Knative Pod Autoscaler(KPA)は、同時実行数または 1 秒あたりのリクエスト数(RPS)に基づいて Pod を自動的にスケーリングします。デフォルトでは、アイドル状態になると Pod はゼロにスケールダウンします。本トピックでは、同時実行数の目標値、スケーリングの上下限、およびゼロへのスケールダウン動作を含む KPA のスケーリングパラメーターの設定方法について説明します。
前提条件
Knative がクラスターにデプロイ済みである必要があります。詳細については、「Knative のデプロイ」をご参照ください。
仕組み
Knative Serving は、各 Pod に queue-proxy という名前のキュー・プロキシコンテナーを挿入します。このコンテナーは、アプリケーションコンテナーの同時実行数に関するメトリックをオートスケーラーに報告します。オートスケーラーはこれらのメトリックと対応するアルゴリズムを用いて Deployment の Pod 数を調整し、自動スケーリングを実現します。

KPA の構成
一部の構成は、アノテーションを用いて Revision レベルで有効化することも、ConfigMap を通じてグローバルに適用することもできます。両方を構成した場合、Revision レベルの構成がグローバル構成よりも優先されます。
config-autoscaler の構成
KPA を構成するには、config-autoscaler ConfigMap を構成する必要があります。この ConfigMap はデフォルトで構成済みです。以下では、その主要なパラメーターについて説明します。
以下のコマンドを実行して、config-autoscaler ConfigMap を表示します。
kubectl -n knative-serving describe cm config-autoscaler以下は、config-autoscaler ConfigMap のデフォルト設定です。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
# デフォルトの Pod あたり最大同時実行数。デフォルト値は 100。
container-concurrency-target-default: "100"
# 同時実行数の目標利用率。デフォルト値は 70(70% を意味する)。
container-concurrency-target-percentage: "70"
