Knative on ASM は、リクエストトラフィックに基づいてサービスを自動的にスケーリングする標準機能である Knative Pod Autoscaler (KPA) を提供します。 トラフィックの変動によりサービスのパフォーマンスが不安定になったり、リソースが無駄になったりする場合は、KPA を使用してオートスケーリングを行います。 KPA は、リアルタイムのトラフィックデータをモニタリングおよび分析することで、サービスインスタンスの数を動的に調整します。 これにより、ピーク時にはサービス品質を確保し、オフピーク時にはリソースを節約することで、システムの効率を向上させ、コストを削減します。
前提条件
Knative on ASM で Knative Service を作成済みであること。 詳細については、「Knative on ASM を使用したサーバーレスアプリケーションのデプロイ」をご参照ください。
このトピックでは、デモ目的でデフォルトドメイン名 example.com を使用します。 カスタムドメイン名を使用するには、「Knative on ASM でのカスタムドメイン名の使用」をご参照ください。
オートスケーリングの仕組み
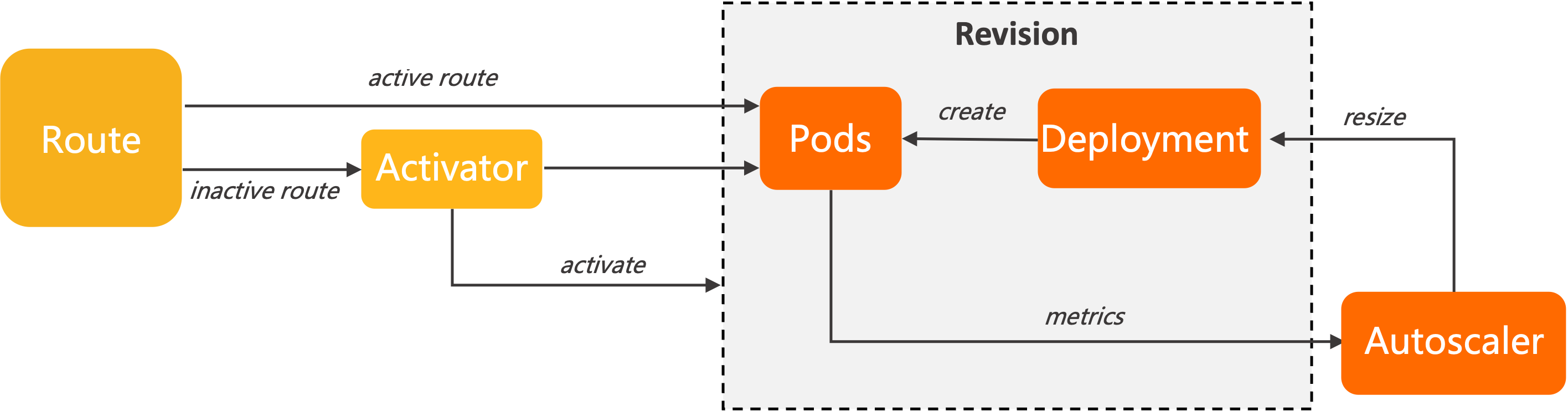
Knative Serving は、各 Pod に Queue Proxy コンテナ (queue-proxy) を挿入します。 このコンテナは、アプリケーションコンテナからの同時実行数メトリックをオートスケーラーにレポートします。 オートスケーラーは、同時リクエスト数とスケーリングアルゴリズムに基づいて Deployment 内の Pod 数を調整し、オートスケーリングを可能にします。
同時実行数と QPS
同時実行数とは、Pod が処理している同時リクエストの数です。 QPS (クエリ/秒) は、Pod が 1 秒あたりに処理するリクエストの数であり、その最大スループットを表します。
高負荷下では、高い同時実行数がシステムに過負荷をかける可能性があります。 これにより、CPU とメモリの消費量が増加し、システムのパフォーマンスが低下し、応答レイテンシーが増加し、QPS が低下する可能性があります。
アルゴリズム
Knative Pod Autoscaler (KPA) は、Pod あたりの平均同時リクエスト数に基づいて Pod をスケーリングします。 デフォルトでは、Knative は同時実行数ベースのオートスケーリングを使用し、Pod あたりの目標同時実行数は 100 です。 KPA はまた、目標使用率を使用してスケーリングのタイミングを決定します。
同時実行数ベースのスケーリングでは、Pod の数は次のように計算されます: 目的の Pod 数 = 合計同時リクエスト数 / (目標同時実行数 * 目標使用率)
たとえば、目標同時実行数が 10 で目標使用率が 0.7 (70%) の場合、100 の同時リクエストが流入すると、オートスケーラーは 15 Pod にスケールします (100 / (10 * 0.7) ≈ 15)。
KPA は、安定モードとパニックモードの 2 つのモードを使用して、トラフィックの段階的な変化と急激な変化の両方に対応してスケーリングします。
-
安定モード
安定モードでは、KPA は 60 秒の安定期間 (stable window) にわたる平均同時実行数を計算し、それに応じて Pod の数を調整します。
-
パニックモード
パニックモードは、トラフィックが急増したときにアクティブになります。 これは、デフォルトで 6 秒である、はるかに短いパニック期間 (panic window) にわたる平均同時実行数を計算します。 パニック期間は
stable window * panic-window-percentageとして計算されます。 デフォルトの panic-window-percentage は 10% (0.1) です。 観測されたトラフィックがパニックしきい値を超えると、KPA は Pod の数を急速にスケールアップして、即時の需要に対応します。
KPA は、パニックしきい値に基づいて、安定モードとパニックモードのどちらの計算を使用するかを決定します。 パニックしきい値は panic-threshold-percentage / 100 として計算されます。 デフォルトの panic-threshold-percentage は 200 であり、デフォルトのパニックしきい値は 2 になります。
パニックモードで計算された目的の Pod 数が、現在の準備完了 Pod 数の少なくとも 2 倍である場合、KPA はパニックモードの計算に基づいてスケーリングします。 それ以外の場合は、安定モードの計算を使用します。
KPA の設定
