ARMS Application Monitoring を統合すると、エージェントが一般的な AI フレームワークを自動的にイベントトラッキングし、コード変更なしにトレースデータを収集します。トレース内に特定のビジネスメソッドをキャプチャするには、loongsuite-util-genai パッケージと OpenTelemetry SDK を使用してカスタムイベントトラッキングを追加します。本トピックでは、loongsuite-util-genai および OpenTelemetry Python SDK を使用してカスタムスパンを作成し、カスタム属性を追加する方法について説明します。
ARMS エージェントがサポートする AI コンポーネントおよびフレームワークの一覧については、以下のトピックをご参照ください。
前提条件
ARMS Application Monitoring の統合が正常に完了していること。
依存関係のインストール
pip install loongsuite-util-genaiこのインストールにより、opentelemetry.util.genai パッケージおよび ExtendedTelemetryHandler などの拡張インターフェイスが提供されます。詳細については、「loongsuite-util-genai 詳細ドキュメント」をご参照ください。
loongsuite-util-genai および OpenTelemetry SDK の使用
loongsuite-util-genai および OpenTelemetry SDK を使用すると、以下の操作が可能です。
GenAI セマンティクス(Entry、Agent、Tool、ReAct Step など)を持つスパンを作成する。
OpenTelemetry SDK を使用してカスタムスパンを作成する。
スパンにカスタム属性を追加する。
現在のトレースコンテキストを取得し、traceId を出力する。
基本概念
スパン:リクエスト内の単一の操作。たとえば、大規模言語モデル (LLM) 呼び出しやツール実行など。
SpanContext:リクエストトレースのコンテキストで、traceId や spanId などの情報を含む。
属性:スパンに追加されるフィールドで、モデル名やトークン使用量などの重要な情報を記録するために使用される。
ハンドラ:loongsuite-util-genai が提供する
ExtendedTelemetryHandler。GenAI セマンティクス規則に準拠したスパンを作成するために使用される。
以下の表は、loongsuite-util-genai がサポートするすべてのスパンタイプを示しています。本トピックでは、Entry、Agent、Tool、および ReAct Step スパンの使用方法に焦点を当てます。Embedding、Retrieval、Rerank、Memory などの他のタイプの詳細については、「loongsuite-util-genai 完全ドキュメント」をご参照ください。
