Elastic Container Instance (ECI) のスケーリンググループと Application Load Balancer (ALB) を使用して、複数ゾーンにまたがるスケーラブルで可用性の高い大規模言語モデル (LLM) 推論サービスを迅速にデプロイします。
ソリューションの概要
このソリューションでは、マルチゾーンの高可用性アーキテクチャを使用します。推論サービスは、単一リージョン内の複数のゾーンに分散された Elastic Container Instance (ECI) インスタンス上で実行され、ゾーンレベルの災害対策を提供します。Application Load Balancer (ALB) はインテリジェントにトラフィックを誘導し、Object Storage Service (OSS) はモデルリポジトリとして機能し、事業継続性とデータの信頼性を確保します。次の図にソリューションアーキテクチャを示します。

メリット
高可用性:このソリューションは、複数のサーバーに ワークロード を分散させることで 単一障害点 を回避します。これにより、サービス容量が増加し、単一コンポーネントの障害によるサービスの中断を防ぎます。
弾力的スケーリング:スケーリンググループが推論サービス クラスターを管理し、ワンクリックで ECI インスタンスの数を調整することで、迅速なスケールアウトができます。また、オートスケーリングを設定して、ワークロードに基づいて リソースをオンデマンドで割り当てる こともできます。
手順
クラスターネットワークの計画。Virtual Private Cloud (VPC) と複数のゾーンに vSwitch を作成し、クラスターの基盤となるネットワーク環境を構築します。
OSS バケットの作成。このバケットは、モデルの重みファイルを格納するために使用します。
インスタンス RAM ロールの設定。ECI インスタンスは、手順 2 で作成した OSS バケットにアクセスするために、このロールを引き受けます。
イメージキャッシュの準備。ECI コンソールでイメージキャッシュを作成してインスタンスの起動を高速化し、モデルの重みファイルを OSS バケットにアップロードします。
ALB インスタンスの作成。ALB インスタンスは、サービスエンドポイントとして機能します。
スケーリンググループの作成。スケーリンググループを作成し、ALB インスタンスに関連付けて、新しい ECI インスタンスを ALB インスタンスのバックエンドサーバーグループに自動的に追加します。
サービスの開始。スケーリンググループの期待されるインスタンス数を調整してサービスを開始し、サービスが利用可能になるまで待機します。
1. クラスターネットワークの計画
最初にクラスターネットワークを計画し、次に Virtual Private Cloud (VPC) と vSwitch を作成します。高可用性を実現するために、Elastic Container Instance (ECI) インスタンスなどのリソースを複数のゾーンに分散し、単一ゾーンの停止によるサービス中断を防止します。この例では、1 つの VPC と異なるゾーンにある 2 つの vSwitch を使用したデュアルゾーン配置を使用します。
既存の VPC を再利用して、この手順をスキップすることもできます。
コンソールで、以下のように VPC を 1 つと vSwitch を 2 つ作成します。
①②:VPC の作成 をクリックします。
③:リージョン: China (Hangzhou)
④:名前:
vpc-ess-hangzhou⑤:IPv4 CIDR ブロック: 192.168.0.0/16 を選択します。

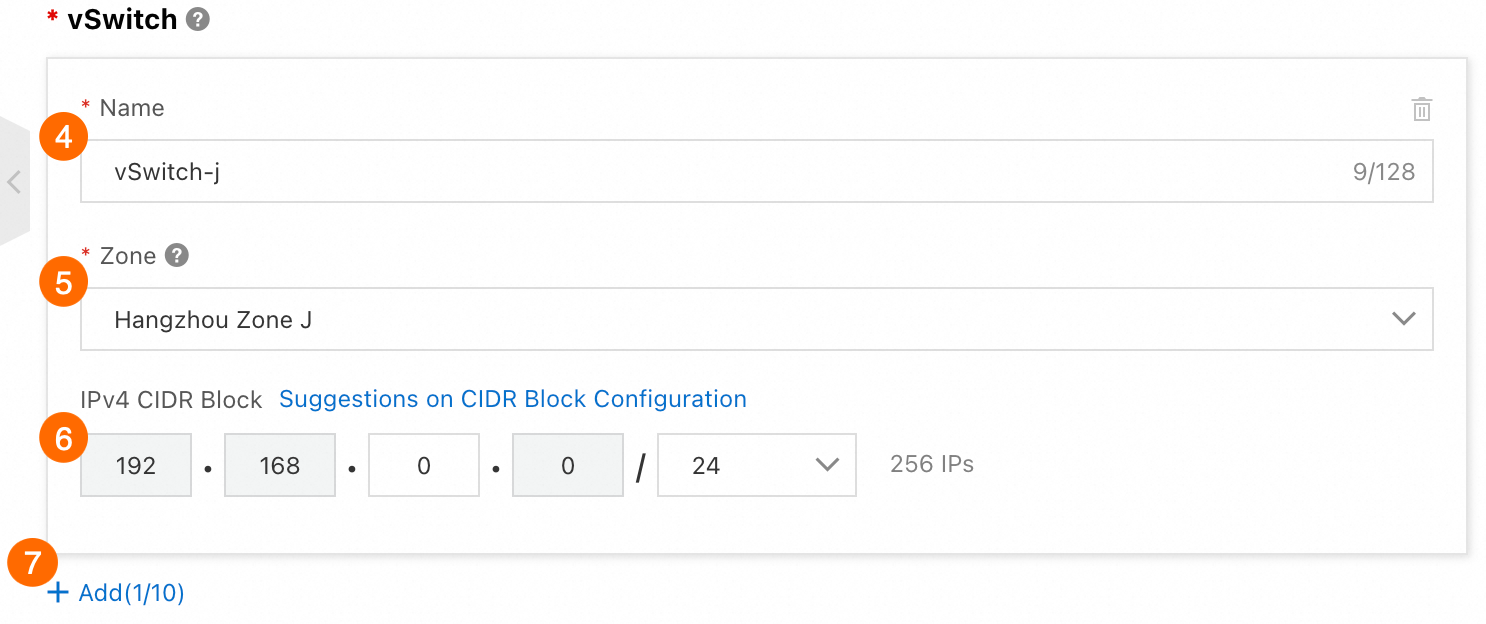
vSwitch 1 :
⑥:名前:
vSwitch-j⑦:ゾーン: Zone J
⑧:IPv4 CIDR ブロック: 192.168.0.0/24
⑨:追加 をクリックして vSwitch 2 を作成します。
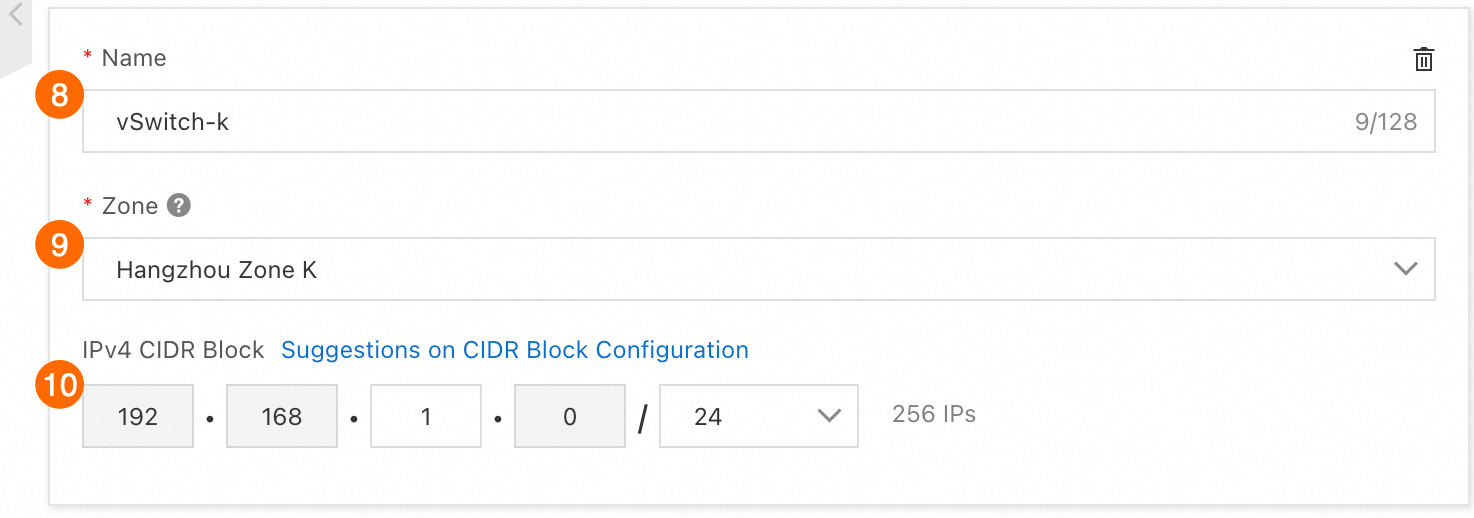
vSwitch 2 :
⑩:名前:
vSwitch-k⑪:ゾーン: Zone K
⑫:IPv4 CIDR ブロック: 192.168.1.0/24
OK をクリックし、VPC が作成されるまで待機します。
2. Object Storage Service バケットの作成
ネットワークを設定した後、Object Storage Service (OSS) バケットを作成してモデルの重みファイルを格納します。ECI インスタンスはこのバケットからファイルを読み取ります。手順は次のとおりです。
既存の Object Storage Service (OSS) バケットを再利用する場合、この手順は省略できます。
Object Storage Service コンソールで、バケットを作成します。
主要なパラメーターを次のように設定し、その他はデフォルト値のままにします。
①: バケットの作成 をクリックします。
②: バケット名 この名前は、後でストレージスペースをマウントするときに必要です。
③: リージョン [特定のリージョン] を選択し、ECI インスタンスと同じリージョンであることを確認してください。このチュートリアルでは [中国東部1 (杭州)] を使用します。
同一リージョン内の ECI インスタンスから OSS バケットにアクセスする場合、内部ネットワークが使用され、データ転送料金は発生しません。 詳細については、「ECI インスタンスから内部ネットワーク経由で OSS リソースにアクセスする」をご参照ください。

完全な作成 をクリックします。
3. Create an instance RAM role
Create an instance RAM role that ECI instances can assume to read the model weight files from your OSS bucket. Follow these steps:
In the console, create an instance RAM role. The key parameter settings are described below.
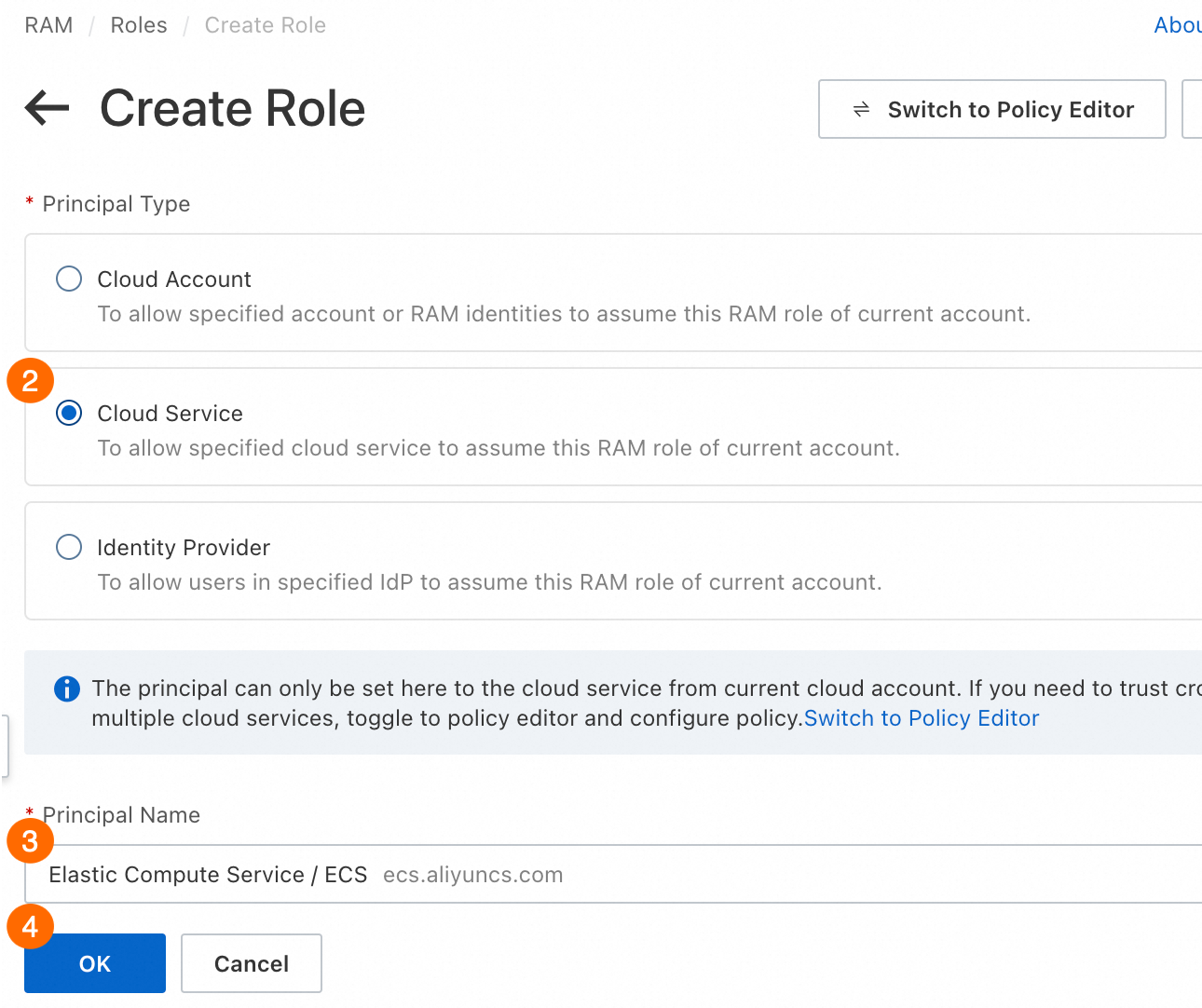
①: Click [ロールの作成].
②: Principal Type. Select Cloud Service.
③: Principal Name. Select [Ecsインスタンス].
4. Click [OK] and set a name for the instance RAM role as prompted.
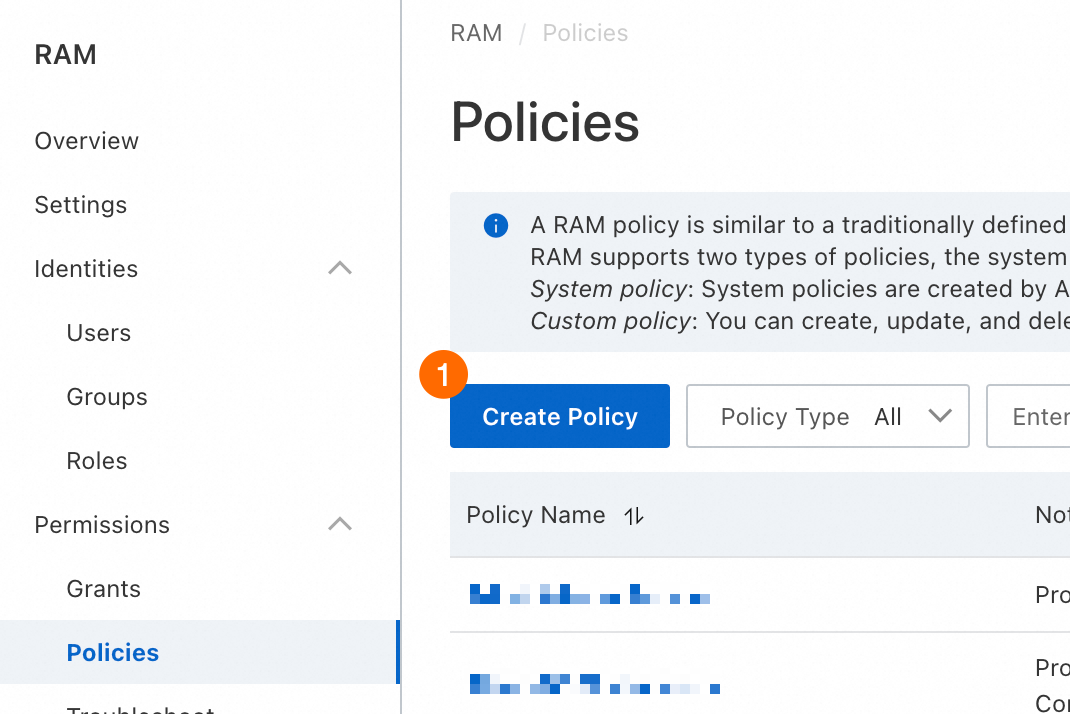
In the console, create the following policy.
①: Click [ポリシーの作成].
②: Click [JSON].
