ) -
選択的勾配チェックポイント最適化を有効化
export CHECKPOINT_OPTIMIZATION=true
3. コンテナの起動
次の例では、付属の ljperf ツールを使用して、コンテナを起動し、トレーニングジョブを実行します。
LLM の場合
# コンテナを起動してコンテナに入る
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# トレーニングデモを実行する
ljperf benchmark --model deepspeed/llama3-8b 4. 推奨事項
-
このイメージには、PyTorch や DeepSpeed などのライブラリの修正版が含まれています。これらを再インストールしないでください。
-
DeepSpeed の設定で、
zero_optimization.stage3_prefetch_bucket_sizeは空にするか、autoに設定してください。 -
イメージに含まれる組み込みの環境変数
NCCL_SOCKET_IFNAMEを、シナリオに応じて設定してください:-
単一の Pod がトレーニングまたは推論タスクに 1、2、4、または 8 個の GPU のみを要求する場合、
NCCL_SOCKET_IFNAME=eth0を設定する必要があります (これはこのイメージのデフォルト設定です)。 -
単一の Pod がトレーニングまたは推論タスクのためにマシン全体の 16 個すべての GPU を要求する場合、HPN 高性能ネットワークを使用するには、
NCCL_SOCKET_IFNAME=hpn0を設定します。
-
既知の問題
現在ありません。