スパンタイプ | 操作名 | 説明 |
Entry |
| アプリケーションのエントリポイントで、セッション ID、ユーザー ID、およびアプリケーションとのやり取りの完全な詳細を含む。 |
Agent |
| エージェントの呼び出しで、トークン使用量を集約する。 |
Tool |
| ツールまたは関数の実行。 |
Step |
| 単一の ReAct 反復のマーカー。 |
LLM |
| LLM チャット。通常はエージェントによって自動的にキャプチャされる。 |
Embedding |
| ベクトル埋め込み操作。 |
Retriever |
| 取得操作(RAG 向け)。 |
Reranker |
| 再ランキング操作。 |
Memory |
| メモリの読み取り/書き込み操作。 |
以下のセクションでは、各タイプのスパンをイベントトラッキングするためのステップバイステップの手順とコードスニペットを提供します。実行可能な完全なコード例は、本文末尾の付録にあります。
TelemetryHandler を直接インスタンス化するのではなく、必ず get_extended_telemetry_handler() を使用してハンドラインスタンスを取得してください。ARMS エージェントは get_extended_telemetry_handler() のみと互換性があります。TelemetryHandler を直接インスタンス化すると、環境変数の互換性に関する問題が発生する可能性があります。
カスタムイベントトラッキングを追加する際は、必ず「LLM トレースフィールド定義」で定義されたセマンティクス規則に従ってください。トークン統計やセッション分析などの AI アプリケーション可観測性機能は、これらの規則に基づいてデータをレンダリングします。スパン属性がこれらの規則に従っていない場合、関連データがコンソールに正しく表示されない可能性があります。
1. ハンドラおよびトレーサーの取得
loongsuite-util-genai からシングルトンハンドラを取得するには get_extended_telemetry_handler() を、OpenTelemetry SDK からトレーサーを取得するには get_tracer(__name__) を使用します。これらはそれぞれ、GenAI セマンティクススパンおよびカスタムビジネススパンを作成するために使用されます。
from opentelemetry.util.genai.extended_handler import get_extended_telemetry_handler
from opentelemetry.util.genai.extended_types import (
ExecuteToolInvocation,
InvokeAgentInvocation,
)
