このトピックでは、DataWorksを使用してMaxComputeからApsaraDB for ClickHouseにデータを同期する方法について説明します。
背景情報
DataWorksのバッチデータ同期機能を使用して、さまざまなデータソースからApsaraDB for ClickHouseにデータを同期できます。 バッチデータ同期でサポートされているデータソースの詳細については、「サポートされているデータソースの種類と同期操作」をご参照ください。
前提条件
DataWorksワークスペースが作成され、MaxComputeが計算エンジンとして選択されます。 詳細については、「ワークスペースの作成」をご参照ください。
Data Integrationの排他的リソースグループが作成および設定されます。 詳細については、「Data Integrationの排他的リソースグループの作成と使用」をご参照ください。
ApsaraDB for ClickHouseクラスターが作成され、データベースアカウントのユーザー名とパスワードが作成されます。 詳細については、「ApsaraDB For ClickHouseクラスターの作成」および「ApsaraDB for ClickHouseクラスターのデータベースアカウントの管理」をご参照ください。
データベースにログインする権限があります。 詳細については、「権限の付与」をご参照ください。
RAMユーザーがDataWorksを使用する場合、Alibaba Cloudアカウントの所有者はRAMユーザーにロールを割り当てる必要があります。 詳細については、「ワークスペースメンバーの追加とロールの割り当て」をご参照ください。
使用上の注意
ApsaraDB for ClickHouseは、Data Integration専用リソースグループのみをサポートしています。
以前に同期されたテーブルを同期する場合は、
TRUNCATE table <TABLE name>;ステートメントを実行して、ApsaraDB for ClickHouseテーブルの同期データをクリアします。
手順
データソースを追加します。
MaxComputeおよびApsaraDB for ClickHouseのデータソースを追加する必要があります。
説明詳細については、「MaxCompute データソースの追加」および「ClickHouseデータソースの追加」をご参照ください。
MaxComputeテーブルを作成します。
DataWorksコンソールにログインします。
左側のナビゲーションウィンドウで、ワークスペース.
上部のナビゲーションバーで、目的のワークスペースが存在するリージョンを選択します。
ワークスペースページ、ワークスペースを見つけて、で、アクション列を作成します。
DataStudioページの上にポインタを移動します。
 アイコンと選択.
アイコンと選択. [テーブルの作成] ダイアログボックスで、[パス] ドロップダウンリストからパスを選択し、[名前] パラメーターを設定します。 この例では、テーブル名としてodptabletest1が使用されています。 [作成] をクリックします。
一般セクションでパラメーターを設定します。

下表に、各パラメーターを説明します。
パラメーター
説明
表示名
テーブルの表示名。
テーマ
テーブルの格納と管理に使用されるフォルダー。 テーブルを格納するレベル1フォルダとレベル2フォルダを指定できます。 レベル1のテーマとレベル2のテーマのパラメーターを使用して、ビジネスカテゴリに基づいてテーブルを分類できます。 同じビジネスカテゴリのテーブルを同じフォルダに格納できます。
説明[DataStudio] ページの [Workspace Tables] ペインにあるレベル1およびレベル2のテーマを使用すると、フォルダー内のテーブルをより適切に管理できます。 現在のテーブルは、[ワークスペーステーブル] ウィンドウでテーマごとにすばやく見つけることができます。 利用可能なテーマがない場合は、作成できます。 テーマの作成方法については、「テーブルの設定の管理」トピックのテーブルのフォルダの作成または管理セクションを参照してください。
クリックDDLツールバーで
[DDL] ダイアログボックスで次の文を入力し、[テーブルスキーマの生成] をクリックします。
CREATE TABLE IF NOT EXISTS odptabletest1 ( v1 TINYINT, v2 SMALLINT );開発環境へのコミットと本番環境へのコミットシーケンスで。
MaxComputeテーブルにデータを書き込みます。
DataStudioページをクリックします。アドホッククエリ左側のナビゲーションウィンドウに表示されます。
ポインターを
 アイコンと選択.
アイコンと選択. ノードの作成ダイアログボックスで、パスドロップダウンリストを設定し、名前パラメーターを使用します。
確認.
