ApsaraDB for ClickHouse Community-compatible Edition クラスターのデータを、より新しいバージョンを実行する新しいクラスターに移行することで、メジャーエンジンバージョンをアップグレードします。この方法は、バージョン 19.15 以降を実行しているクラスターで利用できます。
ダウングレードはサポートされていません。アップグレードが完了すると、以前のメジャーエンジンバージョンに戻すことはできません。開始する前に、アップグレードと切り替えウィンドウを計画してください。
前提条件
開始する前に、以下が準備できていることを確認してください。
-
2 つの Community-compatible Edition クラスターが、いずれも [実行中] ステータスであること
コミュニティ互換エディションと Enterprise Edition 間の移行については、「ClickHouse コミュニティ互換エディションクラスターを Enterprise Edition クラスターに移行する」をご参照ください。
-
両方のクラスターでデータベースアカウントとパスワードが設定されていること
-
両方のクラスターでホットデータとコールドデータの階層化ストレージ構成が同じであること
-
両方のクラスターが同じリージョンと Virtual Private Cloud (VPC) 内にあり、各クラスターの IP アドレスがもう一方のホワイトリストに追加されていること
クラスターの IP アドレスを確認するには、
SELECT * FROM system.clusters;を実行します。ホワイトリストの構成については、「ホワイトリストを設定する」をご参照ください。 -
移行先クラスターのメジャーエンジンバージョンが、移行元クラスターよりも新しいこと
-
移行先クラスターで利用可能なディスクストレージ (コールドストレージを除く) が、移行元クラスターの使用済みディスクストレージ (コールドストレージを除く) の 1.2 倍以上であること
-
移行元クラスターの各ローカルテーブルが、ちょうど 1 つの分散テーブルとペアになっていること
サポートされているバージョンについては、「ApsaraDB for ClickHouse Community-compatible Edition のリリースノート」をご参照ください。
移行対象と対象外
サポートされる移行内容:
-
データベース、テーブル (MergeTree エンジン)、マテリアライズドビュー、データディクショナリ (SQL で作成されたもののみ)、ユーザー権限、およびクラスター設定
-
MergeTree 以外のテーブル (外部テーブルおよびログテーブル) のテーブルスキーマ (ビジネスデータは含まず、スキーマのみ)
ソースクラスターに MergeTree 以外のテーブルが含まれている場合、移行後、送信先クラスターにはそのスキーマのみが作成され、ビジネスデータは含まれません。 ビジネスデータを移行するには、
remote関数を使用できます。 詳細については、「remote 関数を使用してデータを移行する」をご参照ください。
サポート対象外:
-
XML を使用して作成されたデータディクショナリ
-
Kafka および RabbitMQ エンジンテーブル (ビジネスデータ)
事前準備チェックリスト
移行を開始する前に:
-
どちらのクラスターでも管理操作 (スケールアウト、スペックアップ、またはスペックダウン) が実行されていないことを確認します。
-
SELECT * FROM system.dictionaries WHERE (database = '') OR isNull(database);を実行して、XML で作成されたデータディクショナリを確認します。このクエリが結果を返した場合は、続行する前にそれらのディクショナリを削除してください。 -
データディクショナリが外部サービスにアクセスする場合、そのサービスが到達可能であり、そのホワイトリストが移行先クラスターからのアクセスを許可していることを確認します。
-
データディクショナリが、
