本トピックでは、DMS のジョブスケジューリング機能を使用して、ApsaraDB RDS for PostgreSQL インスタンスから AnalyticDB for PostgreSQL インスタンスにデータを定期的に転送する方法について説明します。
仕組み
このプロセスでは、DMS を使用して抽出、変換、ロード (ETL) パイプラインをオーケストレーションします。 ジョブは ApsaraDB RDS for PostgreSQL データベースからデータを抽出し、中間ストレージとして OSS バケットにロードします。その後、サーバーレスモードの AnalyticDB for PostgreSQL インスタンスが OSS からデータを読み取って分析します。 次の図にワークフローを示します。
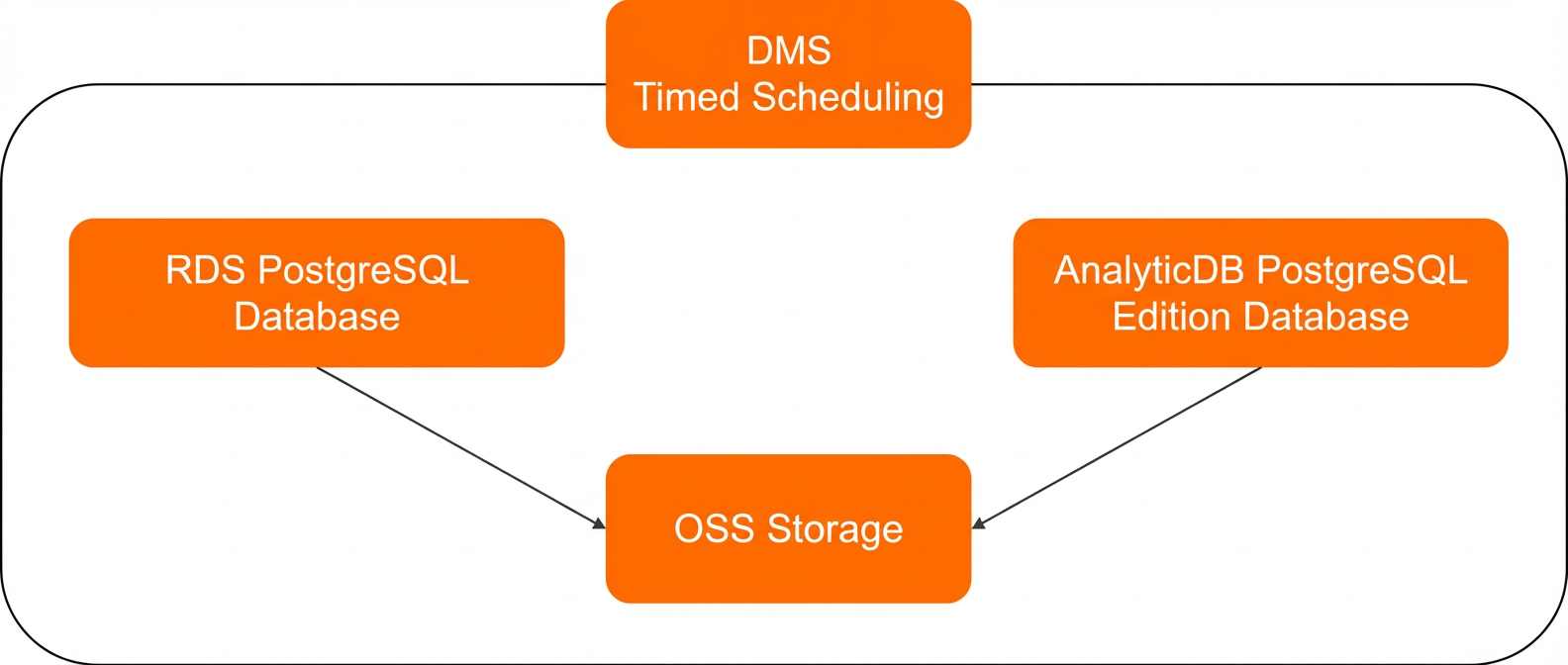
利点
-
OSS にデータを格納することで、データ損失のない低コストのアーカイブソリューションが実現します。
-
ApsaraDB RDS for PostgreSQL データベースから サーバーレスモードの AnalyticDB for PostgreSQL にデータをロードし、通常は T+1 または日次ベースで高性能なデータ分析を実行します。
-
DMS のジョブスケジューリングにおけるローコードのグラフィカルユーザーインターフェース (GUI) は、自動スケジューリングフレームワークの設定を簡素化します。
使用上の注意
-
ApsaraDB RDS for PostgreSQL データベースのデータは、増分アーカイブに適している必要があります。たとえば、時間列を使用して毎日データをアーカイブするなどです。
-
ApsaraDB RDS for PostgreSQL インスタンス、AnalyticDB for PostgreSQL インスタンス、および OSS バケットは、同じリージョンにある必要があります。
前提条件
AnalyticDB for PostgreSQL
-
サーバーレスモードの AnalyticDB for PostgreSQL インスタンスが作成されていること。詳細については、「インスタンスの作成」をご参照ください。
-
初期アカウントが作成されていること。詳細については、「データベースアカウントの作成と管理」をご参照ください。
ApsaraDB RDS for PostgreSQL
-
ApsaraDB RDS for PostgreSQL インスタンスが作成されていること。詳細については、「ApsaraDB RDS for PostgreSQL インスタンスの作成」をご参照ください。
説明ApsaraDB RDS for PostgreSQL インスタンスは PostgreSQL 9.4 から 13.0 で動作している必要があります。
-
特権アカウントが作成されていること。詳細については、「アカウントの作成」をご参照ください。
OSS
-
OSS バケットが作成されていること。詳細については、「バケットの作成」をご参照ください。
-
次の手順で、OSS バケットの [バケット名]と [エンドポイント]を取得します。
-
OSS コンソールにログインします。
-
ナビゲーションペインで、 バケット をクリックします。
-
バケット ページで、対象バケットの名前をクリックします。
バケット ページで、[バケット名]を取得できます。
-
ナビゲーションペインで、 概要 をクリックします。
-
概要 ページで、 アクセスタイプ セクションの エンドポイント を確認します。
VPC 内 ECS からのアクセス (イントラネット) のエンドポイントを使用することを推奨します。
-
AccessKey ID と AccessKey Secret の取得
AccessKey ID と AccessKey Secret の取得方法の詳細については、「AccessKey ペアの作成」をご参照ください。
サービスとデータの準備
ApsaraDB RDS for PostgreSQL
-
ApsaraDB RDS for PostgreSQL データベースに接続します。詳細については、「ApsaraDB RDS for PostgreSQL インスタンスへの接続」をご参照ください。
このチュートリアルのすべての操作は、DMS コンソールを使用して実行します。
-
t_src という名前のテストテーブルを作成し、サンプルデータを挿入します:
CREATE TABLE t_src (a int, b int, c date); INSERT INTO t_src SELECT generate_series(1, 1000), 1, now(); -
oss_fdw 拡張機能をインストールします:
CREATE EXTENSION IF NOT EXISTS oss_fdw; -
OSS 外部テーブルを作成します:
CREATE SERVER ossserver FOREIGN DATA WRAPPER oss_fdw OPTIONS (host '<oss_endpoint>' , id '<access_key_id>', key '<access_key_secret>',bucket '<bucket_name>');パラメーターは次の表のとおりです。
パラメーター
説明
host
「前提条件」の項で取得した OSS の [エンドポイント]。
id
「前提条件」の項で取得した AccessKey ID。
key
「前提条件」の項で取得した AccessKey Secret。
bucket
「前提条件」の項で取得した OSS の [バケット名]。
AnalyticDB for PostgreSQL
-
AnalyticDB for PostgreSQL データベースに接続します。詳細については、「クライアント接続」をご参照ください。
このチュートリアルのすべての操作は、DMS コンソールを使用して実行します。
-
ApsaraDB RDS for PostgreSQL の t_src テーブルと同じ構造を持つ t_target という名前のターゲットテーブルを作成します:
CREATE TABLE t_target (a int, b int, c date);説明サーバーレスモードの AnalyticDB for PostgreSQL はプライマリキーをサポートしていません。
-
oss_fdw 拡張機能をインストールします:
CREATE EXTENSION IF NOT EXISTS oss_fdw; -
OSS サーバーとユーザーマッピングを作成します:
CREATE SERVER oss_serv FOREIGN DATA WRAPPER oss_fdw OPTIONS ( endpoint '<oss_endpoint>', bucket '<bucket_name>' ); CREATE USER MAPPING FOR PUBLIC SERVER oss_serv OPTIONS ( id '<access_key_id>', key '<access_key_secret>' );パラメーターは次の表のとおりです。
パラメーター
説明
endpoint
「前提条件」の項で取得した OSS の [エンドポイント]。
id
「前提条件」の項で取得した AccessKey ID。
key
「前提条件」の項で取得した AccessKey Secret。
bucket
「前提条件」の項で取得した OSS の [バケット名]。
ETL タスクの設定
-
DMS コンソールにログインします。
-
上部メニューで [Data Development] をクリックします。 ナビゲーションペインで、 を選択します。
-
タスクフロー セクションで、 [Create Task Flow] をクリックします。
-
タスクフローの作成 ダイアログボックスで、 タスクフロー名 に名前を入力し、 OK をクリックします。
この例では、タスクフロー名 は [Import RDS PG data to OSS] に設定します。
-
ApsaraDB RDS for PostgreSQL からデータをアーカイブするようにタスクフローを設定します。
-
[Import RDS PG data to OSS] タブで、左側の データ処理 カテゴリから 単一インスタンスの SQL ノードをキャンバスにドラッグします。
-
任意:タスクノードの
 アイコンをクリックして、タスクの名前を変更します。
アイコンをクリックして、タスクの名前を変更します。タスクの名前を変更すると、ETL パイプラインの保守に役立ちます。 ビジネス要件に基づいてタスク名を設定できます。 この例では、タスクの名前は [Extract data from RDS] に変更します。
-
キャンバス上の新しく作成されたタスクノードの
 アイコンをクリックします。
アイコンをクリックします。 -
ApsaraDB RDS for PostgreSQL データベースを選択します。
[Extract data from RDS] ジョブの SQL エディタータブの上部で、ドロップダウンリストから対象のデータベース接続 (例:
[Free-control]public@pgm-bp11c***.pg.rds.aliyuncs.com:5432:postgre) を選択します。ApsaraDB RDS for PostgreSQL データベースの SQL エディタータブに切り替えて、データベースを表示できます。
「サービスとデータの準備」の項の説明に従って、データベースが準備されていることを確認してください。