from opentelemetry.util.genai._extended_common import EntryInvocation, ReactStepInvocation
from opentelemetry.util.genai.types import Error, InputMessage, OutputMessage, Text
from opentelemetry.trace import get_tracer
handler = get_extended_telemetry_handler()
tracer = get_tracer(__name__)
ハンドラは以下の 2 つの使用パターンをサポートします。
コンテキストマネージャー(
with handler.entry(inv)など):推奨される方法です。スパンのライフサイクルを自動的に管理します。start/stop/fail API(
handler.start_entry(inv)/handler.stop_entry(inv)/handler.fail_entry(inv, error)):with文を使用できない非同期、コールバック、ストリーミングなどのシナリオに適しています。
2. Entry スパンの作成
リクエストのエントリポイントで Entry スパンを作成します。session_id および user_id を含め、input_messages を使用してユーザー入力を記録します。ストリーミング応答が完了したら、出力を連結して output_messages に設定し、stop_entry を呼び出してスパンを終了します。これにより、コンソール上でリクエストの完全な入力と最終的な出力を直接確認できます。
entry_inv = EntryInvocation(
session_id=req.session_id or str(uuid.uuid4()),
user_id=req.user_id or "anonymous",
input_messages=[
InputMessage(role="user", parts=[Text(content=req.topic)]),
],
)
def event_generator():
handler.start_entry(entry_inv)
output_chunks: list[str] = [ ]
try:
for chunk in run_agent_stream(topic=req.topic):
output_chunks.append(chunk)
yield f"data: {json.dumps({'content': chunk}, ensure_ascii=False)}\n\n"
yield "data: [DONE]\n\n"
except Exception as exc:
handler.fail_entry(entry_inv, Error(message=str(exc), type=type(exc)))
