大規模言語モデル (LLM) のオンラインサービスでは、変動するトラフィックを処理するために、マルチクラスターアーキテクチャがよく使用されます。ACK One が提供するマルチクラスターソリューションは、このシナリオに最適です。このトピックでは、ACK One フリートを使用してクラウド環境に vLLM 推論サービスをデプロイし、マルチクラスター Horizontal Pod Autoscaler (HPA)、すなわち FederatedHPA を使用してクラスター間の自動スケーリングを行う方法を説明します。
仕組み
大規模な推論シナリオにおいて、LLM のオンラインサービスは、激しく予測不可能なトラフィック変動という課題に直面します。マルチクラスターアーキテクチャは、トラフィックのピークを処理するための一般的なソリューションです。
セルフマネージドデータセンターを持つユーザーは、通常、ハイブリッドクラウドアーキテクチャを使用します。ビジネスのピーク時には、クラウドベースのクラスターを使用して弾力的にスケールアウトします。
クラウドネイティブユーザーは、単一リージョンでのリソース不足のリスクを避けるために、異なるリージョンに複数のクラスターをデプロイする傾向があります。
ACK One フリートは、複数のクラスターにまたがるリソースを管理できます。また、クラスター間のスケジューリングと弾性スケーリングも実行できます。これは、両方のデプロイメントモードのニーズを満たします。
マルチクラスター優先度スケジューリング:クラスターのスケジューリング優先度を設定できます。レプリカはまず優先度の高いクラスターにスケジュールされます。リソースが不足している場合、レプリカは優先度の低いクラスターにスケールアウトされます。スケールイン時には、優先度の低いクラスターのレプリカが最初に削除されます。
在庫ベースのスマートスケジューリング:フリートクラスターは、メンバークラスターの GoatScaler コンポーネントと連携して動作します。ECS 在庫情報を使用して、レプリカをインテリジェントにスケジュールします。
集中型弾性スケーリング:FederatedHPA を作成して、複数のクラスターに対して集中型の弾性スケーリングを実行できます。フリートクラスターの Metrics Adapter は、メンバークラスターからメトリックを収集し、集約します。メンバークラスターは Prometheus-adapter もサポートしています。その後、集約されたメトリックに基づいてワークロードがスケーリングされます。
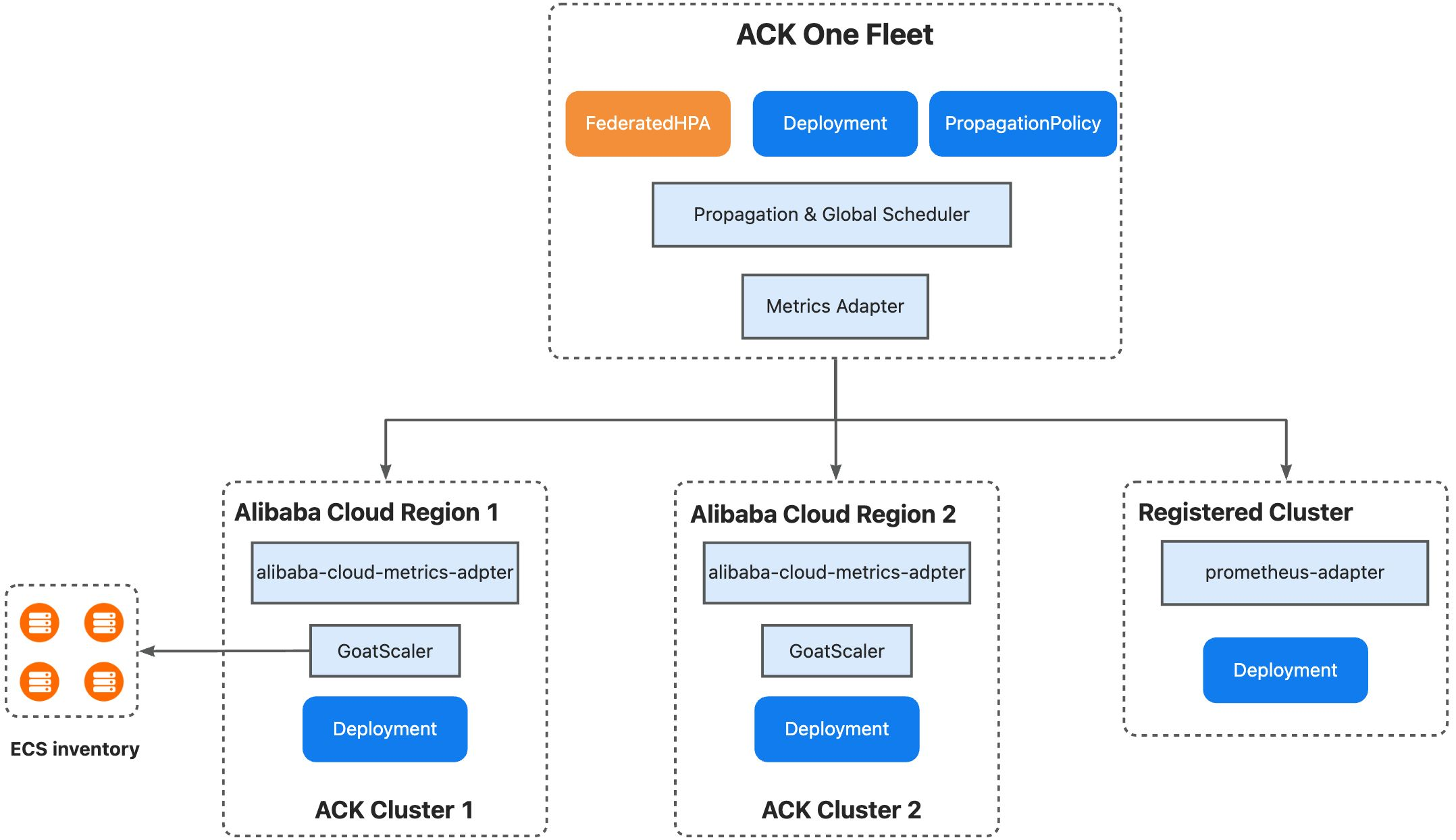
適用範囲
2 つの ACK クラスターが作成済みであること。各クラスターには GPU ノードプールと、初期化された GPU インスタンスが 1 つ必要です。
2 つの ACK クラスターが ACK One フリートに関連付けられており、alibaba-cloud-metrics-adapter コンポーネントが有効になっていること。登録済みクラスターの場合、オープンソースの prometheus-adapter もインストールする必要があります。
マルチクラスター HPA 機能は招待プレビュー段階です。この機能を使用するには、ホワイトリストへの追加を申請してください。
操作手順
ステップ 1:メンバークラスターでのメトリック収集の設定
両方の ACK クラスターで ack-alibaba-cloud-metrics-adapter のコンポーネントパラメーターを設定します。
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、対象のクラスターを見つけてその名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
ack-alibaba-cloud-metrics-adapter コンポーネントを見つけ、[アクション] 列の [更新] をクリックします。
prometheus.adapter.rulesセクションで、メトリック収集設定を変更できます。例:vllm:num_requests_waiting:処理を待機しているリクエストの数。vllm:num_requests_running:処理中のリクエストの数。
rules: - seriesQuery: 'vllm:num_requests_waiting' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: 'vllm:num_requests_waiting' as: 'num_requests_waiting' metricsQuery: 'sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)' - seriesQuery: 'vllm:num_requests_running' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: 'vllm:num_requests_running' as: 'num_requests_running' metricsQuery: 'sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)'設定を変更した後、
[OK]をクリックします。カスタムメトリックが設定されているか確認します。