グローバルな KPA 設定は、knative-serving 名前空間にある config-autoscaler ConfigMap で定義されます。 次のコマンドを実行して、デフォルトの設定を表示します。 主要なパラメーターについては、以下で説明します。
kubectl -n knative-serving get cm config-autoscaler -o yaml期待される出力 (コード内のコメントは省略されています):
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
_example:
container-concurrency-target-default: "100"
container-concurrency-target-percentage: "0.7"
enable-scale-to-zero: "true"
max-scale-up-rate: "1000"
max-scale-down-rate: "2"
panic-window-percentage: "10"
panic-threshold-percentage: "200"
scale-to-zero-grace-period: "30s"
scale-to-zero-pod-retention-period: "0s"
stable-window: "60s"
target-burst-capacity: "200"
requests-per-second-target-default: "200"_example フィールドのパラメーターはデフォルト値を示しています。 パラメーターを変更するには、_example フィールドから data フィールドにコピーしてから、その値を変更します。
config-autoscaler ConfigMap への変更は、すべての Knative Service にグローバルに適用されます。 特定の Knative Service を設定するには、アノテーションを使用します。 詳細については、「ユースケース 1:オートスケーリングの同時実行数の目標値の設定」および「ユースケース 2:オートスケーリングのスケール範囲の設定」をご参照ください。
ゼロへのスケールの設定
|
パラメーター |
説明 |
値の例 |
|
scale-to-zero-grace-period |
非アクティブな Revision がゼロにスケールされるまで実行される期間。 最小値は 30 秒です。 |
30s |
|
stable-window |
安定モードでは、オートスケーラーは安定期間 (stable window) 内の平均同時実行数に基づいて動作します。 さらに、安定期間は Revision アノテーションで設定できます。例: |
60s |
|
enable-scale-to-zero |
フィールドを |
true |
オートスケーラーの同時実行数の設定
|
パラメーター |
説明 |
値の例 |
|
container-concurrency-target-default |
目的の同時リクエスト数を定義します (ソフトリミット)。 これは、Knative のオートスケーラーに推奨される設定です。 ConfigMap のデフォルトの同時実行数の目標値は 100 です。 さらに、このフィールド値は、Revision の |
100 |
|
containerConcurrency |
特定の Revision に対して、特定の時点で許可される同時リクエストの数を制限します (ハードリミット)。
|
0 |
|
container-concurrency-target-percentage |
同時実行率 (concurrency factor とも呼ばれる) は、スケーリングのための有効な同時実行数の目標値を計算するために使用されます。有効な同時実行数の目標値 = target (または containerConcurrency) * container-concurrency-target-percentage。 たとえば、 |
0.7 |
スケール範囲の設定
minScale と maxScale を使用して、アプリケーションの Pod の最小数と最大数を設定できます。 これは、コールドスタートとコンピューティングコストを制御するのに役立ちます。
-
minScaleアノテーションが設定されていない場合、サービスは 0 Pod にスケールできます。 -
maxScaleアノテーションが設定されていない場合、作成できる Pod の数に上限はありません。 -
config-autoscalerConfigMap でenable-scale-to-zeroをfalseに設定した場合、サービスは 1 Pod にスケールダウンします。