ノードの編集ページで、次の文を入力してMaxComputeテーブルにデータを書き込みます。
insert into odptabletest1 values (1,"a"),(2,"b"),(3,"c"),(4,"d"); ツールバーのアイコンをクリックします。
ツールバーのアイコンをクリックします。 MaxComputeコンピューティングコストの見積もりダイアログボックスで、実行.
ApsaraDB for ClickHouseテーブルの作成
ApsaraDB for ClickHouse コンソールにログインします。
上部のナビゲーションバーで、目的のクラスターがデプロイされているリージョンを選択します。
クラスターページで、クラスターエディションに基づいてタブをクリックし、管理するクラスターのIDをクリックします。
クラスター情報ページをクリックします。データベースへのログオン右上隅にあります。
データベースインスタンスにログインダイアログボックスで、データベースアカウントのユーザー名とパスワードを入力し、ログイン.
次の文を入力し、[実行 (F8)] をクリックします。 サンプル文:
create table default.dataworktest ON CLUSTER default ( v1 Int, v2 String ) ENGINE = MergeTree ORDER BY v1;説明ApsaraDB for ClickHouseテーブルのスキーマタイプは、MaxComputeテーブルのスキーマタイプをマッピングする必要があります。
ワークフローを作成します。
すでにワークフローがある場合は、この手順をスキップします。
DataStudioページをクリックします。スケジュール済みワークフロー左側のナビゲーションウィンドウに表示されます。
ポインターを
アイコンと選択ワークフローの作成. ワークフローの作成ダイアログボックスで、ワークフロー名パラメーターを使用します。
重要名前は1 ~ 128文字で、英数字、アンダースコア (_) 、ピリオド (.) を使用できます。
作成.
バッチ同期ノードを作成します。
新しく作成したワークフローをクリックし、右クリックします。データ統合.
選択.
ノードの作成ダイアログボックスで、名前パラメータからパスを選択し、パスドロップダウンリスト。
重要ノード名は1 ~ 128文字で、英数字、アンダースコア (_) 、およびピリオド (.) を使用できます。
確認.
データソースと宛先を設定します。
Source: サポートされているデータソースを選択します。 この例では、MaxComputeが選択されています。
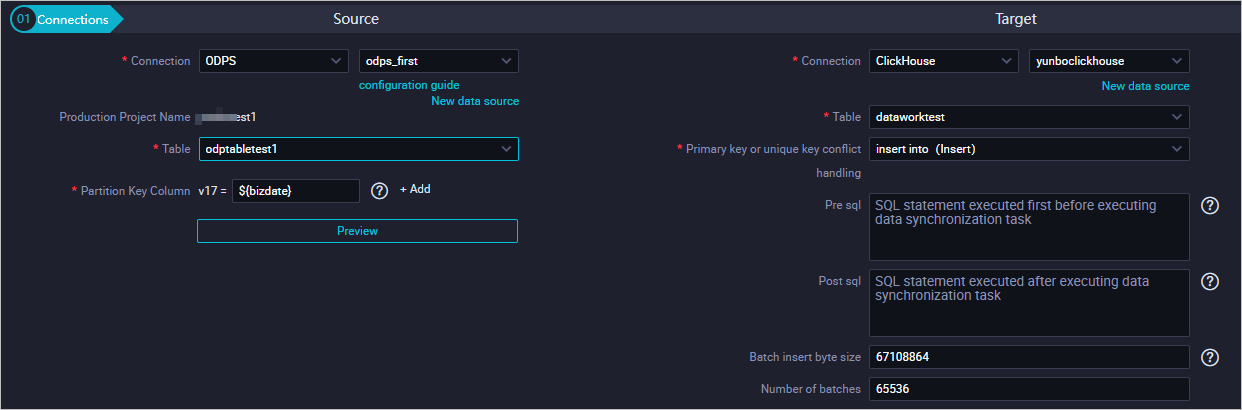
下表に、各パラメーターを説明します。
パラメーター
説明
接続
データソースのタイプと名前。
制作プロジェクト名
本番環境のプロジェクトの名前。 値は変更できません。
Table
同期するテーブル。The table that you want to synchronize.