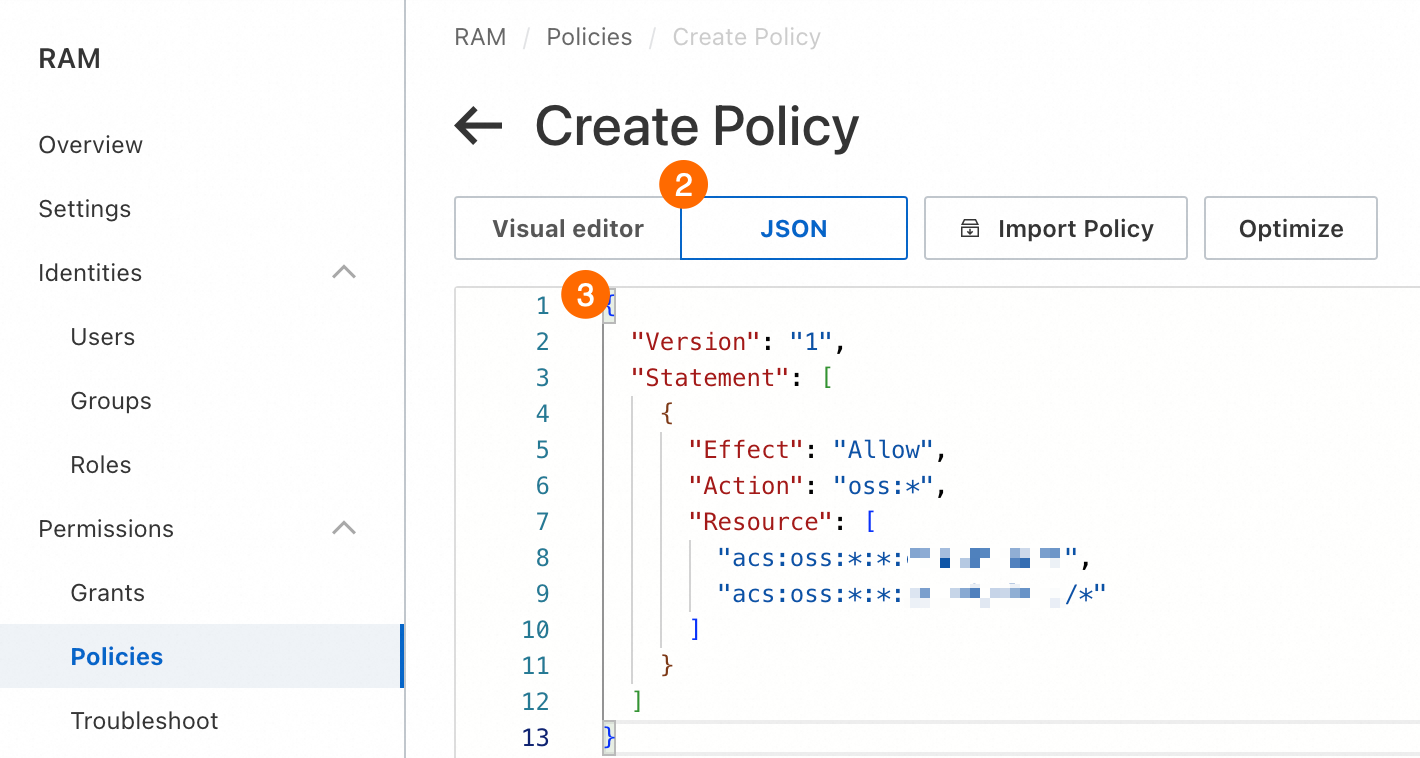
③: This policy grants full permissions for a specific bucket. Use the following policy script.
重要When you configure this policy, replace
<bucket_name>with the [バケット名] of the bucket that you created.{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": "oss:*", "Resource": [ "acs:oss:*:*:<bucket_name>", "acs:oss:*:*:<bucket_name>/*" ] } ] }Click [OK] and set a name for the policy as prompted.
In the console, grant permissions to the instance RAM role.
①②: Click [権限の付与].
③: [権限付与の対象]. Select the instance RAM role that you created.
④: [ポリシー]. Select the policy that you created.
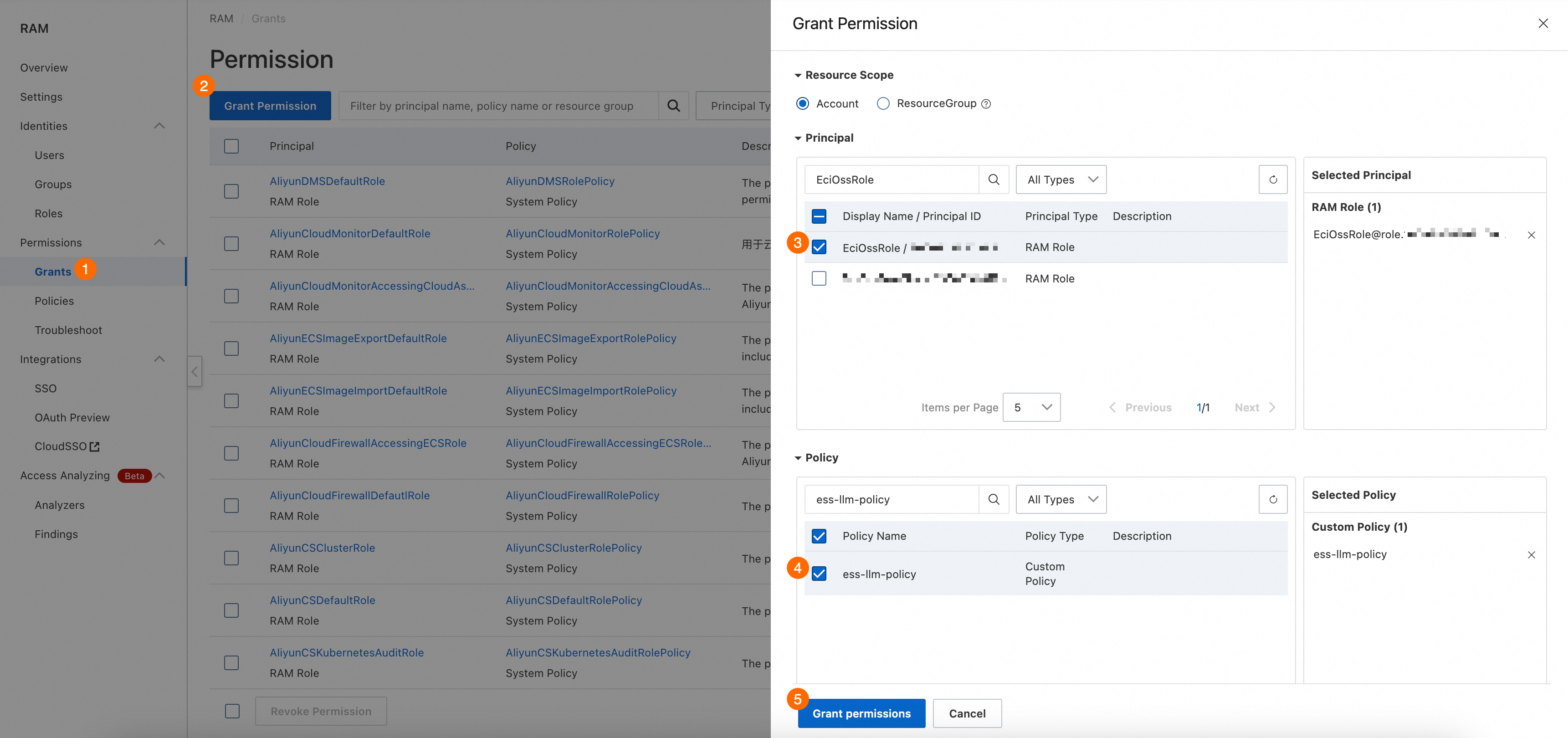
Click [Grant permissions].
4. イメージキャッシュとモデルファイルの準備
このソリューションで ECI インスタンスが使用するコンテナイメージは大容量です。インスタンスの起動を高速化するために、ECI コンソールで イメージキャッシュ を作成します。また、モデルの読み込みを高速化するために、モデルの重みファイルを OSS バケットにダウンロードする必要があります。
ECI コンソールで、ECI イメージキャッシュを作成します。
①②: イメージキャッシュの作成 をクリックします。
③④: [リージョンとゾーン]。リージョンは、ステップ 1 で指定した VPC のリージョンと同じである必要があります。ゾーンは、ステップ 1 で作成した vSwitch のいずれかのゾーンと同じである必要があります。
⑤⑥: ネットワークでは、ステップ 1 で作成した VPC と、いずれかの vSwitch を選択します。
⑦: Elastic IP アドレス。 既存の Elastic IP アドレス (EIP) を選択します。 EIP がない場合は、EIP コンソール をクリックして作成します。 EIP が作成されたら、このページに戻り、更新アイコン
 をクリックして、新しい EIP を選択します。
をクリックして、新しい EIP を選択します。⑧: [セキュリティグループ]。 セキュリティグループを選択します。 セキュリティグループがない場合は、セキュリティグループの作成 をクリックします。 セキュリティグループが作成されたら、このページに戻り、セキュリティグループを選択します。
⑨: [Image Cache Name]。vllm と入力します。
⑩: [キャッシュのサイズ]。100 GB。
⑪: [イメージ]:
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm。⑫: [バージョン]。