次のように、Revision テンプレートで minScale と maxScale を設定できます:
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "2"
autoscaling.knative.dev/maxScale: "10"ユースケース 1:同時実行数の目標値の設定
このユースケースでは、クラスターに autoscale-go アプリケーションをデプロイし、KPA を使用して同時実行数の目標値を設定することでオートスケーリングする方法を示します。
Knative Service の作成方法の詳細については、「Knative on ASM を使用したサーバーレスアプリケーションのデプロイ」をご参照ください。
-
autoscale-go.yamlを作成し、同時実行数の目標値を 10 に設定します。これは、autoscaling.knative.dev/targetの値を10に設定することを意味します。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1 -
kubectl でクラスターに接続し、次のコマンドを実行して
autoscale-goアプリケーションをデプロイします。kubectl apply -f autoscale-go.yaml -
ASM コンソールにログインします。 左側のナビゲーションウィンドウで、ターゲットインスタンスの名前をクリックします。 を選択し、Service address セクションから IP アドレスを取得します。
-
Hey 負荷テストツールを使用して、50 の同時リクエストで 30 秒間トラフィックを送信します。
Hey ツールのインストールと使用方法については、公式の Hey リポジトリをご参照ください。
説明xxx.xxx.xxx.xxxを実際のアクセスゲートウェイアドレスに置き換えてください。 詳細については、「アクセスゲートウェイアドレスの取得」をご参照ください。hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://xxx.xxx.xxx.xxx?sleep=100&prime=10000&bloat=5"(base) xxx .kube % kubectl get deploy -w NAME READY UP-TO-DATE AVAILABLE AGE autoscale-go-00001-deployment 0/0 0 0 7m5s autoscale-go-00001-deployment 0/1 0 0 7m17s autoscale-go-00001-deployment 0/1 0 0 7m17s autoscale-go-00001-deployment 0/1 0 0 7m17s autoscale-go-00001-deployment 0/1 1 0 7m17s autoscale-go-00001-deployment 0/7 1 0 7m18s autoscale-go-00001-deployment 0/7 1 0 7m18s autoscale-go-00001-deployment 0/7 1 0 7m18s autoscale-go-00001-deployment 0/7 7 0 7m18s autoscale-go-00001-deployment 1/7 7 1 7m19s autoscale-go-00001-deployment 2/7 7 2 7m20s autoscale-go-00001-deployment 3/7 7 3 7m20s autoscale-go-00001-deployment 4/7 7 4 7m21s autoscale-go-00001-deployment 5/7 7 5 7m23s autoscale-go-00001-deployment 6/7 7 6 7m23s autoscale-go-00001-deployment 7/7 7 7 7m23s autoscale-go-00001-deployment 7/3 7 7 8m20s autoscale-go-00001-deployment 7/3 7 7 8m20s autoscale-go-00001-deployment 7/3 7 7 8m20s autoscale-go-00001-deployment 3/3 3 3 8m20s autoscale-go-00001-deployment 3/2 3 3 8m26s autoscale-go-00001-deployment 3/2 3 3 8m26s autoscale-go-00001-deployment 2/2 2 2 8m26s autoscale-go-00001-deployment 2/1 2 2 8m36s autoscale-go-00001-deployment 2/1 2 2 8m36s autoscale-go-00001-deployment 1/1 1 1 8m36s autoscale-go-00001-deployment 1/0 1 1 9m48s autoscale-go-00001-deployment 1/0 1 1 9m48s autoscale-go-00001-deployment 0/0 0 0 9m48s出力は、サービスが 7 Pod にスケールアウトすることを示しています。 