# デフォルトの 1 秒あたりのリクエスト数(RPS)。デフォルト値は 200。
requests-per-second-target-default: "200"
# ターゲットバースト容量パラメーターは、トラフィックバーストを処理し、アプリケーションコンテナーの過負荷を防ぎます。デフォルト値は 211 です。これは、サービスのターゲットしきい値と準備完了状態の Pod 数の積が 211 より小さい場合、リクエストが Activator を経由してルーティングされることを意味します。
# Activator はリクエストバッファーとして機能します。このパラメーターの計算結果によって、リクエストが Activator コンポーネントを通過するかどうかが決定されます。
# この値が 0 の場合、Pod がゼロにスケールダウンしたときにのみリクエストが Activator に切り替わります。
# この値が 0 より大きく、container-concurrency-target-percentage が 100 に設定されている場合、リクエストは常に Activator を経由します。
# この値が -1 の場合、リクエストのバースト容量は無限大であることを示します。リクエストは常に Activator を経由します。その他の負の値は無効です。
# (準備完了状態の Pod 数 × 最大同時実行数)− ターゲットバースト容量 − Panic モードで計算された同時実行数 < 0 の場合、トラフィックバーストが容量しきい値を超えています。システムは、リクエストバッファーのために Activator に切り替わります。
target-burst-capacity: "211"
# Stable ウィンドウ。デフォルト値は 60 秒です。
stable-window: "60s"
# Panic ウィンドウの割合。デフォルト値は 10(つまり、デフォルトの Panic ウィンドウは 6 秒(60 × 0.1 = 6))です。
panic-window-percentage: "10.0"
# Panic 閾値の割合。デフォルト値は 200 です。
panic-threshold-percentage: "200.0"
# 最大スケールアップ率。これは、単一のスケールアウトイベントで作成される最大 Pod 数を示します。実際の計算式は:math.Ceil(MaxScaleUpRate × readyPodsCount) です。
max-scale-up-rate: "1000.0"
