このリリースノートでは、training-nv-pytorch 25.06 の更新について説明します。
更新内容
新機能
-
このリリースでは、PyTorch および関連コンポーネントを v2.7.1.8 に、Triton を v3.3.0 に、vLLM を v0.9.1 にアップグレードし、新しい Blackwell アーキテクチャのサポートを追加しました。
バグ修正
-
PyTorch を v2.7.1.8 にアップグレードし、旧イメージにおける VRAM 最適化パフォーマンスの低下を修正しました。
イメージの詳細
|
シナリオ |
トレーニング / 推論 |
|
フレームワーク |
PyTorch |
|
要件 |
NVIDIA ドライバーバージョン 575 以降 |
|
コアコンポーネント |
|
利用可能なイメージ
25.06
-
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.06-serverless
VPC イメージ
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}は、ACS がアクティブ化されているリージョン (cn-beijing、cn-wulanchabu など) を示します。{image:tag}は、イメージの名前とタグを示します。
現在、VPC 経由でプルできるイメージは、中国 (北京) リージョンのイメージのみです。
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.06-serverless イメージは Alibaba Cloud コンテナコンピューティングサービス (ACS) および Lingjun マルチテナントサービスモデルに適しています。このイメージは Lingjun シングルテナントサービスモデルには適しておらず、Lingjun シングルテナントシナリオでは使用してはなりません。
ドライバー要件
-
25.06 リリースは CUDA 12.8.0 をベースとしており、NVIDIA ドライバーバージョン 575 以降が必要です。ただし、データセンター GPU (T4 など) で実行する場合は、NVIDIA ドライバーバージョン 470.57 (または R470 ブランチ以降のバージョン) 、525.85 (または R525 ブランチ以降のバージョン) 、535.86 (または R535 ブランチ以降のバージョン) 、または 545.23 (または R545 ブランチ以降のバージョン) を使用できます。
-
CUDA ドライバー互換性パッケージは、特定のドライバーブランチのみをサポートします。そのため、R418、R440、R450、R460、R510、R520、R530、R555、および R560 ブランチのドライバーをアップグレードする必要があります。これらのブランチは CUDA 12.8 との前方互換性がありません。サポートされているドライバーの完全なリストについては、CUDA Application Compatibility をご参照ください。詳細については、「CUDA Compatibility and Upgrades」をご参照ください。
主な機能と機能強化
PyTorch コンパイルの最適化
PyTorch 2.0 で導入された torch.compile() は、小規模なシングル GPU のワークロードで大きな効果を発揮することがよくあります。しかし、LLM のトレーニングは GPU メモリの最適化と FSDP や DeepSpeed などの分散フレームワークに依存するため、torch.compile() では限定的な利点しか得られないか、パフォーマンスを低下させる可能性があります。
-
DeepSpeed フレームワークでの通信粒度の制御。これにより、コンパイラがより完全な計算グラフをキャプチャし、より広範なコンパイル最適化を適用できます。
-
最適化された PyTorch ビルドの使用:
-
PyTorch コンパイラのフロントエンドが改善され、計算グラフでグラフブレークが発生した場合でもコンパイルが成功するようになりました。
-
パターンマッチングと動的シェイプのサポートが強化され、コンパイル後のパフォーマンスが向上しました。
-
これらの最適化により、8B パラメーターの LLM トレーニングでは、通常、エンドツーエンドのスループットが約 20% 向上します。
再計算のための GPU メモリの最適化
大規模なパフォーマンスデータ (さまざまなモデル、クラスター、トレーニングパラメーター設定、ベンチマーク中に収集された GPU メモリ使用率などのシステムメトリクスを含む) に基づいて構築された GPU メモリオーバーヘッドの予測モデルは、最適なアクティベーション再計算レイヤー数を推奨します。このアプローチは PyTorch に統合されており、最小限の労力で GPU メモリの最適化によるパフォーマンス向上を実現できます。この機能は、DeepSpeed フレームワークでサポートされるようになりました。