yield f"data: {json.dumps({'error': str(exc)}, ensure_ascii=False)}\n\n"
return
entry_inv.output_messages = [
OutputMessage(
role="assistant",
parts=[Text(content="".join(output_chunks))],
finish_reason="stop",
),
]
handler.stop_entry(entry_inv)
3. Agent スパンの作成
start_invoke_agent を使用して、エージェント名、モデル、説明を記録する Agent スパンを作成します。Agent スパンはトレース全体のルート GenAI スパンであり、後続のすべての ReAct Step、LLM 呼び出し、およびツール呼び出しスパンはその子スパンとなります。
invocation = InvokeAgentInvocation(
provider="dashscope",
agent_name="TechContentAgent",
agent_description="Technical content generation assistant",
request_model="qwen-plus",
)
total_input_tokens = 0
total_output_tokens = 0
handler.start_invoke_agent(invocation)
try:
# ... Core agent logic (ReAct loop) ...
invocation.input_tokens = total_input_tokens
invocation.output_tokens = total_output_tokens
handler.stop_invoke_agent(invocation)
except Exception:
handler.fail_invoke_agent(invocation, Error(message="agent failed", type=RuntimeError))
raise
エージェントの実行が完了すると、累積された total_input_tokens および total_output_tokens が Agent スパンに書き込まれ、トークンメトリックが集約されます。
4. ReAct Step スパンの作成
各 ReAct 推論反復に対して Step スパンを作成し、現在の round を渡します。反復が終了すると、継続が必要な場合は finish_reason を continue に、最終回答の場合は stop に設定します。この例では、各反復における LLM 呼び出しは ARMS エージェントによって自動的にイベントトラッキングされるため、手動で作成する必要はありません。