-
エディターに、次の SQL ステートメントを貼り付けます:
DROP FOREIGN TABLE IF EXISTS oss_${mydate}; CREATE FOREIGN TABLE IF NOT EXISTS oss_${mydate} (a int, b int, c date) SERVER ossserver OPTIONS ( dir 'rds/t3/${mydate}/', DELIMITER '|' , format 'csv', encoding 'utf8'); INSERT INTO oss_${mydate} SELECT * FROM t_src WHERE c >= '${mydate}'; -
右側で 変数の設定 タブをクリックし、 Node Variable を選択します。 Variable Name を
mydateに、 時刻形式 をyyyyMMddに設定します。
-
-
[Import RDS PG data to OSS] タスクフローに戻り、AnalyticDB for PostgreSQL のデータロードタスクを設定します。
-
[Import RDS PG data to OSS] タブで、左側の データ処理 カテゴリから 単一インスタンスの SQL ノードをキャンバスにドラッグします。
-
任意:タスクノードの
アイコンをクリックして、タスクの名前を変更します。タスクの名前を変更すると、ETL パイプラインの保守に役立ちます。 ビジネス要件に基づいてタスク名を設定できます。 この例では、タスクの名前は [Load data to ADBPG] に変更します。
-
新しく作成されたタスクノードの
アイコンをクリックします。 -
AnalyticDB for PostgreSQL データベースを選択します。
ドロップダウンリストから対象の AnalyticDB for PostgreSQL データベース接続を選択します。
-
エディターに、次の SQL ステートメントを貼り付けます:
CREATE FOREIGN TABLE IF NOT EXISTS oss_${mydate}( a int , b int , c date ) SERVER oss_serv OPTIONS ( dir 'rds/t3/${mydate}/', format 'csv', delimiter '|', encoding 'utf8'); INSERT INTO t_target SELECT * FROM oss_${mydate}; -
右側で 変数の設定 タブをクリックし、 Node Variable を選択します。 Variable Name を
mydateに、 時刻形式 をyyyyMMddに設定します。
-
-
ApsaraDB RDS for PostgreSQL のデータ抽出タスクが AnalyticDB for PostgreSQL のデータロードタスクの前に実行されるように、スケジューリング依存関係を設定します。
-
[Extract data from RDS] タスクの右側にある円から [Load data to ADBPG] タスクにドラッグします。 依存関係が次のように表示されます。
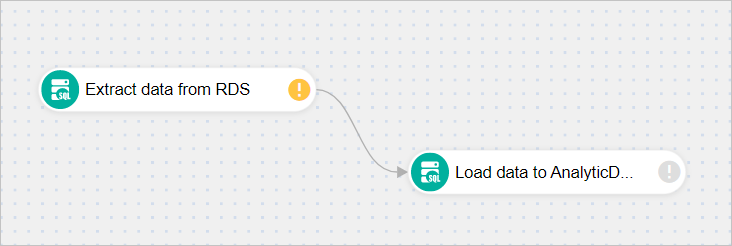
-
ページの下部で、 [Task Flow Information] タブをクリックします。 スケジューリング設定 で、 スケジューリングの有効化 スイッチをオンにします。
-
スケジューリングサイクルを選択します。 ApsaraDB RDS for PostgreSQL からデータを抽出するタスクと、AnalyticDB for PostgreSQL にデータをロードするタスクは、各サイクルで実行されます。
[Basic Properties] セクションで、 [Error Handling Policy] を [Complete running tasks] に、 [Concurrency Control Policy] を [Skip] に設定します。 [Scheduling Settings] セクションで、 [Enable Scheduling] スイッチをオンにし、 [Scheduling Type] を [Periodic Scheduling] に、 [Scheduling Cycle] を [Hour] に設定します。 [Scheduled Time] では、開始時刻を
00:00に、間隔を1に、終了時刻を23:59に設定します。 対応する cron 式は00 00 00-23/1 * * ?です。
-
-
画面左上の トライアル実行 をクリックします。
-
テスト実行が成功したら、 公開 をクリックします。