PAI-Rec のすべてのサービスと実験は、レコメンデーションシナリオに関連付ける必要があります。シナリオは、プラットフォーム上のプレースメントを、一連のラボ、実験レイヤー、実験グループ、および実験にマッピングします。
レコメンデーションシナリオ
レコメンデーションシナリオは、ホームページのウォーターフォール型レコメンデーション、カート内の「おすすめ」提案、商品詳細ページの関連アイテムなど、プラットフォーム上の特定のプレースメントを、一連のレコメンデーションサービスと実験にマッピングします。
各シナリオには、一目で識別できるように、そのページ上の場所に応じた名前を付けます。たとえば、「ホームページのウォーターフォール型レコメンデーション」という名前は、UI パターン (「ウォーターフォール」) とプレースメント (「ホームページ」) の両方を示します。
トラフィックコード
「トラフィックコード」フィールドは、レコメンデーションリクエストをシステム間でどのように分割するかをコントロールします。PAI-Rec を自己管理またはサードパーティのレコメンデーションシステムと並行して実行する場合に使用します。
| トラフィックコードの値 | トラフィックの送信先 |
|---|---|
PAI-REC | PAI-Rec システム |
selfhold | 自己管理のレコメンデーションシステム |
thirdparty | サードパーティのレコメンデーションシステム |
たとえば、HomePageRec シナリオでは、トラフィックはデフォルトで PAI-Rec にルーティングされます。トラフィックを段階的に移行するには、まずシナリオのトラフィックの 10%~20% を PAI-Rec にルーティングすることから始めます。PAI-Rec が期待される結果を達成したら、その割合を増やします。
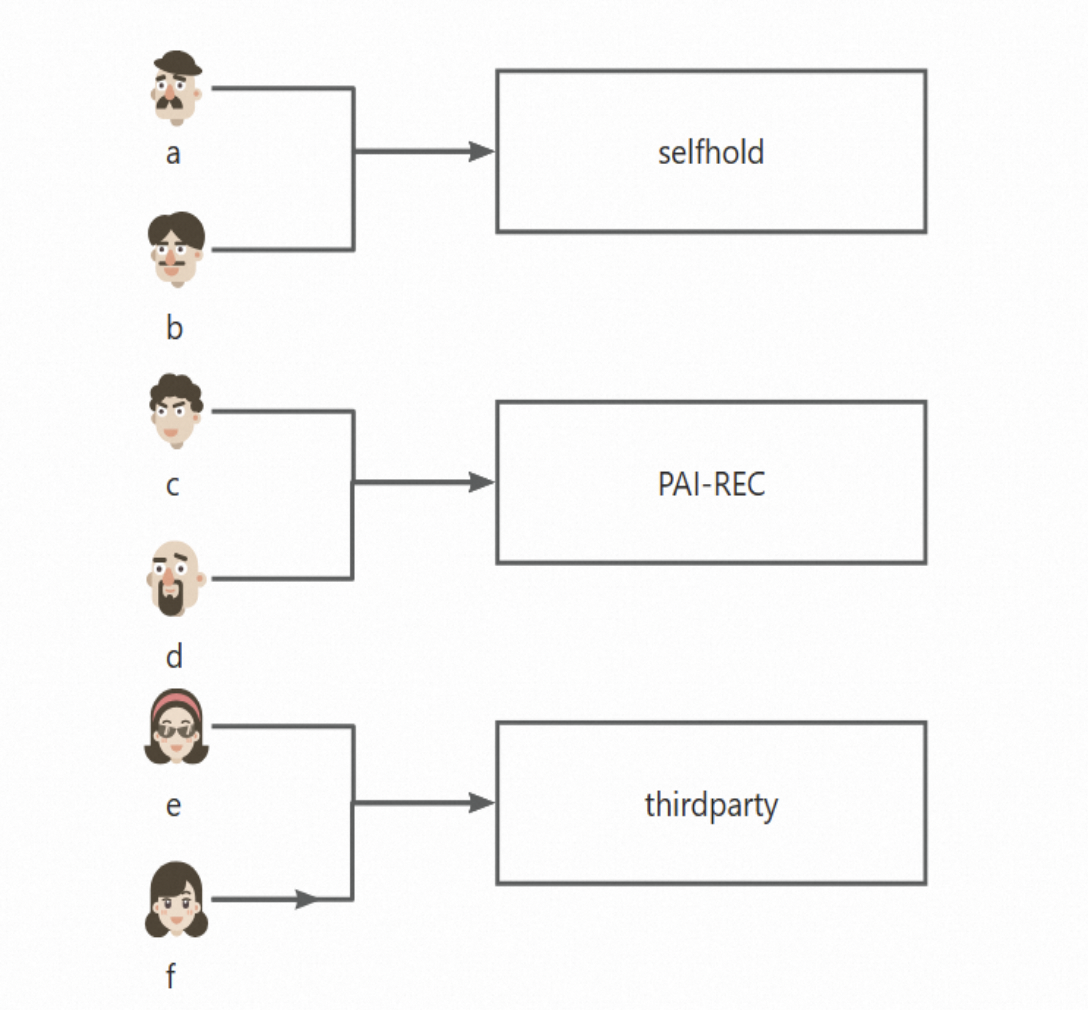
次の図は、6 人のユーザーに対するトラフィックの割り当てを示しています。ユーザー a と b は自己管理システム (selfhold) から、ユーザー c と d は PAI-Rec (PAI-REC) から、ユーザー e と f はサードパーティシステム (thirdparty) から結果を受け取ります。