# 最大スケールダウン率。デフォルト値は 2 であり、各スケールイン時に Pod の半分が削除されることを意味します。
max-scale-down-rate: "2.0"
# ゼロへのスケーリングを有効にするかどうかを指定します。デフォルトで有効です。
enable-scale-to-zero: "true"
# ゼロへのスケーリングの猶予期間。これは、ゼロへのスケーリングが実行されるまでの遅延時間です。デフォルトは 30 秒です。
scale-to-zero-grace-period: "30s"
# ゼロへのスケーリング時の Pod 保持期間。このパラメーターは、Pod の起動コストが高い場合に有用です。
scale-to-zero-pod-retention-period: "0s"
# オートスケーラープラグインの種類。サポートされるプラグインには、KPA、HPA、および AHPA があります。
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
# Activator のリクエスト容量。
activator-capacity: "100.0"
# Revision 作成時に初期化される Pod 数。デフォルトは 1 です。
initial-scale: "1"
# Revision 作成時にゼロ個の Pod を初期化することを許可するかどうかを指定します。デフォルトは false(許可しない)です。
allow-zero-initial-scale: "false"
# Revision レベルで保持する最小 Pod 数。デフォルトは 0(最小値を 0 に設定可能)です。
min-scale: "0"
# Revision がスケールアウト可能な最大 Pod 数。デフォルトは 0(上限なし)です。
max-scale: "0"
# スケールダウンの遅延時間。デフォルトは 0 秒(すなわち、即座にスケールダウン)です。
scale-down-delay: "0s"メトリックの構成
autoscaling.knative.dev/metric アノテーションを用いて、各 Revision のメトリックを構成できます。異なるオートスケーラープラグインでは、サポートされるメトリックの構成が異なります。
サポートされるメトリック:
"concurrency"、"rps"、"cpu"、"memory"、およびその他のカスタムメトリック。デフォルトのメトリック:
"concurrency"。
ターゲットしきい値の構成