# カスタムメトリックの表示 kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/test/pods/qwen3-xxxxx/num_requests_waiting" kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/test/pods/qwen3-xxxxx/num_requests_running"期待される出力には vLLM メトリックが含まれます。これは、メトリック収集が正しく設定されていることを示します。
ステップ 2:フリートでの vLLM 推論サービスの作成
次の YAML テンプレートを deployment.yaml として保存します。次に、kubectl apply -f deployment.yaml コマンドを実行して、フリートに推論サービスをデプロイします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen3
namespace: test
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: qwen3
template:
metadata:
annotations:
# Pod のメトリックを収集するために使用します。PodMonitor に似ています。
prometheus.io/path: /metrics
prometheus.io/port: "8000"
prometheus.io/scrape: "true"
labels:
app: qwen3
spec:
containers:
# ModelScope からダウンロードした qwen3-0.6b モデルを使用します。
- command:
- sh
- -c
- export VLLM_USE_MODELSCOPE=True; vllm serve Qwen/Qwen3-0.6B --served-model-name
qwen3-0.6b --port 8000 --trust-remote-code --tensor_parallel_size=1 --max-model-len
2048 --gpu-memory-utilization 0.8
image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm-openai:v0.9.1
imagePullPolicy: IfNotPresent
name: vllm
ports:
- containerPort: 8000
name: restful
protocol: TCP
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 8000
timeoutSeconds: 1
resources:
limits:
nvidia.com/gpu: "1"
requests:
nvidia.com/gpu: "1"
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30ステップ 3:フリートでのマルチクラスター伝播ポリシーの設定
次のテンプレートを propagationpolicy.yaml として保存します。次に、kubectl apply -f propagationpolicy.yaml コマンドを実行します。
autoScaling.ecsProvision:在庫ベースのスマートスケジューリングを有効にします。ECS インスタンスは必要に応じて自動的にスケールアウトまたはスケールインされます。clusterAffinities:優先度グループを指定します。スケジューリング中、アフィニティは優先度の順に埋められます。
apiVersion: policy.one.alibabacloud.com/v1alpha1
kind: PropagationPolicy
metadata:
name: vllm-deploy-pp
namespace: test
spec:
autoScaling:
ecsProvision: true
placement:
clusterAffinities:
- affinityName: high-priority
clusterNames:
- ${cluster1_id}
- affinityName: low-priority
clusterNames:
- ${cluster2_id}
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
dynamicWeight: AvailableReplicas
preserveResourcesOnDeletion: false
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
namespace: test
- apiVersion: v1
kind: Service
namespace: test
schedulerName: default-schedulerステップ 4:フリートでの FederatedHPA の作成
FederatedHPA は、Pod の CPU、メモリ、カスタムメトリック、および外部メトリックをモニターできます。次の例では、num_requests_waiting と num_requests_running のカスタムメトリックを弾性スケーリングに使用します。