step_inv = ReactStepInvocation(round=iteration + 1)
handler.start_react_step(step_inv)
try:
response = client.chat.completions.create(
model="qwen-plus",
messages=messages,
tools=TOOL_DEFINITIONS,
)
# ... Process the response ...
step_inv.finish_reason = "stop" # or "continue"
handler.stop_react_step(step_inv)
except Exception:
handler.fail_react_step(step_inv, Error(message="step failed", type=RuntimeError))
raise
5. Tool スパンの作成
モデルがツール呼び出しを返した場合、各 tool_call に対して Tool スパンを作成し、ツール名、呼び出し ID、入力パラメーター、および結果を記録します。
tool_inv = ExecuteToolInvocation(
tool_name=tool_call.function.name,
tool_call_id=tool_call.id,
tool_call_arguments=tool_call.function.arguments,
tool_type="function",
)
handler.start_execute_tool(tool_inv)
try:
result = dispatch_tool(tool_name, tool_call.function.arguments)
tool_inv.tool_call_result = result
except Exception as exc:
handler.fail_execute_tool(tool_inv, error=Error(message=str(exc), type=type(exc)))
raise
else:
handler.stop_execute_tool(tool_inv)
6. OpenTelemetry SDK を使用したカスタムスパンの作成
loongsuite-util-genai が提供する GenAI セマンティクススパンに加えて、OpenTelemetry SDK の tracer.start_as_current_span() メソッドを使用してカスタムビジネススパンを作成し、GenAI スパンと組み合わせて使用できます。
以下の例は、カスタムスパンの代表的なユースケースを 2 つ示しています。
duplicate_tool_detection
