KServe(旧称 KFServing)は、クラウドネイティブ環境におけるモデルサーバーおよび推論エンジンです。自動スケーリング、スケールツーゼロ、カナリアデプロイなどの機能をサポートしています。 KServe を Service Mesh(ASM)と統合することで、開発者はクラウドネイティブアプリケーションで機械学習モデルに基づく推論サービスを迅速にデプロイおよび管理できます。これにより、手動設定とメンテナンスの作業負荷が軽減され、開発効率が向上します。
前提条件
Container Service for Kubernetes(ACK)クラスターが v1.17.2.7 以降の ASM インスタンスに追加されています。詳細については、ASM インスタンスへのクラスターの追加をご参照ください。
クラスターの Kubernetes API を使用して Istio リソースにアクセスできるようにする機能が有効になっています。詳細については、クラスターの Kubernetes API を使用した Istio リソースへのアクセスの有効化をご参照ください。
Knative コンポーネントが ACK クラスターにデプロイされており、Knative on ASM 機能が有効になっています。詳細については、Knative on ASM を使用したサーバーレスアプリケーションのデプロイのステップ 1 をご参照ください。
KServe の概要
モデルサーバーとして、KServe は機械学習モデルと深層学習モデルの大規模デプロイをサポートしています。 KServe は、従来の Kubernetes デプロイメントモード、またはスケールツーゼロをサポートするサーバーレスモードで動作するようにデプロイできます。モデルの自動トラフィックベースのスケーリングと、ブルーグリーンまたはカナリアデプロイを提供します。詳細については、KServe をご参照ください。
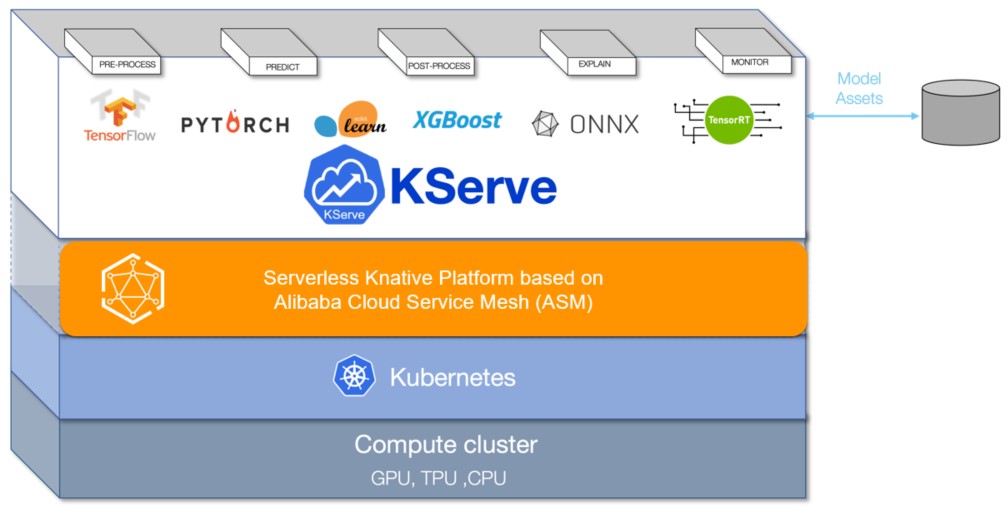
ステップ 1:KServe コンポーネント cert-manager をインストールする
ASM コンソール にログインします。左側のナビゲーションペインで、 を選択します。
[メッシュ管理] ページで、ASM インスタンスの名前をクリックします。左側のナビゲーションペインで、 を選択します。
[ASM 上の Kserve] ページで、[ASM 上の Kserve を有効にする] をクリックします。
KServe は cert-manager コンポーネントに依存しています。 KServe をインストールすると、cert-manager コンポーネントが自動的にインストールされます。独自の cert-manager コンポーネントを使用する場合は、[クラスターに Certmanager コンポーネントを自動的にインストールする] をオフにします。
ステップ 2:ASM イングレスゲートウェイの IP アドレスを取得する
ASM コンソール にログインします。左側のナビゲーションペインで、 を選択します。
[メッシュ管理] ページで、ASM インスタンスの名前をクリックします。左側のナビゲーションペインで、 を選択します。
[イングレスゲートウェイ] ページで、ASM イングレスゲートウェイの [サービスアドレス] を表示して記録します。
ステップ 3:推論サービスを作成する
この例では、テストに scikit-learn トレーニングモデルを使用します。
kubectl を使用して、データプレーン上の ACK クラスターに接続します。次に、次のコマンドを実行して、KServe リソースをデプロイするための名前空間を作成します。
kubectl create namespace kserve-test推論サービスを作成します。
次の内容を使用して、isvc.yaml ファイルを作成します。
apiVersion: "serving.kserve.io/v1beta1" kind: "InferenceService" metadata: name: "sklearn-iris" spec: predictor: model: modelFormat: name: sklearn storageUri: "gs://kfserving-examples/models/sklearn/1.0/model"次のコマンドを実行して、kserve-test 名前空間に sklearn-iris サービスを作成します。
kubectl apply -f isvc.yaml -n kserve-test
次のコマンドを実行して、sklearn-iris サービスが正常に作成されたかどうかをクエリします。
kubectl get inferenceservices sklearn-iris -n kserve-test予期される出力:
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE sklearn-iris http://sklearn-iris.kserve-test.example.com True 100 sklearn-iris-predictor-00001 3h26mREADYの値がTrueであることは、sklearn-iris サービスが正常に作成されたことを示します。(オプション)仮想サービスと Istio ゲートウェイを表示します。
sklearn-iris サービスが作成されると、scikit-learn モデル用に仮想サービスと Istio ゲートウェイが自動的に作成されます。仮想サービスと Istio ゲートウェイを表示するには、次の手順を実行します。
ASM コンソール にログインします。左側のナビゲーションペインで、 を選択します。
[メッシュ管理] ページで、ASM インスタンスの名前をクリックします。左側のナビゲーションペインで、 を選択します。
[virtualservice] ページで、
 [名前空間] の横にある kserve-test名前空間 アイコンをクリックし、 ドロップダウンリストから を選択して、作成された仮想サービスを表示します。
[名前空間] の横にある kserve-test名前空間 アイコンをクリックし、 ドロップダウンリストから を選択して、作成された仮想サービスを表示します。左側のナビゲーションペインで、 を選択します。
[ゲートウェイ] ページの上部で、knative-serving[名前空間] ドロップダウンリストから を選択して、作成された Istio ゲートウェイを表示します。
ステップ 4:scikit-learn モデルによって提供されるサービスにアクセスする
次のセクションでは、Linux および Mac オペレーティングシステムで scikit-learn モデルによって提供されるサービスにアクセスする手順について説明します。
次のコマンドを実行して、scikit-learn モデルの入力ファイルを作成します。
cat <<EOF > "./iris-input.json" { "instances": [ [6.8, 2.8, 4.8, 1.4], [6.0, 3.4, 4.5, 1.6] ] } EOFイングレスゲートウェイを介して scikit-learn モデルによって提供されるサービスへのアクセスをテストします。
次のコマンドを実行して、SERVICE_HOSTNAME の値を取得します。
SERVICE_HOSTNAME=$(kubectl get inferenceservice sklearn-iris -n kserve-test -o jsonpath='{.status.url}' | cut -d "/" -f 3) echo $SERVICE_HOSTNAME予期される出力:
sklearn-iris.kserve-test.example.com次のコマンドを実行してサービスにアクセスします。この手順では、ASM_GATEWAY を ステップ 2 で取得したイングレスゲートウェイの IP アドレスに設定します。
ASM_GATEWAY="XXXX" # XXXX をイングレスゲートウェイの IP アドレスに置き換えます。 curl -H "Host: ${SERVICE_HOSTNAME}" http://${ASM_GATEWAY}:80/v1/models/sklearn-iris:predict -d @./iris-input.json予期される出力:
{"predictions": [1, 1]}
scikit-learn モデルによって提供されるサービスのパフォーマンスをテストします。
次のコマンドを実行して、ストレステスト用のアプリケーションをデプロイします。
kubectl create -f https://alibabacloudservicemesh.oss-cn-beijing.aliyuncs.com/kserve/v0.7/loadtest.yaml次のコマンドを実行して、Pod の名前をクエリします。
kubectl get pod予期される出力:
NAME READY STATUS RESTARTS AGE load-testxhwtq-pj9fq 0/1 Completed 0 3m24s sklearn-iris-predictor-00001-deployment-857f9bb56c-vg8tf 2/2 Running 0 51m次のコマンドを実行して、テスト結果ログを表示します。
kubectl logs load-testxhwtq-pj9fq # Pod 名を、ストレステスト用にデプロイしたアプリケーションが実行されている Pod の名前に置き換えます。予期される出力:
Requests [total, rate, throughput] 30000, 500.02, 500.01 Duration [total, attack, wait] 59.999s, 59.998s, 1.352ms Latencies [min, mean, 50, 90, 95, 99, max] 1.196ms, 1.463ms, 1.378ms, 1.588ms, 1.746ms, 2.99ms, 18.873ms Bytes In [total, mean] 690000, 23.00 Bytes Out [total, mean] 2460000, 82.00 Success [ratio] 100.00% Status Codes [code:count] 200:30000 Error Set:
参考資料
クラウドネイティブシナリオで、ビッグデータアプリケーションや AI アプリケーションなどのデータ集約型アプリケーションのモデル読み込みを高速化する必要がある場合は、ASM 上の KServe 機能と Fluid を統合して、データアクセスを高速化する AI サービングを実装するをご参照ください。
生の入力データをモデルサーバーに必要な形式に変換する必要がある場合は、InferenceService を使用してトランスフォーマーをデプロイするをご参照ください。
大容量、高密度、頻繁に変更されるユースケースのモデルサービスをデプロイする場合は、Model Service Mesh を使用して複数のモデルサービスを管理、デプロイ、およびスケジュールできます。詳細については、Model Service Mesh をご参照ください。