ACK One フリートは AI 推論サービスをサポートします。複数リージョンの ACK クラスターおよびハイブリッドクラウドのマルチクラスターシナリオでは、クラスターの優先度を定義できます。これにより、オンプレミスのデータセンター (IDC) またはプライマリーリージョンのリソースを優先し、Alibaba Cloud またはバックアップリージョンのリソースを補足的な計算能力として使用できます。このインベントリを意識したスケジューリングにより、業務継続性が確保されます。
仕組み
この機能は、次のシナリオに適用されます。
複数リージョンの ACK クラスターシナリオ: AI 推論サービスのプライマリーリージョンとしてリージョン A を設定し、バックアップリージョンとしてリージョン B を設定します。リージョン A のクラスターはより高い優先度を持ちます。GPU リソースが不足し、スケールアウトが必要な場合、ACK One フリートはまずクラスターの優先度に基づいて推論サービスをリージョン A にスケジュールします。リージョン A のリソースが不足している場合、サービスをリージョン B にスケジュールします。スケールインする場合、優先度の低いリージョン B の推論サービスのレプリカが最初にスケールインされ、次にリージョン A のレプリカがスケールインされます。
ハイブリッドクラウドのマルチクラスターシナリオ: フリートを使用して、オンプレミスの IDC とクラウドベースの ACK リソースの両方を管理できます。この場合、クラウドリソースがオンプレミスの IDC リソースを補完します。スケールアウトする場合、ACK One フリートはまず推論サービスを IDC クラスターにスケジュールします。IDC のリソースが不足している場合、クラウドコンピューティング能力を使用するために ACK クラスターにスケジュールします。スケールインする場合、まずクラウド上の推論サービスのレプリカをスケールインし、次に IDC 内のレプリカをスケールインします。
次の例は、ハイブリッドクラウドのマルチクラスターシナリオに適用されます。
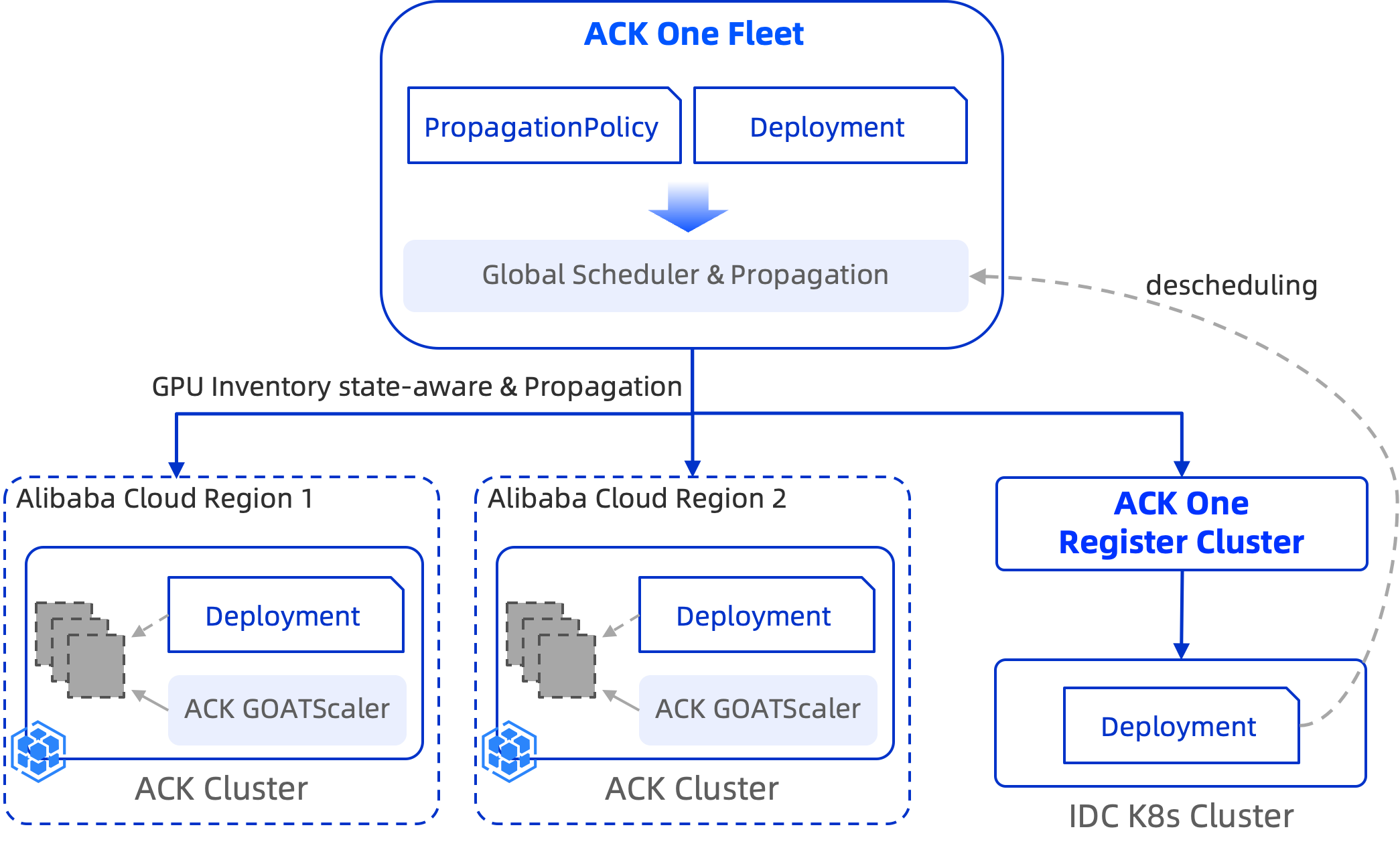
適用性
インスタントノードエラスティシティがメンバークラスターで有効になっていること。ACK クラスターのバージョンは 1.24 以降である必要があります。
メンバークラスターでノードの自動スケーリングがすでに有効になっている場合は、「ステップ 1: インスタントノードエラスティシティを有効にするインスタントノードエラスティシティ
AMC コマンドラインツールがインストールされていること。
ステップ 1: フリートにデモサービスをデプロイする
次の例では、ModelScope からダウンロードし、vllm で実行される qwen3-0.6b モデルを使用します。テストのために、このデプロイメントは T4 または A10 GPU で実行できます。
フリートに `test` 名前空間を作成し、すべてのメンバークラスターにもこの名前空間があることを確認します。
kubectl create ns testdemo.yamlという名前のファイルを作成して保存します。次に、フリートでkubectl apply -f demo.yamlを実行して、デモの Deployment と Service をデプロイします。apiVersion: apps/v1 kind: Deployment metadata: name: qwen3 namespace: test spec: progressDeadlineSeconds: 600 replicas: 2 revisionHistoryLimit: 10 selector: matchLabels: app: qwen3 template: metadata: labels: app: qwen3 spec: containers: # ModelScope からダウンロードした qwen3-0.6b モデルを使用 - command: - sh - -c - export VLLM_USE_MODELSCOPE=True; vllm serve Qwen/Qwen3-0.6B --served-model-name qwen3-0.6b --port 8000 --trust-remote-code --tensor_parallel_size=1 --max-model-len 2048 --gpu-memory-utilization 0.8 image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm-openai:v0.9.1 