HOSTパラメーターが IP アドレスに設定された内部 ClickHouse テーブルをソースとして使用している場合、移行後に IP が変更されます。移行後に新しい IP を使用して、そのデータディクショナリを手動で再作成してください。 -
Kafka および RabbitMQ テーブルの場合:移行元クラスターからそれらをクリアして移行先クラスターで再作成するか、異なるコンシューマーグループを使用してデータ分割を回避します。
-
移行元クラスターのコールドデータの合計を 1 TB 未満に保ちます。コールドデータの量が多いと、移行時間が大幅に長くなり、タスクが失敗する可能性があります。
-
アップグレード後、クライアント設定のエンドポイントを更新して、移行先クラスターを指すようにします。
潜在的な影響
移行中の移行元クラスター:
-
読み取りおよび書き込み操作は正常に続行されます。
-
データ定義言語 (DDL) 操作 (データベースとテーブルの追加、削除、変更) はブロックされます。
-
移行の推定残り時間が 10 分以下になると、データの一貫性を保つために、移行元クラスターは自動的に書き込みを一時停止します。
-
これが事前に設定された書き込み停止タイムウィンドウ内に発生した場合、書き込みはすぐに停止します。
-
これが書き込み停止ウィンドウ外で、タスク作成から 5 日以内に発生した場合、書き込み停止タイムウィンドウを変更して続行します。
-
これが書き込み停止ウィンドウ外で、タスク作成から 5 日を超えて発生した場合、移行は失敗します。タスクをキャンセルし、移行先クラスターから移行されたデータをクリアして、最初からやり直してください。
-
-
すべてのデータが移行されたとき、または移行が完了する前に書き込み停止タイムウィンドウが終了したときに、書き込みは自動的に再開されます。
移行後の移行先クラスター:
移行後、送信先クラスターは一定期間、頻繁にマージ操作を実行するため、I/O 使用量とクエリレイテンシーが増加します。トラフィックを切り替える前に、このレイテンシーの上昇を想定してください。マージ操作にかかる時間を見積もるには、「移行後のマージの持続時間を計算する」をご参照ください。
移行の概要
すべての手順は、移行元クラスターではなく、移行先クラスターで実行されます。
-
Kafka/RabbitMQ エンジンテーブルの記録とクリーンアップ (該当しない場合はスキップ)。
-
移行先クラスターで移行タスクを作成します。
-
移行が完了できるかどうかを評価します (移行元の書き込み速度が 20 MB/s を超える場合にのみ必須)。
-
移行タスクを監視します。
-
移行元クラスターで Kafka/RabbitMQ エンジンテーブルを再構築します (該当しない場合はスキップ)。
-
移行元クラスターで Kafka/RabbitMQ エンジンテーブルを削除します (該当しない場合はスキップ)。
-
移行先クラスターで Kafka/RabbitMQ エンジンテーブルを再構築します (該当しない場合はスキップ)。
-
(オプション) 必要に応じて移行タスクをキャンセルします。
-
(オプション) 書き込み停止タイムウィンドウを変更します。
ステップ 1:Kafka/RabbitMQ エンジンテーブルの記録とクリーンアップ
移行元クラスターに Kafka/RabbitMQ エンジンテーブルが含まれていない場合は、ステップ 1、5、6、7 をスキップし、ステップ 2 から開始してください。
移行を開始する前に、移行元クラスター内のすべての Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューの定義を記録し、暗黙的なテーブルを処理してから、これらのテーブルを削除して移行エラーを回避します。
-
移行元クラスターにログインし、すべての Kafka および RabbitMQ エンジンテーブルと、その下流の依存関係をクエリします。
