ACK クラスターに ECS g8i インスタンスを追加し、Intel® Extension for PyTorch (IPEX) を使用して、コスト効率が高くハードウェアでアクセラレートされた CPU 上の Text-to-Image 推論を実行します。データ機密性を要するワークロードについては、アプリケーションコードを変更せずに、Intel® Trust Domain Extensions (Intel® TDX) 機密 VM へのオプションによるアップグレードが可能です。
本トピックでは、stabilityai/sdxl-turbo モデルを例として使用します。
-
Alibaba Cloud は、「Stable Diffusion」および「stabilityai/sdxl-turbo」などのサードパーティ製モデルの合法性、安全性、正確性を保証しません。これらのモデルの使用に起因する一切の損失または損害について、Alibaba Cloud は責任を負いません。
-
サードパーティ製モデルの利用規約、使用条件および関連する法令・規制を遵守してください。これらのモデルの使用は、お客様の単独の責任において行われるものとします。
-
本トピックで紹介するサンプルサービスは、学習、テスト、および概念実証(POC)のみを目的としています。掲載されているすべての統計数値は参考用であり、実際の結果はお客様の環境によって異なる場合があります。
CPU 推論を利用するタイミング
g8i + IPEX + 高度行列拡張命令 (AMX) の組み合わせは、以下の条件で GPU ベースの推論の実用的な代替手段となります:
-
コストが最優先事項である場合:GPU インスタンス
ecs.gn7i-c8g1.2xlargeから CPU インスタンスecs.g8i.4xlargeへ切り替えることで、インスタンスコストを 53 % 以上削減できます。 -
スループット要件が中程度である場合:ステップ数 = 4、バッチサイズ = 16 の設定で、
ecs.g8i.8xlargeは 1.2 画像/秒の生成速度を実現します。これは、多くの本番ワークロードで求められる 1 画像/秒というしきい値を超えています。 -
データ機密性が要求される場合:アプリケーションコードを変更せずに、TDX 機密 VM ノードプールへ移行できます。
レイテンシ SLO が GPU クラスのスループット(ステップ数 = 30、バッチサイズ = 16 の場合、0.4 画像/秒)を必要とする場合は、GPU インスタンスを継続してご利用ください。一方、最適品質設定(ステップ数 = 4)で 1.2 画像/秒のスループットが許容される場合は、g8i インスタンスがコスト効率の高い選択肢となります。
背景情報
g8i インスタンスファミリー
g8i 汎用 ECS インスタンスファミリーは、Cloud Infrastructure Processing Units (CIPUs) および Apsara Stack により提供されます。AI パフォーマンスを強化するために、AMX を搭載した第 5 世代 Intel® Xeon® Scalable プロセッサ(コードネーム:Emerald Rapids)を採用しています。すべての g8i インスタンスは Intel® TDX をサポートしており、アプリケーションコードを変更することなく、信頼実行環境(TEE)でワークロードを実行できます。
仕様の詳細については、「g8i、汎用インスタンスファミリー」をご参照ください。
Intel® TDX
Intel® TDX は、CPU ハードウェアベースの技術であり、ECS インスタンスに対してハードウェア支援による隔離および暗号化を提供します。実行時に CPU レジスタ、メモリデータ、割り込み注入を保護し、実行中のプロセスや機密データへの不正アクセスを防止します。アプリケーションコードの変更は不要です。
詳細については、「Intel® Trust Domain Extensions (Intel® TDX)」をご参照ください。
IPEX
Intel® Extension for PyTorch (IPEX) は、Intel プロセッサ上で AI アプリケーションのパフォーマンスを向上させるオープンソースの PyTorch 拡張です。最新の Intel ハードウェアおよびソフトウェア技術と連携して継続的に最適化されています。
詳細については、「IPEX」をご参照ください。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
-
中国 (北京) リージョンで ACK Pro マネージドクラスターが作成済みであること。詳細については、「ACK マネージドクラスターの作成」をご参照ください。
-
以下の要件を満たす ECS g8i インスタンスを含むノードプールが存在すること。
-
インスタンスタイプ:最低 16 vCPU。推奨:
ecs.g8i.4xlarge、ecs.g8i.8xlarge、またはecs.g8i.12xlarge。 -
ディスク容量:ノードあたり最低 200 GiB(システムディスクまたはデータディスク)。
-