imagePullPolicy: IfNotPresent name: vllm ports: - containerPort: 8000 name: restful protocol: TCP readinessProbe: failureThreshold: 3 initialDelaySeconds: 30 periodSeconds: 10 successThreshold: 1 tcpSocket: port: 8000 timeoutSeconds: 1 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 --- apiVersion: v1 kind: Service metadata: name: qwen3 namespace: test labels: app: qwen3 spec: ports: - port: 8000 selector: app: qwen3
ステップ 2: ハイブリッドクラウドでのエラスティックスケジューリングのための伝播ポリシーをデプロイする
次の PropagationPolicy では、インベントリを意識したスケジューリングを有効にし、クラスターの優先度を構成できます。この構成では、IDC へのスケジューリングが優先されます。IDC のリソースが不足している場合、スケジューリングはクラウドにフォールバックしてノードのエラスティシティをトリガーします。
例の ${registered cluster ID} と ${ACK Cluster ID} を実際のクラスター ID に置き換えます。demo-pp.yaml という名前のファイルを作成して保存します。次に、フリートで kubectl apply -f demo-pp.yaml を実行して PropagationPolicy をデプロイします。
以下の例では、spec.resourceSelectors フィールドには、「ステップ 1: フリートにデモサービスをデプロイする」で作成されたサンプルリソースが入力されています。本番環境では、実際のリソース情報を使用してください。apiVersion: policy.one.alibabacloud.com/v1alpha1
kind: PropagationPolicy
metadata:
name: vllm-deploy-pp
namespace: test
spec:
autoScaling:
ecsProvision: true
placement:
clusterAffinities:
- affinityName: idc
clusterNames:
- ${registered cluster ID}
- affinityName: ack
clusterNames:
- ${ACK Cluster ID}
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
dynamicWeight: AvailableReplicas
preserveResourcesOnDeletion: false
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
namespace: test
schedulerName: default-scheduler
---
apiVersion: policy.one.alibabacloud.com/v1alpha1
kind: PropagationPolicy
metadata:
name: demo-svc
namespace: test
spec:
preserveResourcesOnDeletion: false
resourceSelectors:
- apiVersion: v1
kind: Service
name: qwen3
placement:
replicaScheduling:
replicaSchedulingType: Duplicatedステップ 3: エラスティックスケーリングを検証する
kubectl amc get pod -ntest -Mを実行して、デプロイメントのステータスを表示します。最初に、IDC クラスターに十分なリソースがある場合、Pod はまず IDC クラスターにデプロイされます:
NAME CLUSTER CLUSTER_ALIAS READY STATUS RESTARTS AGE qwen3-5665b88779-7k*** c6b4******** cluster-idc-demo 1/1 Running 0 18m qwen3-5665b88779-ds*** c6b4******** cluster-idc-demo 1/1 Running 0 18mフリート内の推論サービスのレプリカ数をスケールアウトします:
kubectl scale deploy qwen3 -ntest --replicas=4スケールアウトが完了したら、
kubectl amc get pod -ntest -Mを実行して Pod のデプロイメントステータスを表示します。新しい Pod は ACK クラスターにスケジュールされます。2 つの Pod が Pending 状態であり、これは ACK クラスターのリソースが不足していることを示します:
NAME CLUSTER CLUSTER_ALIAS READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ADOPTION qwen3-5665b88779-7k*** c043******** cluster-bj-demo 0/1 Pending 0 33s <none> <none> <none> <none> N qwen3-5665b88779-ds*** c043******** cluster-bj-demo 0/1 Pending 0 33s <none> <none> <none> <none> N qwen3-5665b88779-7k*** c6b4******** cluster-idc-demo 1/1 Running 0 18m 172.20.245.125 x.x.x.x <none> <none> N qwen3-5665b88779-ds*** c6b4******** cluster-idc-demo 1/1 Running 0 18m 172.19.8.159 x.x.x.x <none> <none> Nkubectl amc get node -Mコマンドを実行してノードのステータスを確認します。出力は、2 つの新しいノードが弾力的に追加され、ACK クラスターに参加していることを示しています:推論サービスがスケールインされると、弾力的に追加されたノードは 10 分後に自動的に削除されます。
NAME CLUSTER CLUSTER_ALIAS STATUS ROLES AGE VERSION ADOPTION cn-beijing.172.19.8.*** c043******** cluster-bj-demo NotReady <none> 20s N cn-beijing.172.20.245.** c043******** cluster-bj-demo Ready <none> 18h v1.34.1-aliyun.1 N cn-beijing.172.21.3.*** c043******** cluster-bj-demo NotReady <none> 20s N cn-beijing.172.21.3.** c043******** cluster-bj-demo Ready <none> 18h v1.34.1-aliyun.1 N cn-beijing.172.20.245.** c6b4******** cluster-idc-demo Ready <none> 3h14m v1.34.1-aliyun.1 N cn-beijing.172.21.3.** c6b4******** cluster-idc-demo Ready <none> 3h16m v1.34.1-aliyun.1 N cn-beijing.172.21.3.** c6b4******** cluster-idc-demo Ready <none> 3h13m v1.34.1-aliyun.1 Nスケールインする場合、レプリカは PropagationPolicy で定義されたクラスターの優先度に基づいて、最も低い優先度から最も高い優先度の順に削除されます。
フリート内の推論サービスのレプリカ数をスケールインします:
kubectl scale deploy qwen3 -ntest --replicas=2kubectl amc get pod -ntest -Mを実行して Pod のデプロイメントステータスを表示します。出力は、ACK クラスター上の 2 つのレプリカがスケールインされたことを示しています:NAME CLUSTER CLUSTER_ALIAS READY STATUS RESTARTS AGE qwen3-5665b88779-7k*** c6b4******** cluster-idc-demo 1/1 Running 0 18m qwen3-5665b88779-ds*** c6b4******** cluster-idc-demo 1/1 Running 0 18m