このプロセスは各 ReAct 反復の前に実行されます。Counter を使用して各ツールの呼び出し回数をカウントし、検出結果を gen_ai.loop_detection.* 属性に書き込みます。ループが検出された場合、メッセージリストにシステムプロンプトを追加して、モデルが繰り返しを回避するように誘導します。
def _check_duplicate_tools(
tool_usage_counter: Counter,
messages: list[dict[str, Any]],
) -> None:
duplicates = [name for name, count in tool_usage_counter.items() if count > 1]
has_duplicates = len(duplicates) > 0
with tracer.start_as_current_span("duplicate_tool_detection") as span:
span.set_attributes({
"gen_ai.loop_detection.detected": has_duplicates,
"gen_ai.loop_detection.duplicate_tools": str(duplicates) if has_duplicates else "[ ]",
"gen_ai.loop_detection.total_calls": sum(tool_usage_counter.values()),
"gen_ai.loop_detection.unique_tools": len(tool_usage_counter),
})
if has_duplicates:
details = ", ".join(f"{n}({tool_usage_counter[n]} calls)" for n in duplicates)
messages.append({
"role": "system",
"content": f"[System Hint] Duplicate tool calls detected: {details}. Please avoid repeating the call.",
})
response_loop_detection
このプロセスは各 LLM 応答後に実行されます。現在の応答と前の応答のテキスト類似度を比較し、is_loop や overlap_ratio などのメトリックをスパン属性に書き込みます。ループが検出された場合(テキストが同一であるか、重複率が 80 % を超える場合)、finish_reason が loop_detected に設定され、エージェントが早期に終了します。
def _check_response_loop(
current_content: str | None,
previous_content: str | None,
) -> bool:
cur = (current_content or "").strip()