0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04。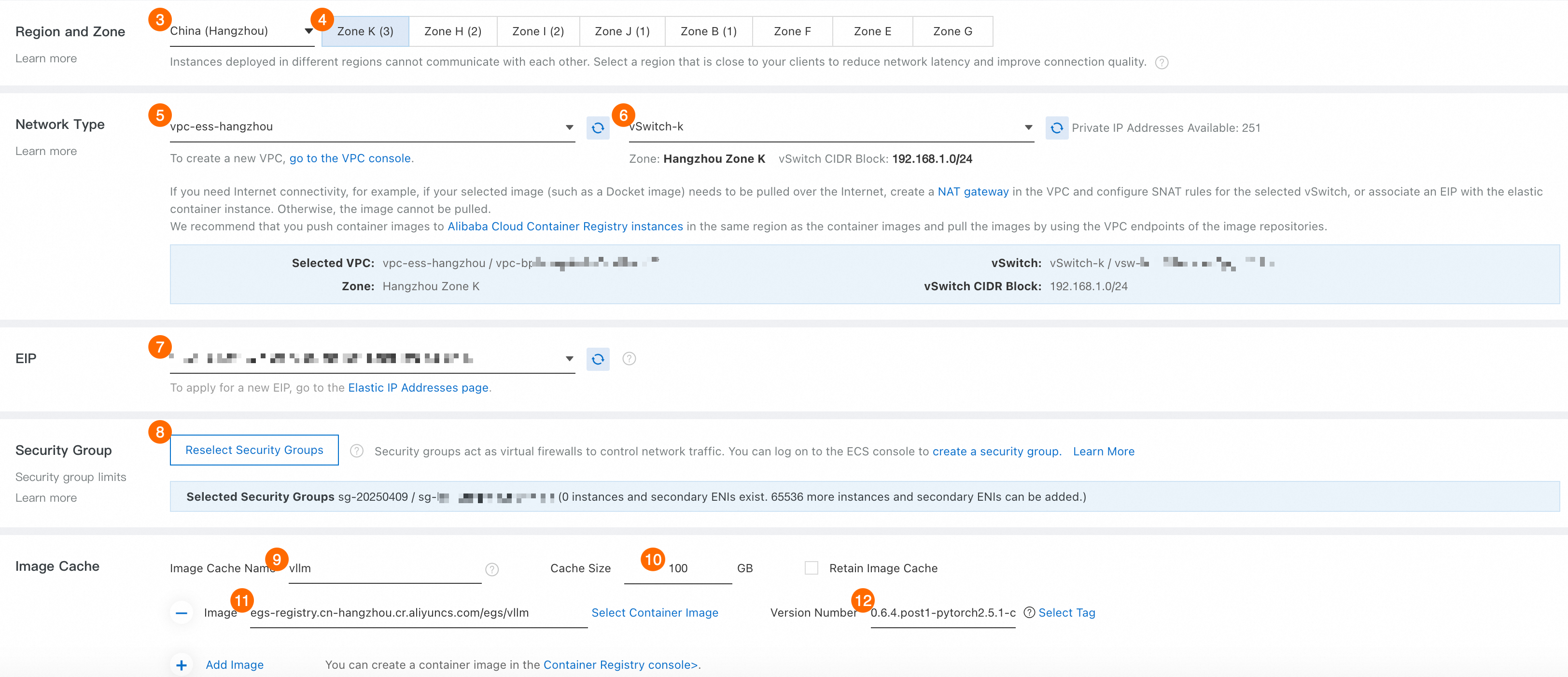

イメージキャッシュが作成されるまで待ちます。これには約 15 分かかる場合があります。ECI コンソールのイメージキャッシュページで、作成の進行状況を確認できます。

ECI コンソールで、一時的な ECI インスタンスを起動して、モデルの重みファイルを OSS バケットにダウンロードします。
①②: エラスティックコンテナーグループの作成 をクリックします。
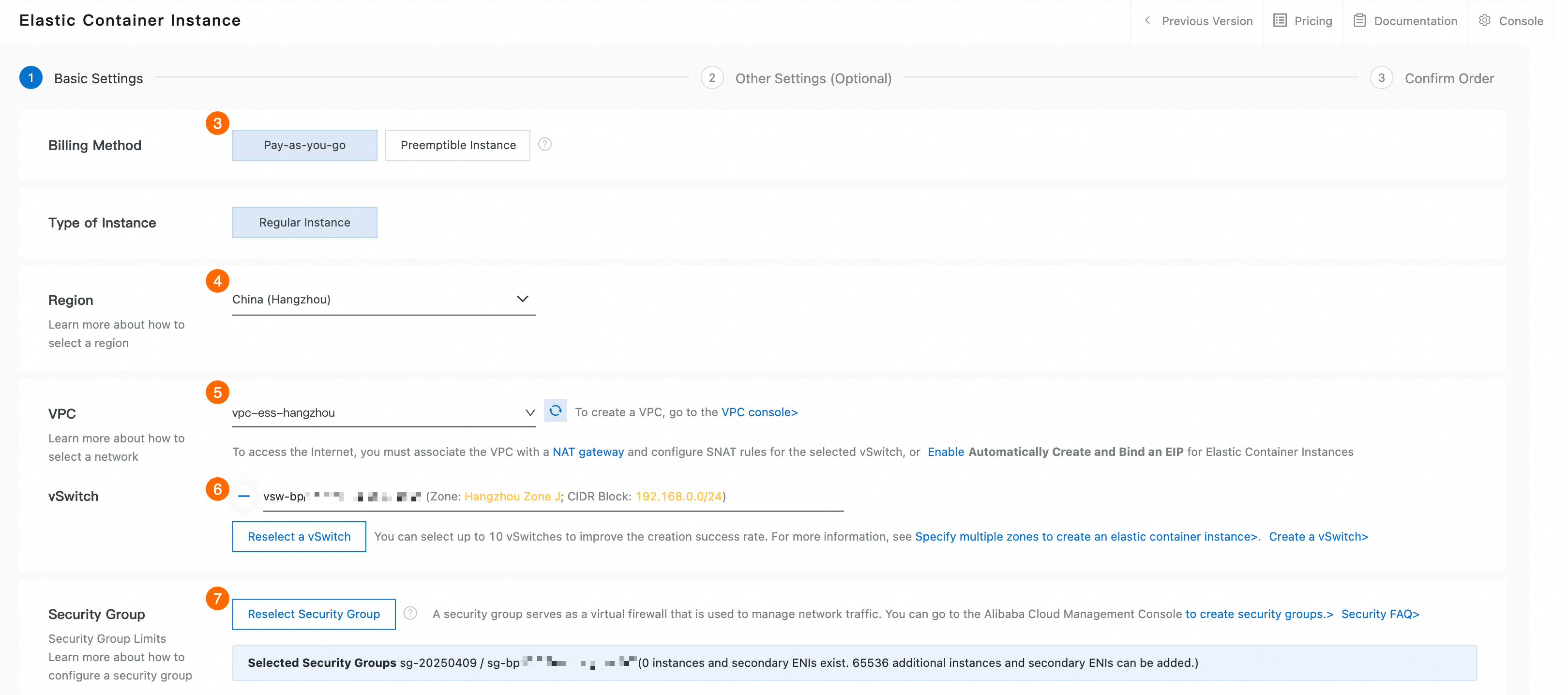
③: [支払いモード]: 従量課金。
④: [リージョン]。 リージョンは、ステップ 1 で指定した VPC のリージョンと同じである必要があります。 このチュートリアルでは、中国 (杭州) を例として使用します。
⑤: VPC には、ステップ 1 で作成した VPC を選択します。
⑥: [vSwitch]。 ステップ 1 で作成した vSwitch を選択します。
⑦: [セキュリティグループ]。 画面の指示に従ってパラメーターを設定します。
コンテナーグループの設定:
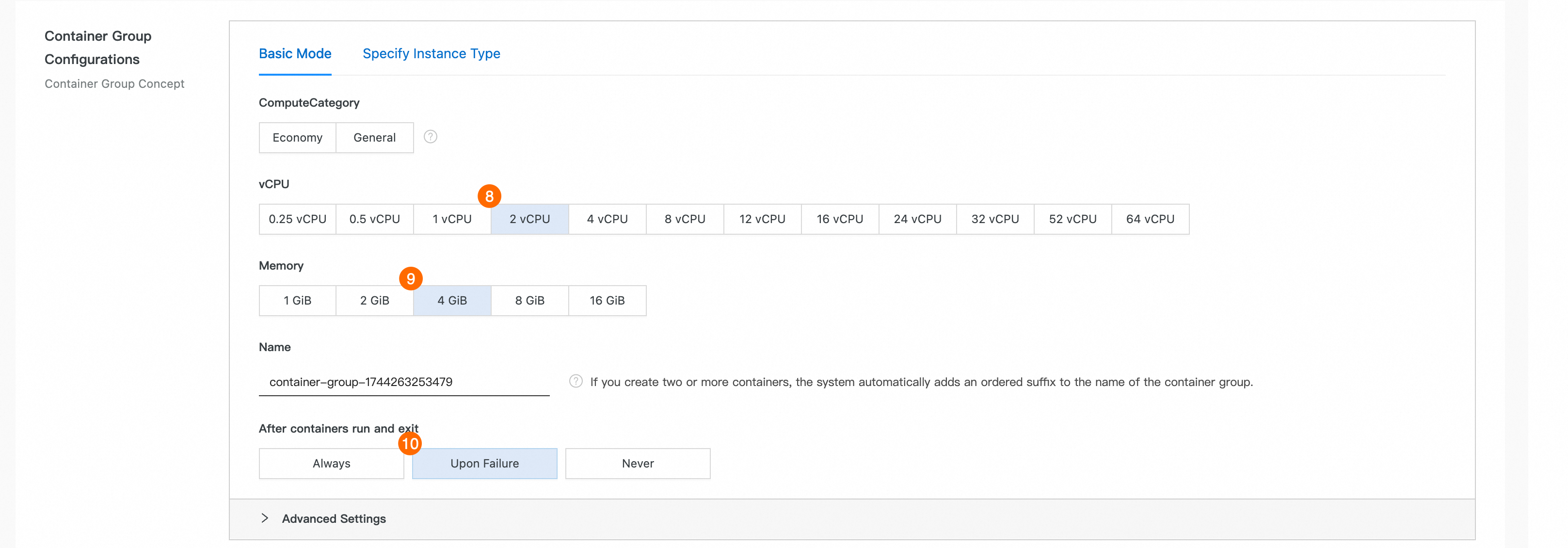
⑧: [CPU]。2 vCPU と入力します。
⑨: [メモリ]: 4 GiB。
⑩: コンテナーの実行と終了後。 [失敗時] を選択します。
詳細設定:
⑪: 高度な構成 を展開します。
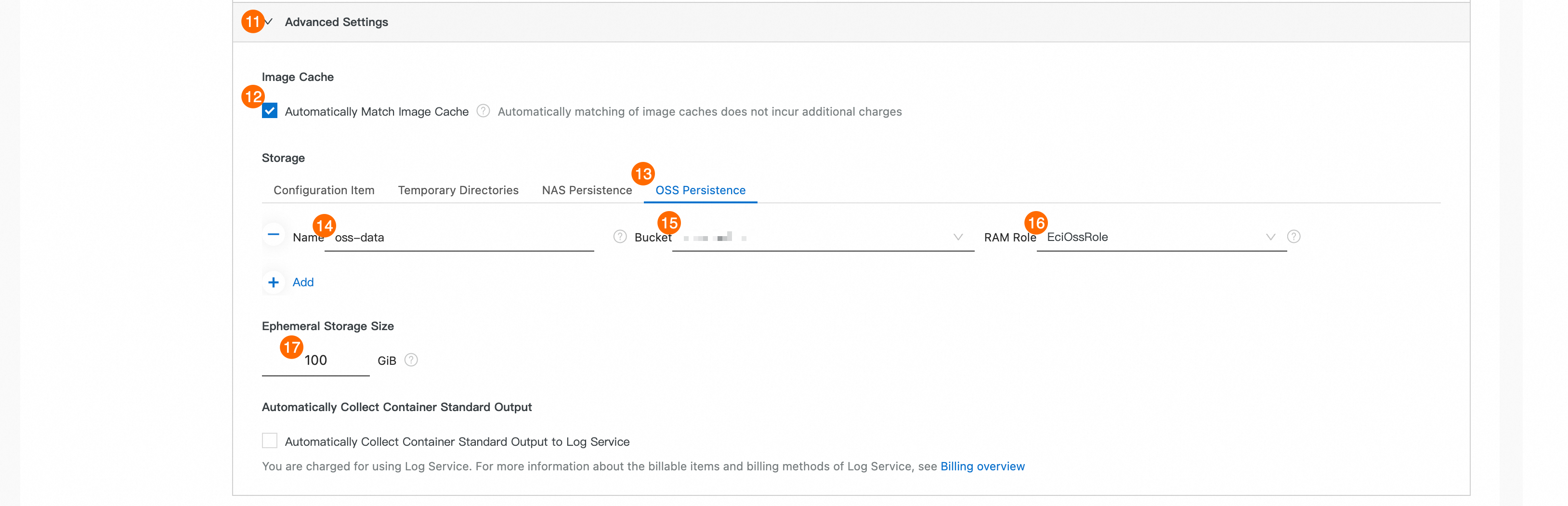
⑫: ミラーキャッシュを自動的に一致させる をオンにします。
⑬: Oss永続ストレージ を選択して追加します。
⑭: [名前].
oss-data.⑮: [Bucket]。ステップ 2 で作成したバケットを選択します。
⑯: [RAM ロール]。ステップ 3 で作成したインスタンス RAM ロールを選択します。
⑰: 一時ストレージサイズ。値を 100 GiB に設定します。
コンテナの設定:
⑱: [イメージ].
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm.Ⲅ:イメージタグ。
0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04。⑳: [Startup Command]。次のコマンドを、図のように対応するフィールドにコピーします。
/bin/bash -c git-lfs clone https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B.git /oss-data/DeepSeek-R1-Distill-Qwen-7Bこのコマンドは、git-lfs を使用して ModelScope コミュニティリポジトリからモデルを
/oss-data/DeepSeek-R1-Distill-Qwen-7Bディレクトリにクローンします。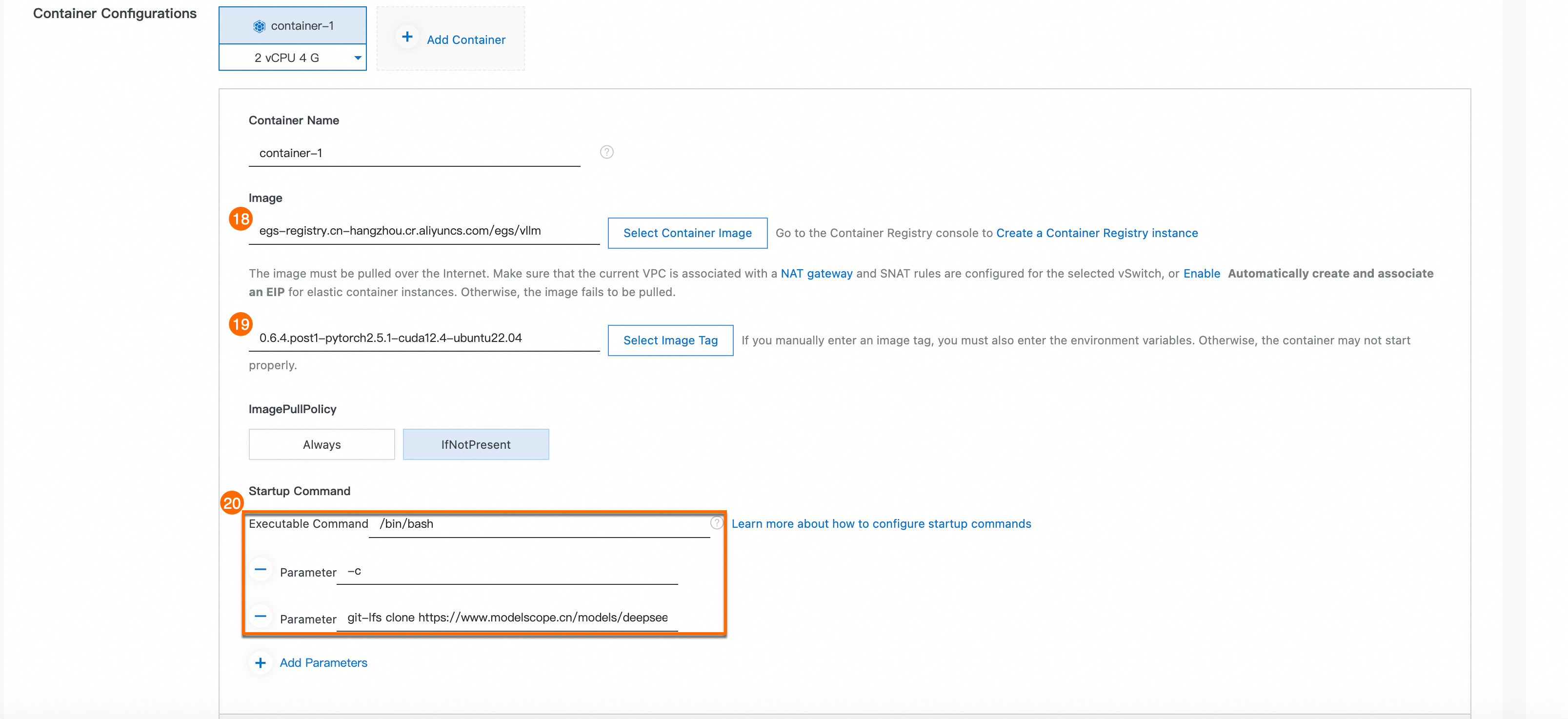
コンテナの詳細設定:
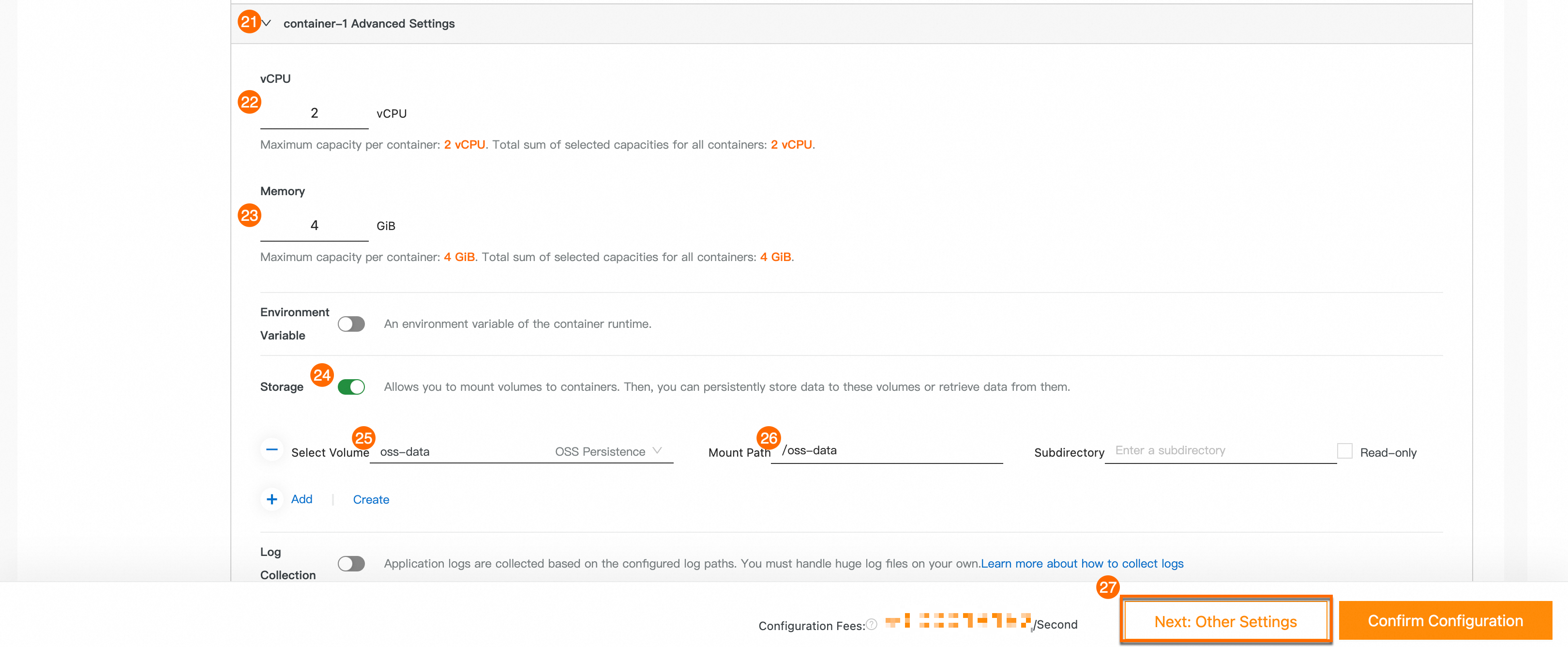
㉑: [Advanced Settings] を展開します。
㉒: [CPU]。2 vCPU と入力します。
㉓: [メモリ]。4 GiB。
