このトピックでは、training-nv-pytorch 25.05 のリリースノートについて説明します。
主な機能とバグ修正
主な機能
ベースイメージの CUDA が 12.9.0 にアップグレードされました。
修正されたバグ
PyTorch が 2.6.0.7.post1 にアップグレードされ、オープンソースコミュニティにおけるプロファイルのクラッシュ問題が修正されました。
コンテンツ
シナリオ | トレーニング/推論 |
フレームワーク | PyTorch |
要件 | NVIDIA ドライバーリリース >= 575 |
コアコンポーネント |
|
アセット
25.05
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.05-serverless
VPC イメージ
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}は、ACS がアクティブ化されているリージョン (cn-beijing、cn-wulanchabu など) を示します。{image:tag}は、イメージの名前とタグを示します。
現在、VPC 経由でプルできるイメージは、中国 (北京) リージョンのイメージのみです。
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.05-serverlessイメージは、ACS サービスと Lingjun マルチテナントサービスに適用されます。このイメージは、Lingjun シングルテナントサービスには適用されません。 Lingjun シングルテナントシナリオでは使用しないでください。egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.05イメージは、Lingjun シングルテナントシナリオに適用されます。
ドライバー要件
25.05 リリースは、NGC pytorch 25.04 イメージバージョンアップデートに合わせています (NGC は毎月末にイメージをリリースするため、Golden イメージの開発は前月の NGC バージョンに基づいてのみ行うことができます)。そのため、Golden-gpu ドライバーは、対応する NGC イメージバージョンの要件に従います。このリリースは CUDA 12.9.0 に基づいており、NVIDIA ドライバーバージョン 575 以降が必要です。ただし、データセンター GPU (T4 など) で実行している場合は、NVIDIA ドライバーバージョン 470.57 (またはそれ以降の R470)、525.85 (またはそれ以降の R525)、535.86 (またはそれ以降の R535)、または 545.23 (またはそれ以降の R545) を使用できます。
CUDA ドライバー互換性パッケージは、特定のドライバーのみをサポートしています。そのため、ユーザーは、CUDA 12.8 と上位互換性のないすべての R418、R440、R450、R460、R510、R520、R530、R545、R555、および R560 ドライバーからアップグレードする必要があります。サポートされているドライバーの完全なリストについては、「CUDA アプリケーションの互換性」のトピックを参照してください。詳細については、「CUDA の互換性とアップグレード」を参照してください。
主な機能と拡張機能
PyTorch コンパイルの最適化
PyTorch 2.0 で導入されたコンパイル最適化機能は、1 つの GPU での小規模トレーニングに適しています。ただし、LLM トレーニングには、GPU メモリの最適化と、FSDP や DeepSpeed などの分散フレームワークが必要です。その結果、torch.compile() はトレーニングにメリットをもたらすことができず、デメリットが生じる可能性があります。
DeepSpeed フレームワークで通信の粒度を制御することで、コンパイラはより広範囲のコンパイル最適化のための完全な計算グラフを取得できます。
最適化された PyTorch:
PyTorch コンパイラのフロントエンドが最適化され、計算グラフでグラフの中断が発生した場合にコンパイルが確実に行われるようになりました。
モードマッチングと動的シェイプ機能が強化され、コンパイル済みコードが最適化されました。
上記の最適化後、8B LLM をトレーニングする場合の E2E スループットが 20% 向上しました。
再計算のための GPU メモリの最適化