prev = (previous_content or "").strip()
with tracer.start_as_current_span("response_loop_detection") as span:
if not prev or not cur:
span.set_attributes({
"gen_ai.loop_detection.is_loop": False,
"gen_ai.loop_detection.reason": "no_text_content",
})
return False
is_identical = cur == prev
longer = max(len(cur), len(prev))
common_prefix_len = sum(1 for a, b in zip(cur, prev) if a == b)
overlap_ratio = common_prefix_len / longer if longer > 0 else 0.0
is_loop = is_identical or overlap_ratio > 0.8
span.set_attributes({
"gen_ai.loop_detection.is_loop": is_loop,
"gen_ai.loop_detection.is_identical": is_identical,
"gen_ai.loop_detection.overlap_ratio": round(overlap_ratio, 2),
"gen_ai.loop_detection.current_length": len(cur),
"gen_ai.loop_detection.previous_length": len(prev),
})
return is_loop
カスタムスパンは GenAI セマンティクス規則に従っていないため、コンソールのトレースビューでそれらを確認するには、すべてのビュー に切り替える必要があります。
モニタリング詳細の確認
Cloud Monitor 2.0 コンソールにログインし、対象のワークスペースを選択して、左側のナビゲーションウィンドウで すべての機能 > AI アプリケーション可観測性 を選択します。
AI アプリケーションページで、統合済みのアプリケーションを確認できます。アプリケーション名をクリックして、詳細なモニタリングデータを表示します。
インストルメンテーションの結果
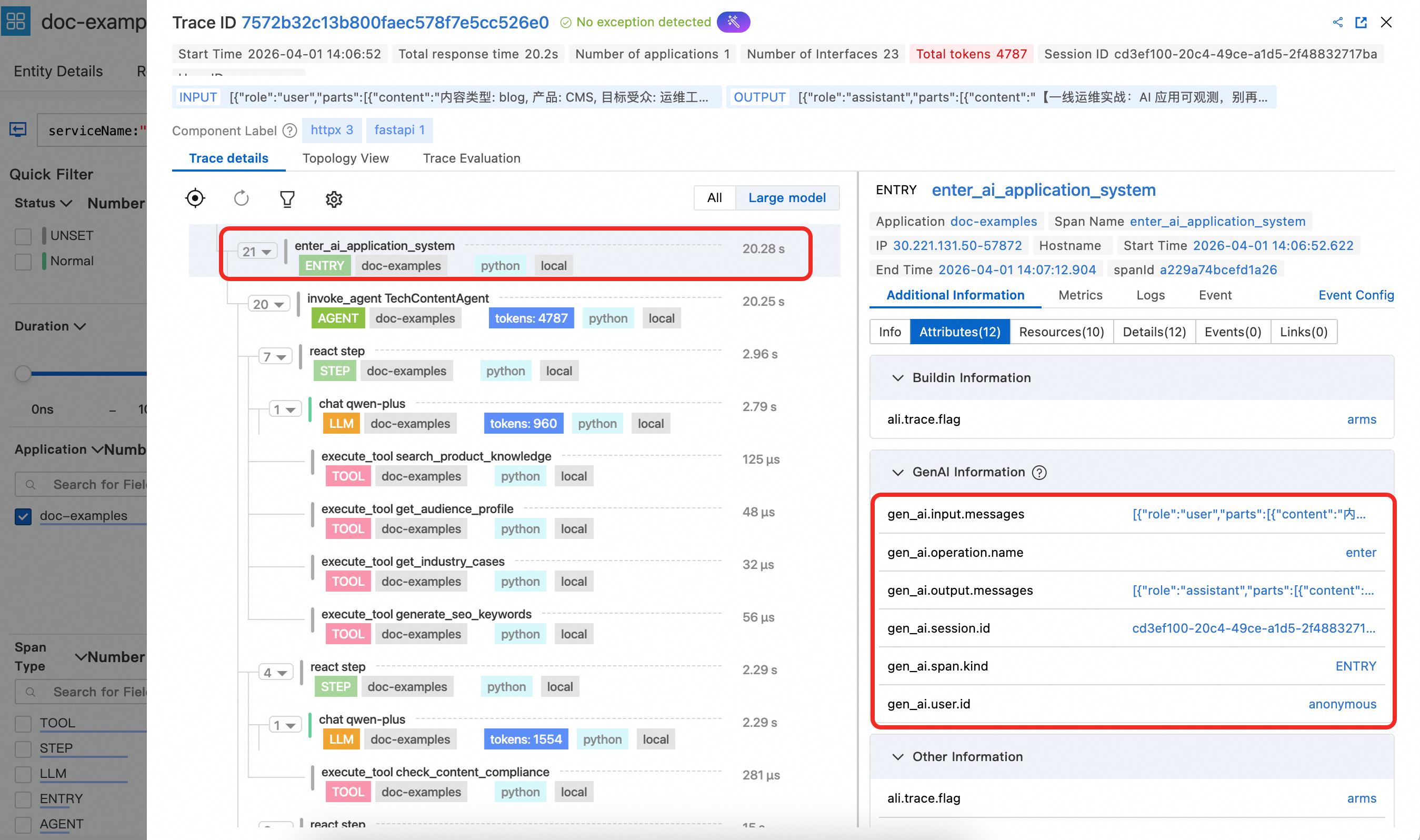
1. Entry スパンの詳細
Entry スパンには、gen_ai.session.id や gen_ai.user.id などの重要な属性が表示されます。関数エントリポイントで設定すると、これらの属性は自動的に LLM、Tool、および他のスパンに伝搬し、セッションおよびユーザー情報に基づいた分析が可能になります。また、Entry スパンには gen_ai.input.messages(ユーザー入力)および gen_ai.output.messages(最終出力)も含まれるため、コンソールでリクエストのやり取り内容全体を簡単に確認できます。