/* create_table_query: テーブル定義 dependencies_database: このテーブルに依存するテーブルのデータベース dependencies_table: このテーブルに依存するテーブル dependencies_database と dependencies_table から、Kafka/RabbitMQ テーブルに依存するマテリアライズドビューを特定できます */ SELECT * FROM system.tables WHERE engine IN ('RabbitMQ', 'Kafka'); -
マテリアライズドビューの定義を表示して、そのターゲットテーブルが暗黙的なテーブルであるかどうかを確認します。
/* マテリアライズドビューの定義を表示します。 マテリアライズドビューのターゲットテーブルが暗黙的なテーブルである場合は、特に注意してください: マテリアライズドビューを削除すると、暗黙的なテーブルも削除され、データ損失が発生します。 例:CREATE MATERIALIZED VIEW [db.]table_name [TO[db.]name] で TO が指定されていない場合、 システムは自動的に暗黙的なテーブルを作成します。形式は '.inner_id.<TABLE_UUID>' または '.inner.<TABLE>' のようになる可能性があります。 */ SELECT * FROM system.tables WHERE database='<DATABASE>' AND name = '<MATERIALIZED_VIEW_NAME>'; -
マテリアライズドビューのターゲットテーブルが暗黙的なテーブルである場合、後でマテリアライズドビューが削除されたときにデータが失われるのを防ぐために、ターゲットテーブルを新しい名前に RENAME します。
-- データを保護するために、暗黙的なターゲットテーブルを新しい名前に変更します RENAME TABLE <DATABASE>.`.inner_id.<TABLE_UUID>` TO <DATABASE>.<new_target_table_name>; -
Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューを削除します。
-- 最初にマテリアライズドビューを削除します DROP TABLE <DATABASE>.<MATERIALIZED_VIEW_NAME>; -- 次に Kafka/RabbitMQ エンジンテーブルを削除します DROP TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;
記録したすべての DDL 文を必ず保存してください。後で移行元クラスターと移行先クラスターの両方でこれらのテーブルを再構築するために必要になります。RENAME 操作を実行した場合は、マテリアライズドビューを再構築するときに、名前変更されたターゲットテーブルを指す TO 句を使用してください。詳細については、「CREATE MATERIALIZED VIEW」をご参照ください。
ステップ 2:移行タスクの作成
-
ApsaraDB for ClickHouse コンソールにログインします。
-
[クラスター] ページで、[コミュニティ互換エディションのクラスター] タブを選択し、送信先クラスターの ID をクリックします。
-
左側のナビゲーションウィンドウで、[データ移行と同期] > [ClickHouse からの移行] をクリックします。
-
[移行タスクの作成] をクリックします。
-
ソースインスタンスと宛先インスタンスを設定し、次に[接続をテストして次に進む]をクリックします。
接続テストが失敗した場合は、エラーメッセージの指示に従ってインスタンスを再設定してください。
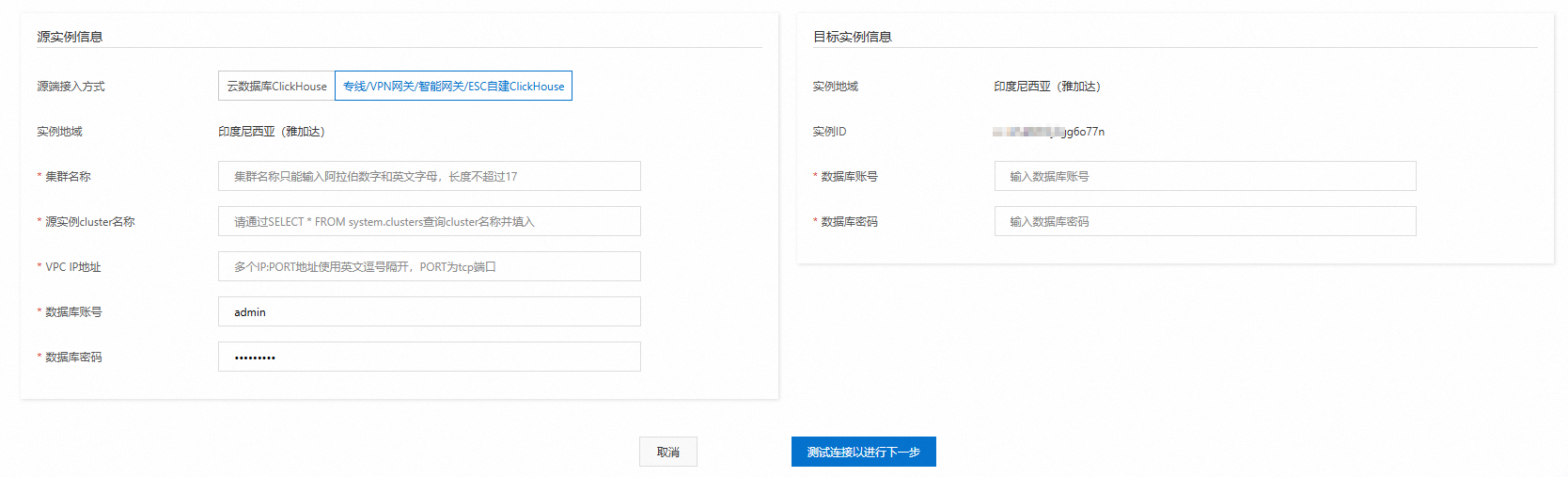
-
移行内容の詳細を確認し、次に [次へ: 事前検出と同期の開始] をクリックします。
-
システムは以下のチェック項目で事前チェックを実行します。
