サーバー側のエラー、特に 5xx 応答は、根本原因がビジネスロジックの奥深くに隠れていることが多いため、トラブルシューティングが最も困難な問題の 1 つです。従来のログベースのデバッグでは、SSH アクセス、手動でのログ検索、分散サービス全体での推測が必要になります。
Application Real-Time Monitoring Service (ARMS) は、バイトコードインストルメンテーションによってこのオーバーヘッドを解消します。ARMS エージェントをインストールすると、コードを変更することなく、例外が自動的にキャプチャ、集約、追跡されます。単一のコンソールから、例外が最初に発生した日時、再発頻度、およびそれをトリガーしたメソッド呼び出しを特定できます。
このアプローチは、特に次のような場合に役立ちます。
分散クラスター全体で特定の例外が発生した時間と頻度を特定する場合。
今日の例外を昨日の例外と比較したり、リリース後の例外をリリース前のベースラインと比較したりする場合。
特定の例外について、パラメーター、アップストリーム呼び出し、ダウンストリーム呼び出しを含む完全なリクエストコンテキストを取得する場合。
サポートチケットで参照されている失敗したトランザクションを、その根本原因までトレースします。
仕組み
診断ワークフローは 3 つのステージで構成されます。
ARMS エージェントをインストールして、アプリケーションの例外データの自動収集を開始します。
例外統計を確認して、トレンド、スパイク、最も頻繁に発生するエラータイプを特定します。
