このリリースノートでは、training-nv-pytorch 25.02 のリリースについて説明します。
主な機能とバグ修正
主な機能
-
ベースイメージは NGC 25.01 に準拠し、CUDA は 12.8.0 に、cuDNN は 9.7.0.66 にアップグレードされました。
-
ACCL-N が 2.23.4.11 にアップグレードされ、ACCL-Barex をサポートするようになりました。
-
Transformers は 4.48.3+ali に、vLLM は 0.7.2 に、Ray は 2.42.1 にアップグレードされました。このリリースには、これらのアップストリームバージョンの機能とバグ修正が含まれます。
バグ修正
このリリースで修正されたバグはありません。
イメージの内容
|
ユースケース |
トレーニング / 推論 |
|
フレームワーク |
PyTorch |
|
要件 |
NVIDIA Driver release >= 570 |
|
主要コンポーネント |
|
イメージアセット
パブリックイメージ
-
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.02-serverless
VPC イメージ
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}は、ACS がアクティブ化されているリージョン (cn-beijing、cn-wulanchabu など) を示します。{image:tag}は、イメージの名前とタグを示します。
現在、VPC 経由でプルできるイメージは、中国 (北京) リージョンのイメージのみです。
-
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.02-serverlessイメージは、ACS および Lingjun のマルチテナント製品に適しています。Lingjun のシングルテナント製品とは互換性がありません。 -
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.02イメージは、Lingjun のシングルテナントシナリオに適しています。
ドライバー要件
-
25.02 リリースは NGC PyTorch 25.01 イメージに合わせて更新されているため、Golden-gpu のドライバーには対応する NGC イメージの要件が適用されます。このリリースは CUDA 12.8.0 をベースとしており、NVIDIA ドライバーのバージョン 570 以降が必要です。ただし、データセンター GPU (T4 やその他のデータセンター GPU など) で実行している場合は、NVIDIA ドライバーのバージョン 470.57 (またはそれ以降の R470 リリース)、525.85 (またはそれ以降の R525 リリース)、535.86 (またはそれ以降の R535 リリース)、または 545.23 (またはそれ以降の R545 リリース) を使用できます。
-
CUDA ドライバー互換性パッケージは、特定のドライバーのみをサポートします。したがって、CUDA 12.8.0 と前方互換性のない R418、R440、R450、R460、R510、R520、R530、R545、および R555 ドライバーからアップグレードする必要があります。サポートされているドライバーの完全なリストについては、「CUDA Application Compatibility」をご参照ください。詳細については、「CUDA Compatibility and Upgrades」をご参照ください。
主な機能と拡張機能
PyTorch コンパイルの最適化
PyTorch 2.0 で導入された torch.compile() は、小規模なシングル GPU のワークロードで大きな効果を発揮することがよくあります。しかし、LLM のトレーニングは GPU メモリの最適化と FSDP や DeepSpeed などの分散フレームワークに依存するため、torch.compile() では限定的な利点しか得られないか、パフォーマンスを低下させる可能性があります。
-
DeepSpeed フレームワークでの通信粒度の制御。これにより、コンパイラがより完全な計算グラフをキャプチャし、より広範なコンパイル最適化を適用できます。
-
最適化された PyTorch ビルドの使用:
-
PyTorch コンパイラのフロントエンドが改善され、計算グラフでグラフブレークが発生した場合でもコンパイルが成功するようになりました。
-
パターンマッチングと動的シェイプのサポートが強化され、コンパイル後のパフォーマンスが向上しました。
-
これらの最適化により、8B パラメーターの LLM トレーニングでは、通常、エンドツーエンドのスループットが約 20% 向上します。
再計算のための GPU メモリの最適化