autoscaling.knative.dev/target アノテーションを用いて、各 Revision のターゲットしきい値を構成します。グローバルなターゲットしきい値を設定するには、ConfigMap 内の container-concurrency-target-default アノテーションを使用します。
Revision レベル
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
# Revision レベルでスケーリングのターゲットしきい値を 50 に設定します。
autoscaling.knative.dev/target: "50"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56グローバルレベル
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"ゼロへのスケーリングの構成
グローバル構成によるゼロへのスケールインの制御
enable-scale-to-zero パラメーターは "false" または "true" に設定できます。これは、アイドル状態のときに Knative サービスが自動的にゼロレプリカにスケールダウンするかどうかを指定します。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false" # 値が "false" の場合、オートスケーリング機能は無効化され、アイドル状態のときに Knative サービスはゼロレプリカに自動的にスケールダウンしません。グローバルなゼロへのスケールダウン猶予期間の構成
scale-to-zero-grace-period パラメーターは、Knative サービスがゼロレプリカにスケールダウンするまでの待機時間を指定します。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-grace-period: "40s"ゼロへのスケーリング時の Pod 保持期間
Revision レベル
autoscaling.knative.dev/scale-to-zero-pod-retention-period アノテーションは、サービスが一定時間アイドル状態になった後に Pod を保持する期間を指定します。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56グローバルレベル