呼び出しスナップショットとメソッドスタックを詳細に表示して、例外を根本原因までトレースします。
前提条件
ご利用のアプリケーションに ARMS エージェントをインストールします。デプロイメントに合った方法を選択してください。
Java アプリケーション: ARMS エージェントを手動でインストールする
Container Service for Kubernetes (ACK) の Java アプリケーション: ACK で ARMS エージェントを自動的にインストールする
オープンソースの Kubernetes クラスター内の Java アプリケーション:Kubernetes 環境に ARMS エージェントを自動的にインストールする
インストール後、エージェントはメトリックの自動収集を開始し、前日比および前週比の比較を行います。追跡されるメトリックには、平均応答時間、リクエスト数、エラー、リアルタイムインスタンス、フル GC イベント、低速 SQL クエリ、例外、低速呼び出しが含まれます。
例外統計の確認
ARMS コンソールを使用して、最も頻繁に発生する例外と、時間の経過に伴うトレンドの変化を特定します。
ARMS コンソールにログインします。
左側のナビゲーションウィンドウで、[アプリケーションモニタリング] > [アプリケーション] を選択します。
上部のナビゲーションバーで、アプリケーションがデプロイされているリージョンを選択します。
[アプリケーション] ページで、ご利用のアプリケーションの名前をクリックします。
[アプリケーション概要] ページで、[概要] タブをクリックします。下部には、例外の総数と、前日比および前週比の変化が表示されます。
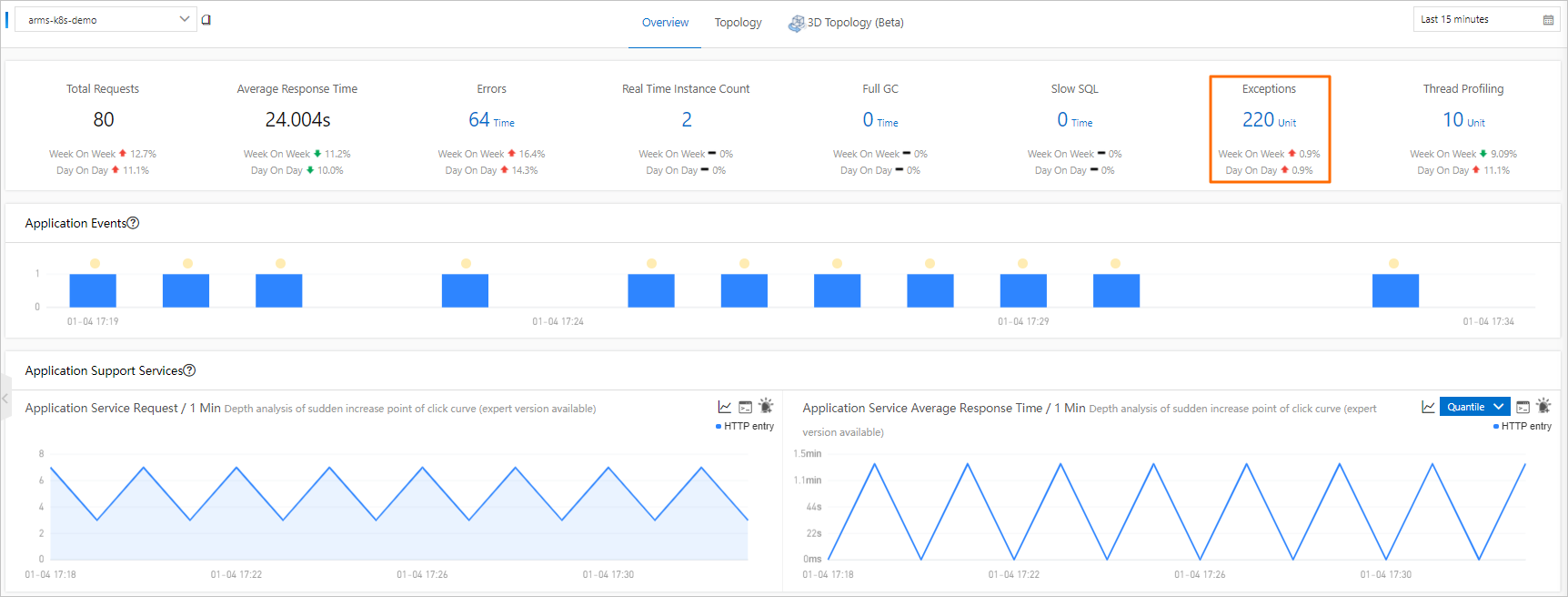
[統計分析] セクションまでスクロールし、[例外タイプ] を見つけます。この内訳には、各例外タイプが発生した回数が表示されます。
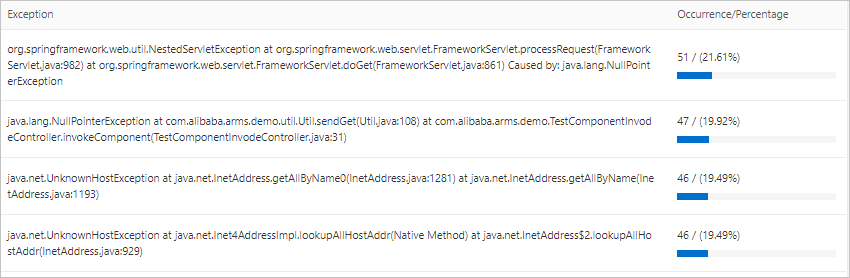
左側のナビゲーションウィンドウで、[アプリケーション詳細] をクリックします。[アプリケーション詳細] ページで、[例外分析] タブをクリックして、例外統計チャート、エラー数、例外スタックを表示します。
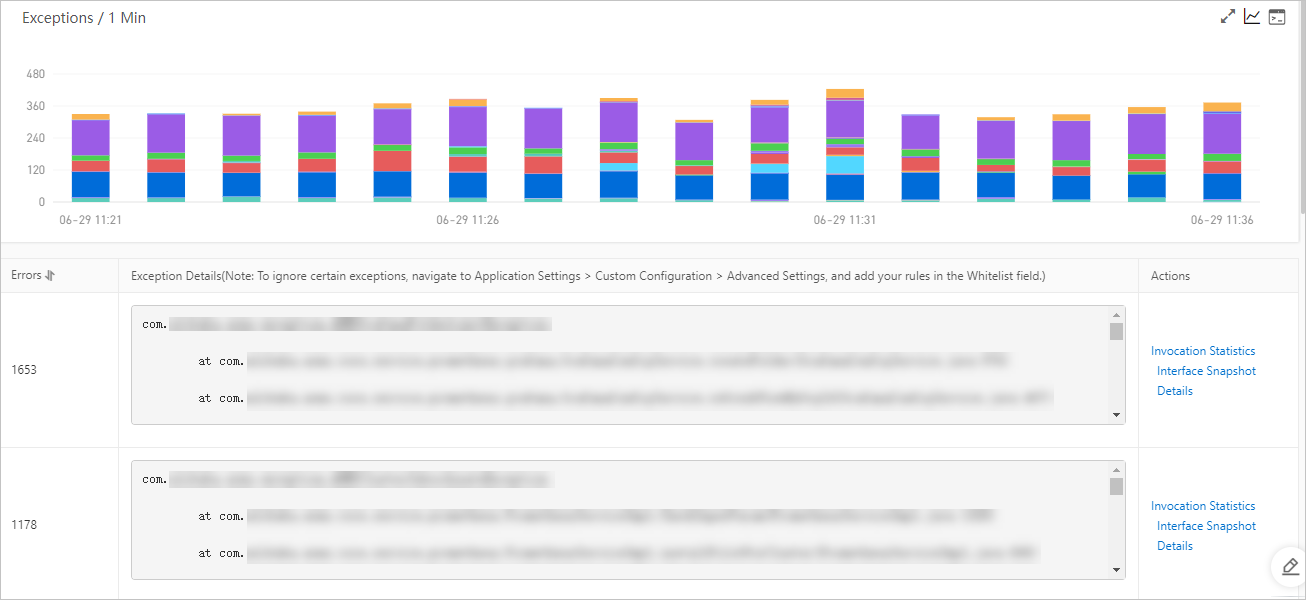
例外の根本原因のトレース
例外統計は、何が失敗しているかを示しますが、その理由は示しません。ログファイル内のスタックトレースは、どの行が例外をスローしたかを示しますが、完全なアップストリームおよびダウンストリームの呼び出しコンテキストとリクエストパラメーターが欠けています。
ARMS は、バイトコードインストルメンテーションによってこのギャップを埋めます。最小限のパフォーマンスオーバーヘッドで、すべての例外について完全なアップストリームおよびダウンストリームの呼び出しスナップショットをキャプチャします。これにより、根本原因を特定するために必要な、パラメーター、呼び出しチェーン、メソッドスタックを含む完全なリクエストコンテキストが得られます。