次のテンプレートを federatedhpa.yaml として保存します。次に、kubectl apply -f federatedhpa.yaml コマンドを実行します。
apiVersion: autoscaling.one.alibabacloud.com/v1alpha1
kind: FederatedHPA
metadata:
name: vllm-fhpa
namespace: test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: qwen3
minReplicas: 1
maxReplicas: 10
behavior:
scaleDown:
stabilizationWindowSeconds: 30
scaleUp:
stabilizationWindowSeconds: 10
metrics:
- type: Pods
pods:
metric:
name: num_requests_waiting
target:
type: AverageValue
averageValue: ${waiting_size} # GPU とモデルの最適値によって異なります。
- type: Pods
pods:
metric:
name: num_requests_running
target:
type: AverageValue
averageValue: ${running_size} # GPU とモデルの最適値によって異なります。結果の検証
優先度スケジューリングの検証
kubectl scale deployment -ntest qwen3 --replicas=2コマンドを実行してワークロードをスケールアウトします。cluster1 には GPU インスタンスが 1 つしかないため、2 番目のレプリカは優先度の低いグループの cluster2 にスケジュールされます。FederatedHPA の検証
マルチクラスター Application Load Balancer (ALB) を使用してサービスを公開し、Ingress アドレスを取得します。詳細については、「南北トラフィックの管理」をご参照ください。
次のコマンドの ALB アドレスを置き換えます。次に、コマンドを実行してサービスの負荷テストを実行します。
hey -n 600 -c 60 -m POST -H "Content-Type: application/json" -d '{"messages": [{"role": "user", "content": "Run a test"}]}' http://alb-xxxxxx.cn-hangzhou.alb.aliyuncsslb.com:8000/v1/chat/completionsnum_requests_runningとレプリカ数が大幅に増加することが確認できます。Current Metrics: Pods: Current: Average Value: 0 Metric: Name: num_requests_waiting Type: Pods Pods: Current: Average Value: 58 Metric: Name: num_requests_running Type: Pods Current Replicas: 2 Desired Replicas: 3
在庫認識スマートスケジューリングの検証
推論アプリケーションが 3 つのレプリカにスケールアウトされた後、新しいレプリカは正常にスケジュールされ、起動します。これは、cluster1 と cluster2 に合計で 2 つの GPU インスタンスしかないにもかかわらず発生します。これは、フリートの在庫ベースのスマートスケジューリングが正しく機能していることを示します。
よくある質問
kubectl get fhpa を実行した後、なぜ REPLICAS 列が空なのですか?
これは、FederatedHPA が正しいワークロードと一致していないために発生します。ワークロード名と名前空間の設定を確認してください。
kubectl get fhpa -o yaml を実行した後、なぜエラーが報告されるのですか?
条件に the HPA was unable to compute the replica count: unable to get metric xxx というエラーが報告されます。これは、FederatedHPA がメンバークラスターから対応するワークロードのメトリックを取得できなかったためです。
すべてのメンバークラスターに ack-alibaba-cloud-metrics-adapter コンポーネントがインストールされていることを確認してください。
メンバークラスターの ack-alibaba-cloud-metrics-adapter コンポーネントのパラメーターが正しく設定されていることを確認してください。メンバークラスターのダッシュボードでメトリックをクエリして、クエリが成功するかどうかを確認できます。
メンバークラスターでメトリックをクエリしても表示されないのはなぜですか?
次のコマンドを実行して、メトリックが登録されているか確認します。関連するメトリックが見つからない場合は、Helm アプリケーションのコンポーネントパラメーターが正しく設定されているか確認してください。
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .