AnalyticDB for MySQL は、標準 SQL を使用して非構造化データに対するベクトル検索をサポートします。特徴ベクトルを構造化カラムと併せて格納し、近似最近傍 (ANN) インデックスを作成することで、L2_DISTANCE 関数を用いた類似性クエリを実行できます。別途ベクトルデータベースを導入する必要はありません。
前提条件
クラスターはカーネルバージョン 3.1.4.0 以降で実行されている必要があります。
ベクトルインデックス機能は、カーネルバージョン 3.1.5.16、3.1.6.8、3.1.8.6 以降で実行されているクラスター上でより安定して動作します。
クラスターが上記の安定版マイナーバージョンのいずれかで実行されていない場合、ベクトルインデックス機能を使用する前に、CSTORE_PROJECT_PUSH_DOWN および CSTORE_PPD_TOP_N_ENABLE パラメーターを false に設定してください。
開始する前に、以下の条件を満たしていることを確認してください。
AnalyticDB for MySQL クラスター(V3.1.4.0 以降)が稼働していること
(推奨)ベクトル検索のパフォーマンスを最適化するため、マイナーバージョン 3.1.5.16、3.1.6.8、3.1.8.6 以降が適用されていること
お使いのクラスターが推奨マイナーバージョンではない場合、ベクトル検索を使用する前に、[CSTORE_PROJECT_PUSH_DOWN] および [CSTORE_PPD_TOP_N_ENABLE] パラメーターを [false] に設定してください。 マイナーバージョンを確認するには、「AnalyticDB for MySQL クラスターのバージョンを照会する方法」をご参照ください。 マイナーバージョンをスペックアップするには、テクニカルサポートにご連絡ください。
仕組み
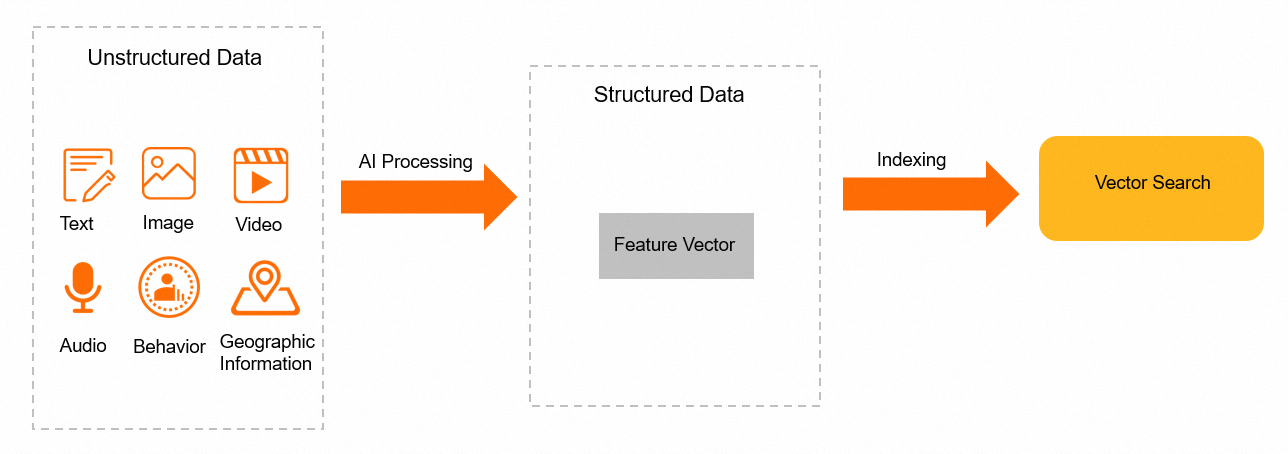
AI モデルを用いて非構造化データから特徴を抽出し、固定長の浮動小数点数配列(特徴ベクトル)として符号化します。これらのベクトルを、構造化カラムと併せて AnalyticDB for MySQL に格納します。
クエリ実行時には、クエリベクトルを L2_DISTANCE 関数に渡します。データベースは、クエリベクトルと各格納済みベクトルとの間の二乗ユークリッド距離を計算し、最も近いマッチを返します。距離値が小さいほど、類似度は高くなります。
全体のワークフローは以下のとおりです。
1 つ以上のベクトルカラム(
ARRAY<FLOAT>、ARRAY<BYTE>、またはARRAY<SMALLINT>)を含むテーブルを作成します。各ベクトルカラムに対して ANN インデックスを追加します。これはテーブル作成時、または
ALTER TABLE文を用いて実行可能です。ベクトル値を含む行を挿入します。
L2_DISTANCEを用いたクエリを実行し、ORDER BY … LIMIT(k 近傍検索)で結果を取得するか、WHERE句に距離しきい値を指定して(半径近傍検索)フィルタリングします。
基本概念
| 用語 | 定義 |
|---|---|
| 特徴ベクトル | ベクトル空間におけるエンティティを表す固定長の数値配列です。2 つのベクトル間の距離は、それらの類似度を測定します。たとえば、512 次元の浮動小数点数配列は人間の顔を表現できます。 |
| ベクトルインデックス(ANN INDEX) | ベクトルカラムに対する近似最近傍検索を高速化する専用インデックスです。 |
| k 近傍検索(KNN) | クエリベクトルに最も近い *k* 個の行を返します。ORDER BY l2_distance(...) LIMIT k を使用します。 |
| 半径近傍検索(RNN) | クエリベクトルからの距離が指定されたしきい値以内にあるすべての行を返します。WHERE l2_distance(...) < threshold を使用します。 |
| L2_DISTANCE | 二乗ユークリッド距離を計算する SQL 関数です。(x₁−y₁)² + (x₂−y₂)² + … + (xₙ−yₙ)²。値が小さいほど、ベクトル間の類似度は高くなります。 |
シナリオ
AnalyticDB for MySQL のベクター分析は、以下のシナリオで一般的に使用されます。
イメージ検索:画像を用いて類似する画像を検索します。
音声照合:音声ファイルを用いて類似する音声を検索します。
テキスト検索:テキスト文字列を用いて類似するテキストを検索します。
プロダクトイメージ検索:多数の画像から、同一のプロダクトを含む画像を検索します。
ベクトル分析モード
AnalyticDB for MySQL ベクター分析では、ロスレスモードと若干ロスありモードの 2 つのモードがサポートされています。適切なモードは、お客様のシナリオによって異なります。ロスレスモードでは、データの取得率が 100% 保証されます。若干ロスありモードでは、AnalyticDB for MySQL がベクターに対してインデックスを構築します。このインデックス構築により、取得率はわずかに低下しますが、99% 以上を維持します。お客様のビジネス シナリオに適したモードを選択するには、以下の表を参照してください。
シナリオ | データ量 | QPS | ベクター分析 モード | 取得率 |
| 数百万件 | 100 QPS | ロスレスモード | 100 % |