リージョンおよびゾーン:g8i インスタンスが利用可能なリージョンおよびゾーン。詳細については、「リージョンごとの利用可能なインスタンスタイプ」をご参照ください。
-
-
kubectl が ACK クラスターに接続済みであること。詳細については、「kubectl を使用した ACK クラスターへの接続」をご参照ください。
手順 1:モデルの準備
デプロイメントでは stabilityai/sdxl-turbo モデルを使用します。モデルの保存場所に応じて、以下のいずれかのオプションを選択してください。
オプション 1:公式モデルの使用(推奨)
Helm チャートイメージ (v0.1.5) には、公式の stabilityai/sdxl-turbo モデルがバンドルされています。以下の内容で values.yaml ファイルを作成します。CPU およびメモリの設定は、ご利用のインスタンスタイプに応じて調整してください。
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24Giオプション 2:OSS からのカスタムモデルの使用
OSS(Object Storage Service)にカスタムの stabilityai/sdxl-turbo モデルを保存している場合、PersistentVolume(PV)および PersistentVolumeClaim(PVC)を用いてデプロイメントにマウントします。
OSS の読み取り権限を持つ RAM ユーザーを作成し、その AccessKey ペアを取得した後、以下の手順を実行してください。
-
models-oss-secret.yamlというファイルを作成し、以下の内容を記述します。apiVersion: v1 kind: Secret metadata: name: models-oss-secret namespace: default stringData: akId: <your-access-key-id> # RAM ユーザーの AccessKey ID akSecret: <your-access-key-secret> # RAM ユーザーの AccessKey Secret -
シークレットを適用します。
kubectl create -f models-oss-secret.yaml期待される出力:
secret/models-oss-secret created -
models-oss-pv.yamlというファイルを作成し、以下の内容を記述します。プレースホルダーの値を、お客様の OSS バケットの詳細情報に置き換えてください。apiVersion: v1 kind: PersistentVolume metadata: name: models-oss-pv labels: alicloud-pvname: models-oss-pv spec: capacity: storage: 50Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: models-oss-pv nodePublishSecretRef: name: models-oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" # マウント対象の OSS バケット url: "<your-oss-endpoint>" # 内部エンドポイント(例:oss-cn-beijing-internal.aliyuncs.com) otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: "/models" # stabilityai/sdxl-turbo サブディレクトリを含むパスである必要がありますOSS パラメーターの詳細については、「方法 1:シークレットの使用」をご参照ください。
-
PV を作成します。
kubectl create -f models-oss-pv.yaml期待される出力:
persistentvolume/models-oss-pv created -
models-oss-pvc.yamlというファイルを作成し、以下の内容を記述します。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: models-oss-pvc spec: accessModes: - ReadOnlyMany resources: requests: storage: 50Gi selector: matchLabels: alicloud-pvname: models-oss-pv -
PVC を適用します。
kubectl create -f models-oss-pvc.yaml期待される出力:
persistentvolumeclaim/models-oss-pvc created -
カスタムモデルボリュームを有効化する