ラボと実験レイヤー
PAI-Rec は、以下の 4 階層を使用して A/B テストを構成します:
ラボ
└── 実験レイヤー
└── 実験グループ
└── 実験ラボ
ラボはトラフィックのコレクションです。PAI-Rec は、実験のマッチングが行われる前に、受信したレコメンデーションリクエストをラボにルーティングします。
すべてのシナリオには、少なくとも 1 つのベースラボが必要です。トラフィックは最初に非ベースラボにマッチングされます。マッチングする非ベースラボがない場合、リクエストはベースラボにフォールバックします。ラボを 1 つしか作成しない場合は、それをフォールバック用のベースラボとして使用する必要があります。ベースラボは、トラフィックスパイク時にも安定して動作するように、シンプルな再現とランキングのロジックで構成してください。ベースラボは、人気およびランダムフォールバックロジックを使用して実装することもできます。
非ベースラボには、より複雑な主要な再現とランキングのロジックを保持します。異なるアルゴリズム戦略を並行してテストする必要がある場合は、複数の非ベースラボを作成します。
次の図は、ベースラボの構成フィールドを示しています。
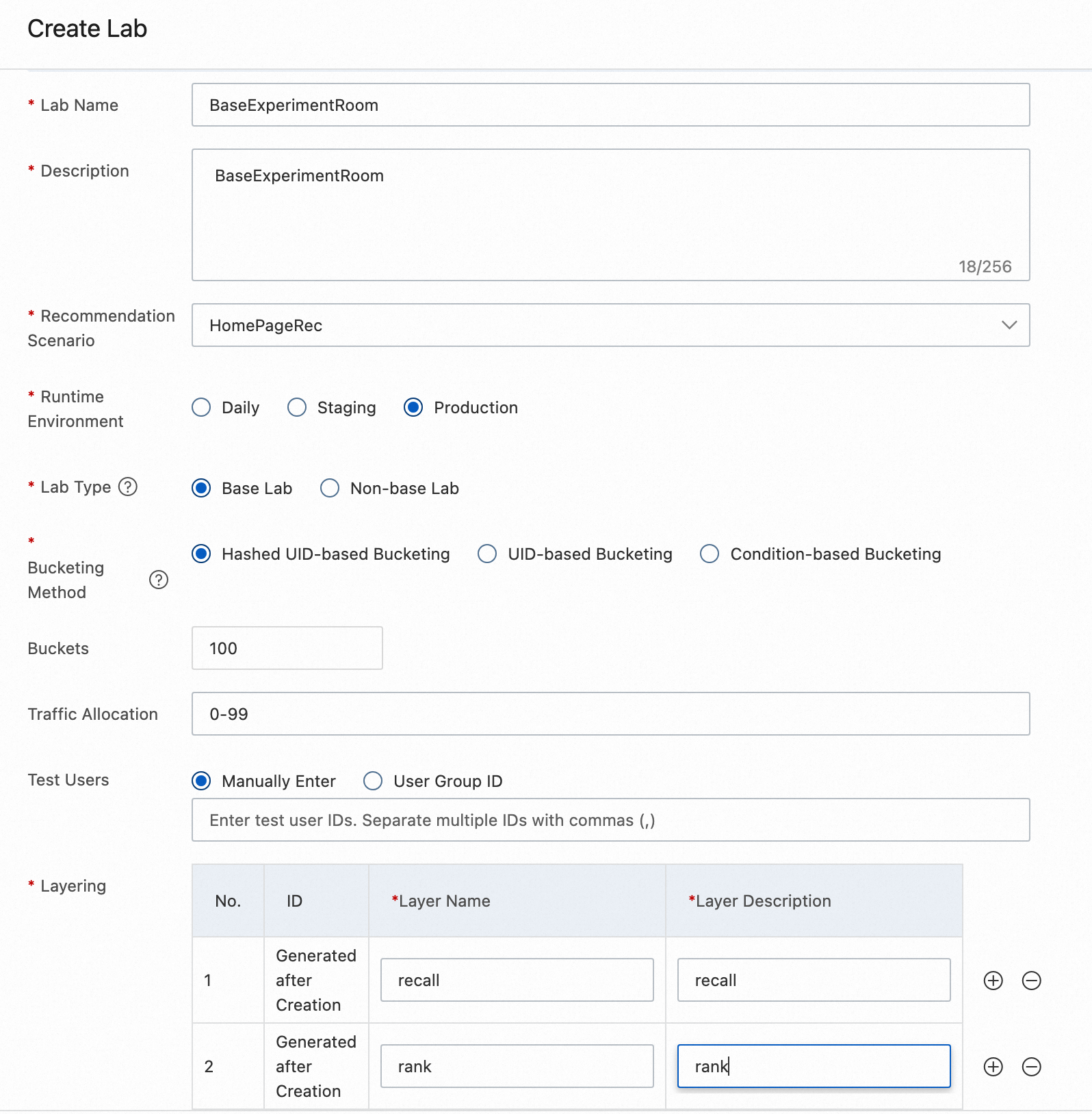
| フィールド | 説明 |
|---|---|
| [ラボ名] | ラボのカスタム名です。 |
| 説明 | ラボの詳細な説明です。 |
| [ラボタイプ] | ベースラボ (必須) または 非ベースラボ (任意) です。 |
| [実行環境] | レコメンデーションエンジンの実行環境です。有効な値:Daily、Staging、Production。 |
| [バケツ化メソッド] | PAI-Rec がユーザーをバケットに割り当てる方法です。詳細は、下記の「バケツ化メソッド」をご参照ください。 |
| [バケット] | このラボのバケット総数です (例:100)。 |
| [トラフィック割り当て] | このラボに割り当てられるバケット番号です。有効範囲:0~99。 |
