このドキュメントでは、training-nv-pytorch 25.03 イメージの主な特徴、バグ修正、およびコンポーネントの更新について詳しく説明します。
主な特徴とバグ修正
主な特徴
-
ベースイメージ は NGC 25.02 に合わせて更新されました。
-
PyTorch と関連コンポーネントを 2.6.0.7 に、TransformerEngine (TE) を 2.1 に、accelerate を 1.5.2 にアップグレードしました。
-
ACCL-N を 2.23.4.12 にアップグレードしました。
-
vLLM を 0.8.2.dev0 に、Ray を 2.44 にアップグレードし、flash-infer 0.2.3 のサポートを追加しました。 Transformers を 4.49.0+ali に、flash_attn を 2.7.2 にアップグレードしました。
バグ修正
vLLM 0.8.2.dev0 へのアップグレードにより、H20 上の Mixture of Experts (MoE) での不正なメモリアクセス (#13693) の問題が解決されました。
構成
|
ユースケース |
トレーニング/推論 |
|
フレームワーク |
pytorch |
|
要件 |
NVIDIA ドライバーリリース >= 570 |
|
コアコンポーネント |
|
アセット
パブリックイメージ
-
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.03-serverless
VPC イメージ
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}は、ACS がアクティブ化されているリージョン (cn-beijing、cn-wulanchabu など) を示します。{image:tag}は、イメージの名前とタグを示します。
現在、VPC 経由でプルできるイメージは、中国 (北京) リージョンのイメージのみです。
-
ACS および Lingjun のマルチテナント環境では、
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.03-serverlessイメージを使用してください。 このイメージは、Lingjun のシングルテナント製品フォーマットと互換性がありません。 -
Lingjun のシングルテナントシナリオでは、
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.03イメージを使用してください。
ドライバー要件
-
このリリースは NGC PyTorch 25.02 イメージに準拠しているため、GPU ドライバーの要件は同じです。 このリリースは CUDA 12.8.0.38 をベースとしており、NVIDIA ドライバーバージョン 570 以降が必要です。 ただし、データセンター GPU (T4 など) で実行している場合は、NVIDIA ドライバーバージョン 470.57 (またはそれ以降の R470 バージョン)、525.85 (またはそれ以降の R525 バージョン)、535.86 (またはそれ以降の R535 バージョン)、または 545.23 (またはそれ以降の R545 バージョン) を使用できます。
-
CUDA ドライバーの前方互換性パッケージは、特定のドライバーのみをサポートします。 R418、R440、R450、R460、R510、R520、R530、R545、および R555 の各ドライバーは CUDA 12.8 との前方互換性がないため、アップグレードする必要があります。 サポートされているドライバーの完全なリストについては、「CUDA アプリケーションの互換性」をご参照ください。 詳細については、「CUDA の互換性とアップグレード」をご参照ください。
主な特徴と機能強化
PyTorch コンパイラ最適化
PyTorch 2.0 で導入された torch.compile() 機能は、シングル GPU のワークロードに大きなメリットをもたらしますが、GPU メモリ最適化や、FSDP や DeepSpeed といった分散トレーニングフレームワークの要件のため、大規模言語モデル (LLM) のトレーニングではそのメリットが減少します。
-
DeepSpeed フレームワーク内の通信の粒度を制御することで、コンパイラがより完全な計算グラフを取得し、より広範な最適化が可能になります。
-
以下のような最適化されたバージョンの PyTorch が含まれています:
-
PyTorch コンパイラのフロントエンドを改善し、計算グラフでグラフブレークが発生した場合でもコンパイルが成功するようにします。
-
パターンマッチングと動的シェイプの機能を強化し、コンパイル済みコードのパフォーマンスを向上させます。
-