㉔: [ストレージ] をオンにし、[追加] でボリュームマウントを追加します。
㉕:
oss-dataを選択します。㉖: [コンテナーのマウントパス]。
/oss-data。㉗: 次: その他の設定 をクリックします。
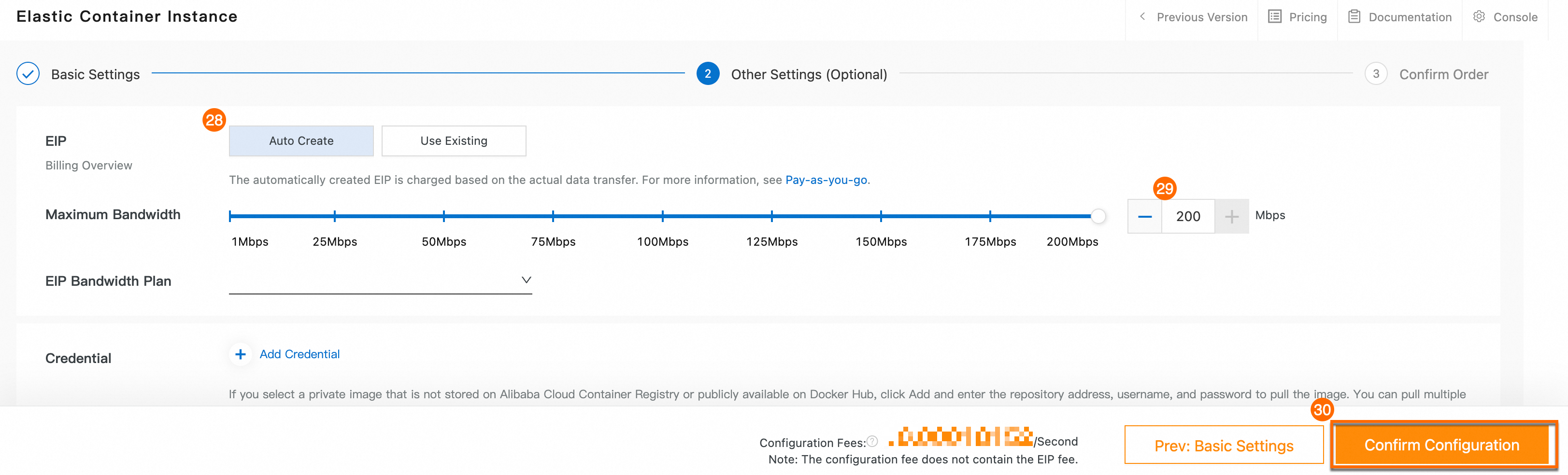
㉘: Elastic IP アドレス: 自動作成 を選択します。
㉙: [最大帯域幅]。 値を 200 Mbit/s に設定します。
㉚: 設定の確認 をクリックし、画面の指示に従って ECI インスタンスの作成を完了します。
ECI インスタンスが作成されると、モデルの重みファイルのダウンロードが自動的に開始されます。ダウンロードの進行中に、ステップ 5 と ステップ 6 に進むことができます。
ダウンロードが完了すると、ECI コンソールで ECI インスタンスのステータスが 正常に実行 に変わります。

Object Storage Service コンソールで、バケット内に
DeepSeek-R1-Distill-Qwen-7Bという名前のフォルダーが生成されます。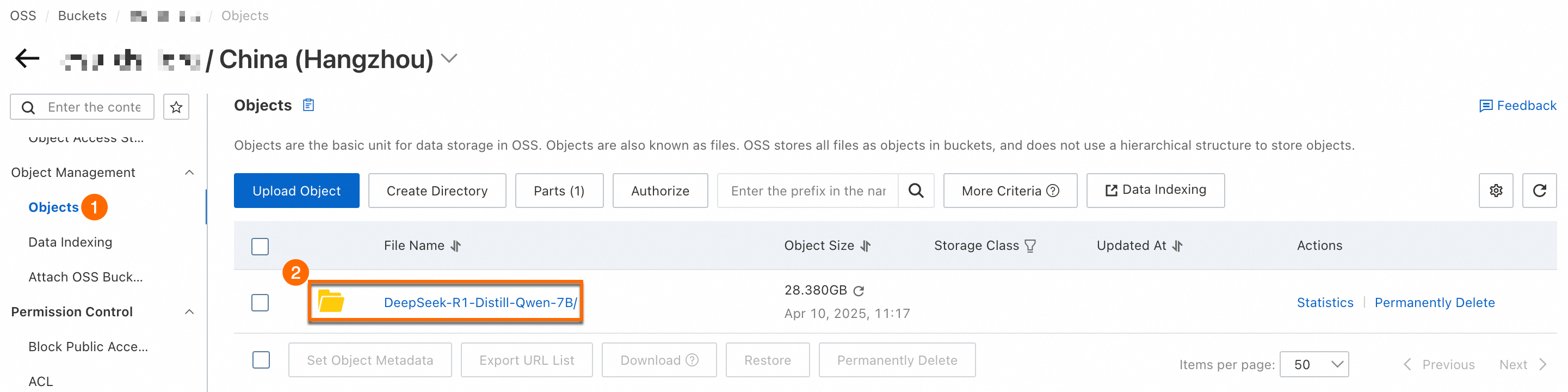
5. Application Load Balancer インスタンスの作成
ECI クラスターを作成する前に、サービスエンドポイントとして機能する Application Load Balancer (ALB) インスタンスを作成します。次の手順に従ってください。
コンソールで、ALB インスタンスを作成します。
①②: [ALB の作成] をクリックします。
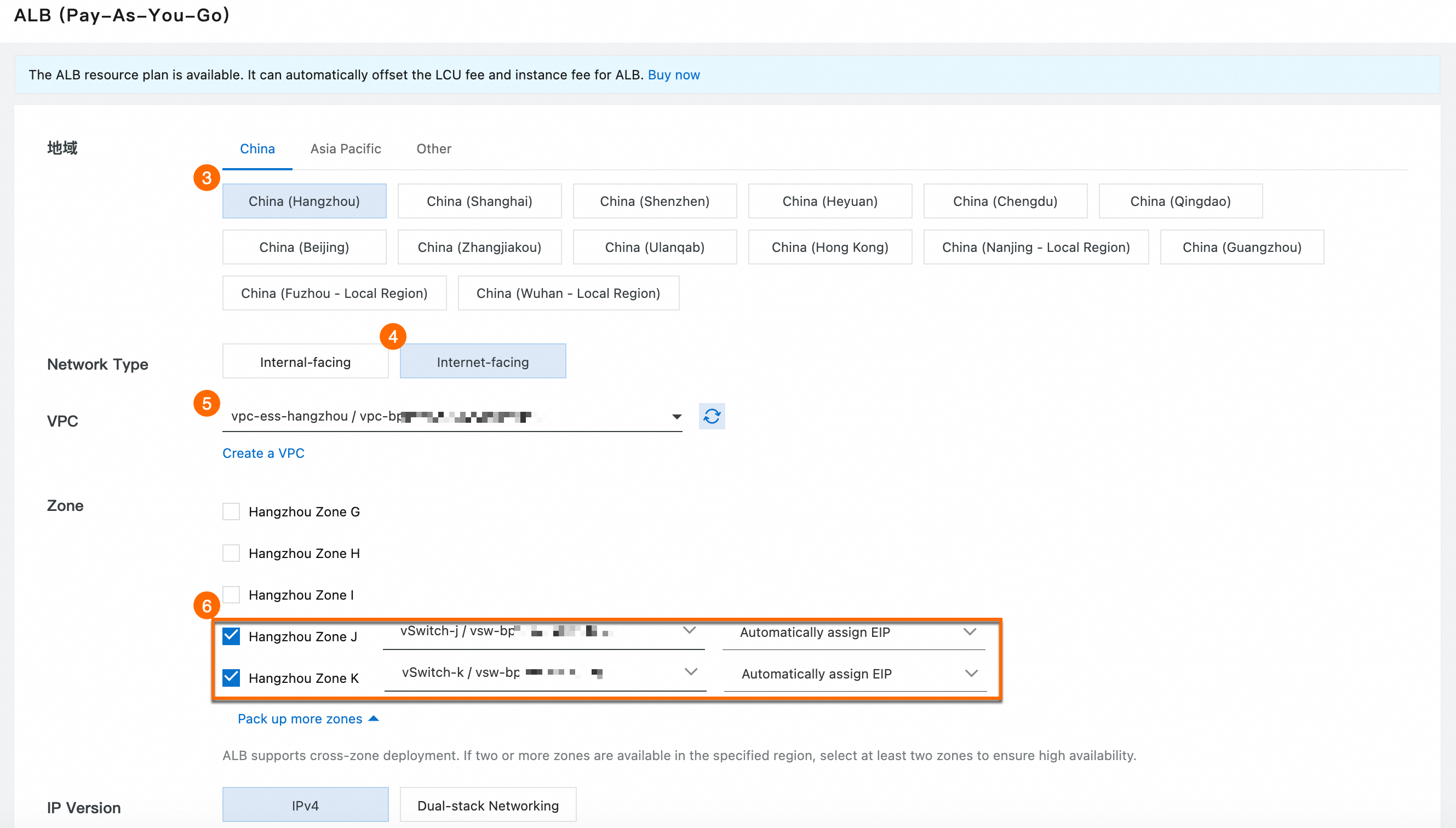
③: [リージョン]。ステップ 1 で作成した VPC と一致するように、中国東部1 (杭州) を選択します。
④: インスタンスネットワークタイプでは、インターネット経由でサービスを提供するために外部を選択します。
⑤: [VPC]。ステップ 1 で作成した VPC を選択します。
⑥: ゾーン と vSwitch:ステップ 1 で作成した vSwitch を選択します。
⑦: [インスタンス名]。
alb-eci-deepseek-7B。⑧: 今すぐ購入 をクリックし、画面の指示に従って ALB インスタンスの作成を完了します。
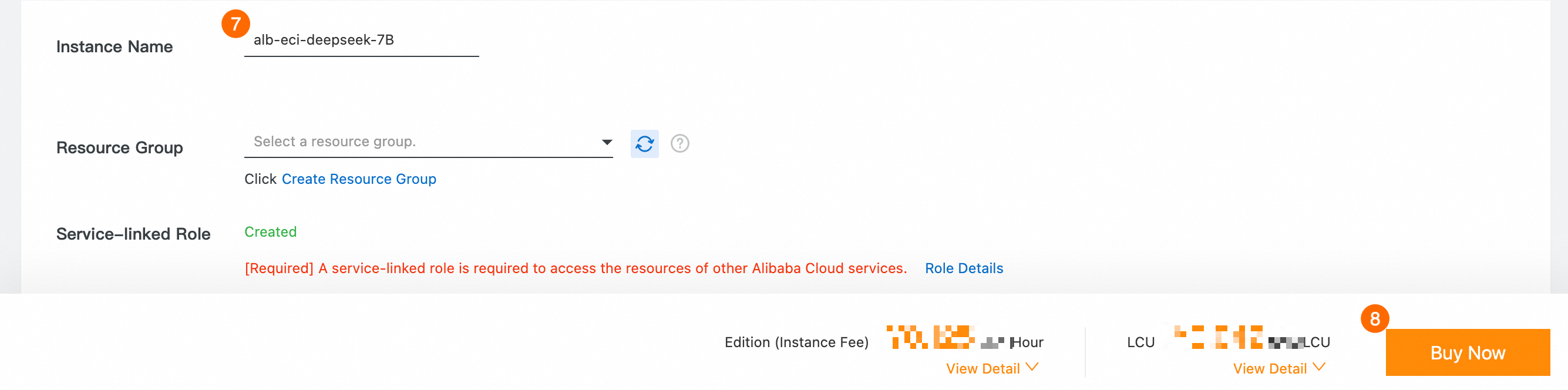
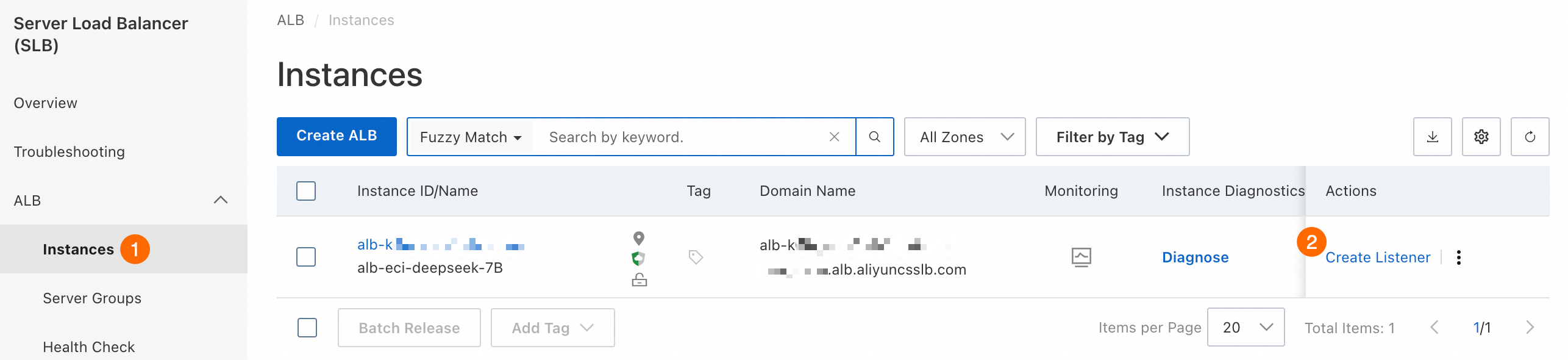
コンソールで、ALB インスタンスのリスナーとバックエンドサーバーグループを作成します。
①②: 作成した ALB インスタンスを見つけ、操作 列で リスナーの作成 をクリックします。
ALB インスタンスが見つからない場合は、ページの左上隅で別のリージョンに切り替えてください。
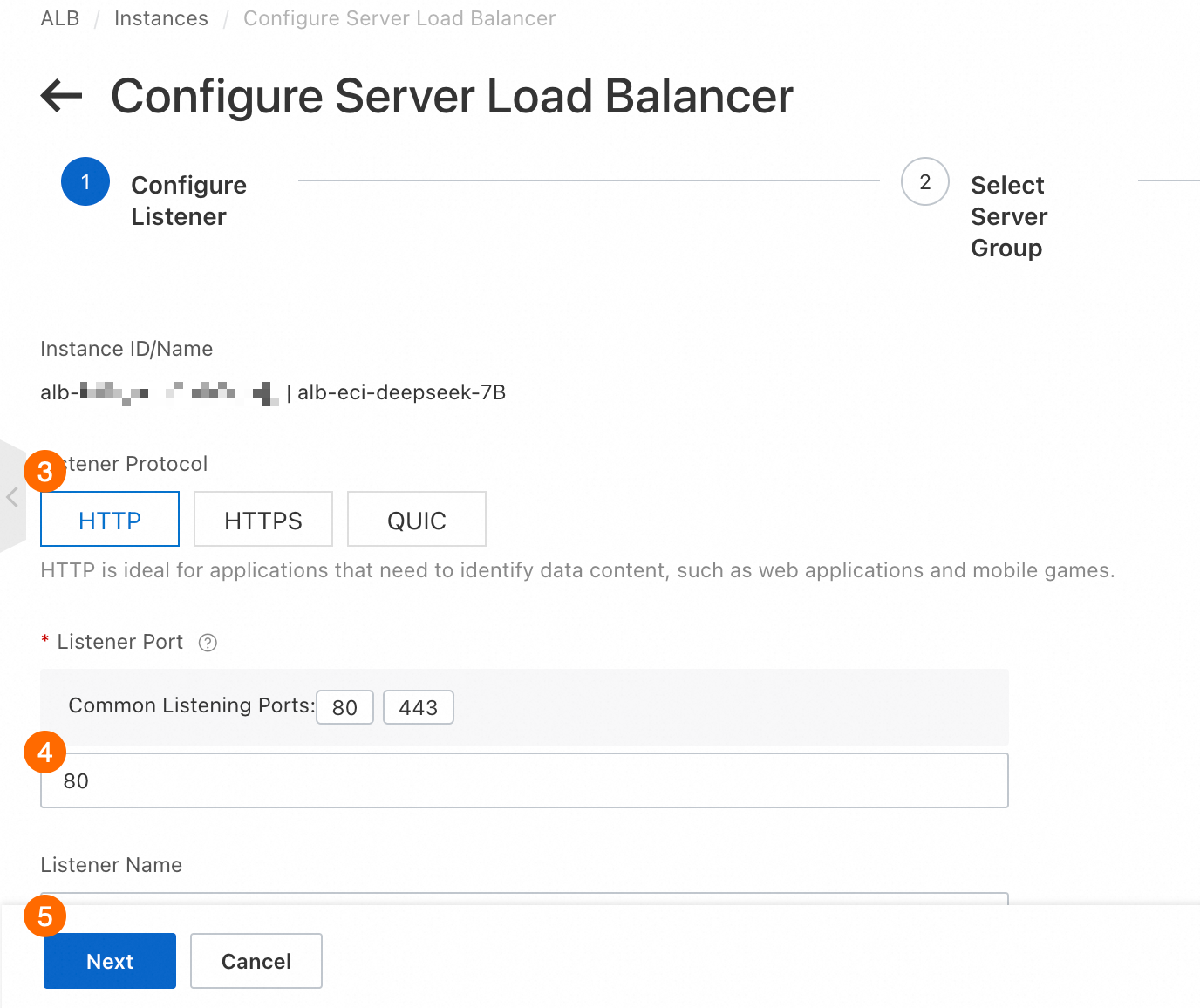
③: プロトコルとして HTTP を選択します。
④: リスナーポートを 80 に設定します。
⑤: 次へ をクリックします。
⑥: サーバーグループの作成 をクリックします。
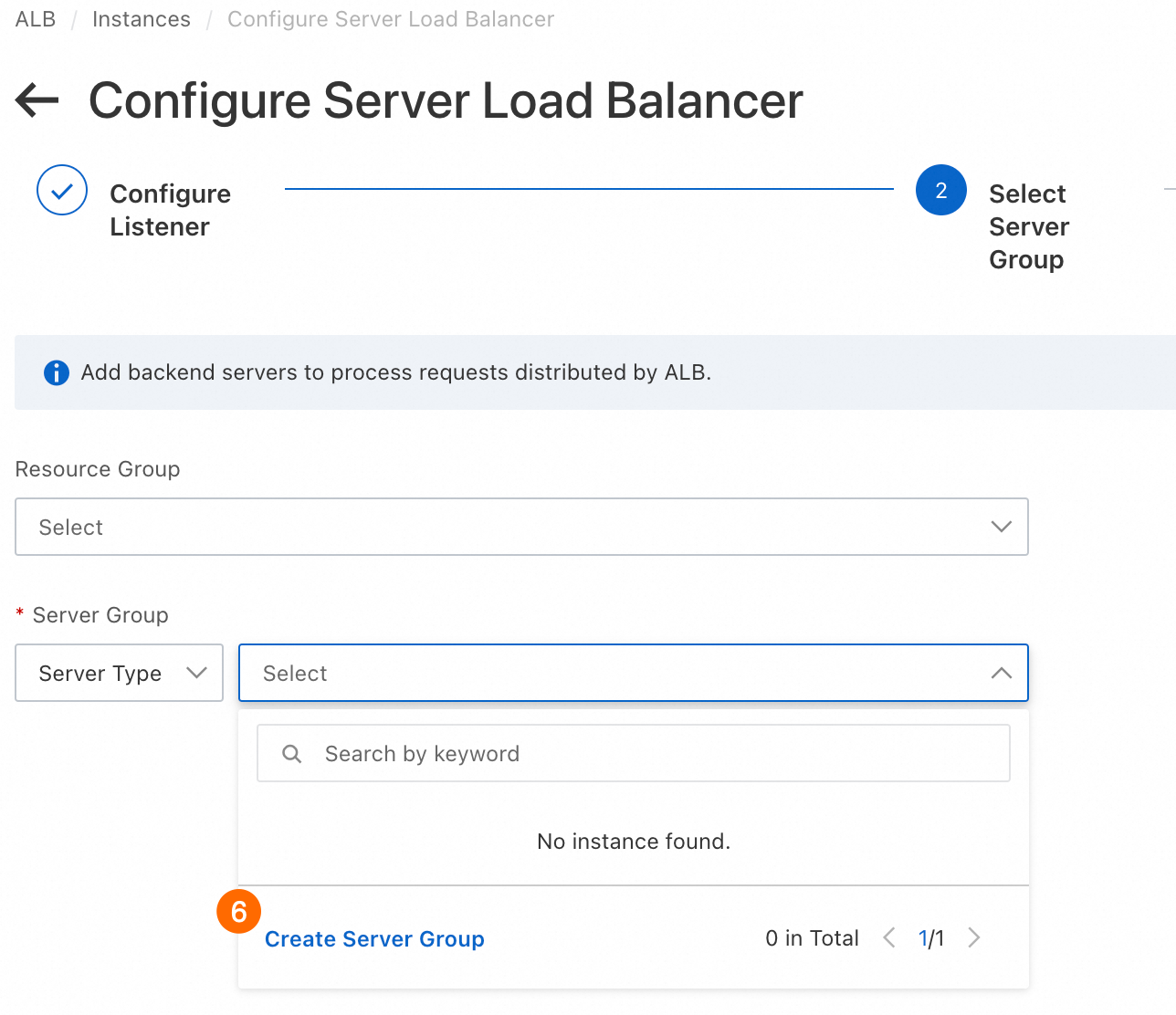
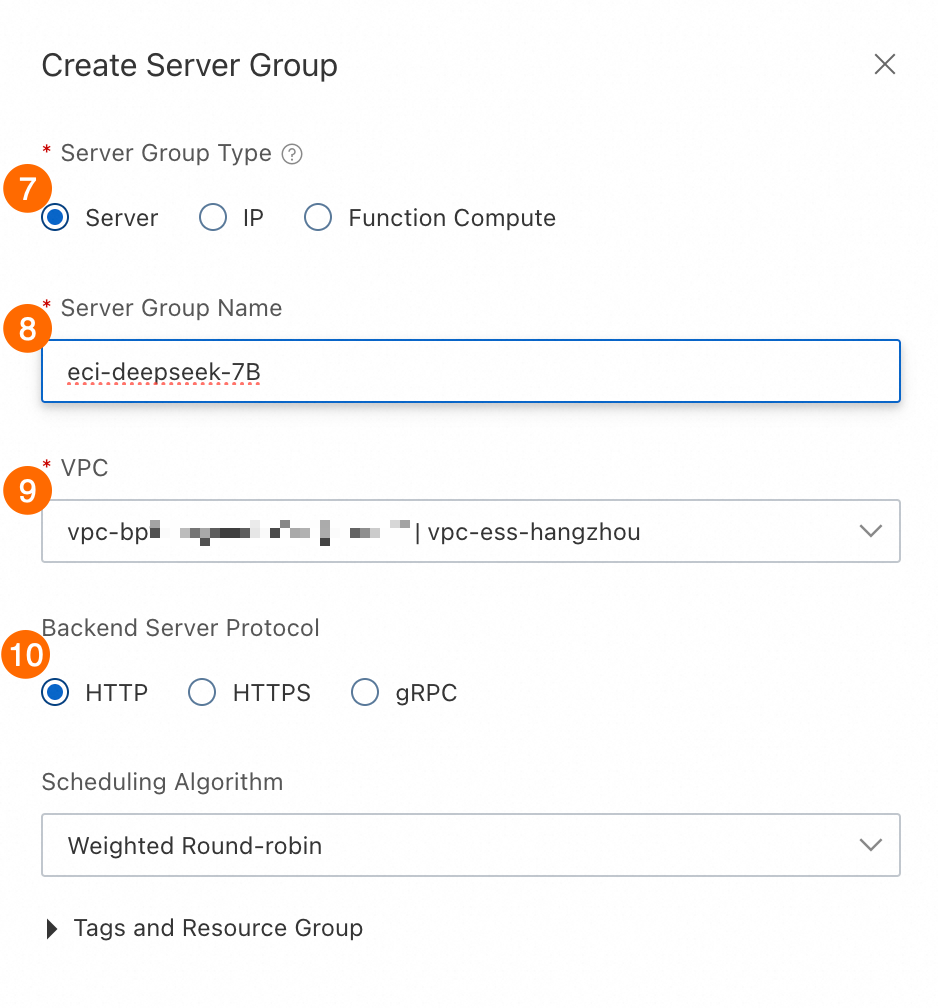
⑦: [サーバーグループのタイプ]。 [サーバー] を選択します。
⑧: サーバーグループ名.