パーティションキー列
毎日の増分データが特定の日付のパーティションに格納されている場合は、パーティション情報を指定して毎日の増分データを同期できます。 たとえば、v17を ${bizdate} に設定します。
説明DataWorksは、パーティション分割されたMaxComputeテーブルのフィールドをマッピングできません。 パーティション分割されたMaxComputeテーブルからデータを読み取る場合は、MaxCompute Readerを設定するときに各パーティションを指定する必要があります。
説明パラメーターの詳細については、「MaxCompute データソース」をご参照ください。
ターゲット: を選択ClickHouse.
下表に、各パラメーターを説明します。
パラメーター
説明
接続
データソースのタイプと名前。 [ClickHouse] を選択します。
Table
同期されたデータをインポートするテーブル。
主キーまたは一意キーの競合処理
この値をinsert into (Insert) に設定します。
Pre sql
同期タスクが実行される前に実行するSQL文。
ポストsql
同期タスクの実行後に実行するSQL文。
一括挿入バイトサイズ
挿入される最大バイト数。
バッチ数
1つのバッチに挿入されるデータエントリの数。
(オプション) マッピング: フィールドマッピングを選択できます。 左側のフィールドは右側のフィールドに対応します。
 説明
説明パラメーターの詳細については、「コードレスUIを使用したバッチ同期タスクの設定」トピックの「手順4: ソースフィールドと宛先フィールド間のマッピングの設定」をご参照ください。
(オプション)チャンネル: 最大伝送速度とダーティデータチェックルールを設定します。
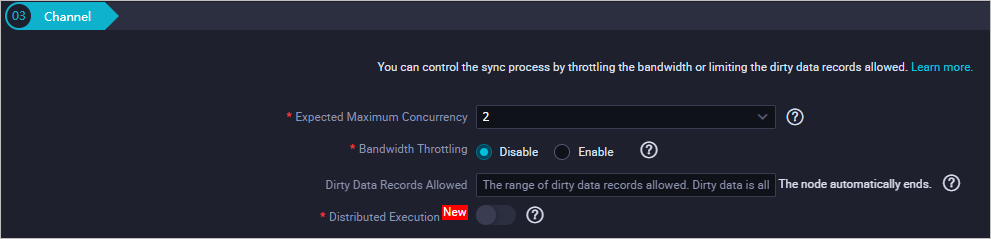 説明
