説明
機能の一貫性は、アルゴリズムプロジェクトにおける一般的なエンジニアリングの課題であり、モデルのトレーニング中に使用される機能が、オンラインスコアリング中に使用される機能と一致している必要があることを示します。機能の不一致は、モデルがサービスまたはアプリケーションで使用されるときに、スコアリングの不一致とパフォーマンスの低下につながる可能性があります。そのため、機能の不一致によるパフォーマンスの低下を防ぐために、機能の一貫性チェックを定期的に実行することをお勧めします。
機能の一貫性チェックは、オンライン機能とオフライン機能の間で、次の不一致の問題を自動的に識別するために行われます。
オンライン機能の名前がオフライン機能の名前と一致していません。
同じ名前のオンライン機能とオフライン機能のタイプが一致していません。
オンライン機能が欠落しているか、生成されていません。レコメンデーションエンジンにリクエストが送信されたときにコンテキスト機能が欠落しているか、レコメンデーションエンジンが関連するコンテキスト機能を生成できていません。
機能値が一致していません。オンライン機能値の処理ロジックまたはメソッドが、オフライン機能値に使用されるものと一致していません。
モデルの機能処理ロジックが正しくありません。スコアリングの前に、スコアリングサービスとしてデプロイされたEasyRecプロセッサなどのプロセッサが、機能を処理する必要があります。機能処理には、機能の読み込み、デフォルトの機能値の生成、および機能ジェネレーター(FG)モジュールを使用して実装された機能の導出が含まれます。EasyRecプロセッサのデバッグモードを有効にして、生成された機能を取得し、機能をさらに比較できます。
機能比較プロセス
フローチャート
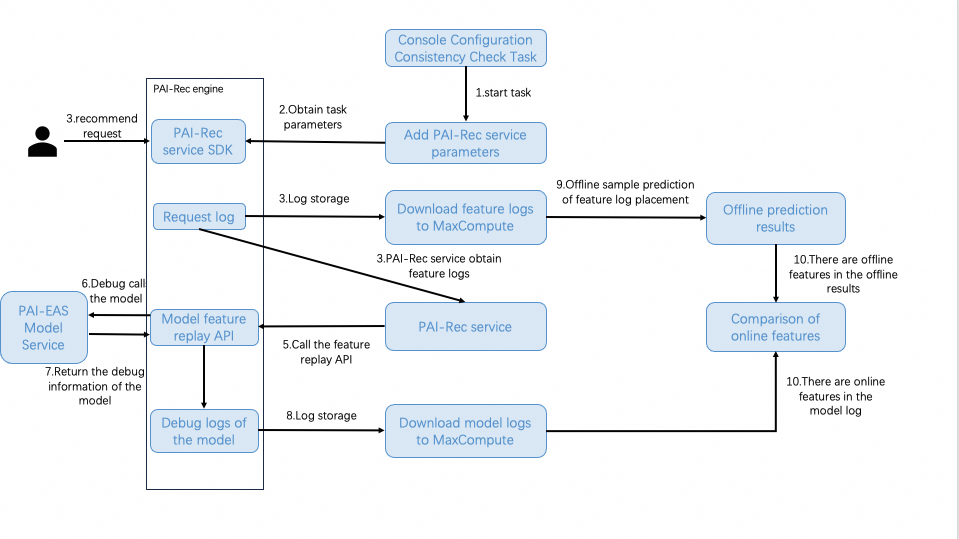
プロセス
ステップ 1:コンソールで機能の一貫性チェックタスクを作成して開始します
PAI-Recコンソールにログインします。左側のナビゲーションペインで、[トラブルシューティングツール] > [一貫性チェック] を選択します。次に、機能の一貫性チェックタスクを作成して開始します。
タスクを開始すると、PAI-Recはタスク構成に基づいてタスクの実行に必要なリソースをチェックして作成します。リソースは、機能ログとモデルログを処理するために使用されます。リソースが作成されると、PAI-Recコンソールの [パラメーター管理] ページにサービスパラメーターが追加されます。タスクが開始されます。