| [レイヤー化] | このラボ内の実験レイヤーです。一般的な値:recall、filter、coarse_rank、rank。 |
| [テストユーザー] | バケットマッチングをバイパスし、トラフィックがこのラボに直接ルーティングされるユーザーです。 |
[テストユーザー] は 2 つの入力方法をサポートしています:
手動入力: 1 つ以上のユーザー ID をカンマで区切って入力します。
ユーザーグループ ID: [ユーザーグループ管理] ページで作成したユーザーグループを選択します。
バケット分割メソッド
PAI-Rec は、ユーザーをバケットに割り当てる 3 つの方法をサポートしています:
| メソッド | 仕組み |
|---|---|
| UID ベースのバケット分割 | ユーザーの UID の末尾の数字に基づいてユーザーを割り当てます。 |
| ハッシュ化 UID ベースのバケット分割 | ユーザーの UID のハッシュ値に基づいてユーザーを割り当てます。 |
| 条件ベースのバケット分割 | gender=man のようなキーと値の式に基づいてユーザーを割り当てます。 |
実験レイヤー
実験レイヤーは、ラボ内の論理的なグループです。各ラボは複数の実験レイヤーを持つことができます。一般的なレイヤー名には、recall、filter、coarse_rank、rank などがあります。
実験グループと実験
実験グループ
実験グループは、実験レイヤーのサブディビジョンです。複数のアルゴリズムエンジニアが独立して再現またはランキングの実験を実行する必要がある場合は、レイヤー内に複数の実験グループを作成します。
実験
実験は、実験グループ内の単一のアルゴリズムまたは構成のバリエーションです。
実験グループには通常、同時に実行される複数の実験が含まれています。 たとえば、次の図は、2 つのアクティブな実験 (swing と etrec) と、トラフィックの割合を 0% に、状態をオンラインに設定してテスト中の dssm を示しています。 この構成により、設定されたホワイトリストを使用して推奨効果を取得できます。