さまざまなクラスターにデプロイされたモデル、またはさまざまなパラメーターで構成されたモデルのパフォーマンステストを実行し、GPU メモリ使用率などのシステムメトリックを収集することにより、モデルの GPU メモリ消費量を予測および分析します。結果に基づいて、最適なアクティベーション再計算レイヤー数を提案し、PyTorch に統合します。これにより、ユーザーは GPU メモリの最適化を簡単に活用できます。現在、この機能は DeepSpeed フレームワークで使用できます。
ACCL
ACCL は、Alibaba Cloud が Lingjun 向けに提供する社内 HPN 通信ライブラリです。GPU アクセラレーションシナリオ向けに ACCL-N を提供します。 ACCL-N は、NCCL に基づいてカスタマイズされた HPN ライブラリです。 NCCL と完全に互換性があり、NCCL のいくつかのバグを修正しています。ACCL-N は、より高いパフォーマンスと安定性も提供します。
E2E パフォーマンスメリット評価
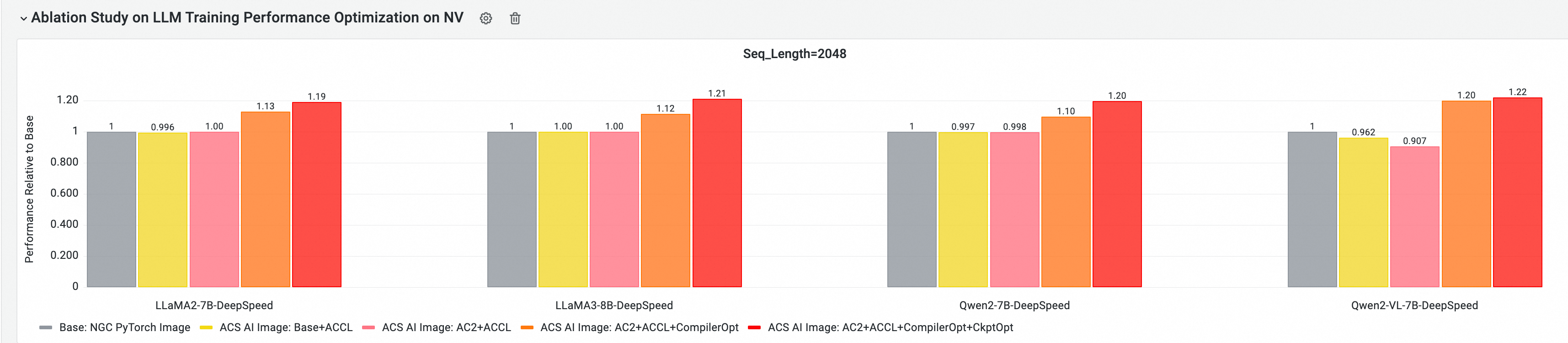
クラウドネイティブ AI パフォーマンス評価および分析ツール CNP を使用すると、主流のオープンソースモデルとフレームワークを標準ベースイメージと共に使用して、E2E パフォーマンスを分析できます。さらに、アブレーションスタディを使用して、各最適化コンポーネントがモデルトレーニング全体にどのようにメリットをもたらすかをさらに評価できます。
GPU コアコンポーネントの E2E トレーニングパフォーマンスへの貢献度の分析
次のテストは Golden-25.05 に基づいており、マルチノード GPU クラスターで E2E パフォーマンステストと比較分析を実行します。比較項目は次のとおりです。
ベース: NGC PyTorch イメージ
ACS AI イメージ: ベース+ACCL: イメージは ACCL 通信ライブラリを使用します
ACS AI イメージ: AC2+ACCL: Golden イメージは、最適化を有効にせずに AC2 BaseOS を使用します
ACS AI イメージ: AC2+ACCL+CompilerOpt: Golden イメージは AC2 BaseOS を使用し、torch コンパイル最適化のみを有効にします
ACS AI イメージ: AC2+ACCL+CompilerOpt+CkptOpt: Golden イメージは AC2 BaseOS を使用し、torch コンパイルと選択的勾配チェックポイント最適化の両方を有効にします
クイックスタート
次の例では、Docker のみを使用して training-nv-pytorch イメージをプルします。
ACS で training-nv-pytorch イメージを使用するには、ワークロードを作成するコンソールのアーティファクトセンターページからプルするか、YAML ファイルでイメージを指定する必要があります。
1. イメージを選択する
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. API を呼び出して、コンパイルの最適化と再計算のための GPU メモリの最適化を有効にする
コンパイルの最適化を有効にする
transformers Trainer API を使用する:

再計算のための GPU メモリの最適化を有効にする
export CHECKPOINT_OPTIMIZATION=true
3. コンテナを起動する
イメージには、ljperf という名前の組み込みモデルトレーニングツールが用意されており、コンテナを起動してトレーニングタスクを実行する手順を示しています。
LLM
# コンテナを起動し、コンテナにログインします。
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# トレーニングデモを実行します。
ljperf benchmark --model deepspeed/llama3-8b 4. 提案
イメージの変更には、PyTorch ライブラリと DeepSpeed ライブラリが含まれます。再インストールしないでください。
DeepSpeed 構成の
zero_optimization.stage3_prefetch_bucket_sizeは空のままにするか、autoに設定します。
既知の問題
イメージは PyTorch を 2.6 にアップグレードします。 LLM モデルの再計算メモリ最適化のパフォーマンスメリットは、以前のイメージほど良くありません。継続的な最適化が進行中です。