説明パラメーターの詳細については、コードレスUIを使用したバッチ同期タスクの設定の手順5: チャネル制御ポリシーの設定セクションをご参照ください。
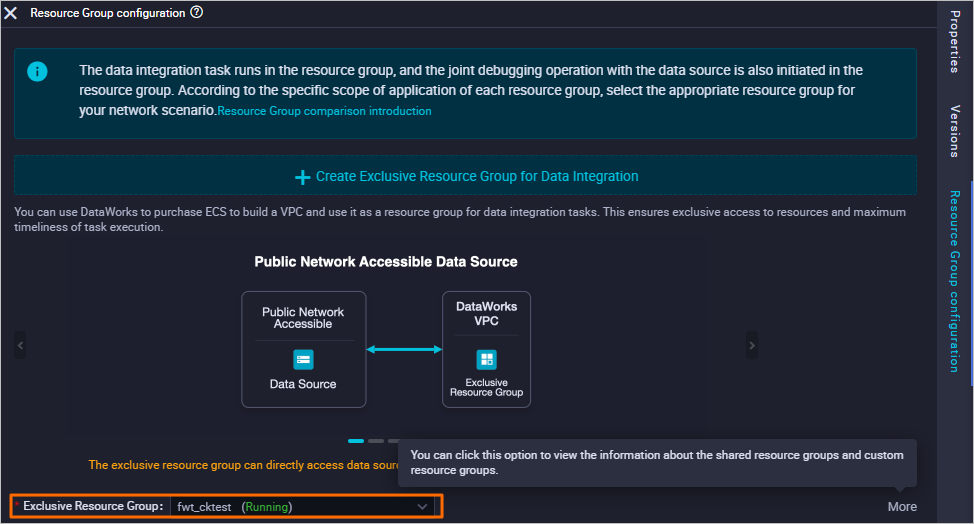
Data Integrationのリソースグループを設定します。
右側の [リソースグループの設定] をクリックし、[排他的リソースグループ] ドロップダウンリストからグループを選択します。
同期タスクを実行して保存します。
をクリックし、
 ツールバーのアイコンをクリックして、同期タスクを保存します。
ツールバーのアイコンをクリックして、同期タスクを保存します。 ツールバーの
 アイコンをクリックして、同期タスクを実行します。
アイコンをクリックして、同期タスクを実行します。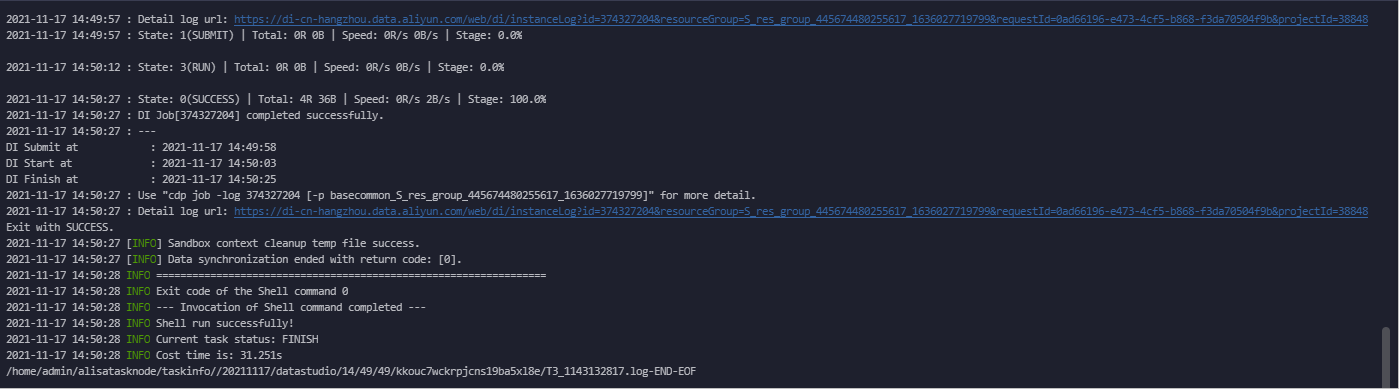
データ同期結果の確認
ApsaraDB for ClickHouse コンソールにログインします。
上部のナビゲーションバーで、目的のクラスターがデプロイされているリージョンを選択します。
On theクラスターページで、クラスターエディションに基づいてタブをクリックし、管理するクラスターのIDをクリックします。
On theクラスター情報ページをクリックします。データベースへのログオン右上隅にあります。
では、データベースインスタンスにログインダイアログボックスで、データベースアカウントのユーザー名とパスワードを入力し、ログイン.
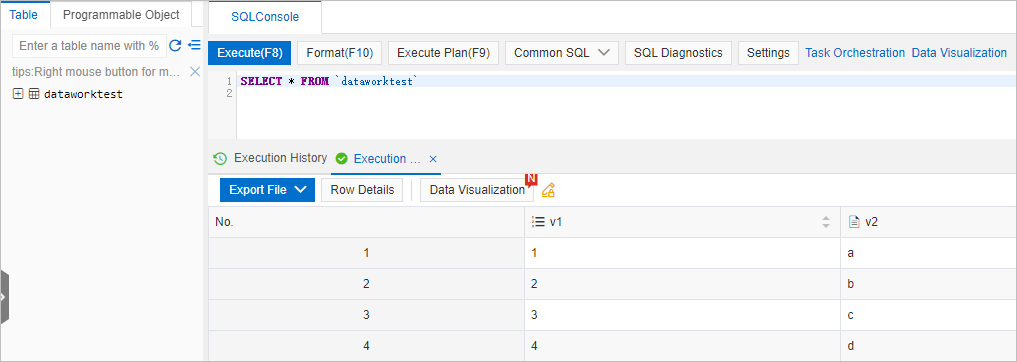
次のクエリステートメントを入力し、[実行] (F8) をクリックして、データが同期されているかどうかを確認します。
SELECT * FROM dataworktest;次の結果が返されます。
 説明
説明クエリステートメントの実行後に結果が返された場合、データはMaxComputからApsaraDB for ClickHouseに同期されています。