scale-to-zero-pod-retention-period キーは、Knative サービスがゼロレプリカにスケールダウンする前に Pod を保持する期間を指定します。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-pod-retention-period: "42s"同時実行数の構成
同時実行数とは、単一の Pod が同時に処理できるリクエストの最大数です。ソフト制限、ハード制限、目標利用率、および 1 秒あたりのリクエスト数(RPS)の構成を用いて、同時実行数を設定できます。
ソフト制限の構成
ソフト制限は、厳密な境界ではなく、目標値です。リクエストの急増など、特定の状況下では、この値を超えることがあります。
Revision レベル
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "200"グローバルレベル
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200" # Knative サービスのデフォルトコンテナー同時実行数ターゲットを指定します。
ハード制限の構成(Revision レベル)
アプリケーションが同時実行実行数の明確な上限を持つ場合にのみ、ハード制限の構成を使用してください。低いハード制限を指定すると、アプリケーションのスループットおよびレイテンシーに悪影響を及ぼす可能性があります。
ハード制限は、必須の上限値です。同時実行数がハード制限に達すると、余剰のリクエストは queue-proxy または Activator によってバッファーされます。その後、処理可能なリソースが十分に確保された時点で処理されます。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56
containerConcurrency: 50目標利用率
目標利用率の値は、同時実行数のしきい値を調整します。この値は、定義された同時実行数制限の目標利用率の割合を指定します。この機能は、リソースのプリフェッチとも呼ばれます。定義されたハード制限にリクエストが到達する前に、スケールアウトを実行できます。
たとえば、containerConcurrency が 10 に設定され、目標利用率が 70% に設定されている場合、既存のすべての Pod の平均同時実行リクエスト数が 7 に達すると、オートスケーラーは新しい Pod を作成します。Pod の作成および準備完了には時間がかかるため、目標利用率の値を下げることで、より早期に Pod のスケールアウトを開始できます。これにより、応答レイテンシーの低減やコールドスタートによる問題の軽減が期待できます。