eci-deepseek-7B.⑨: [VPC]。 ステップ 1 で作成した VPC を選択します。 このパラメーターは自動的に選択されます。
⑩: バックエンドサーバープロトコル:HTTP を選択します。
⑪⑫: ヘルスチェック を有効にします。
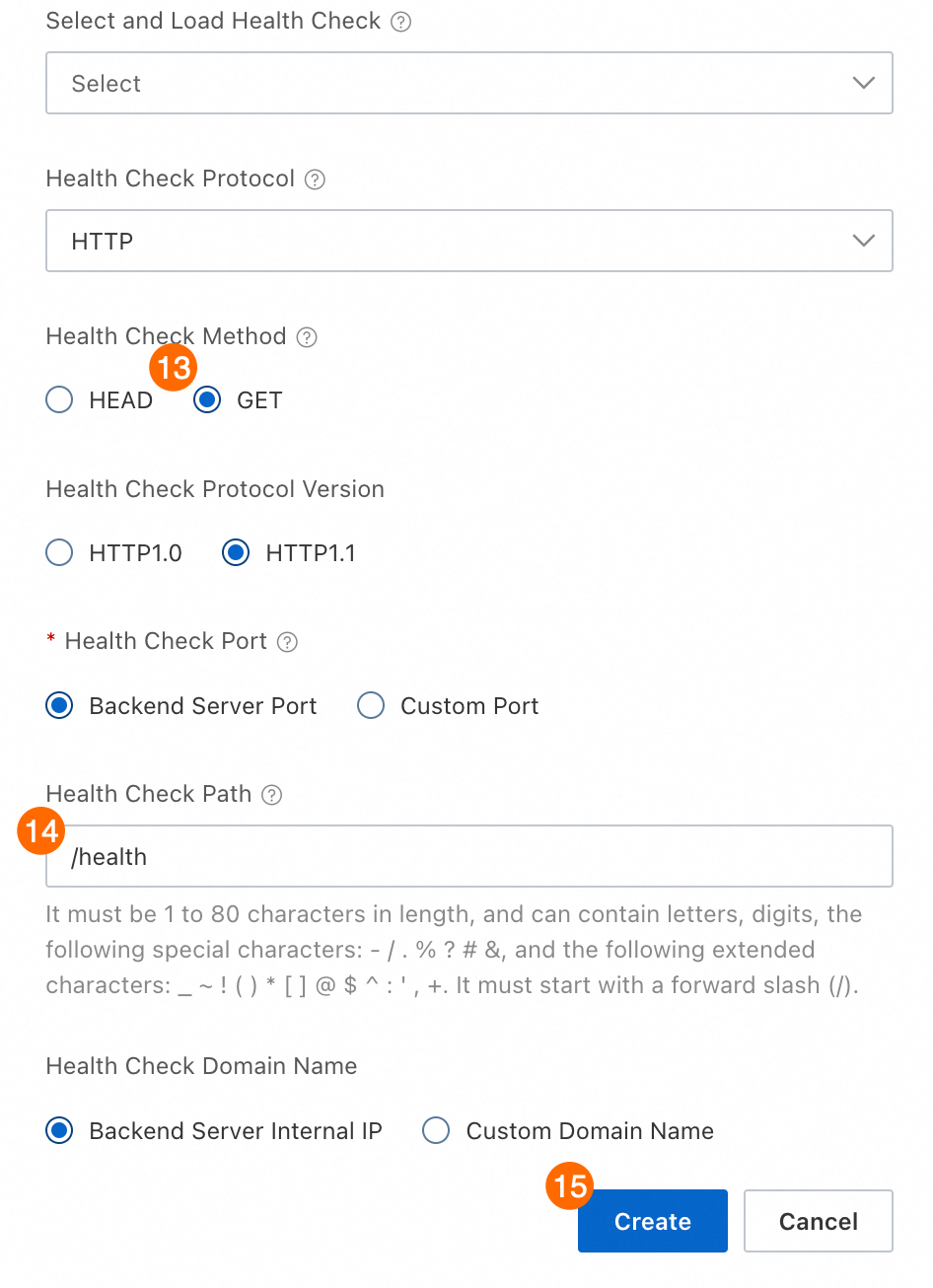
⑬: ヘルスチェックメソッド:GET を選択します。
⑭: ヘルスチェックパス:値を
/healthに設定します。推論サービスの起動後、ALB は/healthパスを使用してサービスのステータスを判断します。⑮⑯⑰: 作成 をクリックし、次へ をクリックし、次に 送信 をクリックします。作成が完了するまで待ちます。



6. スケーリンググループの作成
スケーリンググループを作成し、ALB インスタンスに関連付けます。このグループは、ECI インスタンスを自動的に作成および管理し、負荷分散のために ALB のバックエンドサーバーグループに追加します。
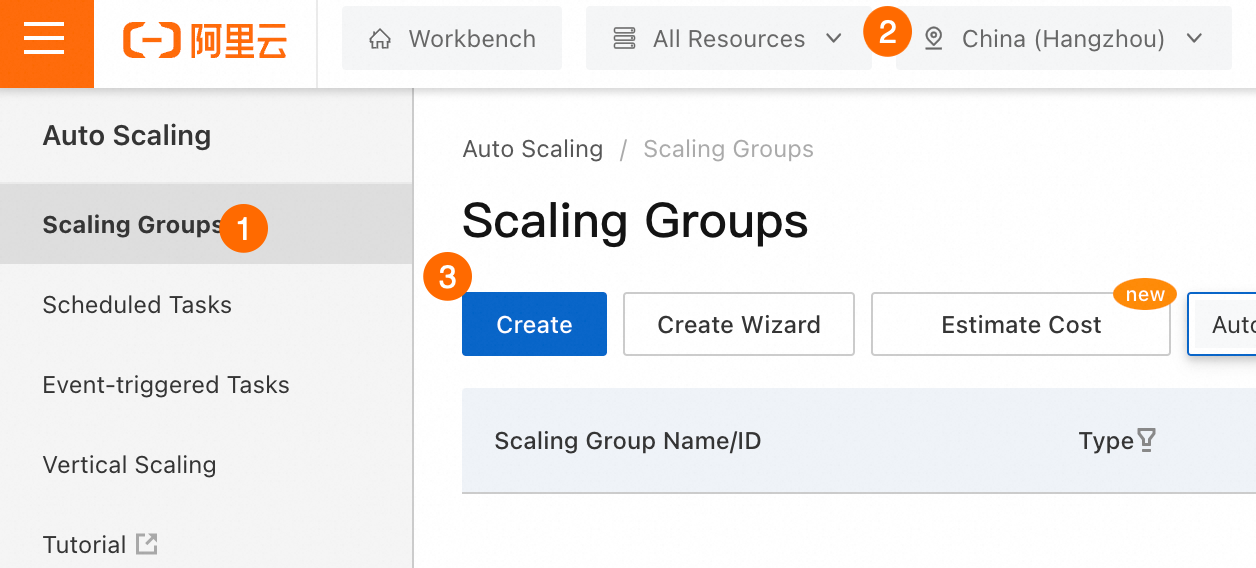
Auto Scaling コンソールで、スケーリンググループを作成し、ALB インスタンスに関連付けます。
①②③: スケーリンググループの作成 をクリックします。
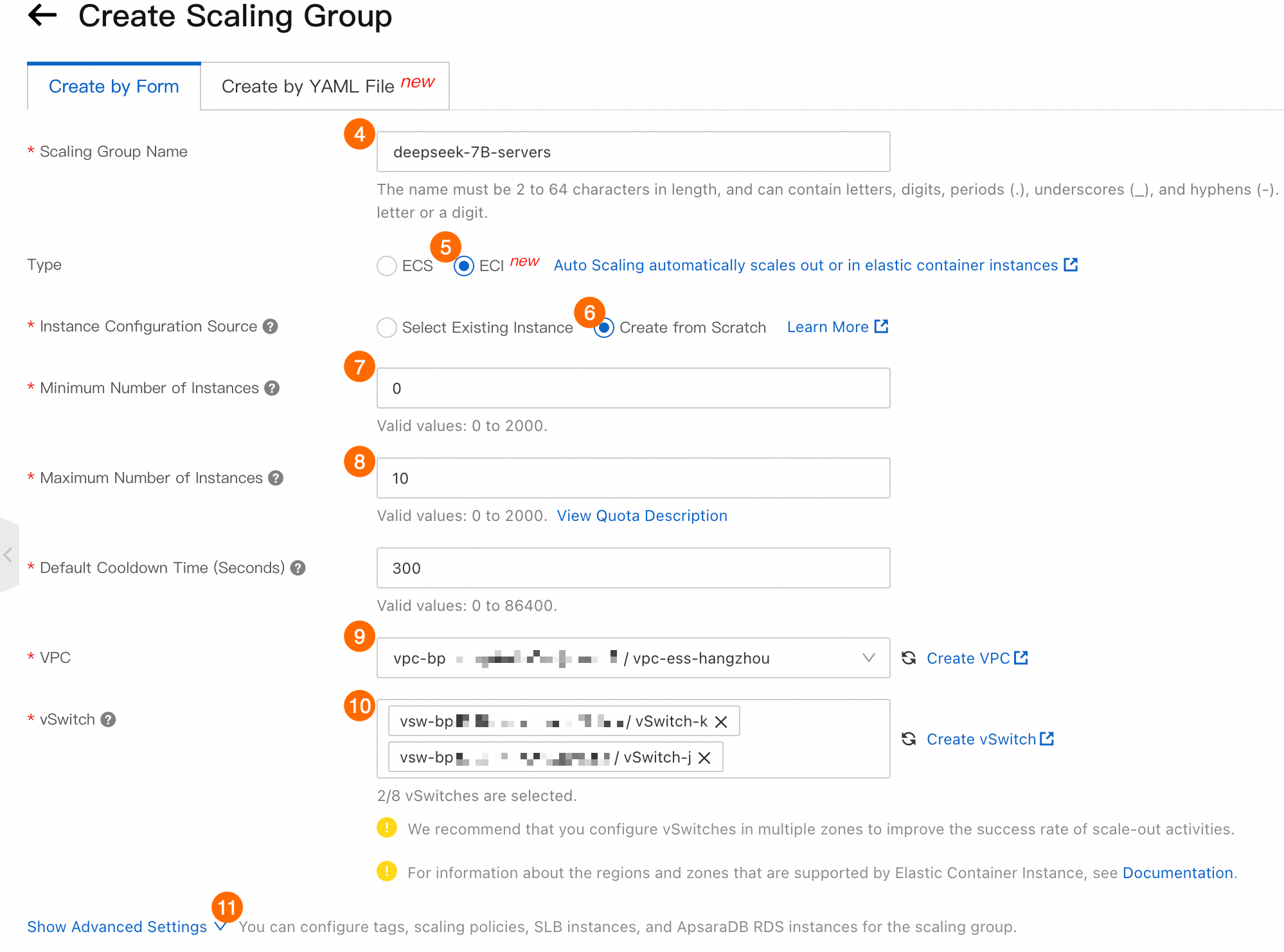
④: [スケーリンググループ名]。
deepseek-7B-servers。⑤: [タイプ]。ECI を選択します。
⑥: [インスタンス設定ソース]: 新規作成 を選択します。
⑦: [最小インスタンス数]。スケーリンググループ内のインスタンスの最小数です。このパラメーターを 0 に設定します。
⑧: [最大インスタンス数]。このパラメーターを 10 に設定します。スケーリンググループ内のインスタンスの最大数です。
⑨: [VPC]。ステップ 1 で作成した VPC を選択します。
⑩: [vSwitch]。ステップ 1 で作成したすべての vSwitch を選択します。
⑪: 詳細設定を表示する をクリックします。
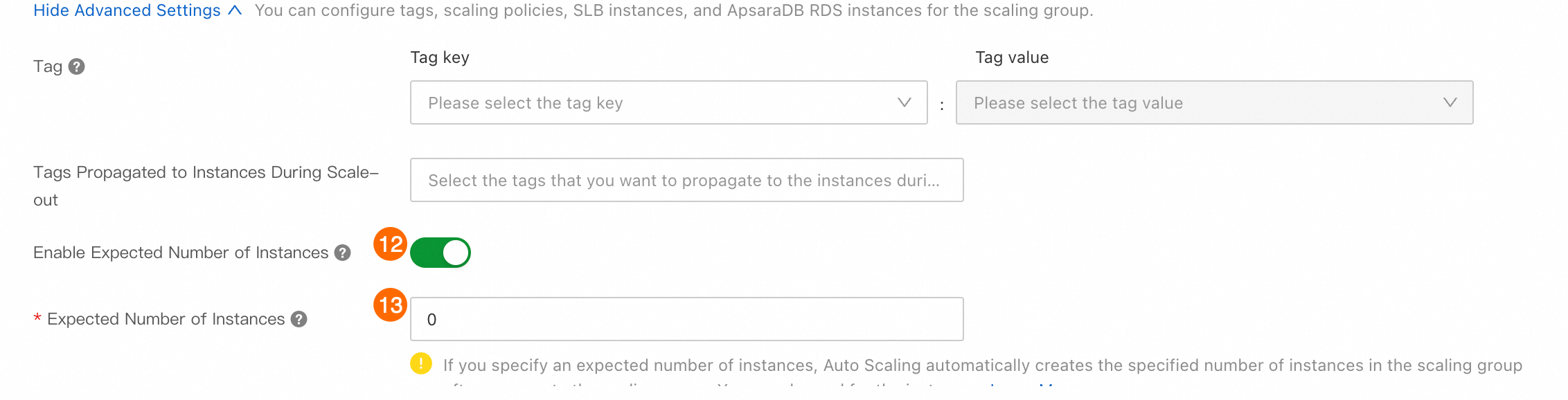
詳細設定:
⑫⑬: 希望インスタンス数 を有効にし、値を 0 に設定します。これにより、空のスケーリンググループが作成されます。
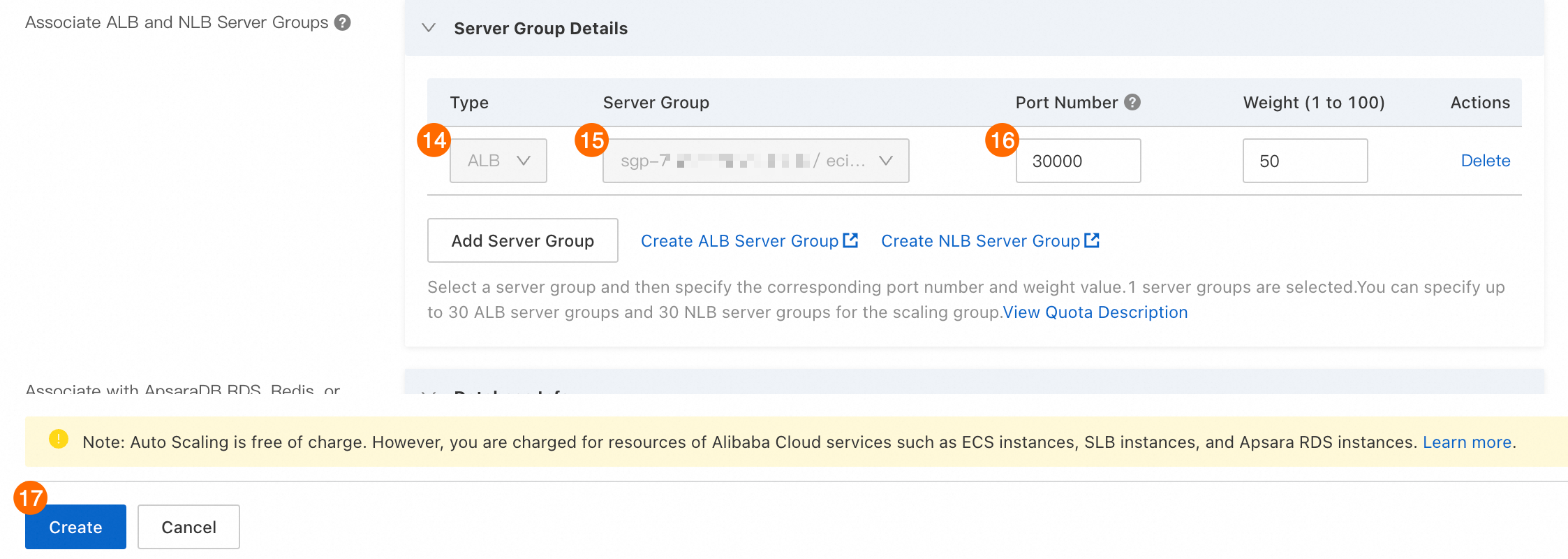
⑭: サーバーグループの追加 をクリックし、タイプ を ALB に設定します。