ステップ 2:PAI-Recエンジンがタスクパラメーターを取得します
PAI-Recエンジンは、PAI-Rec SDKを使用して開始されたタスクのパラメーターを取得することにより、最新のサービスパラメーターを取得します。
ステップ 3:PAI-Recエンジンが機能ログをMaxComputeに保存し、PAI-Recが機能ログを取得します。
PAI-Recエンジンがタスクパラメーターを取得した後、PAI-Recエンジンはサービスプロセス中に生成された機能ログをMaxComputeに保存します。
同時に、PAI-Recは機能ログを取得します。
ステップ 4:PAI-RecがPAI-Recエンジンの機能リプレイインターフェースを呼び出します
PAI-Recが機能ログを取得すると、PAI-Recは、取得した機能ログとタスクに指定されたサンプリング比率に従って、バッチでPAI-Recエンジンの機能リプレイインターフェースを呼び出します。機能リプレイとは、取得した機能ログを使用して、モデル サービスのデバッグモードを有効にするために使用されるPAI-Recエンジンのインターフェースを呼び出すことを指します。
ステップ 5:PAI-RecエンジンがEASにデプロイされたモデルサービスを呼び出します
リクエストを受信すると、PAI-RecエンジンはElastic Algorithm Service(EAS)にデプロイされたモデルサービスをデバッグモードで呼び出します。このプロセスでは、モデルに関するデバッグ情報が生成されます。これには、機能生成フェーズの前後のすべての機能情報が含まれています。
ステップ 6:モデルに関するデバッグ情報が返されます
EASにデプロイされたモデルサービスに関するデバッグ情報は、PAI-Recエンジンに返され、モデルデバッグログが生成されます。
ステップ 7:デバッグログが保存されます
PAI-Recエンジンによって生成されたモデルデバッグログは、MaxComputeに保存されます。
ステップ 8:機能ログに基づいて予測が実行されます
MaxComputeからの機能ログは、予測のオフラインサンプルデータとして使用されます。
ステップ 9:オンライン機能とオフライン機能が比較されます