これは、コンテナの同時実行数が目標の特定の割合 (デフォルトでは 70%) を超えると、Knative がプロアクティブにより多くの Pod を作成するためです。 これにより、同時実行数が増加し続けても目標が破られるのを防ぎます。
ユースケース 2:スケール範囲の設定
スケール範囲は、アプリケーションの Pod の最小数と最大数を定義します。 このユースケースでは、autoscale-go アプリケーションをデプロイし、これらの範囲を設定してオートスケーリングする方法を示します。
Knative Service の作成方法の詳細については、「Knative on ASM を使用したサーバーレスアプリケーションのデプロイ」をご参照ください。
-
autoscale-go.yamlという名前のファイルを作成します。 同時実行数の目標値を 10、最小インスタンス (minScale) を 1、最大インスタンス (maxScale) を 3 に設定します。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/minScale: "1" autoscaling.knative.dev/maxScale: "3" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1 -
kubectl でクラスターに接続し、次のコマンドを実行して
autoscale-goアプリケーションをデプロイします。kubectl apply -f autoscale-go.yaml -
ASM コンソールにログインします。 左側のナビゲーションウィンドウで、ターゲットインスタンスの名前をクリックします。 を選択し、Service address セクションから IP アドレスを取得します。
-
Hey 負荷テストツールを使用して、50 の同時リクエストで 30 秒間トラフィックを送信します。
Hey ツールのインストールと使用方法については、公式の Hey リポジトリをご参照ください。
説明xxx.xxx.xxx.xxxを実際のアクセスゲートウェイアドレスに置き換えてください。 詳細については、「アクセスゲートウェイアドレスの取得」をご参照ください。hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://xxx.xxx.xxx.xxx?sleep=100&prime=10000&bloat=5"
kubectl get deploy -w <code code-type="xCode" data-tag="codeblock"> 期待される出力:Expected output:出力は、サービスが最大 3 Pod にスケールアウトすることを示しています。 リクエストトラフィックがない場合、サービスは最小 1 Pod にスケールダウンします。 これにより、オートスケーリングが期待どおりに機能していることが確認されます。
関連ドキュメント
-
Knative で構築されたマイクロサービスに安全にアクセスして管理するには、ASM ゲートウェイを使用して HTTPS アクセスを有効にすることができます。 サービスエンドポイントへのトラフィックを暗号化することで、通信を保護し、アーキテクチャのセキュリティと信頼性を向上させます。 詳細については、「ASM ゲートウェイを使用して HTTPS 経由で Knative Service にアクセスする」をご参照ください。
-
アプリケーションのアップグレード中に互換性と安定性の課題に直面した場合、Knative on ASM で Knative Service のカナリアリリースを実行できます。 詳細については、「Knative on ASM で Knative Service のカナリアリリースを実行する」をご参照ください。
-
Knative Service の CPU メトリックのしきい値を設定して、負荷の急増に対応してリソースをオートスケーリングできます。 詳細については、「Knative で HPA を使用する」をご参照ください。