⑮: [サーバーグループ]。ステップ 5 で作成したサーバーグループを選択します。
⑯: [ポート]:
30000を選択します。 ECI インスタンスにデプロイされた推論サービスは、このポートを使用してサービスを提供します。⑰: 作成 をクリックします。スケーリンググループが作成されるまで待ちます。その後、プロンプトに従ってスケーリング設定を作成できます。
Auto Scaling コンソールで、スケーリング設定を作成します。
スケーリング設定は、スケールアウトイベント中にスケーリンググループが新しいインスタンスを作成する際に使用するテンプレートです。手順は次のとおりです。
①②③: 作成したスケーリンググループを見つけ、その ID をクリックして詳細ページに移動します。
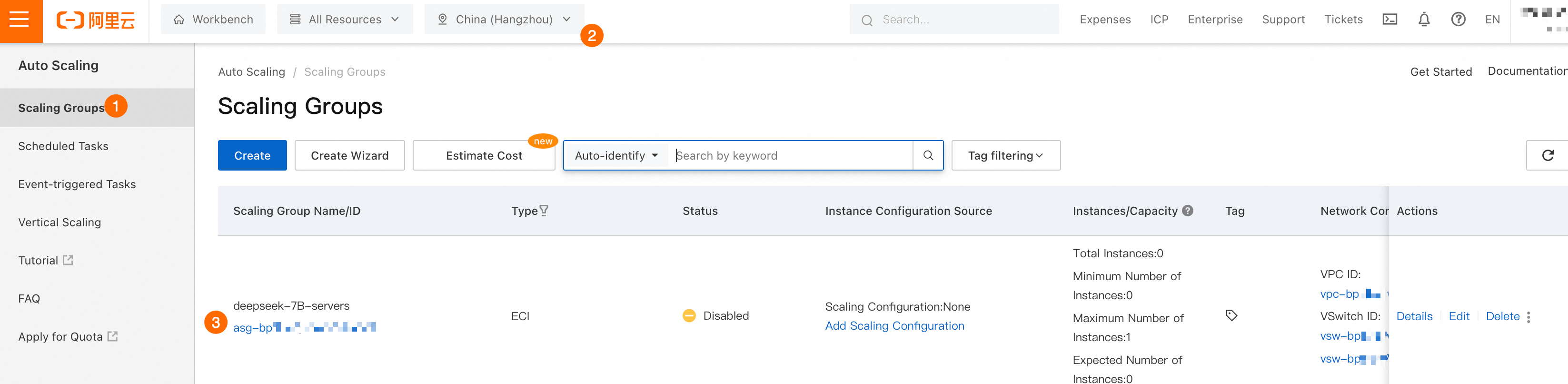
④⑤⑥: をクリックします。
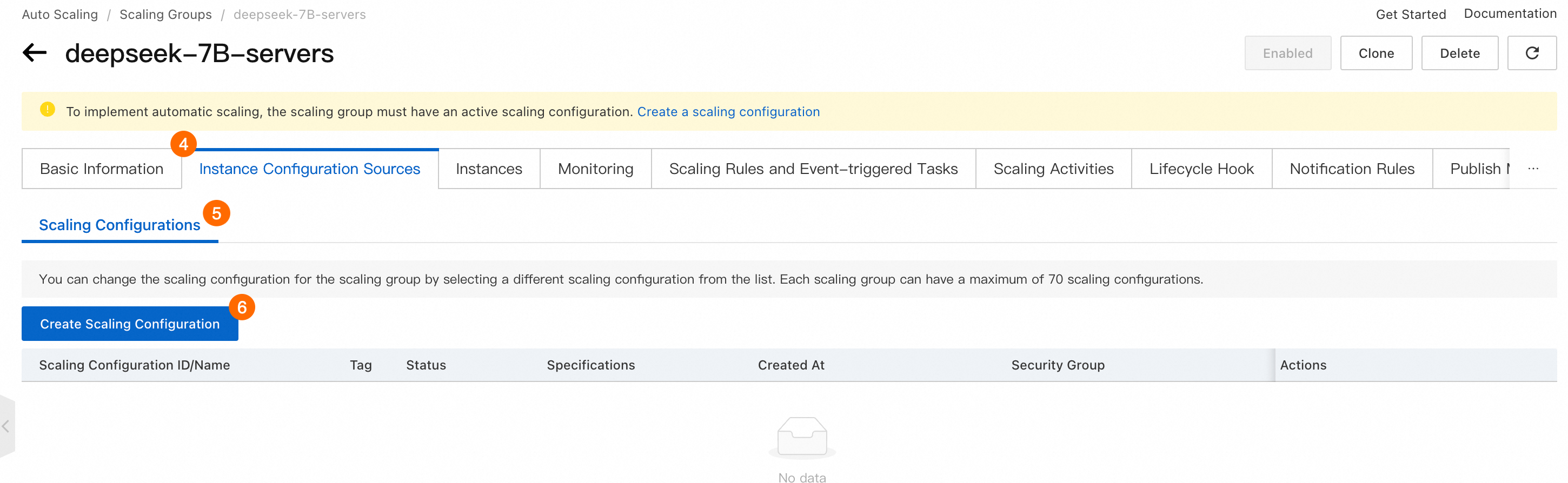
⑦: [支払いモード]。 従量課金 を選択します。
⑧: セキュリティグループ を選択します。
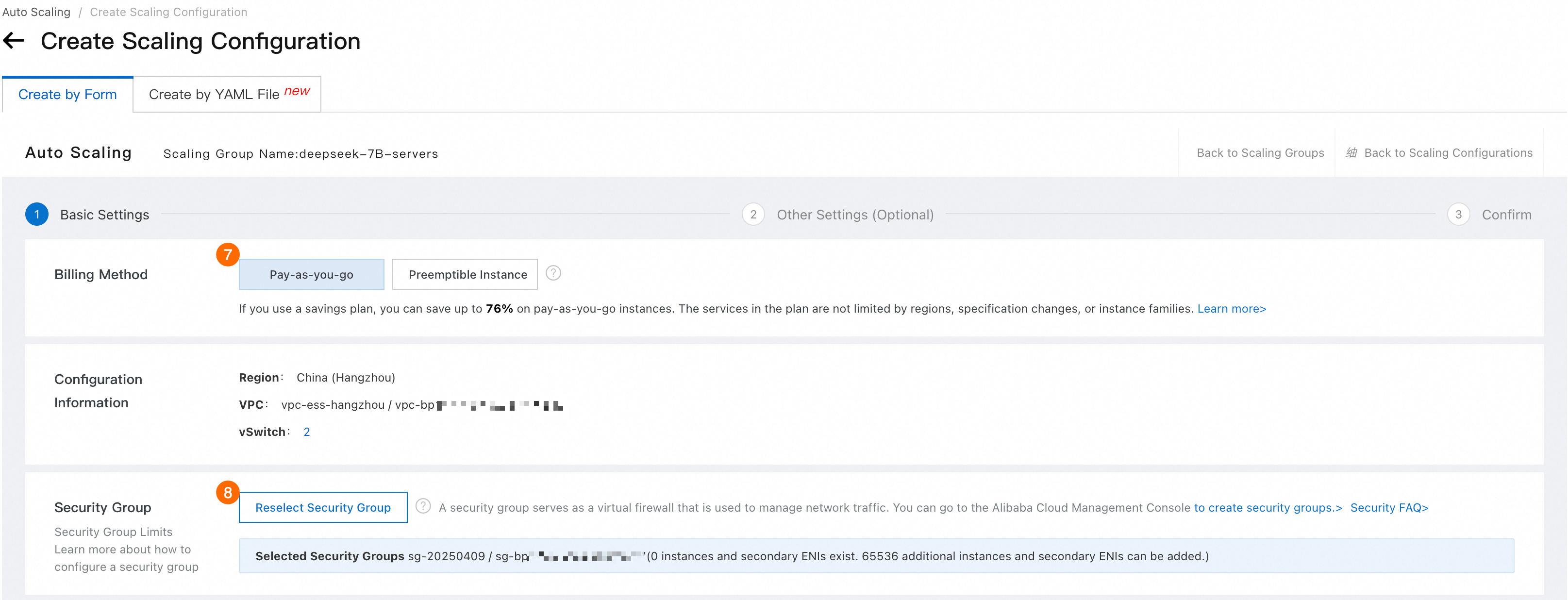
コンテナーグループの設定:
⑨: タイプの指定 を選択します。
⑩: [インスタンスタイプ]。
ecs.gn7i-c8g1.2xlarge。⑪: ミラーキャッシュを自動的に一致させる を選択します。
⑫: 高度な構成 を展開します。
⑬⑭⑮⑯: Oss永続ストレージ を選択し、[バケット] とインスタンスの RAM ロール を設定します。
⑰: [一時ストレージサイズ]:100 GiB。
⑱: [GPU ドライバのバージョン ]。
tesla=550。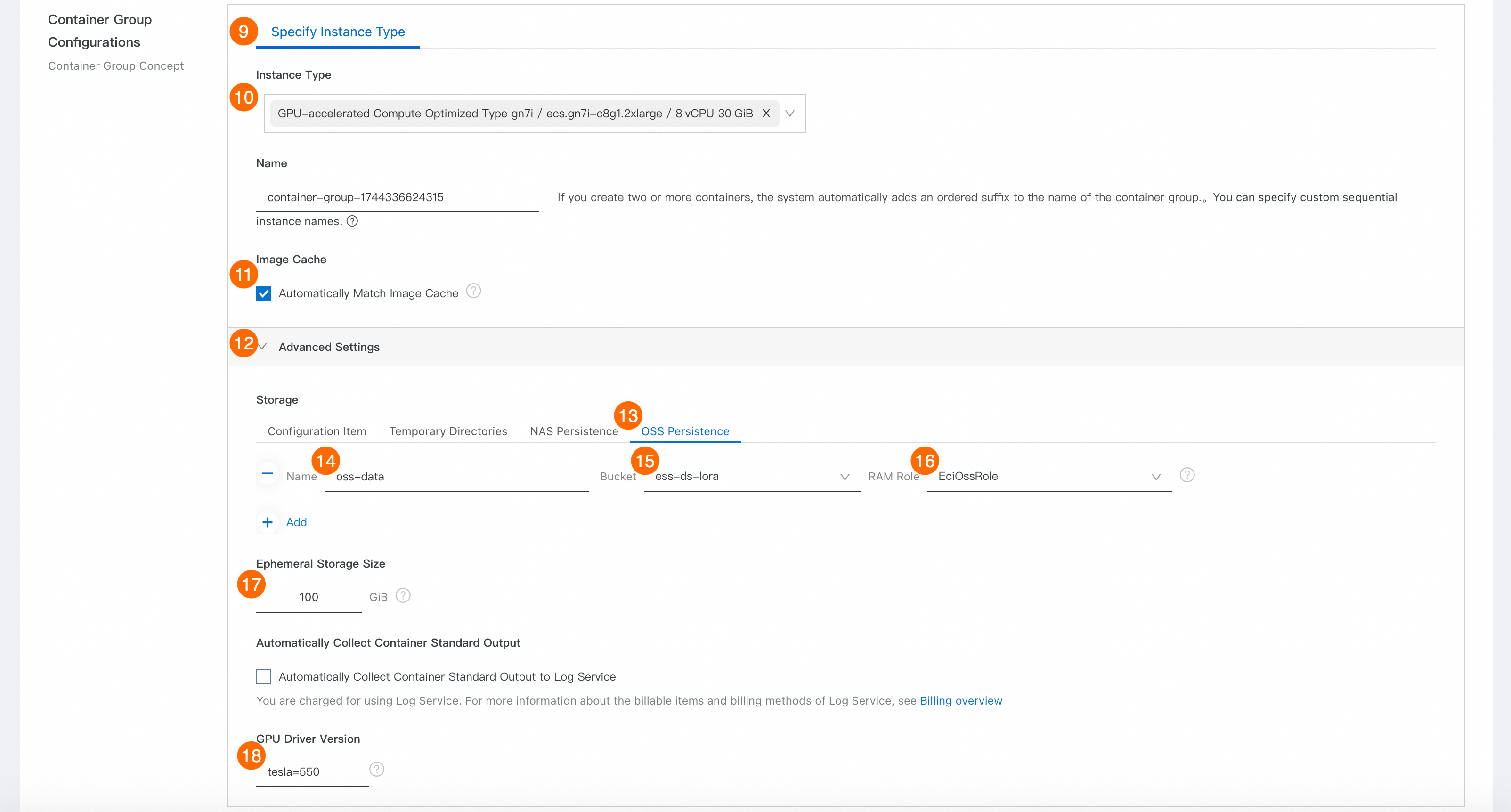
コンテナの設定:
Ⲅ: [イメージ]。
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm。⑳: イメージタグ。
0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04。㉑: [起動コマンド]。図に示すように、次のコマンドを対応するフィールドにコピーします。
/bin/bash -c vllm serve /oss-data/DeepSeek-R1-Distill-Qwen-7B --port 30000 --served-model-name DeepSeek-R1-Distill-Qwen-7B --tensor-parallel-size 1 --max-model-len=16384 --enforce-eager --dtype=half --api-key api-key-example-abc123このコマンドは、OSS からモデルの重みファイルを読み取り、ポート