MaxComputeのモデルログが取得された後、モデルログのオンライン機能とオフライン予測結果のオフライン機能が比較され、タスク結果が生成されます。
使用上の注意
1. 機能の一貫性チェックタスクを構成する
前提条件
機能整合性チェックタスクを構成する前に、モデルサービスがデプロイされている MaxCompute と EAS を含む、必要なデータソースを追加する必要があります。結果をオブジェクトストレージサービス(OSS)にエクスポートする場合は、OSS データソースを追加する必要があります。
データソースの追加方法の詳細については、「メタデータの管理」をご参照ください。
手順
左側のナビゲーションペインで、[一貫性チェック] をクリックします。表示されるページで、タスクを作成するか、既存のタスクを変更します。
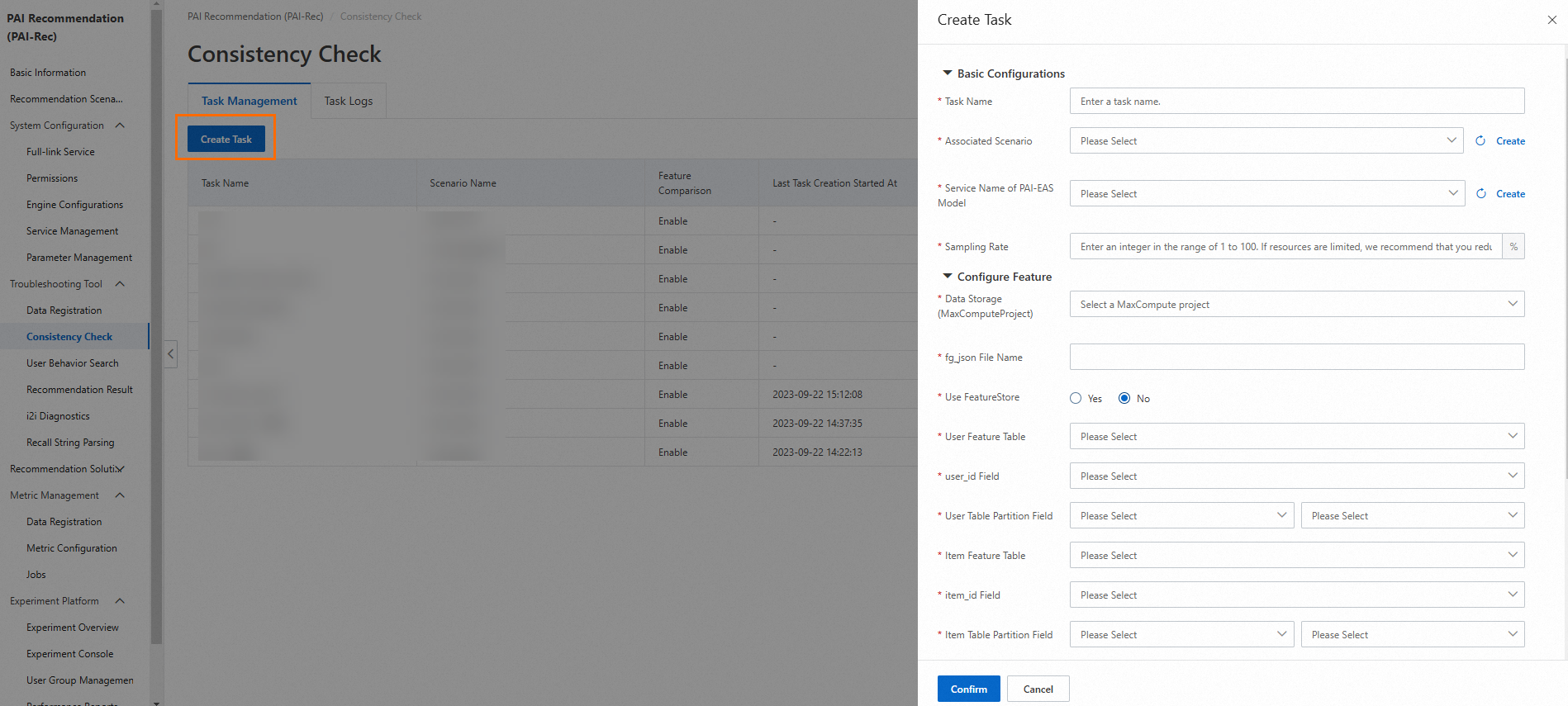
次のセクションでは、機能の一貫性チェックタスクのパラメーターについて説明します。
タスク名:カスタムタスク名を入力します。
関連付けられたシナリオ:ドロップダウンリストから、タスクに関連付けるレコメンデーションシナリオを選択します。選択したシナリオは、エンジン構成で指定されたシナリオとリクエストパラメーターで指定されたシナリオと同じである必要があります。
サンプリングレート:サンプリングするデータの比率を指定します。最大値: 100%。サンプリングレートを小さくすると、エンジンに送信される1秒あたりのクエリ数(QPS)を減らすことができます。たとえば、[サンプリングレート] を 10% に設定すると、QPSは 10 になり、1秒あたり1つのレコメンデーションリクエストログのみがサンプリングされます。
データストレージ(MaxComputeProject):ドロップダウンリストからMaxComputeプロジェクトを選択してデータを保存します。
PAI-EASモデルのサービス名:EASにデプロイされたモデルサービスの名前。モデル関連のデータとログが保存されているOSSパスやアルゴリズム名など、モデルからいくつかのパラメーターを取得する必要があります。
fg_jsonファイル名:MaxComputeプロジェクトでモデルのトレーニングに使用されるfg_jsonファイルの名前。
ユーザー機能テーブル:必要なユーザー機能を格納するテーブルを選択します。
user_idフィールド:[ユーザー機能テーブル] パラメーターで指定されたテーブルのuser_idフィールド。これはテーブルの主キーでもあります。
ユーザーテーブルパーティションフィールド:日付(文字列)フィールドを選択します。フィールドは、yyyymmdd および yyyy-mm-dd の形式で表示できます。ドロップダウンリストから1つ選択します。
アイテム機能テーブル:必要なアイテム機能を格納するテーブルを選択します。
item_idフィールド:[アイテム機能テーブル] パラメーターで指定されたテーブルのitem_idフィールド。これはテーブルの主キーでもあります。
アイテムテーブルパーティションフィールド:日付(文字列)フィールドを選択します。フィールドは、yyyymmdd および yyyy-mm-dd の形式で表示できます。ドロップダウンリストから1つ選択します。
機能比較:デフォルトでは、[はい] が選択されています。[いいえ] を選択すると、モデルの詳細は表示されません。
レコメンデーションサービス名:ログリプレイに使用するレコメンデーションサービスの名前を選択します。サービス管理 ページで名前を確認できます。
ZIPパッケージ:デフォルトでは、[いいえ] が選択されています。これは、ZIPパッケージが生成されないことを示します。ZIPパッケージを生成する場合は、[はい] を選択し、必要なパラメーター(OSSバケット、ワークフロー名、カスタムEasyRecバージョン、カスタムEasyRecパッケージパス、カスタムfg_jarパッケージ名、機能の優先順位、機能表示フィルタリングを含む)を構成します。次に、[確認] をクリックします。
注:機能の一貫性チェックタスクを作成する前に、ユーザーテーブルとアイテムテーブルに当日のデータが格納されていることを確認してください。
2. タスクを実行して結果を表示する
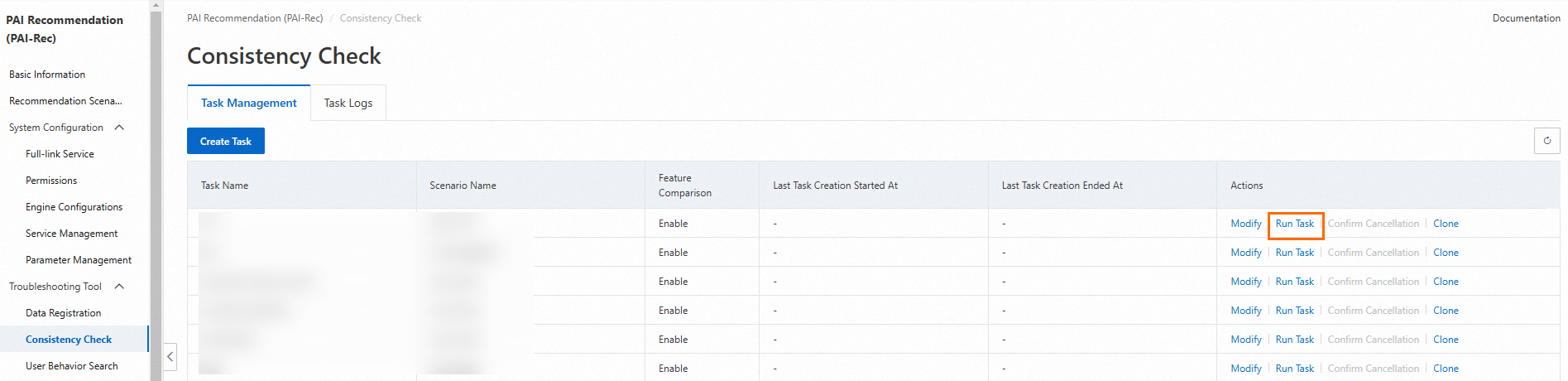
タスクを実行する
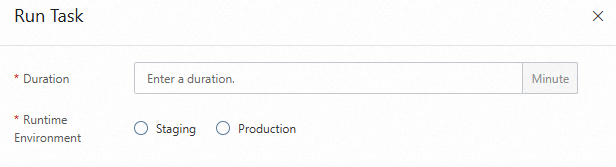
[一貫性チェック] ページで、タスクの [アクション] 列の [タスクの実行] をクリックします。表示されるパネルで、[期間] と [ランタイム環境] パラメーターを構成し、[確認] をクリックします。[ランタイム環境] パラメーターの有効な値は、ステージングと本番です。その後、タスクが完了するまで待機するか、タスクをキャンセルできます。
結果を表示する