values.yamlファイルを作成します。リソース設定は、ご利用のインスタンスタイプに応じて調整してください。resources: limits: cpu: "16" memory: 32Gi requests: cpu: "14" memory: 24Gi # bundled image model の代わりに OSS からカスタムモデルをマウントする場合は true に設定します。 useCustomModels: true volumes: models: name: data-volume persistentVolumeClaim: claimName: models-oss-pvc
values.yaml の完全なリファレンス
Helm チャートは、リソースおよびモデルソース以外にも追加の構成オプションをサポートしています。デフォルト値の完全な一覧は以下のとおりです。
# Pod のレプリカ数。
replicaCount: 1
# コンテナイメージの構成。
image:
repository: registry-vpc.cn-beijing.aliyuncs.com/eric-dev/stable-diffusion-ipex
pullPolicy: IfNotPresent
tag: "v0.1.5" # 公式の stabilityai/sdxl-turbo モデルをバンドル
tagOnlyApi: "v0.1.5-lite" # API 専用イメージ。モデルのマウントは手動で行う必要があります(useCustomModels 参照)
# 非公開コンテナイメージをプルするための認証情報。
imagePullSecrets: []
# コンテナ内での生成画像の出力パス。
outputDirPath: /tmp/sd
# volumes.models PVC を介してカスタムモデルをマウントする場合は true に設定します。
# false の場合、モデルを含む image.tag イメージが使用されます。
useCustomModels: false
volumes:
# 画像出力パス用のボリューム。
output:
name: output-volume
emptyDir: {}
# カスタムモデル用のボリューム。useCustomModels: true の場合のみ有効になります。
# マウントパスの stabilityai/sdxl-turbo サブディレクトリにモデルを配置してください。
models:
name: data-volume
persistentVolumeClaim:
claimName: models-oss-pvc
# または、ホストパスを使用することもできます:
# models:
# hostPath:
# path: /data/models
# type: DirectoryOrCreate
# サービスの構成。
service:
type: ClusterIP
port: 5000
# コンテナのリソース制限および要求。
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24Gi
# ワークロードの更新戦略。
strategy:
type: RollingUpdate
# スケジューリングの構成。
nodeSelector: {}
tolerations: []
affinity: {}
# コンテナのセキュリティ設定。
securityContext:
capabilities:
drop:
- ALL
runAsNonRoot: true
runAsUser: 1000
# Horizontal Pod Autoscaler(HPA)の構成。
# https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 90手順 2:サービスのデプロイ
-
Helm を使用して、IPEX でアクセラレートされた Stable Diffusion XL Turbo サービスをデプロイします。
helm install stable-diffusion-ipex \ https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz \ -f values.yaml期待される出力:
NAME: stable-diffusion-ipex LAST DEPLOYED: Mon Jan 22 20:42:35 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None -
モデルのロード完了まで約 10 分待ち、その後 Pod が実行中であることを確認します。
kubectl get pod | grep stable-diffusion-ipex期待される出力:
stable-diffusion-ipex-65d98cc78-vmj49 1/1 Running 0 1m44s
Pod が実行中になると、サービスはポート 5000 で Text-to-Image API を公開します。パラメーターの完全な一覧については、「API リファレンス」をご参照ください。
手順 3:サービスのテスト
-
サービスのポートをローカルマシンに転送します。
kubectl port-forward svc/stable-diffusion-ipex 5000:5000期待される出力:
Forwarding from 127.0.0.1:5000 -> 5000 Forwarding from [::1]:5000 -> 5000 -
生成リクエストを送信します。サービスは
512x512および1024x1024の出力サイズをサポートしています。512x512 画像curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "ヘッドフォンを着用して音楽を聴いているパンダ。非常に詳細で、8K 解像度。", "number": 1}'期待される出力:
{ "averageImageGenerationTimeSeconds": 2.0333826541900635, "generationTimeSeconds": 2.0333826541900635, "id": "9ae43577-170b-45c9-ab80-69c783b41a70", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "ヘッドフォンを着用して音楽を聴いているパンダ。非常に詳細で、8K 解像度。", "size": "512x512", "step": 4 } }, "output": [ { "latencySeconds": 2.0333826541900635, "url": "http://127.0.0.1:5000/images/9ae43577-170b-45c9-ab80-69c783b41a70/0_0.png" } ], "status": "success" }1024x1024 画像
curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "ヘッドフォンを着用して音楽を聴いているパンダ。非常に詳細で、8K 解像度。", "number": 1, "size": "1024x1024"}'期待される出力:
{ "averageImageGenerationTimeSeconds": 8.635204315185547, "generationTimeSeconds": 8.635204315185547, "id": "ac341ced-430d-4952-b9f9-efa57b4eeb60", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "ヘッドフォンを着用して音楽を聴いているパンダ。非常に詳細で、8K 解像度。", "size": "1024x1024", "step": 4 } }, "output": [ { "latencySeconds": 8.635204315185547, "url": "http://127.0.0.1:5000/images/ac341ced-430d-4952-b9f9-efa57b4eeb60/0_0.png" } ], "status": "success" }生成された画像を表示するには、
url値をブラウザで開きます。
パフォーマンスベンチマーク
以下の表は、さまざまな g8i インスタンスタイプにおける平均生成時間(バッチサイズ:1、ステップ数:4)を示しています。結果は参考用です。
| インスタンスタイプ | Pod 要求/制限(vCPU) | 平均生成時間 — 512x512 | 平均持続時間 — 1024x1024 |
|---|---|---|---|
| ecs.g8i.4xlarge(16 vCPU、64 GiB) | 14/16 | 2.2 秒 | 8.8 秒 |
| ecs.g8i.8xlarge(32 vCPU、128 GiB) | 24/32 | 1.3 秒 | 4.7 秒 |
| ecs.g8i.12xlarge(48 vCPU、192 GiB) | 32/32 | 1.1 秒 | 3.9 秒 |
推奨事項:ecs.g8i.8xlarge は、コストとスループットのバランスが最も優れています。ステップ数 = 4、バッチサイズ = 16 の設定で、1.2 画像/秒の生成速度を実現します。これは、画質を損なうことなく 1 画像/秒を超える性能です。
(オプション)手順 4:TDX 機密 VM ノードプールへの移行
デプロイ済みのサービスを TDX 機密 VM ノードプールに移行することで、ハードウェアベースのメモリ隔離および暗号化を追加できます。アプリケーションコードの変更は不要です。
前提条件
ACK クラスター内に、以下の構成を持つ TDX 機密 VM ノードプールが存在すること。
-
インスタンスタイプ:最低 16 vCPU。推奨:
ecs.g8i.4xlarge。 -
ディスク容量:ノードあたり最低 200 GiB。
-
ノードラベル:
nodepool-label=tdx-vm-pool。
セットアップ手順については、「TDX 機密 VM をサポートするノードプールの作成」をご参照ください。
サービスの移行
-