30000で推論サービスを起動します。API キーはapi-key-example-abc123に設定されます。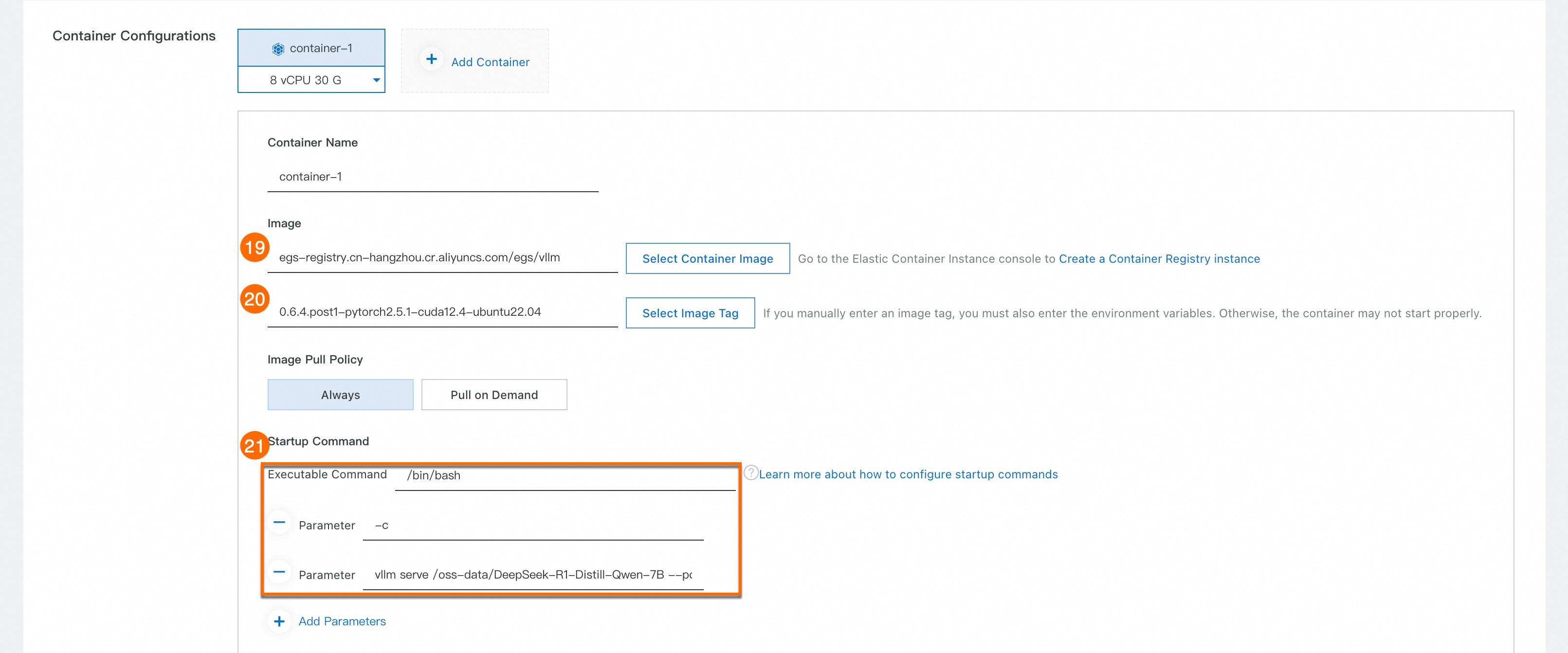
㉒: [container-1 の詳細設定] を展開します。
㉓: [CPU] を 8 vCPU に設定します。
㉔: メモリ。30 GiB に設定します。
㉕: [GPU] を 1 に設定します。
㉖㉗: [ストレージ] をオンにし、[追加] をクリックします。
㉘: [マウントパス] に
/oss-dataと入力します。㉙: 次: その他の設定 をクリックします。
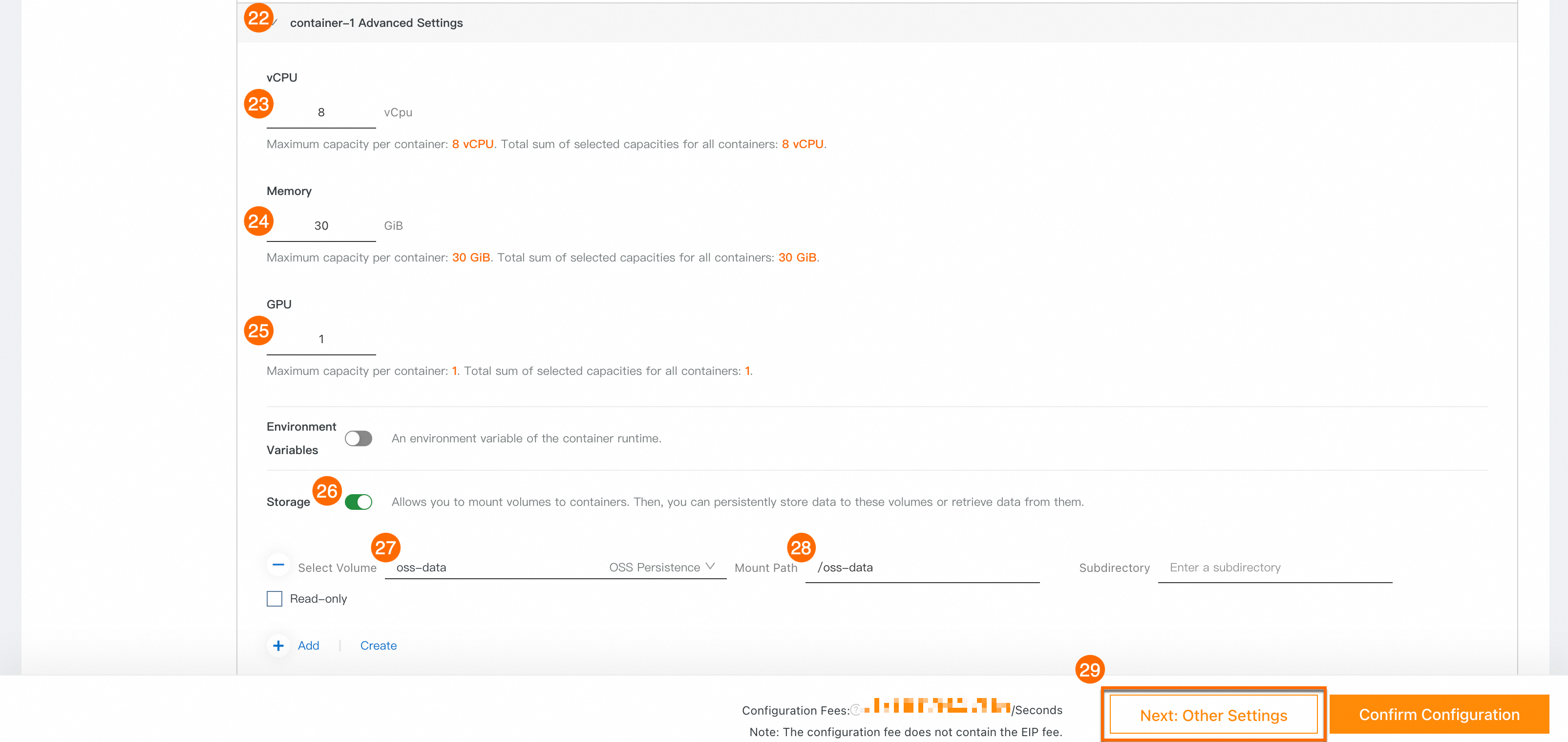
㉚: Elastic IP アドレス。 自動作成 を選択します。
㉛: [最大帯域幅] に 200 Mbit/s と入力します。
㉜: 設定の確認 をクリックし、指示に従ってスケーリング構成の作成を完了します。
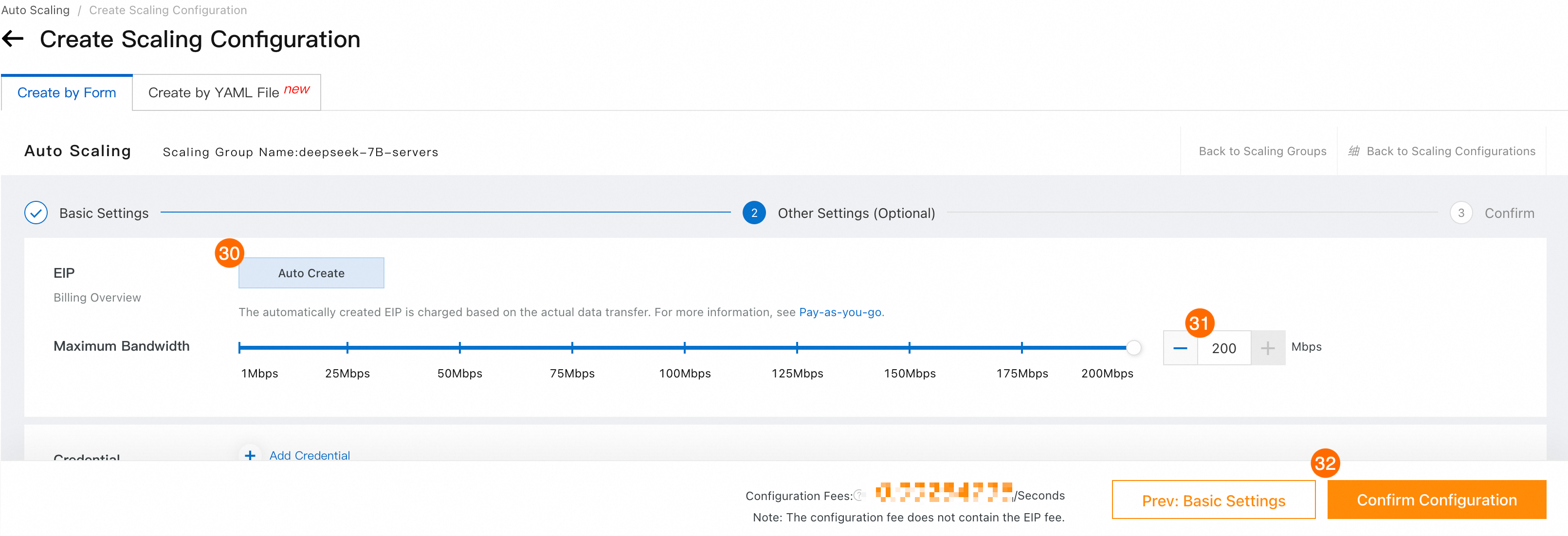
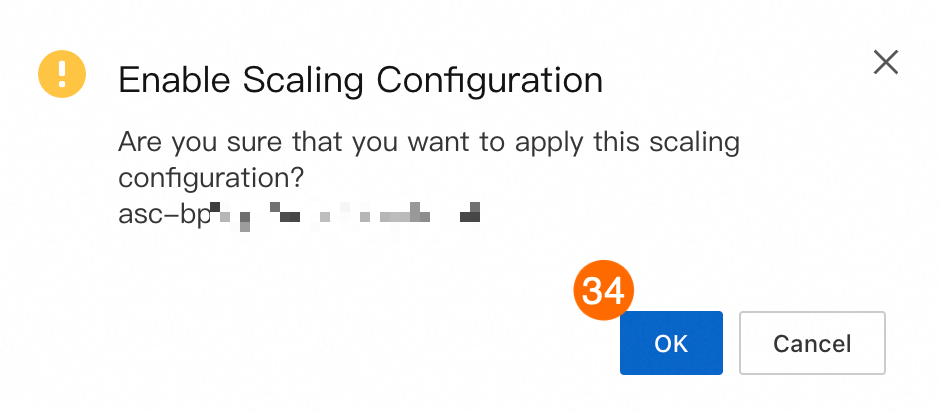
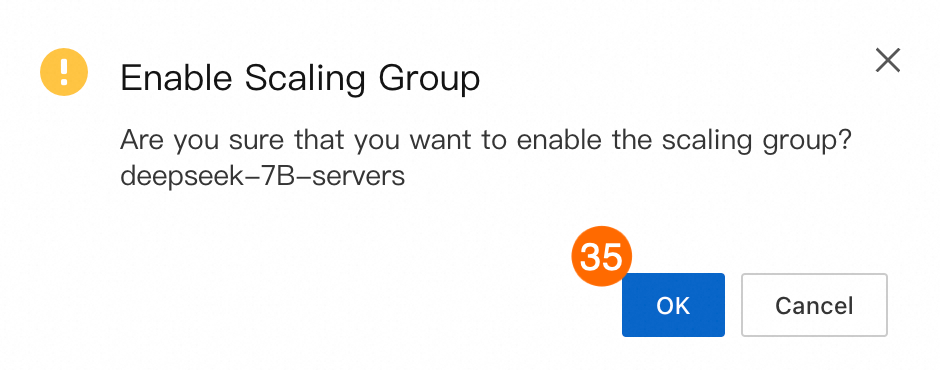
㉝㉞㉟: プロンプトに従って、スケーリング設定を有効にし、スケーリンググループを起動します。

7. サービスの起動
続行する前に、ステップ 4 のモデルの重みファイルが完全にダウンロードされていることを確認してください。
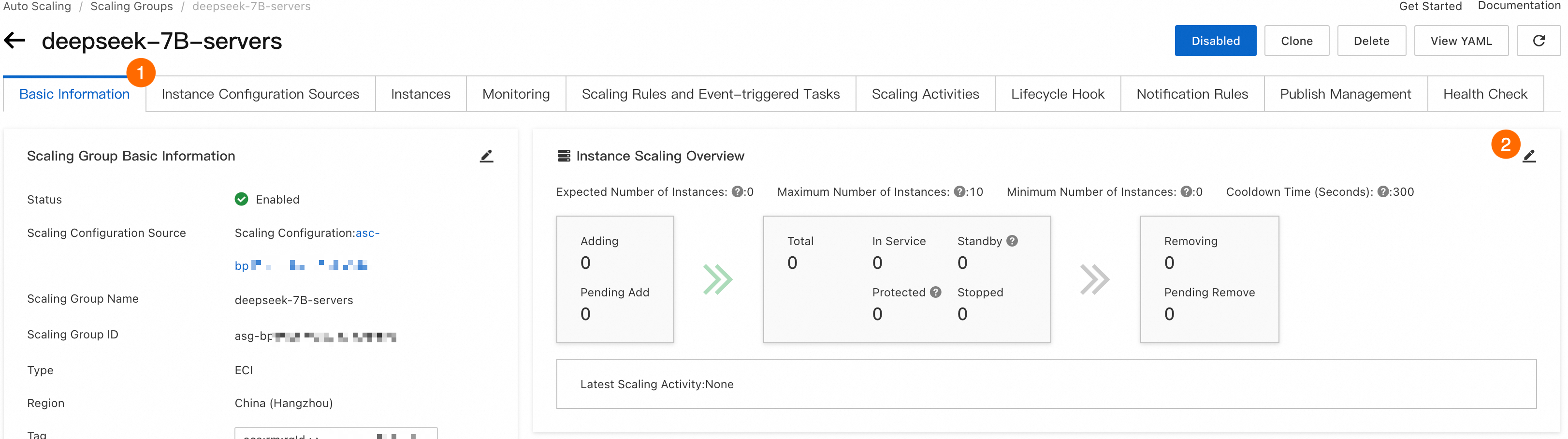
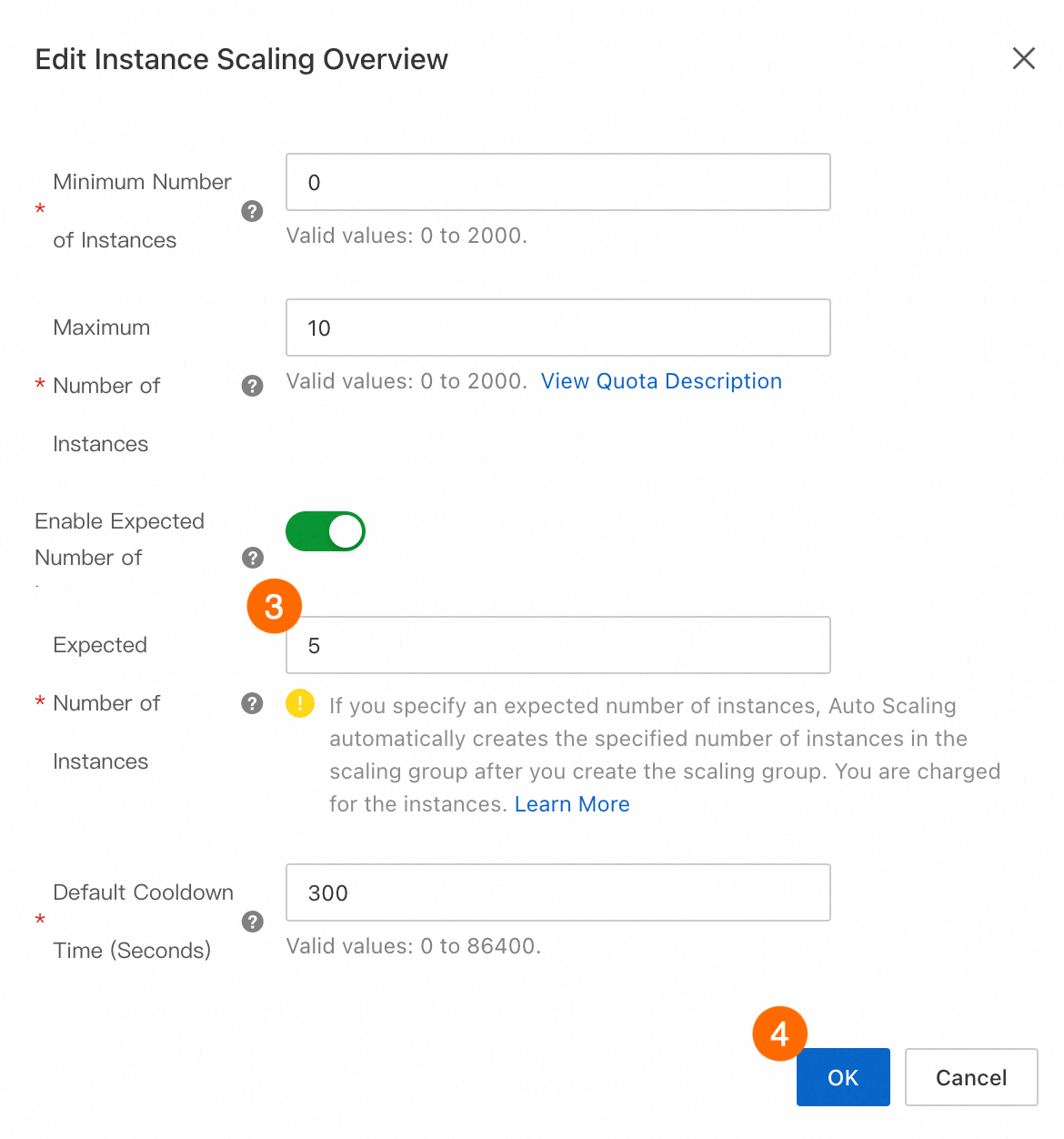
前の手順を完了した後、スケーリンググループの予想インスタンス数を調整して、スケールアウトイベントをトリガーします。この例では、5 つの ECI インスタンスにスケールアウトします。以下の図は、手順を示しています。
期待されるインスタンス数を調整した後、新しいインスタンスが作成されるまでには遅延があります。進行状況は、スケーリングアクティビティ タブで監視できます。
|
|
次のステップ
Dify 統合
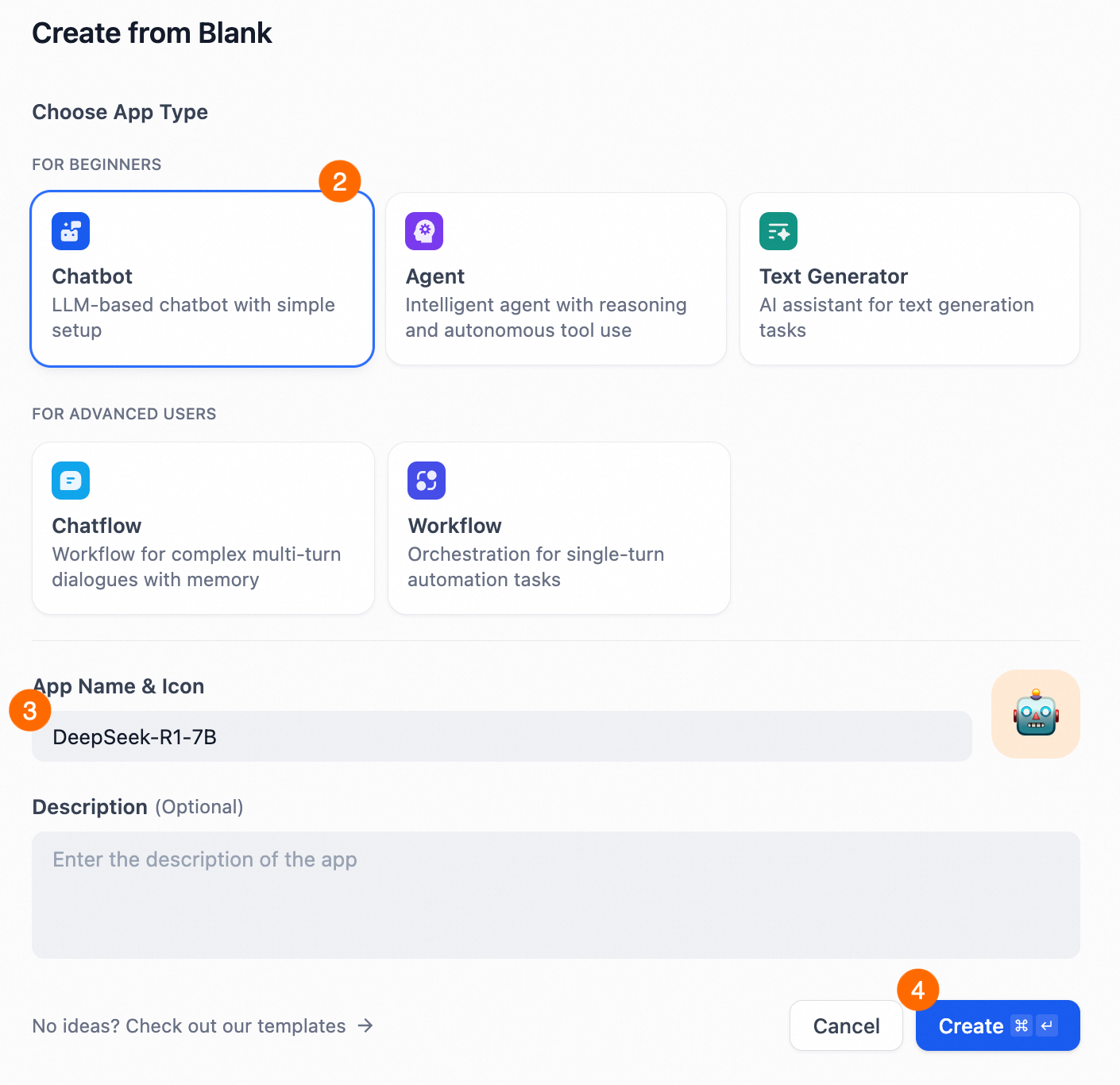
Dify にログインします。
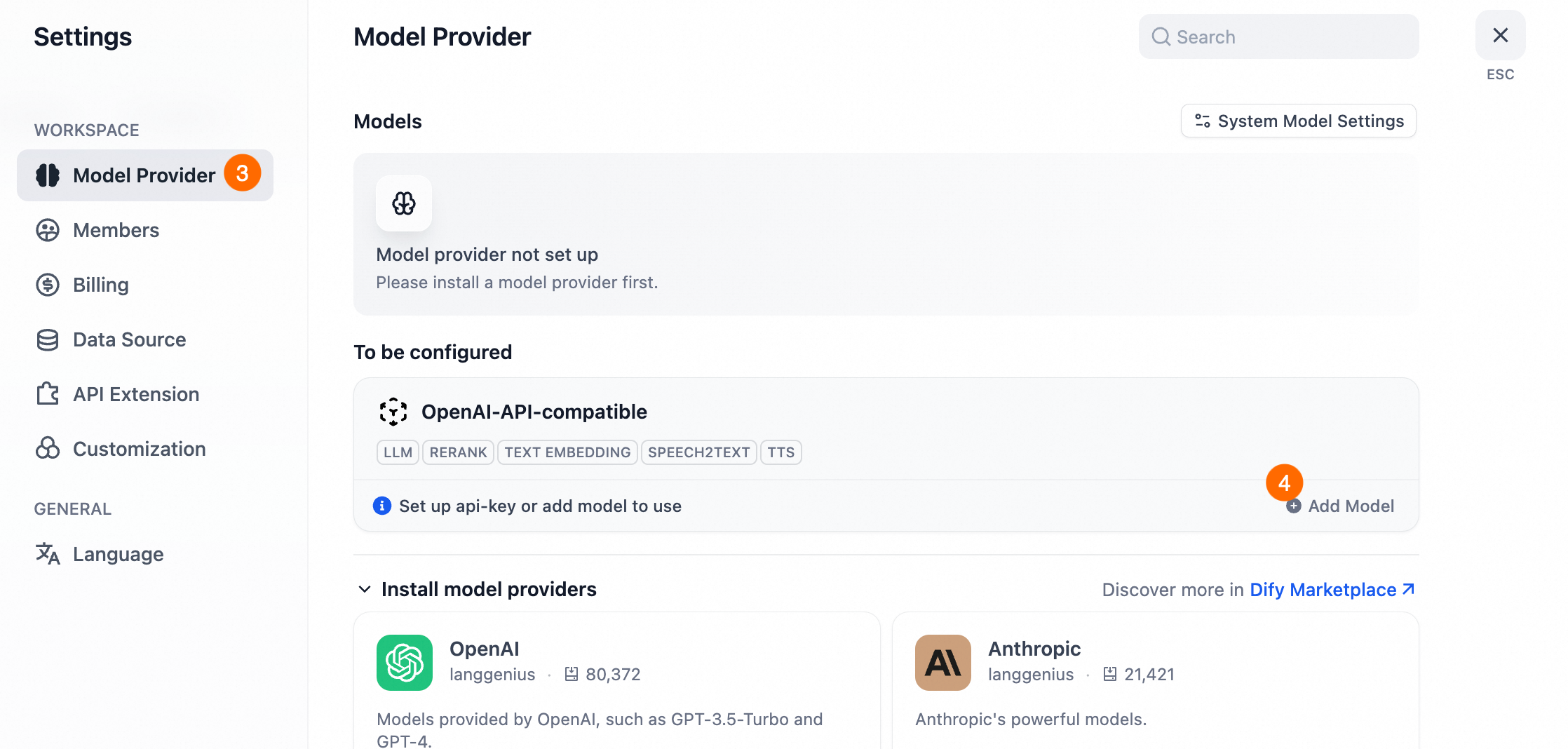