これらの最適化を組み合わせることで、8B LLM トレーニングの E2E スループットが約 20% 向上します。
再計算のための GPU メモリ最適化
さまざまなモデル、クラスター、トレーニング構成から得られた広範なパフォーマンスデータに基づき、GPU メモリ消費量の予測モデルを開発しました。 このモデルは、アクティベーション再計算レイヤーの最適な数を推奨します。 この機能は PyTorch に統合されており、GPU メモリ最適化のパフォーマンス上のメリットを簡単に活用できます。 この機能は現在、DeepSpeed フレームワークに対応しています。
ACCL 通信ライブラリ
ACCL は、Alibaba Cloud が Lingjun 製品向けに開発した高性能なネットワーク通信ライブラリです。 ACCL-N バリアントは、GPU ワークロード向けに設計されています。 NVIDIA NCCL をカスタマイズした ACCL-N は、アップストリームライブラリと完全に互換性があり、バグ修正、パフォーマンスの最適化、および安定性の向上が含まれています。
E2E パフォーマンス効果の評価
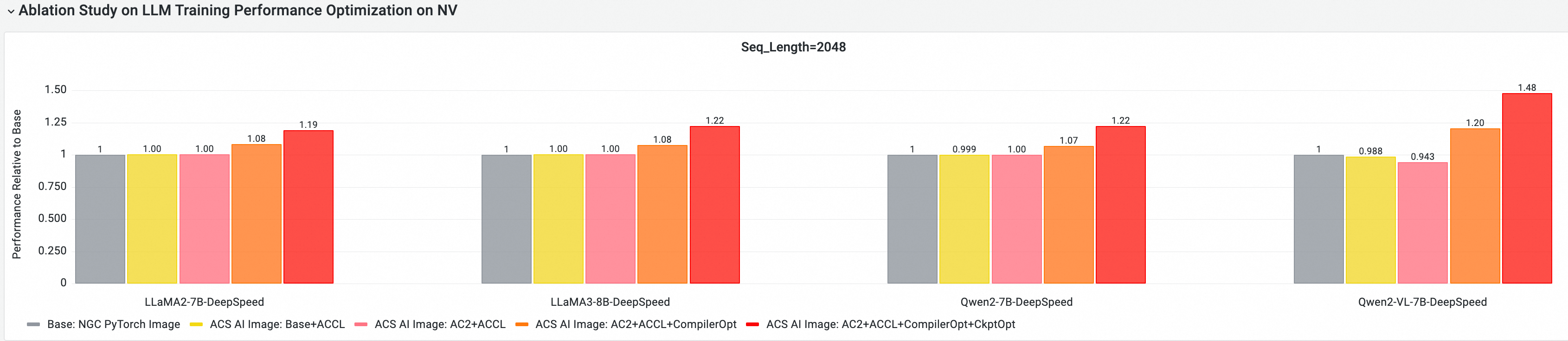
クラウドネイティブ AI パフォーマンス評価ツール CNP を使用し、主流のオープンソースモデルとフレームワーク構成を用いて、このイメージと標準のベースイメージとの間で包括的な E2E パフォーマンス比較を実施しました。 また、最適化された各コンポーネントのパフォーマンスへの貢献度を評価するために、アブレーションスタディも実施しました。
GPU コアコンポーネントの E2E パフォーマンスへの貢献度
バージョン 25.03 に基づく以下のテストは、E2E パフォーマンスを評価および比較するために、マルチノード GPU クラスターで実施されました。 比較項目は次のとおりです:
-
ベース: NGC PyTorch イメージ
-
ACS AI イメージ: ベース+ACCL: ACCL 通信ライブラリを使用したベースイメージ。
-
ACS AI イメージ: AC2+ACCL: AC2 BaseOS を使用し、最適化を有効にしていない本イメージ。
-
ACS AI イメージ: AC2+ACCL+CompilerOpt: AC2 BaseOS を使用し、
torch.compile最適化のみを有効にした本イメージ。 -
ACS AI イメージ: AC2+ACCL+CompilerOpt+CkptOpt: AC2 BaseOS を使用し、
torch.compileと選択的勾配チェックポイントの両方の最適化を有効にした本イメージ。
クイックスタート
この例では、Docker を使用してイメージをプルする方法を示します。
ACS でこのイメージを使用するには、コンソールでワークロードを作成するときにアーティファクトセンターから選択するか、YAML ファイルでイメージ参照を指定します。
ステップ 1: イメージのプル
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]ステップ 2: コンパイラ最適化と再計算メモリ最適化の有効化
-
コンパイラ最適化の有効化
Transformers Trainer API を使用する場合は、
torch_compile=Trueを設定します:training_args = TrainingArguments( bf16=True, gradient_checkpointing=True, torch_compile=True ) -
再計算のための GPU メモリ最適化の有効化
export CHECKPOINT_OPTIMIZATION=true
ステップ 3: コンテナの起動
このイメージには、ljperf モデルトレーニングツールが含まれています。 次の手順に従ってコンテナを起動し、トレーニングタスクを実行します。
LLM の例
# コンテナを起動し、シェルに入ります
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# トレーニングデモを実行します
ljperf --action train --model_name deepspeed/llama3-8b ステップ 4: 使用上の注意
-
このイメージには、PyTorch や DeepSpeed などのライブラリの修正版が含まれています。 これらを再インストールしないでください。再インストールすると、含まれている最適化が上書きされます。 これらの変更は、将来アップストリームに反映される予定です。
-
DeepSpeed の設定では、
zero_optimization.stage3_prefetch_bucket_sizeパラメーターを空のままにするか、autoに設定してください。
既知の問題
現在、既知の問題はありません。