tdx_values.yamlというファイルを作成し、以下の nodeSelector を記述します。ノードプールのラベル値が異なる場合は、tdx-vm-poolを適宜置き換えてください。nodeSelector: nodepool-label: tdx-vm-pool -
Helm リリースをアップグレードして、Pod を TDX ノードプール上に再スケジュールします。
helm upgrade stable-diffusion-ipex \ https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz \ -f tdx_values.yaml期待される出力:
Release "stable-diffusion-ipex" has been upgraded. Happy Helming! NAME: stable-diffusion-ipex LAST DEPLOYED: Wed Jan 24 16:38:04 2024 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: None -
約 10 分待ってから、Pod が TDX ノードプール上で実行中であることを確認します。
kubectl get pod | grep stable-diffusion-ipex期待される出力:
stable-diffusion-ipex-7f8c4f88f5-r478t 1/1 Running 0 1m44s -
モデルが TDX ノードプールで正しく動作することを確認するため、「手順 3:サービスのテスト」を再度実行します。
API リファレンス
デプロイ後、サービスはポート 5000 で REST API を公開します。
リクエスト構文
POST /api/text2imageリクエストパラメーター
サンプルリクエスト
レスポンスパラメーター
サンプルレスポンス
パフォーマンス比較
g8i ノードプールは、AMX および IPEX を活用して CPU 上の推論をアクセラレートします。以下のデータは、lambda-diffusers ベンチマークツール を使用して ecs.g8i.8xlarge(32 vCPU、128 GiB)で生成されたものです。結果は参考用です。
CPU アクセラレーションベンチマーク
| インスタンスタイプ | モデル | ステップ | コマンド |
|---|---|---|---|
| ecs.g8i.8xlarge(32 vCPU、128 GiB) | sdxl-turbo | 4 | python sd_pipe_sdxl_turbo.py --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 4 --prompt "ヘッドフォンを着用して音楽を聴いているパンダ。非常に詳細で、8K 解像度。" |
| ecs.g8i.8xlarge(32 vCPU、128 GiB) | stable-diffusion-2-1-base | 30 | python sd_pipe_infer.py --model /data/models/stable-diffusion-2-1-base --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 30 --prompt "ヘッドフォンを着用して音楽を聴いているパンダ。非常に詳細で、8K 解像度。" |
パフォーマンス結果(画像/秒):
| 構成 | スループット |
|---|---|
| ecs.g8i.8xlarge、ステップ数 = 4、バッチサイズ = 16(sdxl-turbo) | 1.2 画像/秒 |
| ecs.g8i.8xlarge、ステップ数 = 30、バッチサイズ = 16(sd-2-1-base) | 0.14 画像/秒 |
GPU アクセラレーションベンチマーク
GPU ベンチマークデータは、「Lambda Diffusers Benchmarking inference」から引用しています。実際の結果は異なる場合があります。
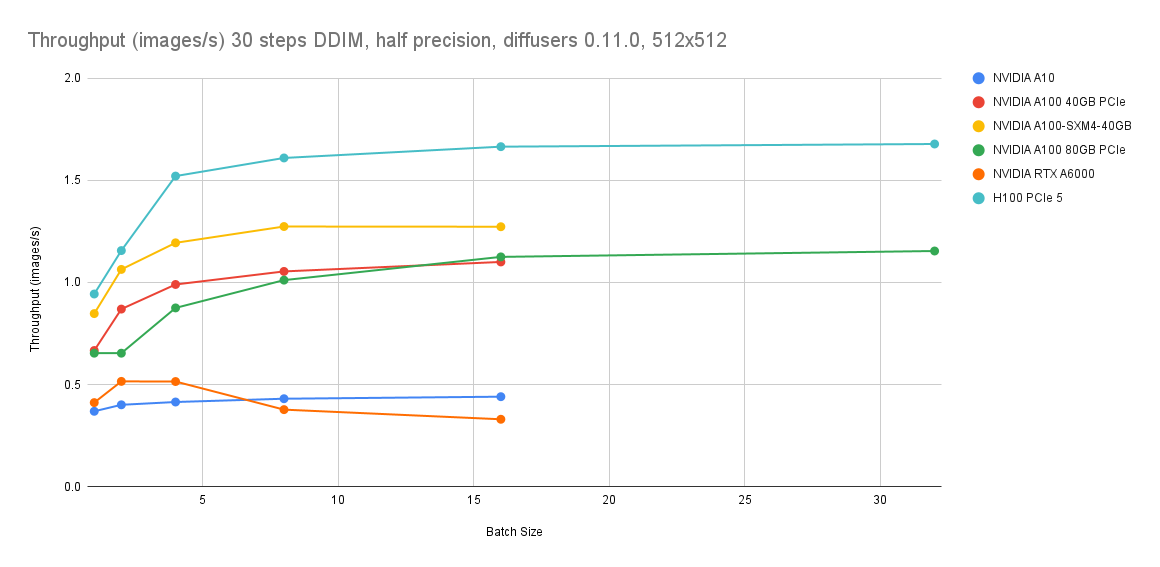
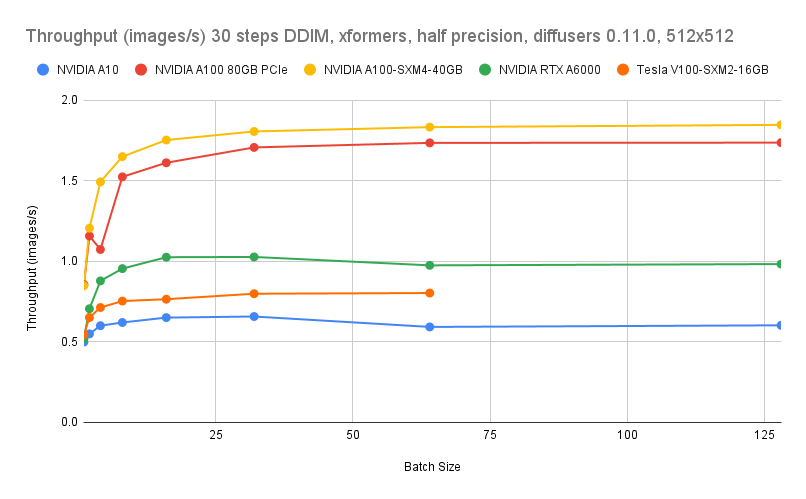
コスト比較
以下の見積もりは、g8i CPU インスタンスと ecs.gn7i-c8g1.2xlarge(GPU)を比較したものです。最新の価格については、「Elastic Compute Service」ページの料金タブをご確認ください。
| インスタンスタイプ | ecs.gn7i-c8g1.2xlarge に対するコスト | ステップ数 = 4、バッチサイズ = 16 におけるスループット |
|---|---|---|
| ecs.g8i.8xlarge | 9%低下 | 1.2 画像/秒 |
| ecs.g8i.4xlarge | >53% 低下 | 0.5 画像/秒 |
コスト削減と 1 画像/秒を超えるスループットの両方を必要とする場合は、ecs.g8i.8xlarge をご利用ください。コスト削減が最優先事項であり、0.5 画像/秒で要件を満たす場合は、ecs.g8i.4xlarge をご利用ください。