| 数億 | 1,000 QPS | ややロスありモード | 99 % |
アーカイブデータベース | 数百万件 | 100 QPS | ややロスありモード | 99 % |
Create a table with a vector index
ベクトルカラムは ARRAY<FLOAT>、ARRAY<BYTE>、または ARRAY<SMALLINT> として定義し、同じ CREATE TABLE 文内で ANN INDEX 宣言を追加します。
構文:
ANN INDEX [index_name] (column_name) [algorithm=HNSW_PQ] [distancemeasure=SquaredL2]| パラメーター | 説明 |
|---|---|
index_name | インデックス名です。「命名制限」をご参照ください。 |
column_name | ベクトルカラム名です。サポートされるデータの型は ARRAY<FLOAT>、ARRAY<BYTE>、ARRAY<SMALLINT> です。「命名制限」をご参照ください。 |
algorithm | HNSW_PQ(階層的ナビゲーブル・スモールワールド+積量子化)を指定します。このアルゴリズムのみがサポートされています。 |
distancemeasure | SquaredL2(二乗ユークリッド距離)を指定します。この距離メトリックのみがサポートされています。計算式:(x₁−y₁)² + (x₂−y₂)² + … + (xₙ−yₙ)²。 |
例:
以下のステートメントでは、vector という名前のテーブルを作成し、2 つのインデックス付きベクトルカラム(float_feature(ARRAY<FLOAT>、4 次元)および short_feature(ARRAY<SMALLINT>、4 次元))を定義しています。
CREATE TABLE vector (
xid bigint not null,
cid bigint not null,
uid varchar not null,
vid varchar not null,
wid varchar not null,
float_feature array < float >(4),
short_feature array < smallint >(4),
ANN INDEX idx_short_feature(short_feature),
ANN INDEX idx_float_feature(float_feature),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);既存テーブルへのベクトルインデックスの追加
既存テーブルのカラムに ANN インデックスを追加するには、ALTER TABLE を使用します。
構文:
CREATE TABLE vector (
xid BIGINT not null,
cid BIGINT not null,
uid VARCHAR not null,
vid VARCHAR not null,
wid VARCHAR not null,
float_feature array < FLOAT >(4),
short_feature array < SMALLINT >(4),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);例:
以下のように ANN インデックスなしで作成されたテーブルを想定します。
CREATE TABLE vector (
xid BIGINT not null,
cid BIGINT not null,
uid VARCHAR not null,
vid VARCHAR not null,
wid VARCHAR not null,
float_feature array < FLOAT >(4),
short_feature array < SMALLINT >(4),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);両方のベクトルカラムにインデックスを追加します。
ALTER TABLE vector ADD ANN INDEX idx_float_feature(float_feature);
ALTER TABLE vector ADD ANN INDEX idx_short_feature(short_feature);ALTER TABLE table_name ADD ANN INDEX [index_name] (column_name) [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]ベクトルデータのクエリ
以下のすべての例では、クエリベクトルとの類似度に基づき行を並べ替えるために L2_DISTANCE を使用しています。
サンプルデータの挿入:
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (1,2,'A','B','C','[1,1,1,1]','[1.2,1.5,2,3.0]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (2,1,'e','v','f','[2,2,2,2]','[1.5,1.15,2.2,2.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (0,6,'d','f','g','[3,3,3,3]','[0.2,1.6,5,3.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','b','h','[4,4,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (8,5,'Sj','Hb','Dh','[5,5,5,5]','[1.3,4.5,6.9,5.2]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'x','g','h','[3,4,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','r','k','[6,6,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'s','i','q','[2,2,4,4]','[1.0,4.15,6,2.9]');KNN:上位 k 個の最近傍を返す
short_feature カラムにおいて、[1,1,1,1] に最も近い 3 行を返します。
SELECT xid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector ORDER BY 2 LIMIT 3;結果:
+-------+--------------+
| xid | dis |
+-------+--------------+
| 1 | 0.0 |
+-------+--------------+
| 2 | 4.0 |
+-------+--------------+
| 0 | 16.0 |
+-------+--------------+構造化フィルターを伴う KNN
xid = 5 かつ cid = 4 を満たす、最も近い 4 行を返します。
SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector WHERE xid = 5 AND cid = 4 ORDER BY 2 LIMIT 4;結果:
+-------+--------------+
| uid | dis |
+-------+--------------+
| s | 20.0 |
+-------+--------------+
| x | 31.0 |
+-------+--------------+
| j | 36.0 |
+-------+--------------+
| j | 68.0 |
+-------+--------------+RNN:距離しきい値によるフィルター
距離が 50.0 未満であり、かつ xid = 5 を満たす最大 3 行を返します。
SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector WHERE l2_distance(short_feature, '[1,1,1,1]') < 50.0 AND xid = 5 ORDER BY 2 LIMIT 3;結果:
+-------+---------------+
| uid | dis |
+-------+---------------+
| s | 20.0 |
+-------+---------------+
| x | 31.0 |
+-------+---------------+
| j | 36.0 |
+-------+---------------+ベクトルインデックスの削除
構文
ベクトルインデックスの削除は、カーネルバージョン 3.2.1.0 以降で実行されているクラスターでのみサポートされます。以下のステートメントを用いて、テーブルからベクトルインデックスを削除できます。
ALTER TABLE table_name DROP [ANN] INDEX index_name;例
vector テーブルからベクトルインデックスを削除します。
ALTER TABLE vector DROP ann INDEX idx_short_feature;
ALTER TABLE vector DROP ann INDEX idx_float_feature;ユースケース
画像ベースの検索 — 製品やシーンの画像をベクトルに符号化し、視覚的に類似した結果を検索します。
顔認識 — 顔の埋め込みを格納し、クエリ顔をデータベースと照合します。
音声認証 — 話者の音声埋め込みを比較し、認証または識別を行います。
テキスト検索 — 言語モデルを用いて文を符号化し、意味的に類似した文章を取得します。
パフォーマンス
AnalyticDB for MySQL は、ミリ秒単位のベクトル検索を実現するために、超並列処理(MPP)アーキテクチャを採用しています。512 次元の顔ベクトルを用いたベンチマーク結果は以下のとおりです。
| シナリオ | データ量 | QPS | 応答時間 | 再現率 |
|---|---|---|---|---|
| 高再現率、中程度の負荷 | 100 億件 | 100 | 50 ms | 99% |
| 高スループット | 2 億件 | 1,000 | 1 秒 | 99% |
データベースは、高同時実行数のリアルタイム書き込みをサポートします。挿入後、データは即座にクエリ可能になります。