Revision レベル
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target-utilization-percentage: "70" # Knative サービスのオートスケーリング機能を構成し、目標リソース利用率の割合を指定します。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56グローバルレベル
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-percentage: "70" # Knative は、各 Pod の同時実行数が現在利用可能なリソースの 70% を超えないように保つよう試みます。1 秒あたりのリクエスト数(RPS)の構成
RPS とは、単一の Pod が 1 秒間に処理できるリクエストの数です。
Revision レベル
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "150"
autoscaling.knative.dev/metric: "rps" # このサービスのオートスケーリングが、1 秒あたりのリクエスト数(RPS)に基づいてレプリカ数を調整することを示します。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56グローバルレベル
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
requests-per-second-target-default: "150"シナリオ 1:同時実行リクエスト数を設定して自動スケーリングを有効化する
Knative Pod Autoscaler(KPA)を用いて、同時実行リクエスト数を設定することで自動スケーリングを有効化できます。
autoscale-go.yaml ファイルを作成し、クラスターにデプロイします。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" # 現在の同時実行リクエスト数の最大値を 10 に設定します。 spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yamlサービスアクセスゲートウェイを取得します。
ALB
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl get albconfig knative-internet想定される出力:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl -n knative-serving get ing stats-ingress想定される出力:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"想定される出力:
121.XX.XX.XXKourier
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl -n knative-serving get svc kourier想定される出力:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49mHey ストレステストツールを用いて、30 秒間 50 件の同時リクエストを維持します。
説明Hey ストレステストツールの詳細については、「Hey」をご参照ください。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX はゲートウェイの IP アドレスです。想定される出力:
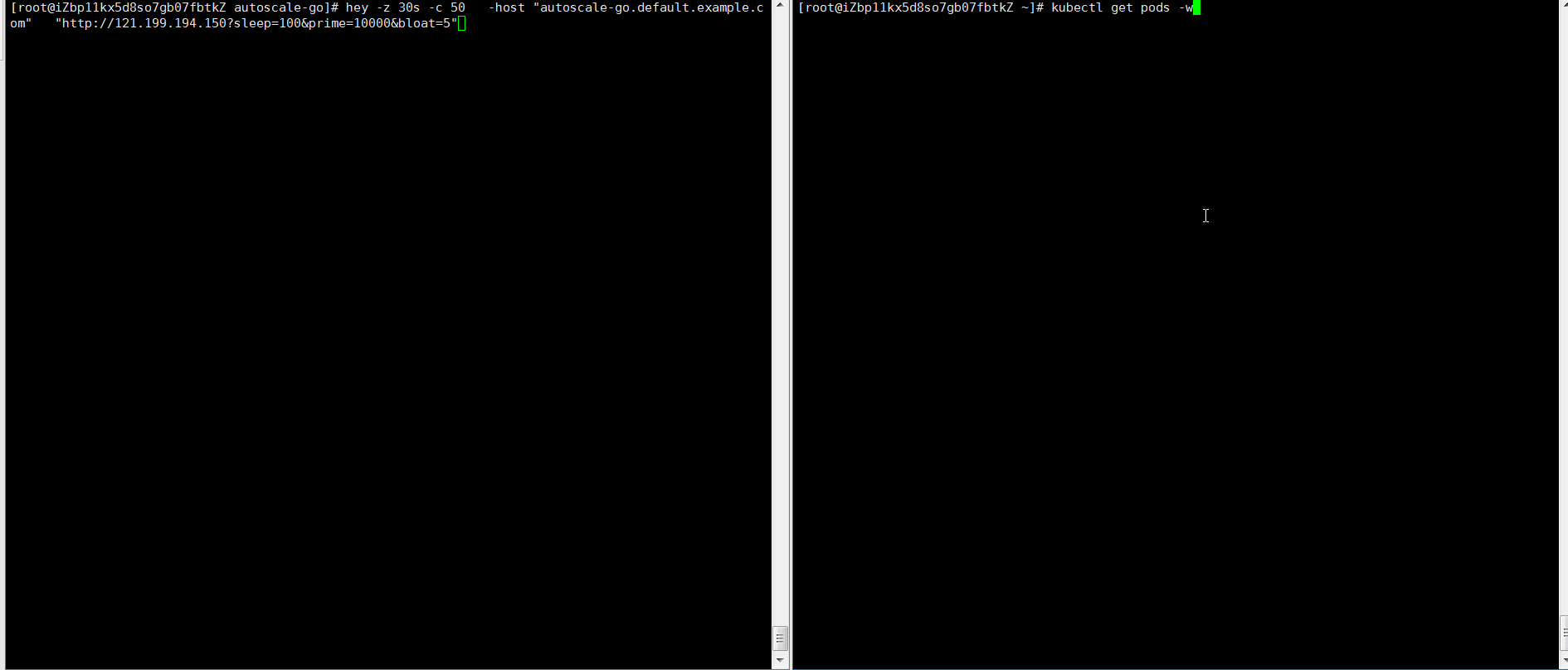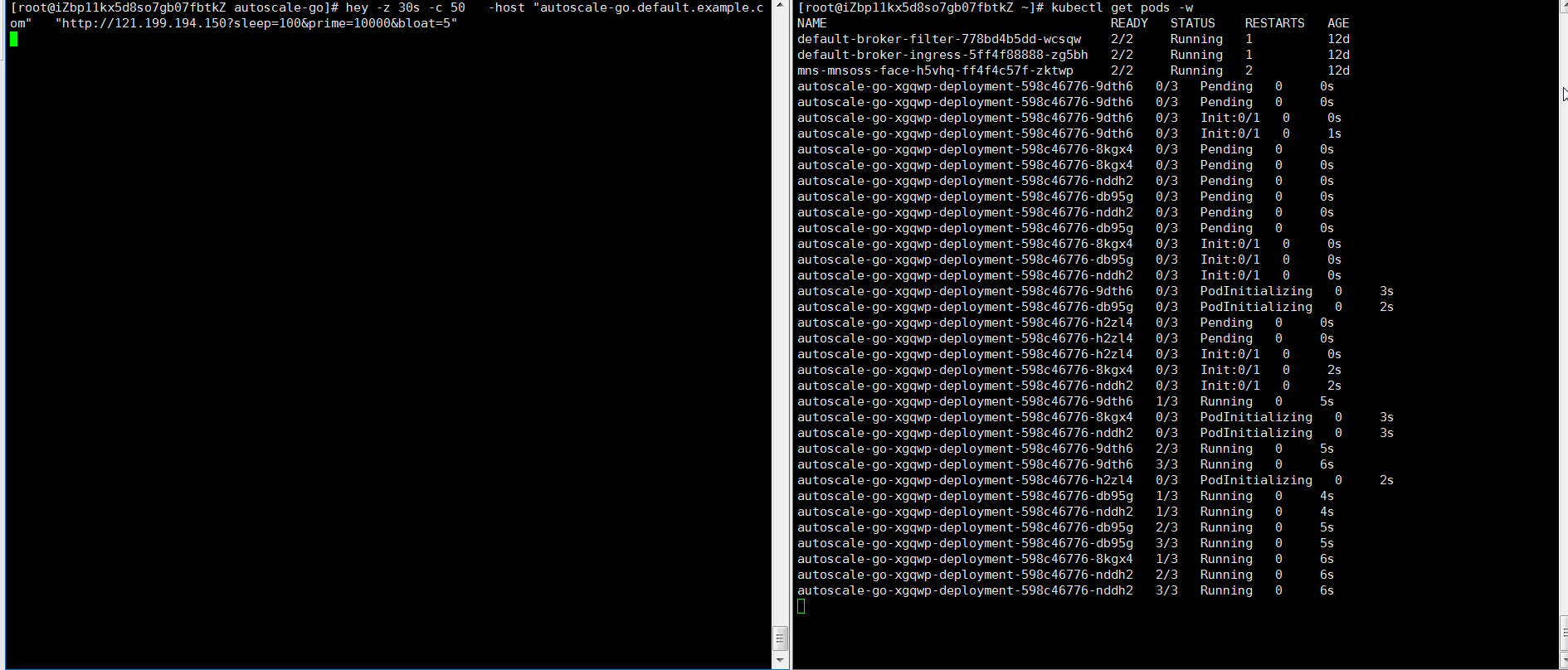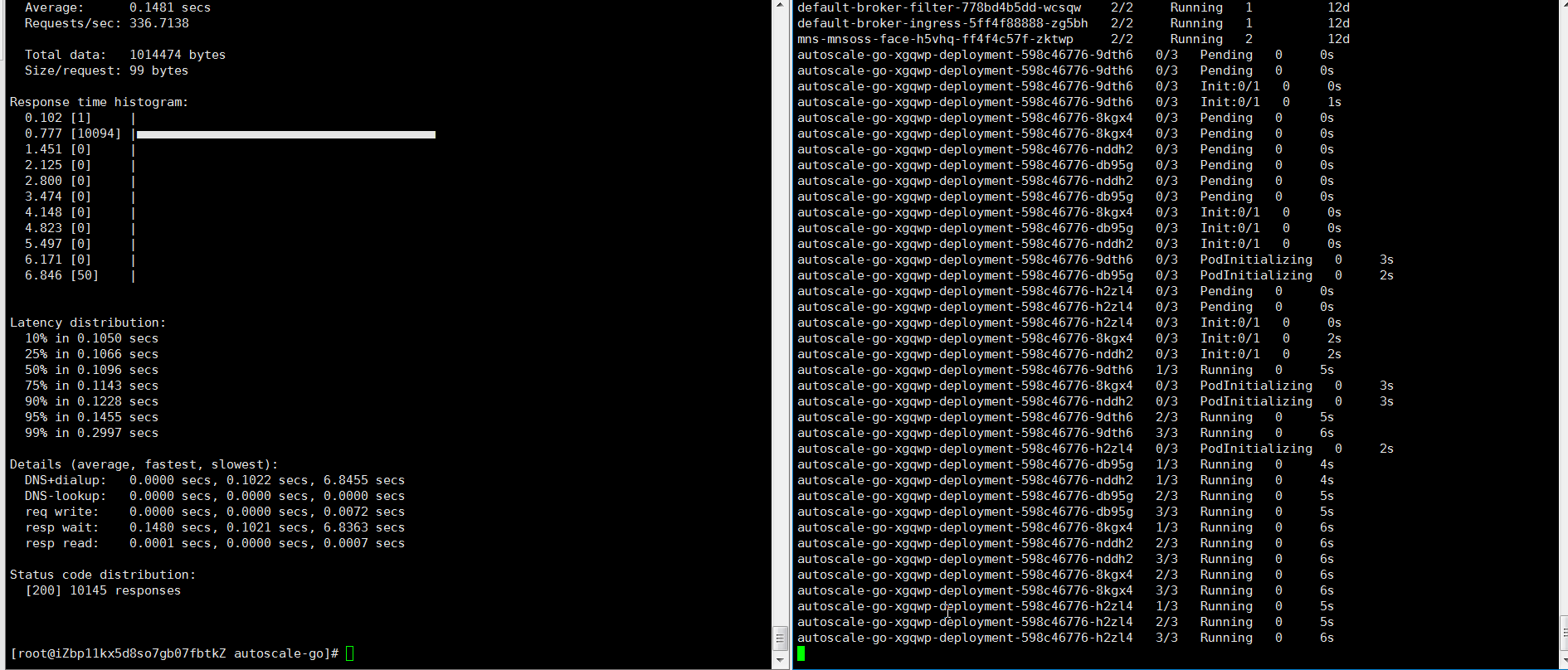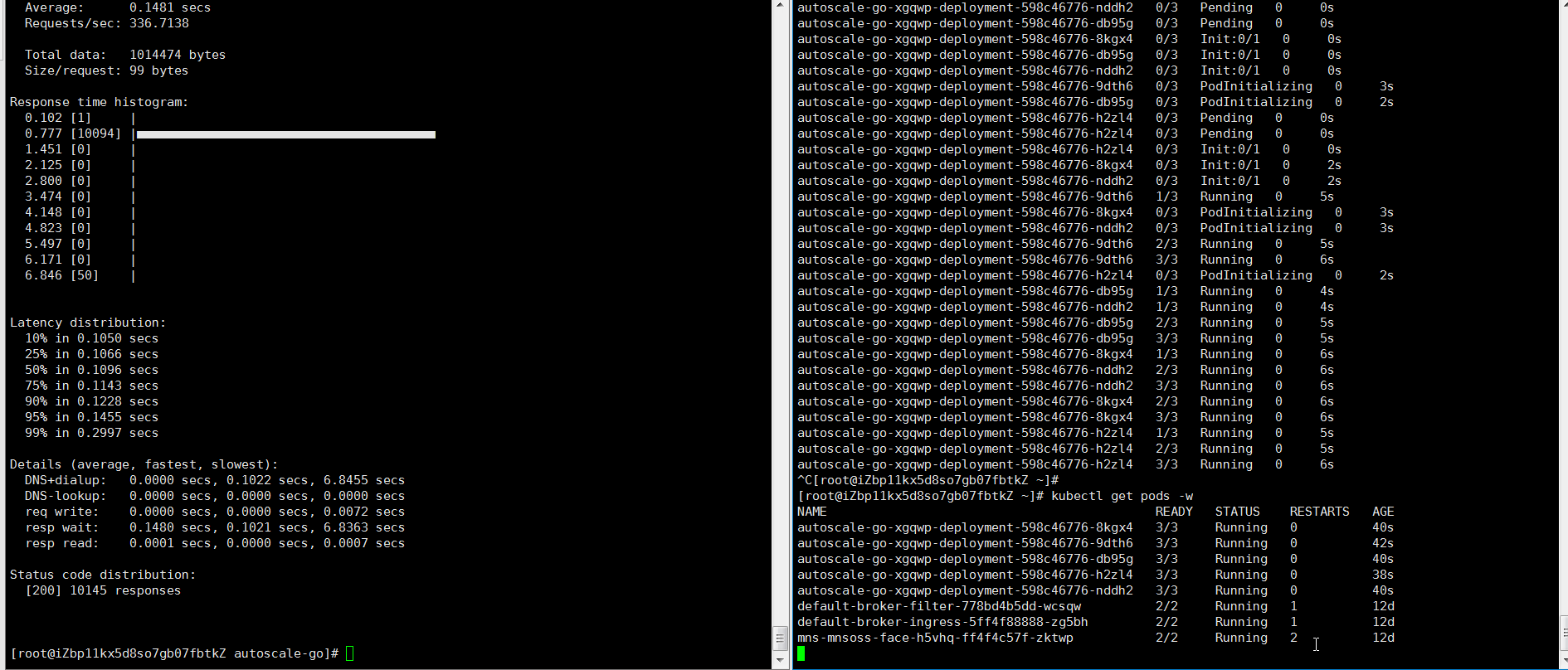
想定通り、5 個の Pod がスケールアウトしました。
シナリオ 2:スケーリングの上下限を設定して自動スケーリングを有効化する
スケーリングの上下限とは、アプリケーションサービスの最小および最大 Pod 数を定義するものです。アプリケーションサービスの最小および最大 Pod 数を設定することで、自動スケーリングを有効化できます。
autoscale-go.yaml ファイルを作成し、クラスターにデプロイします。
この YAML の例では、同時実行リクエスト数の最大値を 10、
min-scale(最小 Pod 数)を 1、max-scale(最大 Pod 数)を 3 に設定しています。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/min-scale: "1" autoscaling.knative.dev/max-scale: "3" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yamlサービスアクセスゲートウェイを取得します。