大規模なパフォーマンスデータ (さまざまなモデル、クラスター、トレーニングパラメーター設定、ベンチマーク中に収集された GPU メモリ使用率などのシステムメトリクスを含む) に基づいて構築された GPU メモリオーバーヘッドの予測モデルは、最適なアクティベーション再計算レイヤー数を推奨します。このアプローチは PyTorch に統合されており、最小限の労力で GPU メモリの最適化によるパフォーマンス向上を実現できます。この機能は、DeepSpeed フレームワークでサポートされるようになりました。
ACCL
ACCL は、Lingjun 向けに構築された Alibaba Cloud の高性能な通信ライブラリです。ACCL-N は GPU に特化したバージョンです。ACCL-N は、NVIDIA NCCL をカスタマイズした高性能な通信ライブラリです。NCCL と完全に互換性があり、アップストリームの NCCL リリースの問題を修正し、パフォーマンスと安定性を向上させています。
エンドツーエンドのパフォーマンス評価
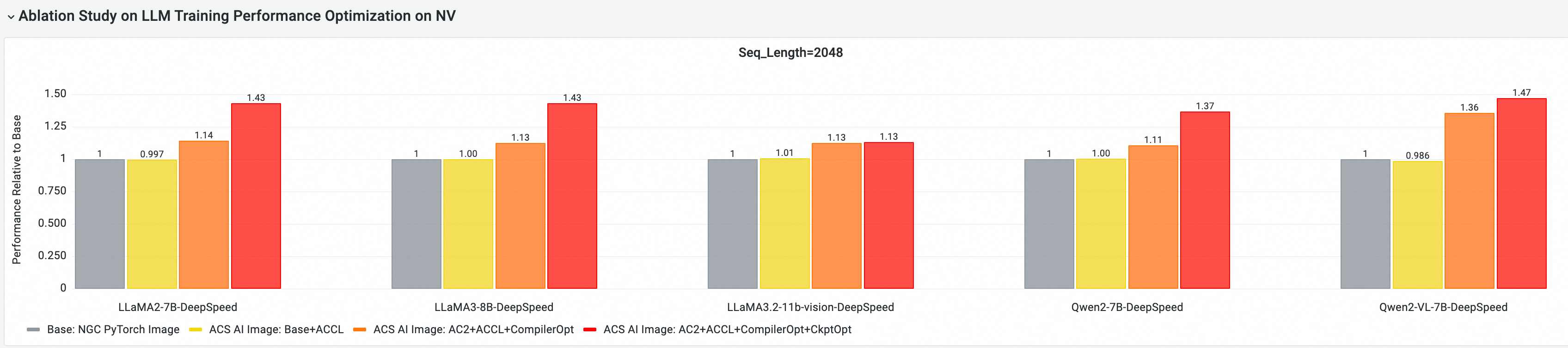
クラウドネイティブな AI パフォーマンスのベンチマークおよび分析ツールである CNP を使用し、主流のオープンソースモデルとフレームワーク構成を備えた標準のベースイメージとの、完全なエンドツーエンドのパフォーマンス比較を実施しました。また、各最適化コンポーネントがモデルトレーニング全体のパフォーマンスにどれだけ貢献するかを測定するために、アブレーションスタディも実施しました。
GPU 主要コンポーネントのエンドツーエンドパフォーマンス貢献度分析
以下のテストは 25.02 に基づいており、マルチノード GPU クラスターでエンドツーエンドのパフォーマンスベンチマークと比較を実行します。比較項目は次のとおりです。
-
Base: NGC PyTorch イメージ。
-
ACS AI Image: Base+ACCL: ACCL 通信ライブラリを備えたベースイメージ。
-
ACS AI Image: AC2+ACCL: AC2 BaseOS 上で ACCL を備えたベースイメージ。
-
ACS AI Image: AC2+ACCL+CompilerOpt: AC2 BaseOS 上で ACCL と torch.compile() の最適化を有効にしたベースイメージ。
-
ACS AI Image: AC2+ACCL+CompilerOpt+CkptOpt: AC2 BaseOS 上で ACCL、torch.compile()、および選択的勾配チェックポイントの最適化を有効にしたベースイメージ。
クイックスタート
以下の例は、Docker を使用して training-nv-pytorch イメージをプルする方法を示しています。
ACS で training-nv-pytorch イメージを使用するには、ワークロードを作成する際にコンソールのアーティファクトセンターページから選択するか、YAML ファイルでイメージ参照を指定します。
1. イメージのプル
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. コンパイラとメモリ最適化の有効化
-
コンパイル最適化の有効化
Transformers Trainer API を使用します:
training_args = TrainingArguments( bf16=True, gradient_checkpointing=True, torch_compile=True ) -
再計算のための GPU メモリの最適化を有効化
export CHECKPOINT_OPTIMIZATION=true
3. コンテナの起動
イメージには、モデルトレーニングツール ljperf が含まれます。以下の手順では、コンテナを起動してトレーニングタスクを実行する方法を説明します。
LLM
# コンテナを起動して接続します。
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# トレーニングデモを実行します。
ljperf benchmark --model deepspeed/llama3-8b 4. 使用上の注意
-
PyTorch や DeepSpeed を再インストールしないでください。イメージにはこれらのライブラリへの変更が含まれます (この変更は、後ほどアップストリームにコントリビュートされる予定です)。
-
DeepSpeed 設定で、
zero_optimization.stage3_prefetch_bucket_sizeは空白のままにするか、autoに設定してください。
既知の問題
-
Illegal memory access for MoE On H20 #13693。この問題を解決するには、vLLM をアップデートしてください。