[タスクログ] タブで、タスクの実行ステータスを表示します。ほとんどの場合、実際のタスクの実行時間は、指定された時間よりも長くなります。これは、データの同期と最終的なデータ分析に追加の時間がかかるためです。
タスクが実行された後、[アクション] 列の [結果の確認] をクリックしてタスク結果を表示します。
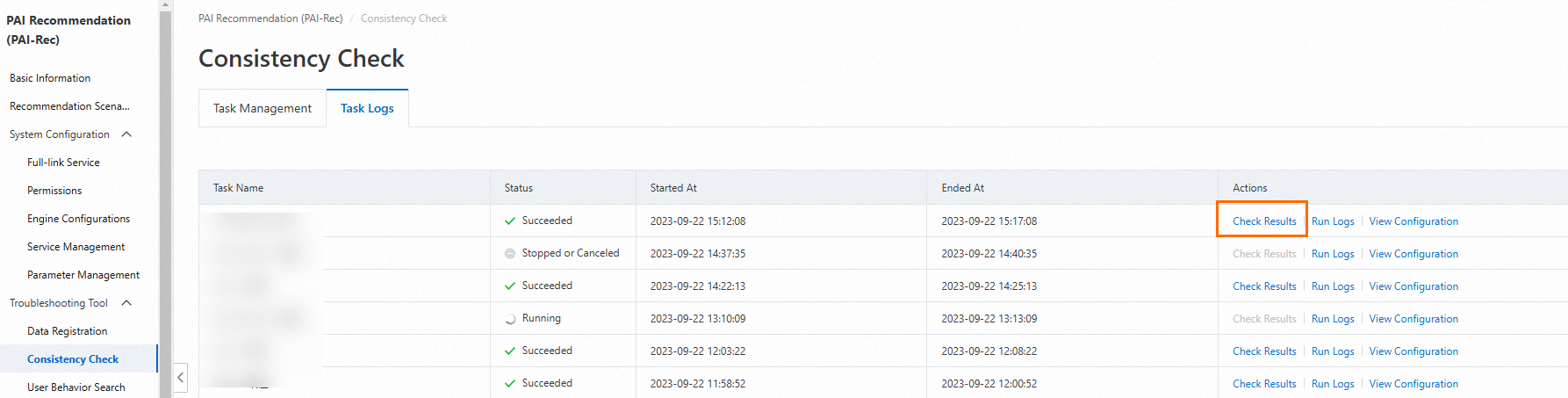
結果には、UserId、ItemId、RequestId、およびScoreDiff(差分の降順でソート)の情報が含まれています。[アクション] 列の [機能比較] をクリックして、機能の違いを表示できます。
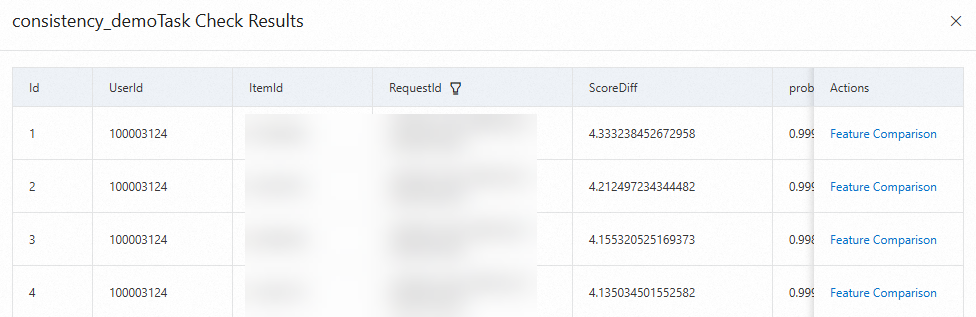
注:item_idフィールドの場合、[OnlineValue] 列の値が「-1024」の場合、有効なアイテムIDが取得されていないことを示します。titleやauthorなどのフィールドの場合、[OnlineValue] 列の値はデフォルト値です。
リクエストIDの結果が正常であることを確認した場合は、RequestIdの横にあるフィルターアイコンをクリックし、リクエストIDを選択して、[OK] をクリックすると、リクエストIDの結果を除外できます。

3. 結果をインポートする
タスクの作成時に [詳細設定] セクションのパラメーターを構成すると、生成されたタスクファイルは指定されたOSSバケットにZIPパッケージとして保存されます。
次のセクションでは、圧縮ZIPパッケージをDataWorksにアップロードしてタスクを手動で実行する方法について説明します。
OSSに保存されている圧縮ZIPパッケージをローカルコンピューターにダウンロードします。
DataWorksコンソールにログインし、次の図に示すようにボタンを順番にクリックします。
[DataWorks 内の移行] > [DataWorks インポート] を選択します。
ページの右上隅にある [インポートタスクの作成] をクリックします。インポート タスクの作成
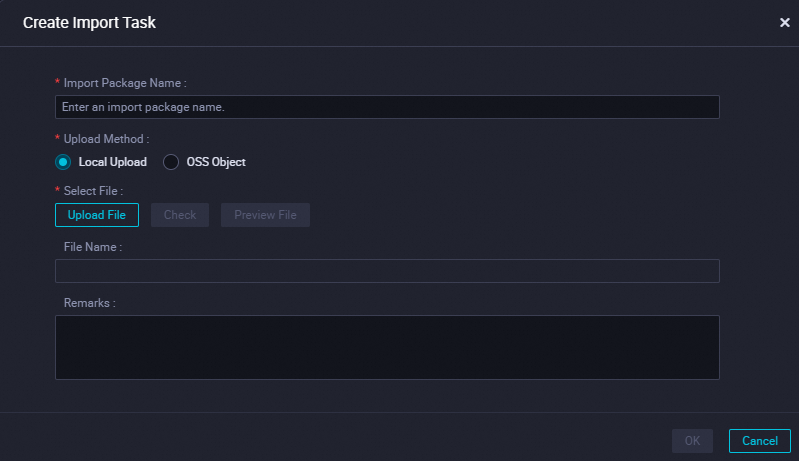
カスタム名を入力し、[ファイルのアップロード] をクリックしてZIPパッケージをアップロードし、[OK] をクリックします。
タスクファイルが存在するフォルダーは、[ワークフロー名] パラメーターで指定されたワークフローにあります。ワークフロー名