ACCL
ACCL は、Lingjun 向けに構築された Alibaba Cloud の高性能な通信ライブラリです。ACCL-N は GPU に特化したバージョンです。ACCL-N は、NVIDIA NCCL をカスタマイズした高性能な通信ライブラリです。NCCL と完全に互換性があり、アップストリームの NCCL リリースの問題を修正し、パフォーマンスと安定性を向上させています。
エンドツーエンドのパフォーマンス評価
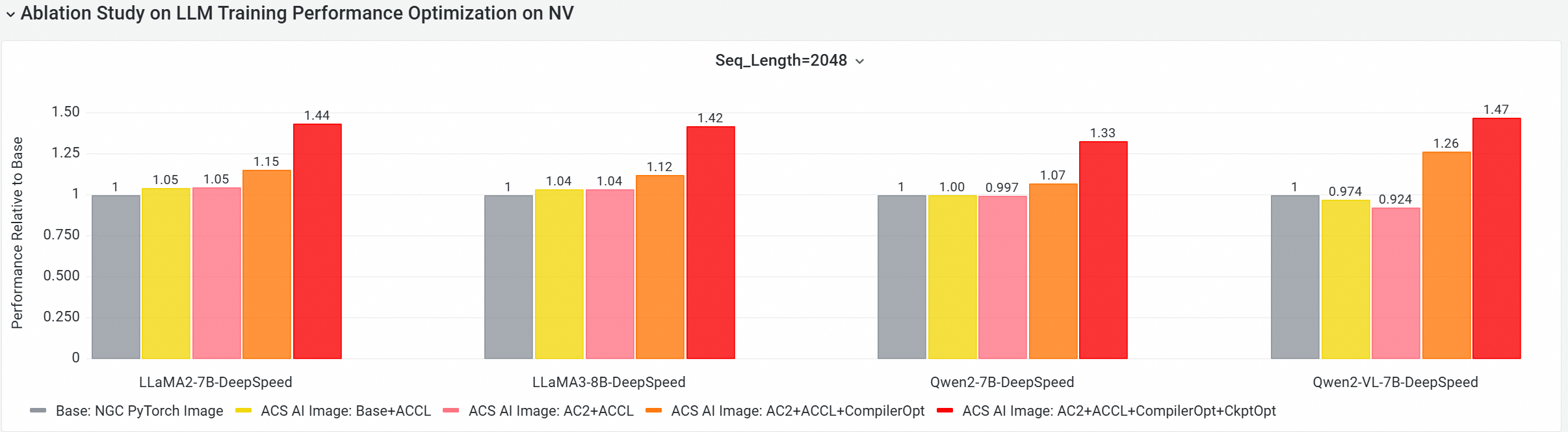
Cloud Native Platform (CNP) AI パフォーマンス分析ツールを使用して、このイメージと主流のオープンソースモデルおよびフレームワーク構成を使用した標準ベースイメージとの包括的なエンドツーエンドのパフォーマンス比較を実施しました。さらに、アブレーションスタディにより、各最適化コンポーネントがモデルトレーニング全体に対するパフォーマンスの貢献度を評価しました。
GPU コアコンポーネントの E2E パフォーマンス貢献度
以下のテストをマルチノード GPU クラスタで実行し、下記の構成間でエンドツーエンドのトレーニングパフォーマンスを比較しました。
-
Base: NGC PyTorch Image
-
Base+ACCL: ACCL を使用したベースイメージ。
-
ACS AI Image: AC2+ACCL: ACCL を使用した AC2 BaseOS (その他の最適化なし)。
-
ACS AI Image: AC2+ACCL+CompilerOpt: ACCL および
torch.compile最適化を使用した AC2 BaseOS。 -
ACS AI Image: AC2+ACCL+CompilerOpt+CkptOpt: ACCL、
torch.compile、および選択的勾配チェックポイント最適化を使用した AC2 BaseOS。
クイックスタート
以下の例は、Docker を使用して training-nv-pytorch イメージをプルする方法を示しています。
ACS で training-nv-pytorch イメージを使用するには、ワークロード作成時にコンソールの [Artifact Center] ページからイメージを選択するか、YAML ファイルでイメージ参照を指定してください。
1. イメージのプル
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. コンパイラと選択的勾配チェックポイントの有効化
-
コンパイルの最適化を有効化
Transformers Trainer API を使用する場合:
training_args = TrainingArguments( bf16=True, gradient_checkpointing=True, torch_compile=True ) -
選択的勾配チェックポイントを有効化
export CHECKPOINT_OPTIMIZATION=true
3. コンテナの起動
このセクションでは、組み込みのモデルトレーニングツールである ljperf を使用して、コンテナを起動し、トレーニングタスクを実行する手順について説明します。
LLM の例
# コンテナを起動し、そのコマンドラインにアクセスします
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# トレーニングデモを実行
ljperf benchmark --model deepspeed/llama3-8b 4. 使用上の注意
-
このイメージには、PyTorch や DeepSpeed などのカスタマイズ版ライブラリが含まれています。これらを再インストールしないでください。
-
DeepSpeed 構成では、
zero_optimization.stage3_prefetch_bucket_sizeを空のままにするか、autoに設定してください。 -
このイメージの組み込み環境変数
NCCL_SOCKET_IFNAMEは、ユースケースに応じて動的に調整する必要があります:-
単一の Pod がトレーニングまたは推論タスク用に 1、2、4、または 8 個の GPU のみを要求する場合、
NCCL_SOCKET_IFNAME=eth0(このイメージのデフォルト設定) を設定する必要があります。 -
単一の Pod がトレーニングまたは推論タスクのためにマシン全体の 16 個すべての GPU を要求する場合 (これにより HPN 高性能ネットワーキングが使用可能になります)、
NCCL_SOCKET_IFNAME=hpn0を設定する必要があります。
-
既知の問題
なし。