チェック項目 要件 インスタンスのステータス どちらのクラスターでも管理タスク (スケールアウト、設定変更) が実行されていないこと ストレージスペース 移行先ディスクストレージ >= 1.2 × 移行元ディスクストレージ (コールドストレージを除く) ローカルテーブルと分散テーブル 移行元クラスターの各ローカルテーブルに、ちょうど 1 つの分散テーブルがあること -
事前チェックが成功した場合:
-
ページ上の影響の詳細を確認します。
-
[データ書き込み停止時刻] を設定します。
移行の成功率を高めるために、書き込み停止ウィンドウを少なくとも 30 分に設定してください。終了日は今日から 5 日以内でなければなりません。ビジネスへの影響を最小限に抑えるために、オフピーク時にウィンドウをスケジュールしてください。
-
[完了] をクリックしてタスクを作成し、開始します。
-
-
事前チェックが失敗した場合:示された問題を解決してから、移行を再試行してください。
-
ステップ 3:移行が完了できるかどうかの評価
移行元クラスターの書き込み速度が 20 MB/s 未満の場合は、このステップをスキップしてください。
移行元クラスターの書き込み速度が 20 MB/s を超える場合は、移行先クラスターが追いつけることを確認してください。
-
クラスターモニタリング情報の表示を開き、送信先クラスターの[ディスクスループット] メトリックを確認します。
-
2 つの書き込み速度を比較します。
-
移行先の書き込み速度 >= 移行元の書き込み速度:移行の成功率は高いです。ステップ 4 に進んでください。
-
移行先の書き込み速度 < 移行元の書き込み速度: 移行が失敗する可能性があります。移行タスクをキャンセルし、代わりに手動移行を実行してください。
-
ステップ 4:移行タスクの監視
-
[クラスター] ページで、[コミュニティ互換エディションのクラスター] タブを選択し、送信先クラスターの ID をクリックします。
-
左側のナビゲーションウィンドウで、[ClickHouse からの移行] をクリックします。移行リストには、各タスクの[移行ステータス]、[実行情報]、および[データ書き込み停止ウィンドウ]が表示されます。
[実行情報] 列の推定残り時間が 10 分以下になり、ステータスが 移行中 になると、書き込み停止ロジックがトリガーされます。 各シナリオで何が起こるかについては、「潜在的な影響」をご参照ください。
重要-
移行元クラスターに Kafka/RabbitMQ エンジンテーブルが含まれている場合:移行タスクがデータ移行フェーズ (つまり、テーブルスキーマ移行が完了) に入ったら、ステップ 5 を実行して移行元クラスターに Kafka/RabbitMQ エンジンテーブルを再構築し、増分データが再び流れ込み、移行先クラスターに同期されるようにします。
-
設定された書き込み停止ウィンドウの直前に、ステップ 6 を実行して、移行元クラスター上の Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューを削除し、書き込み停止期間中のメッセージのバックログによるデータの不整合を防ぎます。
-
ステップ 5:移行元クラスターでの Kafka/RabbitMQ エンジンテーブルの再構築
移行タスクがデータ移行フェーズ (つまり、テーブルスキーマ移行が完了) に入った後、以前に保存した DDL 文を使用して、移行元クラスターに Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューを再構築します。再構築されると、増分データが再び流れ込み、自動的に移行先クラスターに同期されます。
以前に暗黙的なターゲットテーブルに対して RENAME 操作を実行した場合は、マテリアライズドビューを再構築するときに、名前変更されたターゲットテーブルを指す TO 句を使用してください。詳細については、「CREATE MATERIALIZED VIEW」をご参照ください。
-- 移行元クラスターで Kafka/RabbitMQ エンジンテーブルを再構築します
CREATE TABLE <database>.<kafka_or_rabbitmq_table_name> (...)
