ジョブリソースグループ内で多数のジョブが同時に実行される場合、それらのジョブはグループが提供可能なリソース量を超えて競合する可能性があります。たとえば、上流のダッシュボードに依存する重大な集約ジョブは、低優先度のデータ同期ジョブよりも先に実行される必要があります — 両方のジョブが同時に待機中であっても同様です。AnalyticDB for MySQL Data Lakehouse Edition (V3.0) では、即座に実行できないジョブをキューに格納し、リソースが利用可能になるまで「送信済み」状態で保持します。優先度付きキューを使用すると、どのジョブがキューの先頭に移動するかを制御できます。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
AnalyticDB for MySQL Data Lakehouse Edition (V3.0) クラスターが V3.1.6.3 以降のバージョンで実行中であること
少なくとも 1 つのジョブが送信済みのジョブリソースグループが存在すること
優先度レベル
利用可能な優先度レベルは 4 つあり、最も高い順に以下のように並びます。
| レベル | 説明 |
|---|---|
| HIGH | ジョブは高優先度キューに入り、すべての低優先度ジョブより先に実行されます。 |
| NORMAL | デフォルトのレベルです。抽出・変換・ロード(ETL)クエリおよび SELECT クエリは、特に設定がない限りこのレベルを使用します。 |
| LOW | ジョブは低優先度キューに入り、NORMAL および HIGH のジョブに対して譲ります。 |
| LOWEST | ジョブは、リソースが利用可能になったときに最後に実行されます。 |
ジョブ優先度の設定
コンソールでの表示
ジョブリソースグループ内のジョブ優先度は、以下のいずれかの方法で確認できます。
ジョブの優先度は、送信前に設定してください。ジョブが「送信済み」状態になると — 実行中かどうかにかかわらず — 優先度を変更することはできません。
設定方法はジョブの種類によって異なります。
| ジョブタイプ | 設定方法 | キー |
|---|---|---|
| XIHE バルク同期並列(BSP) | SQL ヒント | query_priority |
| Spark SQL | SET 文 | spark.adb.priority |
| Spark バッチ | conf パラメーター | spark.adb.priority |
XIHE BSP ジョブ
クエリの直前にヒントを追加します。
/*+ query_priority=<priority_level>*/ <your_query>以下の例では、優先度を HIGH に設定しています。
/*+ query_priority=HIGH*/ SELECT * FROM test_table;Spark SQL ジョブ
同一セッション内で、クエリの前に SET 文を実行します。
SET spark.adb.priority = <priority_level>;
<your_query>以下の例では、優先度を LOW に設定しています。
SET spark.adb.priority = LOW;
SELECT * FROM test_table;Spark バッチジョブ
ジョブ送信ペイロードの conf オブジェクト内に spark.adb.priority を含めます。
{
"comments": [
"-- これは SparkPi の一例です。内容を変更して、ご自身の Spark プログラムを実行してください。"
],
"args": [
"1000"
],
"file": "local:///tmp/spark-examples.jar",
"name": "SparkPi",
"className": "org.apache.spark.examples.SparkPi",
"conf": {
"spark.driver.resourceSpec": "medium",
"spark.executor.instances": 2,
"spark.executor.resourceSpec": "medium",
"spark.adb.priority": "HIGH"
}
}ジョブ優先度の表示
XIHE BSP および Spark SQL ジョブ
AnalyticDB for MySQL コンソール にログインします。
クラスターの左側ナビゲーションウィンドウで、ジョブ開発 > SQL 開発 を選択します。
実行記録 タブで、各ジョブの優先度を確認します。

Spark バッチジョブ
AnalyticDB for MySQL コンソール にログインします。
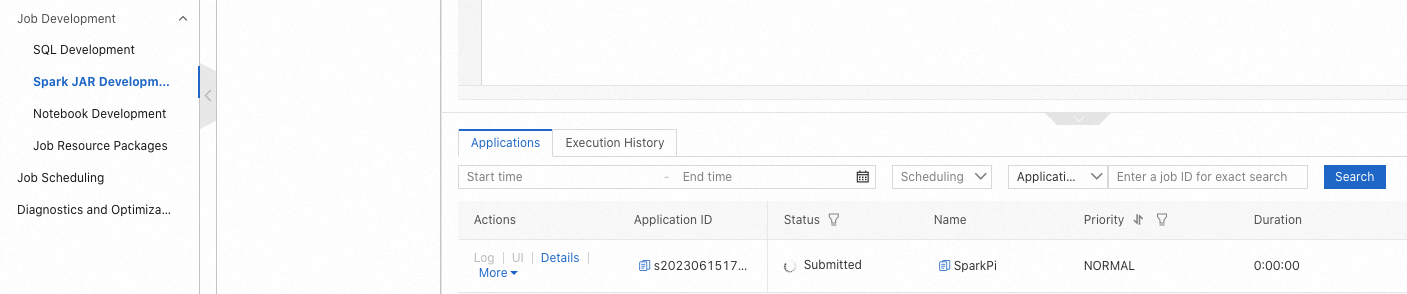
クラスターの左側ナビゲーションウィンドウで、ジョブ開発 > Spark JAR 開発 を選択します。
アプリケーション タブで、各ジョブの優先度を確認します。
SQL を使用した表示
SHOW job status WHERE job = '<JobId>'; 文を実行します。