ALB
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl get albconfig knative-internet想定される出力:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl -n knative-serving get ing stats-ingress想定される出力:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"想定される出力:
121.XX.XX.XXKourier
以下のコマンドを実行して、サービスアクセスゲートウェイを取得します。
kubectl -n knative-serving get svc kourier想定される出力:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49mHey ストレステストツールを用いて、30 秒間 50 件の同時リクエストを維持します。
説明Hey ストレステストツールの詳細については、「Hey」をご参照ください。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX はゲートウェイの IP アドレスです。想定される出力:
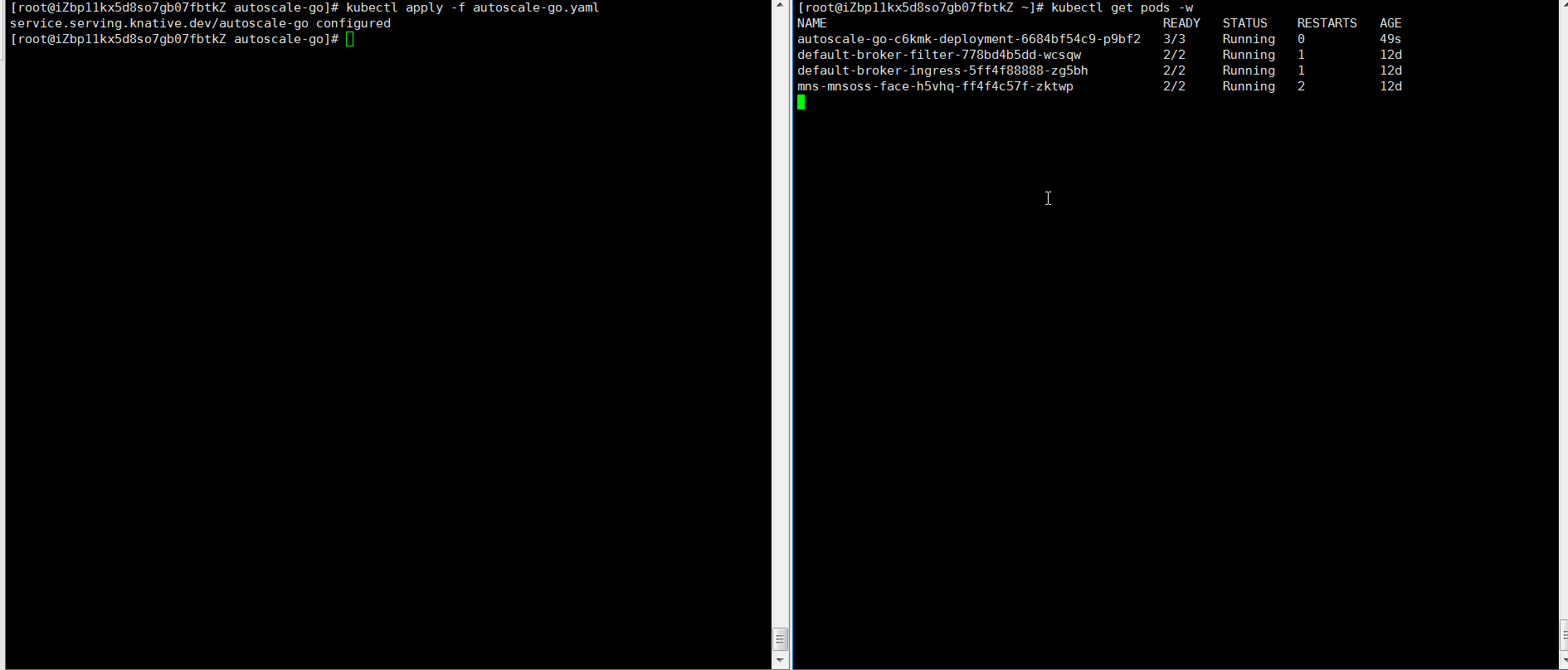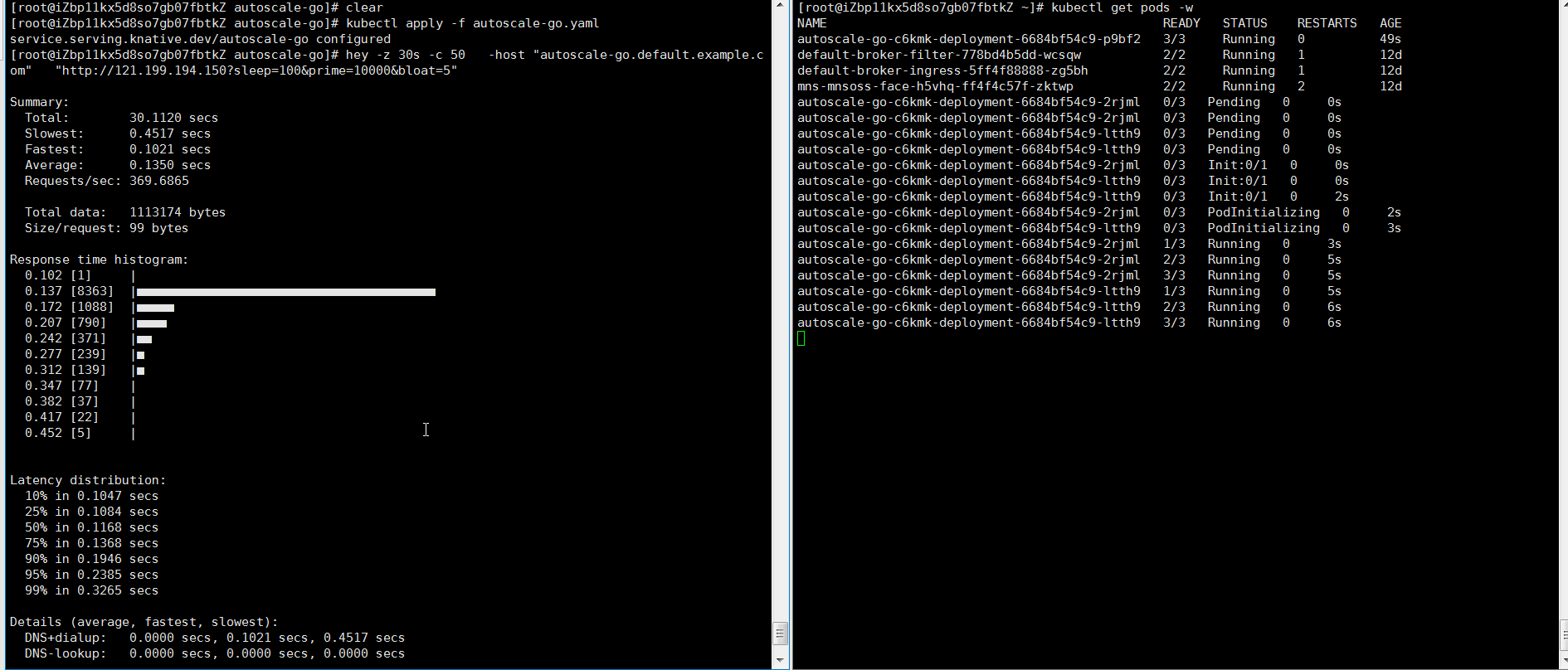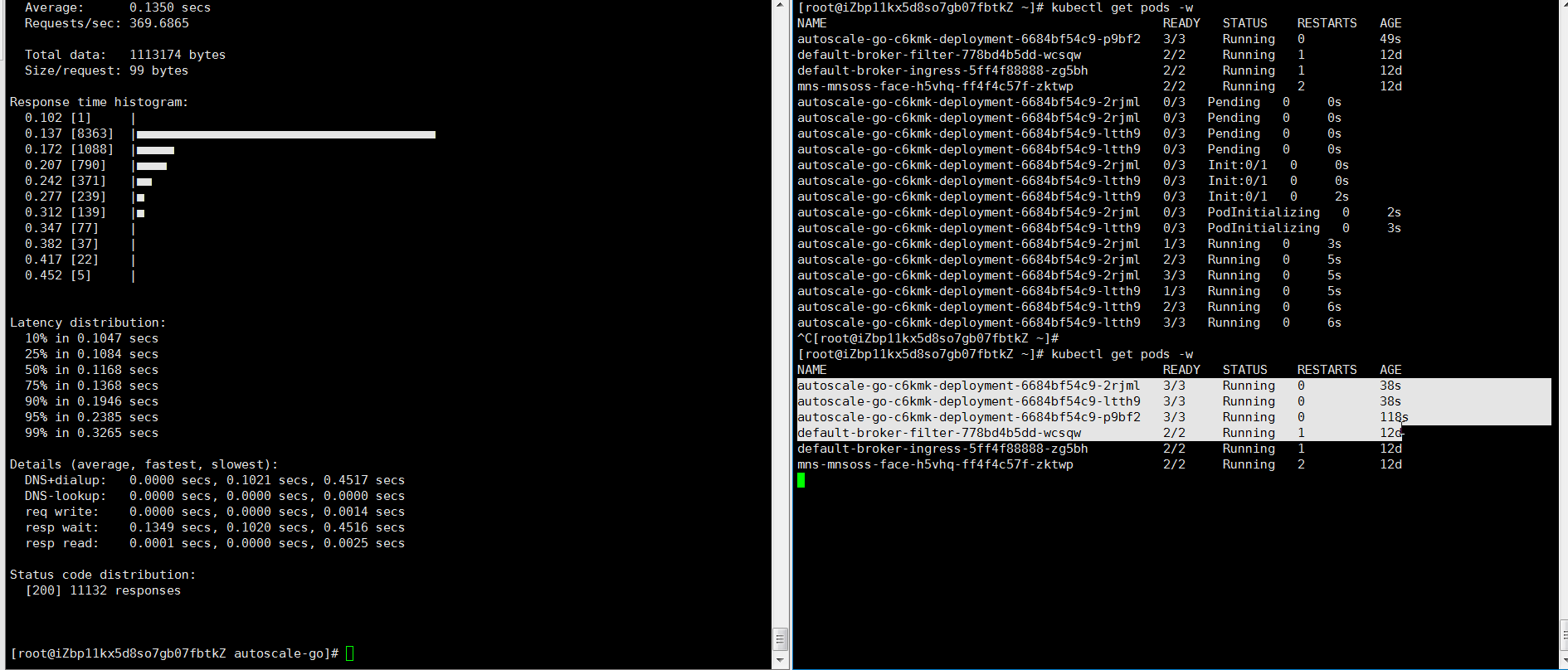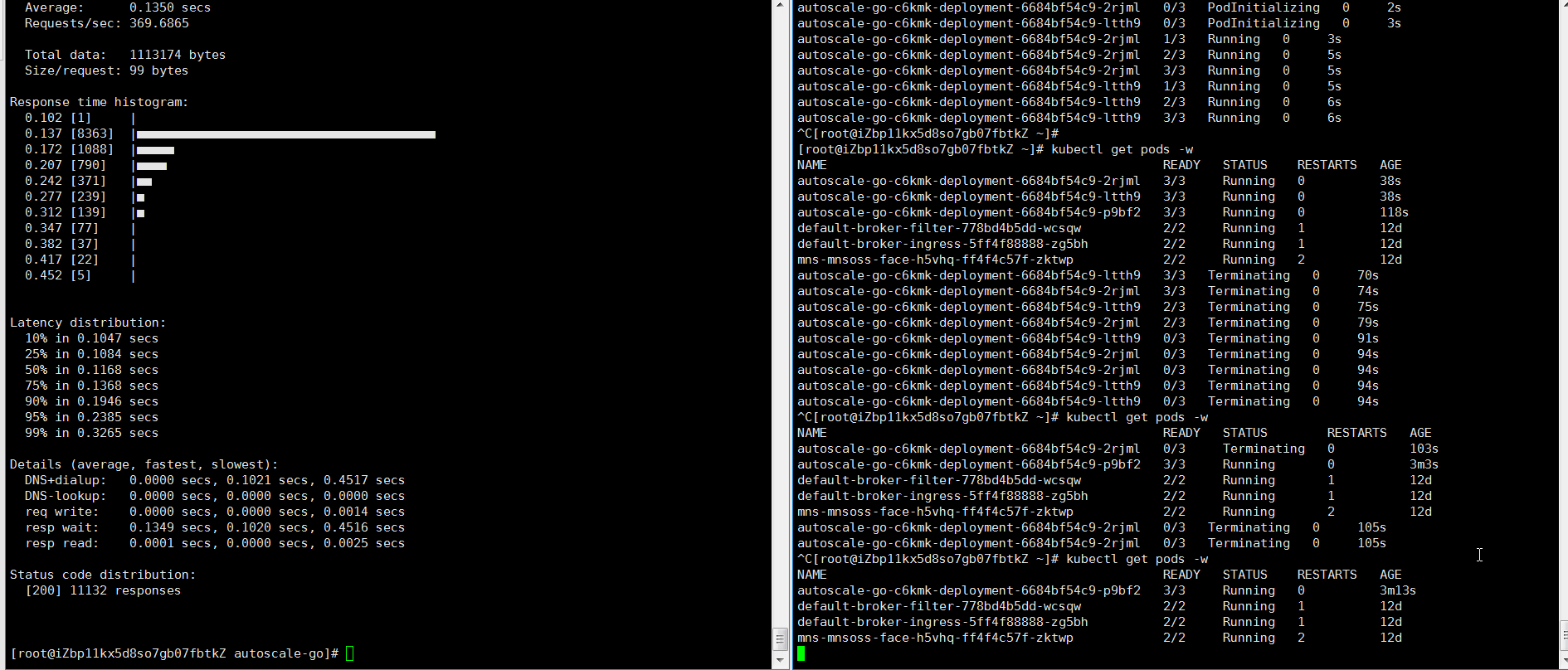
最大で 3 個の Pod がスケールアウトします。また、着信リクエストトラフィックがない場合でも、1 個の Pod が実行されたままになります。これは想定通りの動作です。
関連ドキュメント
履歴リソースメトリックに基づいた能動的なスケーリング計画を実現するために、Knative では Advanced Horizontal Pod Autoscaler(AHPA)を使用できます。これにより、スケジュールされたスケーリングが可能になります。詳細については、「Knative と AHPA を用いたスケジュール自動スケーリングの実装」をご参照ください。