ENGINE = Kafka/RabbitMQ
SETTINGS ...;-- マテリアライズドビューを再構築します (名前変更されたターゲットテーブルを指します)
CREATE MATERIALIZED VIEW <database>.<materialized_view_name> TO <database>.<new_target_table_name>
AS SELECT ... FROM <database>.<kafka_or_rabbitmq_table_name>;ステップ 6:移行元クラスターでの Kafka/RabbitMQ エンジンテーブルの削除
設定された書き込み停止ウィンドウの直前に、移行元クラスター上の Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューを削除して、増分データの書き込みを停止し、最終的なデータ同期の一貫性を確保します。
-- 最初にマテリアライズドビューを削除します
DROP TABLE <DATABASE>.<MATERIALIZED_VIEW_NAME>;
-- 次に Kafka/RabbitMQ エンジンテーブルを削除します
DROP TABLE <DATABASE>.<KAFKA_OR_RABBITMQ_TABLE_NAME>;ステップ 7:移行先クラスターでの Kafka/RabbitMQ エンジンテーブルの再構築
移行タスクが完了した後、以前に保存した DDL 文を使用して、移行先クラスターに Kafka/RabbitMQ エンジンテーブルとその下流のマテリアライズドビューを再構築し、増分データ消費パイプラインを復元します。
以前に暗黙的なターゲットテーブルに対して RENAME 操作を実行した場合は、マテリアライズドビューを再構築するときに、名前変更されたターゲットテーブルを指す TO 句を使用してください。詳細については、「CREATE MATERIALIZED VIEW」をご参照ください。
-- 移行先クラスターで Kafka/RabbitMQ エンジンテーブルを再構築します
CREATE TABLE <database>.<kafka_or_rabbitmq_table_name> (...)
ENGINE = Kafka/RabbitMQ
SETTINGS ...;-- マテリアライズドビューを再構築します
CREATE MATERIALIZED VIEW <database>.<materialized_view_name> TO <database>.<target_table_name>
AS SELECT ... FROM <database>.<kafka_or_rabbitmq_table_name>;ステップ 8:(オプション) 移行タスクのキャンセル
-
[クラスター] ページで、[コミュニティ互換エディションのクラスター] タブを選択し、送信先クラスターの ID をクリックします。
-
左側のナビゲーションウィンドウで、[ClickHouseからの移行] をクリックします。
-
対象のタスクの[アクション] 列で、[移行の停止] をクリックします。
-
[移行の停止] ダイアログボックスで、[OK] をクリックします。
キャンセル後、タスクリストがすぐに更新されない場合があります。ページを更新して最新のステータスを確認してください。キャンセル後、[移行ステータス] は [完了] に変わります。新しい移行を開始する前に、データの重複を避けるために、移行先クラスターから移行されたデータをクリアしてください。
ステップ 9:(オプション) 書き込み停止タイムウィンドウの変更
-
[クラスター] ページで、[コミュニティ互換エディションのクラスター] タブを選択し、次に送信先クラスターの ID をクリックします。
-
左側のナビゲーションウィンドウで、[ClickHouse からの移行] をクリックします。
-
対象のタスクの[アクション]列で、[データ書き込み停止時間ウィンドウの変更]をクリックします。
-
[データ書き込み停止時間の変更] ダイアログボックスで、新しい [書き込み停止時間] を選択します。 タスクの作成時と同じルールが、ここでも適用されます。
-
[OK] をクリックします。
次のステップ
すべてのビジネスデータが移行先クラスターに正常に移行されたことを確認した後、移行元クラスターを削除します。
移行元クラスターを削除すると、その中のすべてのデータが永久に削除されます。この操作は元に戻せません。続行する前に、移行が完了していることを確認してください。
削除手順については、「クラスターの削除」をご参照ください。