モデルプロバイダーを追加します。
プロフィール画像をクリックして設定を選択し、モデルプロバイダーに移動して
OpenAI-API-compatibleを見つけ、[追加]をクリックします。インストールされていない場合は、画面の指示に従ってモデルプロバイダーをインストールしてください。
次の設定を行い、保存 をクリックします。
モデルタイプ: LLM。
モデル名:
DeepSeek-R1-Distill-Qwen-7B。API キー:
api-key-example-abc123。 このキーは、ステップ 6 のコンテナグループの起動コマンドで設定したapi-keyと同じである必要があります。
API エンドポイント URL:
重要<alb_domain_name>を、お使いの ALB インスタンスのドメイン名で置き換えます。コンソールに移動し、ステップ 5 で作成した ALB インスタンスを見つけて、図のようにドメイン名を表示します。

http://<alb_domain_name>/v1
チャットアシスタントアプリケーションを作成して操作します。
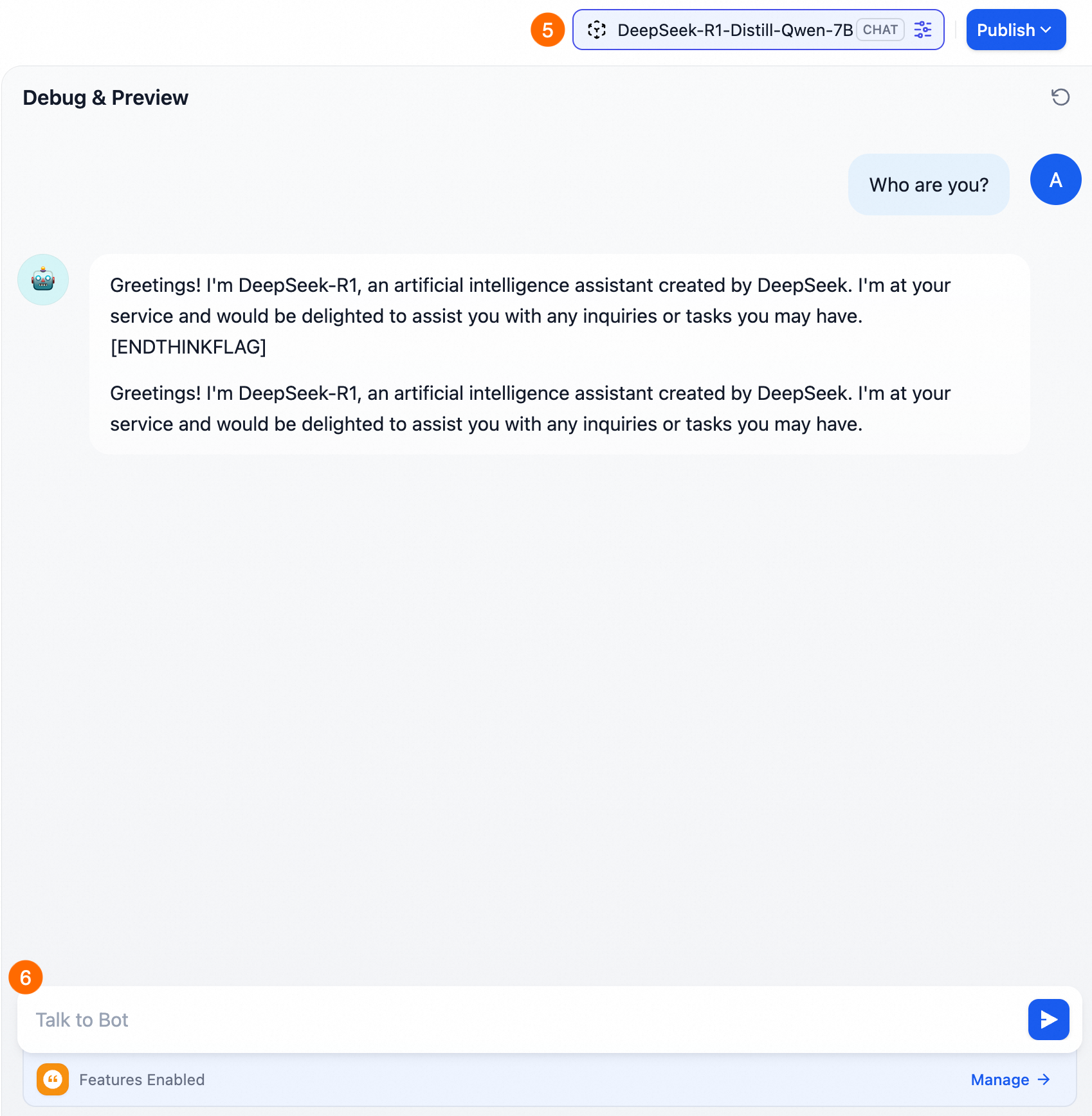
リソースのクリーンアップ
本番環境での考慮事項
本番環境では、アーキテクチャを改善するために次の推奨事項を検討してください。
Auto Scaling の設定:ワークロードに基づいてスケーリンググループ内のインスタンス数を自動的にスケーリングすることで、コストを削減できます。たとえば、イベントトリガータスクを設定して GPU メモリ使用量に基づくカスタムスケーリングを実装したり、単一の ALB インスタンスの 1 秒あたりのクエリ数 (QPS) メトリクスに基づいて自動的にスケールしたりできます。
NAT ゲートウェイの使用:これにより、すべてのインスタンスに Elastic IP アドレス (EIP) を設定する必要がなくなります。このチュートリアルでは、パブリックイメージをプルするために ECI インスタンスに EIP を設定しています。本番環境では、NAT ゲートウェイを使用して ECI インスタンスにインターネットアクセスを提供できます。
ALB インスタンスのドメイン名の設定と HTTPS サポートの追加:セキュリティを強化するために、サービスエンドポイントにカスタムドメイン名を使用し、HTTPS リスナーを設定することを推奨します。詳細については、「ALB インスタンスの CNAME レコードを設定する」および「HTTPS リスナーを追加する」をご参照ください。