[例外分析] タブで、診断する例外タイプを見つけ、[操作] 列の [インターフェーススナップショット] をクリックします。[インターフェーススナップショット] タブには、この例外タイプに関連付けられた呼び出しトレースが表示されます。
特定の呼び出しの TraceId をクリックして、その完全なトレースを開きます。
説明高度なトレースフィルタリングについては、「トレースクエリ」をご参照ください。
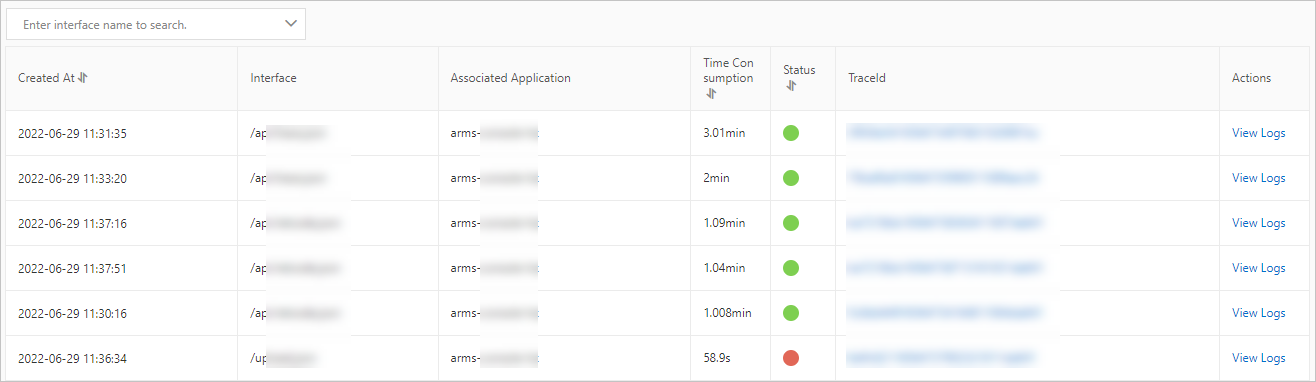
トレース詳細ページで、完全な呼び出しチェーンを確認します。[メソッドスタック] 列で、虫眼鏡アイコンをクリックしてメソッドスタックを調査し、失敗した呼び出しの完全な実行コンテキストを把握します。
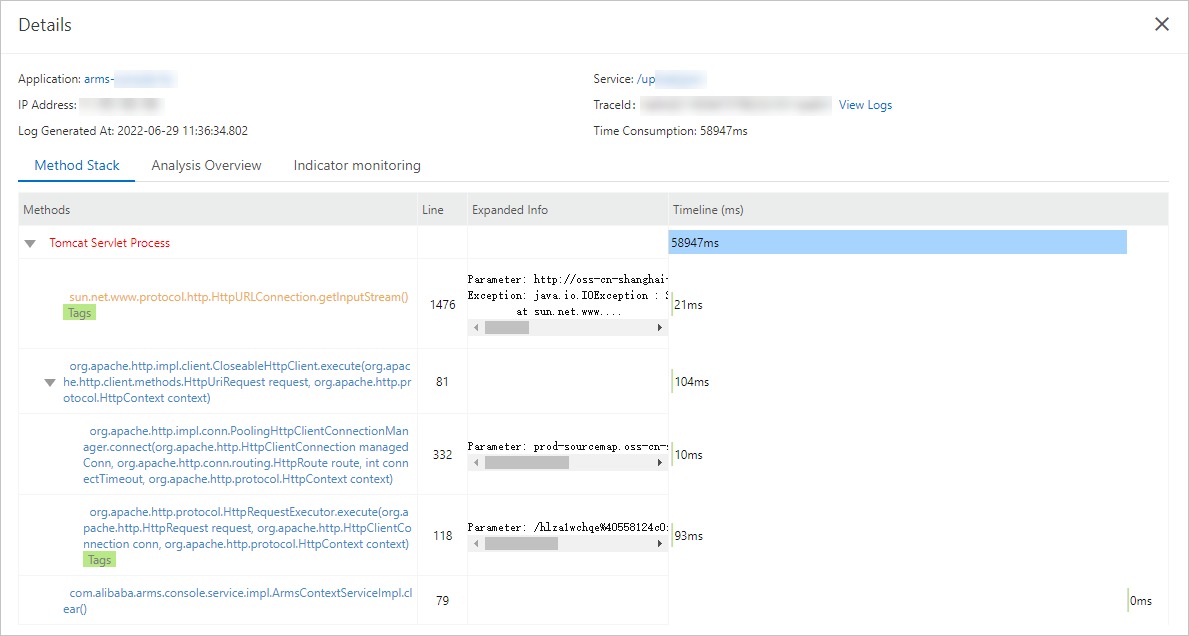
根本原因を特定したら、基になるコードを修正します。追加の例外を解決するには、[インターフェース呼び出し] タブに戻り、他の失敗した呼び出しを確認します。
プロアクティブなアラート機能の設定
例外が発生した瞬間にチームに通知されるように、アラートルールを設定します。これにより、事後的に問題を発見するのを防ぎます。特定の API またはアプリケーション内のすべての API に対してアラートルールを作成できます。詳細については、「アプリケーションモニタリングのアラートルール」をご参照ください。