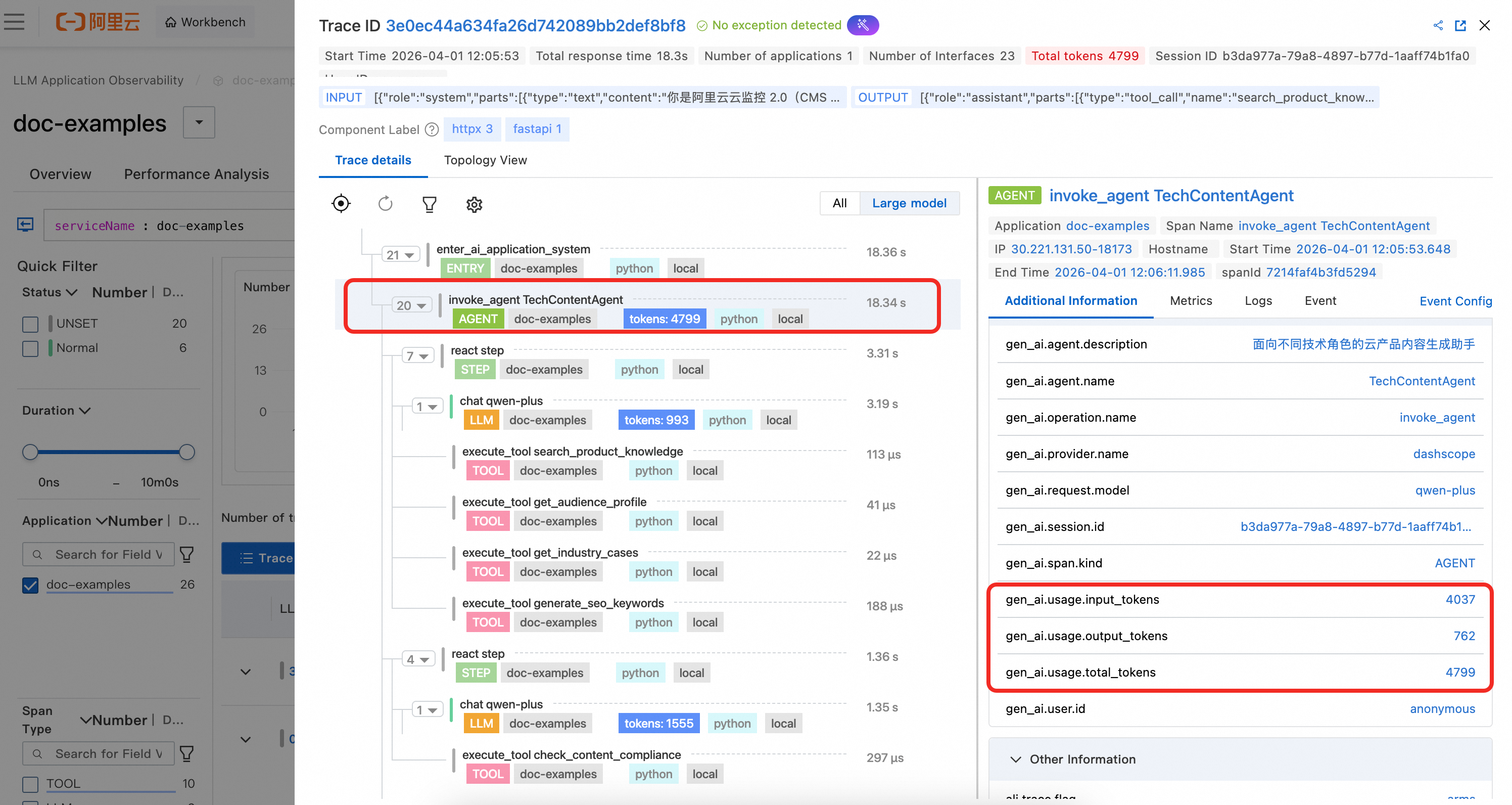
2. Agent スパンの詳細
Agent スパンには、エージェントの定義済み名および説明が表示されます。また、例示コードで計算されたエージェントレベルでの集約トークン使用量統計も表示されます。
3. Tool スパンの詳細
Tool スパンには、ツール名、入力パラメーター、およびツール呼び出しの結果が表示されます。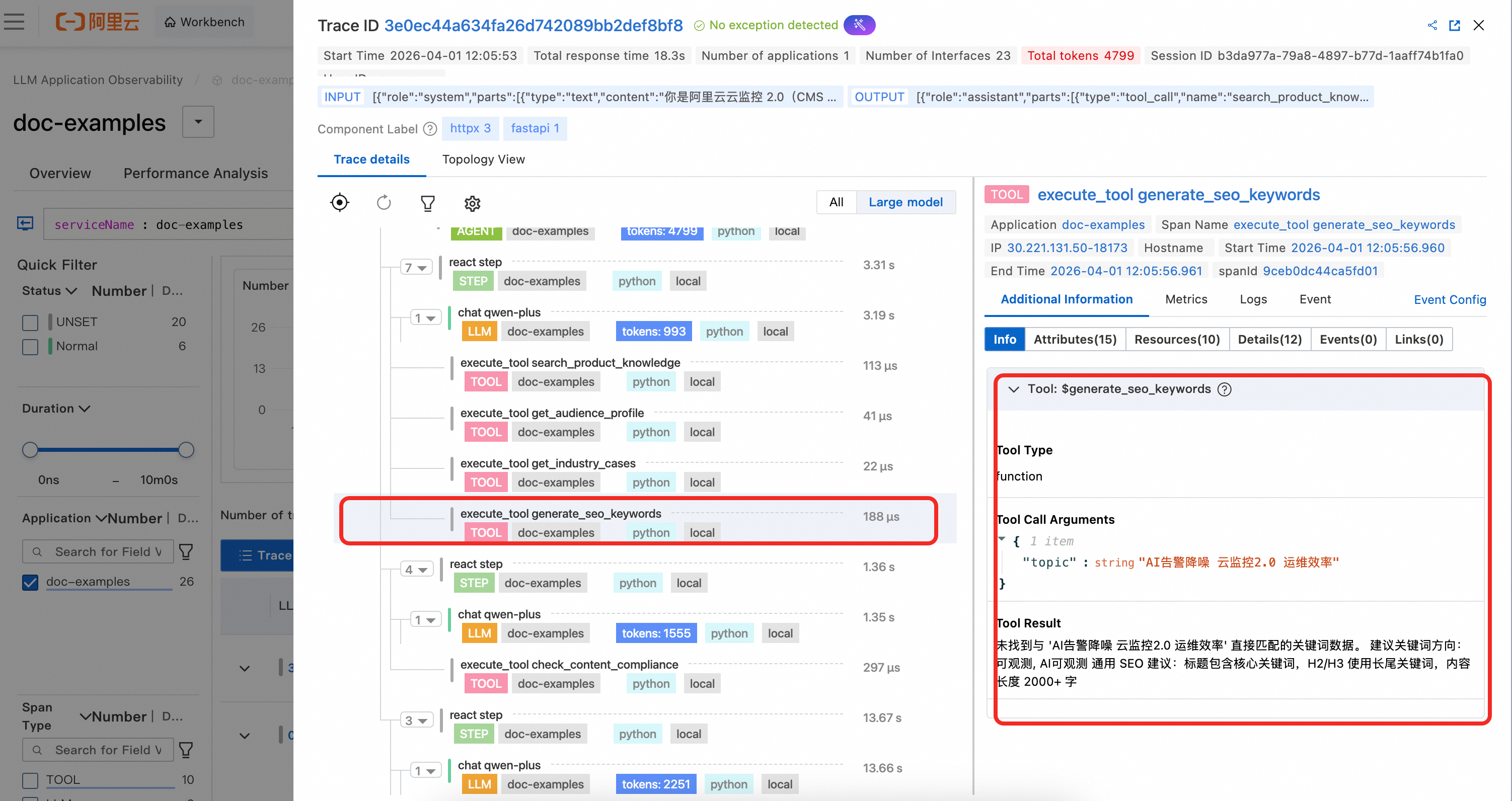
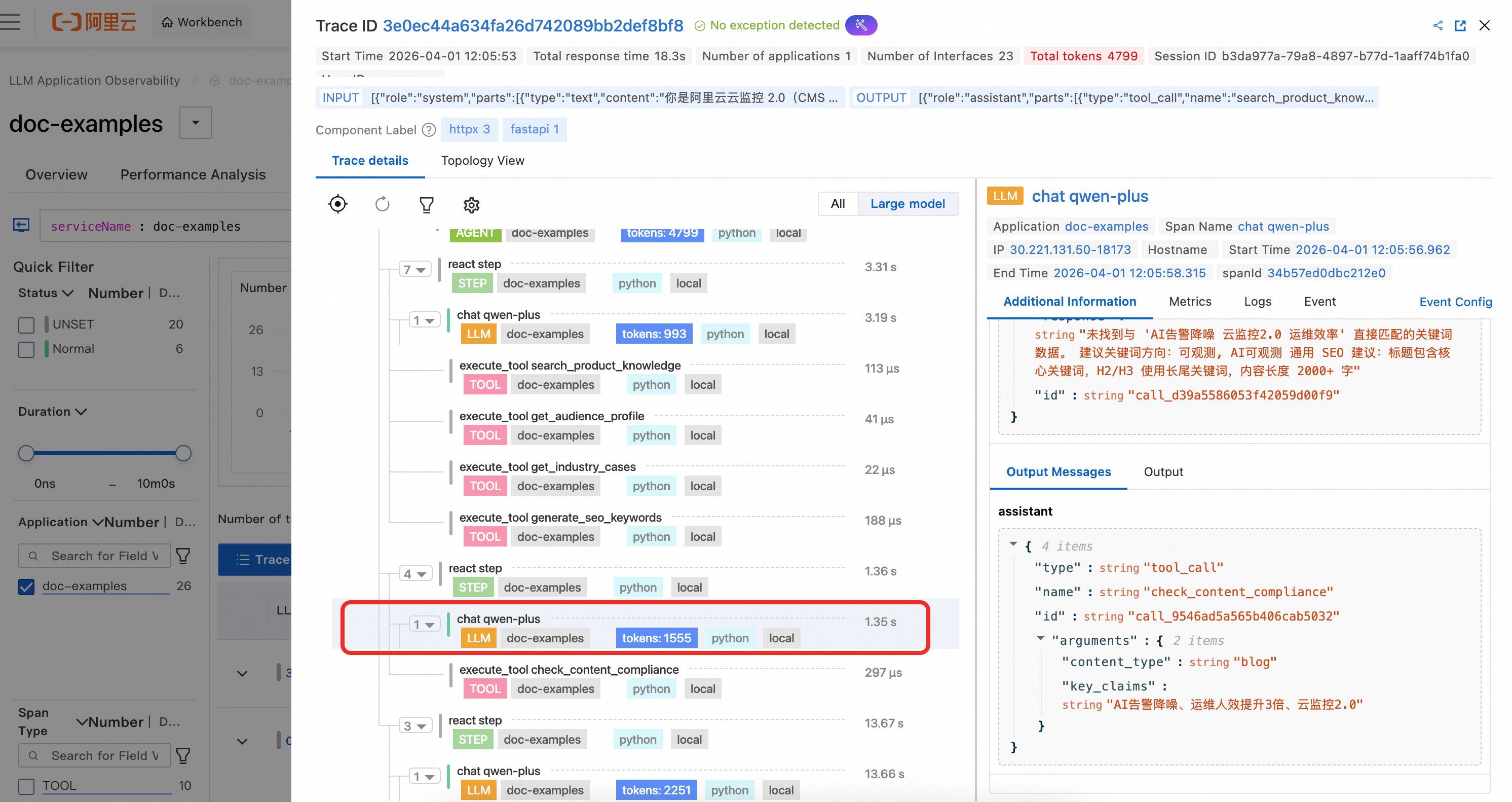
4. LLM スパンの詳細
例示コードでは、LLM スパンは手動でイベントトラッキングされていません。OpenAI 呼び出しであるため、エージェントによって自動的にキャプチャされます。LLM 呼び出しの完全なコンテキスト情報およびトークン消費量を明確に確認できます。
5. カスタムスパンの詳細
例示コードでは、OpenTelemetry SDK を使用して GenAI セマンティクススパンと組み合わせる方法を示すために、2 つのカスタムビジネススパンが作成されています。これらのカスタムスパンは GenAI セマンティクスの一部ではないため、確認するには「すべてのビュー」に切り替える必要があります。
duplicate_tool_detection:このスパンは各 ReAct 反復の前に作成され、エージェントが繰り返しツール呼び出しのループに陥っているかどうかを検出します。スパン属性には、重複が検出されたかどうか、重複ツールのリスト、呼び出し総数、および一意のツール数が記録されます。これにより、ARMS でツール呼び出しループの問題を迅速に診断できます。
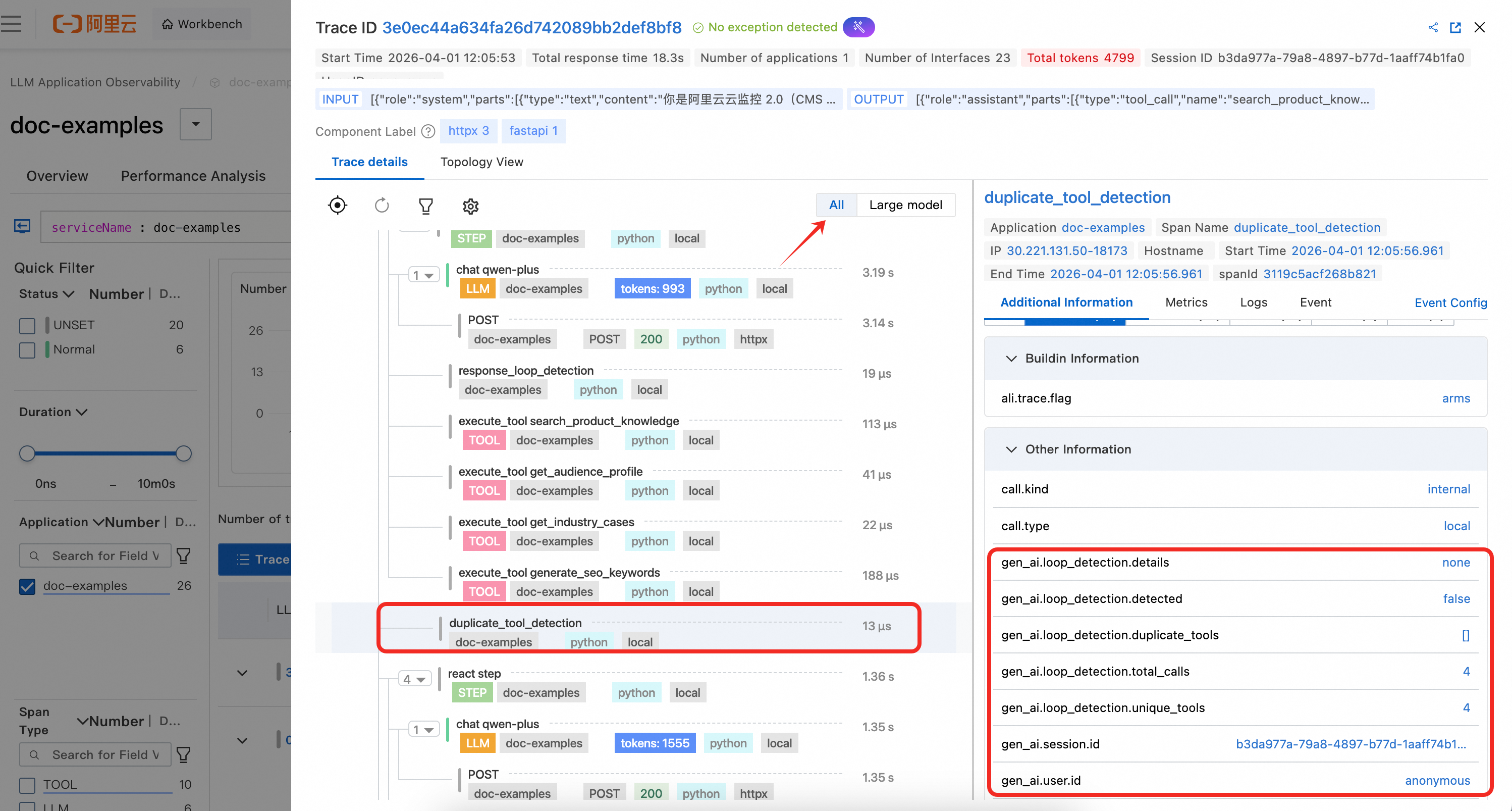
response_loop_detection:このスパンは各 LLM 応答後に作成され、モデルが非常に類似したコンテンツを繰り返し返していないかどうかを検出します。スパン属性には、ループが識別されたかどうか、テキストが同一かどうか、重複率、および現在と前の応答の長さが記録されます。これにより、モデルが繰り返し出力ループに陥る異常なシナリオのトラブルシューティングが可能になります。
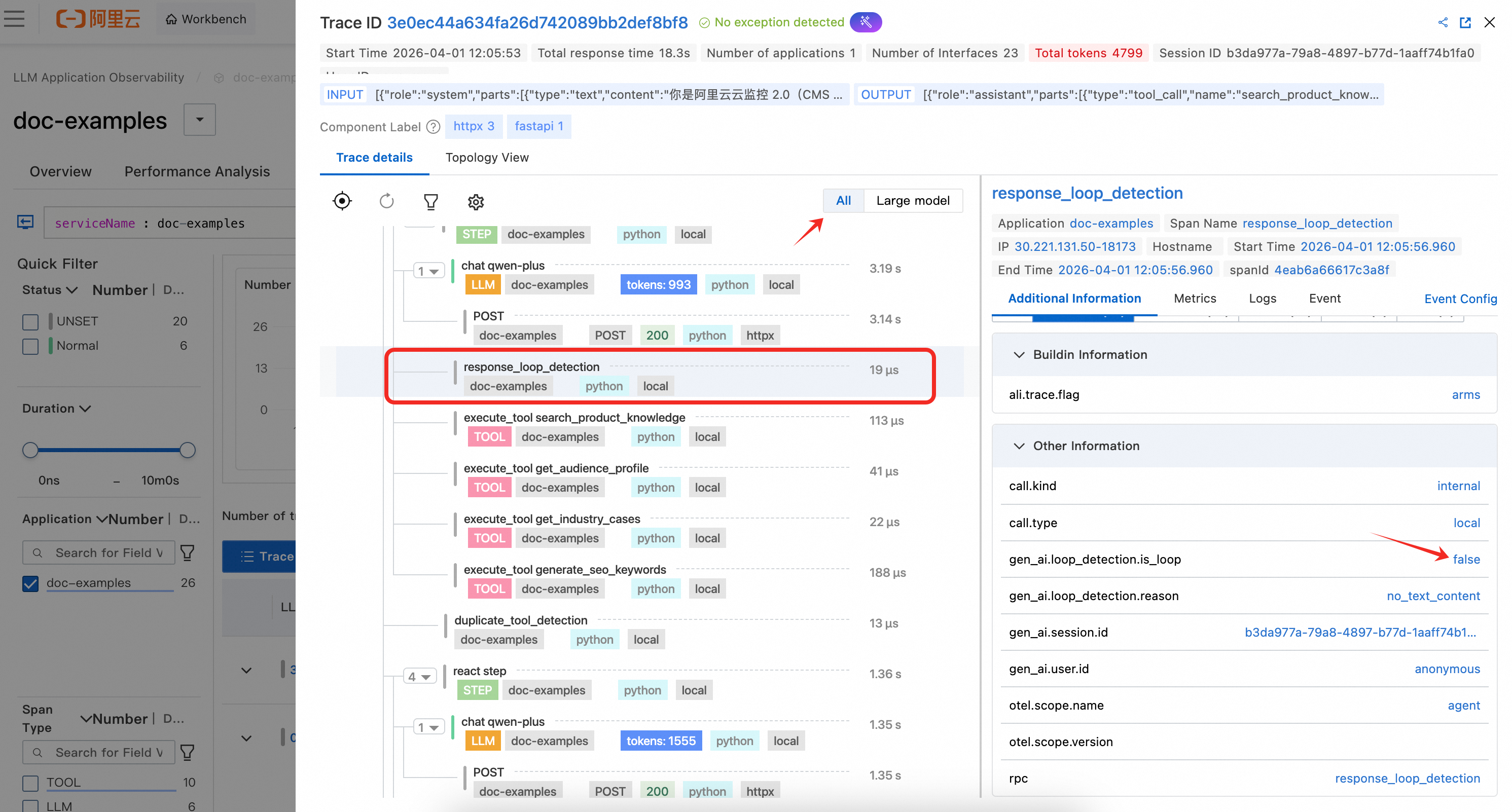
参考文献
loongsuite-util-genaiがサポートするすべてのスパンタイプ(Embedding、Retrieval、Rerank、Memory など)の詳細な使用方法については、「loongsuite-util-genai 完全ドキュメント」をご参照ください。