IPEX を搭載した Container Service for Kubernetes (ACK) クラスターで Elastic Compute Service (ECS) g8i ワーカーノードを使用すると、コスト効率の高い Text-to-Image 推論を実現できます。オプションで TDX 機密 VM ノードプールに移行して、データの機密性を確保することも可能です。
このトピックでは、stabilityai/sdxl-turbo モデルを例として使用します。
-
Alibaba Cloud は、サードパーティのモデルである「Stable Diffusion」および「stabilityai/sdxl-turbo」の正当性、安全性、または正確性を保証しません。Alibaba Cloud は、これらのモデルの使用に起因するいかなる損失または損害に対しても責任を負いません。
-
サードパーティモデルのユーザー契約、利用規約、および関連する法令を遵守してください。これらのモデルの使用は、お客様ご自身の責任において行われるものとします。
-
このサンプルサービスは、学習、テスト、および概念実証 (POC) のみを目的としています。統計は参考用です。実際の結果は、環境によって異なる場合があります。
CPU 推論を使用するケース
g8i + IPEX + Advanced Matrix Extensions (AMX) は、次のような場合に GPU 推論に代わる実用的な選択肢となります。
-
コストが優先事項である場合:
ecs.gn7i-c8g1.2xlarge(GPU) からecs.g8i.4xlargeに切り替えることで、インスタンスのコストを 53% 以上削減できます。 -
スループット要件が中程度である場合:step=4、batch=16 の設定で、
ecs.g8i.8xlargeは 1.2 画像/秒を生成します。これは、多くの本番ワークロードのしきい値である 1 画像/秒を上回ります。 -
データの機密性が必要な場合:コードを変更することなく、TDX 機密 VM ノードプールに移行できます。
レイテンシー SLO が GPU クラスのスループット (step=30、batch=16 で 0.4 画像/秒) を必要とする場合は、GPU インスタンスを引き続き使用してください。step=4 で 1.2 画像/秒が許容できる場合は、g8i はコスト効率の高い選択肢です。
背景情報
g8i インスタンスファミリー
汎用 ECS インスタンスファミリーである g8i は、Cloud Infrastructure Processing Units (CIPU) と Apsara Stack を搭載しています。AI アクセラレーションのために AMX を備えた第 5 世代 Intel® Xeon® スケーラブルプロセッサー (開発コード名:Emerald Rapids) を使用しています。すべての g8i インスタンスは Intel® TDX をサポートしており、最小限のパフォーマンスオーバーヘッドで、コードを変更することなく高信頼実行環境 (TEE) ワークロードを実現します。
詳細については、「g8i、汎用インスタンスファミリー」をご参照ください。
Intel® TDX
Intel® TDX は、ECS インスタンスを分離および暗号化し、実行時に CPU レジスタ、メモリ、および割り込みの注入を保護するハードウェアベースの高信頼実行環境 (TEE) テクノロジーです。これにより、コードを変更することなく、プロセスや機密データへの不正アクセスを防止できます。
詳細については、「Intel® Trust Domain Extensions (Intel® TDX)」をご参照ください。
IPEX
Intel® Extension for PyTorch (IPEX) は、Intel プロセッサー上の AI を高速化するオープンソースの PyTorch 拡張機能であり、最新の Intel ハードウェアおよびソフトウェア向けに継続的に最適化されています。
詳細については、「IPEX」をご参照ください。
前提条件
開始する前に、次のものが揃っていることを確認してください。
-
中国 (北京) リージョンに ACK Pro クラスターがあること。詳細については、「ACK マネージド型クラスターの作成」をご参照ください。
-
次の要件を満たす ECS g8i インスタンスを持つノードプール:
-
インスタンスタイプ:16 vCPU 以上。推奨:
ecs.g8i.4xlarge、ecs.g8i.8xlarge、またはecs.g8i.12xlarge。 -
ディスク容量:ノードあたり 200 GiB 以上 (システムディスクまたはデータディスク)。
-
リージョンとゾーン:g8i インスタンスが利用可能なリージョンとゾーン。「各リージョンで利用可能なインスタンスタイプ」をご確認ください。
-
-
kubectl が ACK クラスターに接続されていること。詳細については、「kubectl を使用した ACK クラスターへの接続」をご参照ください。
手順1:モデルの準備
このデプロイでは、stabilityai/sdxl-turbo モデルを使用します。モデルが保存されている場所に基づいてオプションを選択してください。
オプション1:公式モデルの使用 (推奨)
Helm チャートイメージ (v0.1.5) には、公式の stabilityai/sdxl-turbo モデルがバンドルされています。次の内容で values.yaml を作成します。ご使用のインスタンスタイプに合わせて CPU とメモリを調整してください。
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24Giオプション2:OSS のカスタムモデルの使用
Object Storage Service (OSS) にカスタムの stabilityai/sdxl-turbo モデルを保存している場合は、PersistentVolume (PV) と PersistentVolumeClaim (PVC) を使用してマウントします。
OSS の読み取り権限を持つ Resource Access Management (RAM) ユーザーを作成し、その AccessKey ペアを取得してください。
-
次の内容で
models-oss-secret.yamlを作成します。apiVersion: v1 kind: Secret metadata: name: models-oss-secret namespace: default stringData: akId: <your-access-key-id> # RAM ユーザーの AccessKey ID akSecret: <your-access-key-secret> # RAM ユーザーの AccessKey シークレット -
Secret を適用します。
kubectl create -f models-oss-secret.yaml期待される出力:
secret/models-oss-secret created -
次の内容で
models-oss-pv.yamlを作成します。プレースホルダーを実際の OSS バケットの詳細に置き換えてください。apiVersion: v1 kind: PersistentVolume metadata: name: models-oss-pv labels: alicloud-pvname: models-oss-pv spec: capacity: storage: 50Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: models-oss-pv nodePublishSecretRef: name: models-oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" # マウントする OSS バケット url: "<your-oss-endpoint>" # 内部エンドポイントを使用します (例: oss-cn-beijing-internal.aliyuncs.com) otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: "/models" # stabilityai/sdxl-turbo サブディレクトリを含む必要がありますOSS パラメーターについては、「方法1:Secret の使用」をご参照ください。
-
PV を作成します。
kubectl create -f models-oss-pv.yaml期待される出力:
persistentvolume/models-oss-pv created -
次の内容で
models-oss-pvc.yamlを作成します。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: models-oss-pvc spec: accessModes: - ReadOnlyMany resources: requests: storage: 50Gi selector: matchLabels: alicloud-pvname: models-oss-pv -
PVC を適用します。
kubectl create -f models-oss-pvc.yaml期待される出力:
persistentvolumeclaim/models-oss-pvc created -
カスタムモデルボリュームを有効にして
values.yamlを作成します。ご使用のインスタンスタイプに合わせてリソースを調整してください。resources: limits: cpu: "16" memory: 32Gi requests: cpu: "14" memory: 24Gi # バンドルされたイメージモデルの代わりに OSS のカスタムモデルをマウントする場合は true に設定します。 useCustomModels: true volumes: models: name: data-volume persistentVolumeClaim: claimName: models-oss-pvc
values.yaml の完全なリファレンス
Helm チャートは、リソースとモデルソース以外の追加オプションもサポートしています。デフォルト値:
# Pod レプリカの数。
replicaCount: 1
# コンテナイメージの設定。
image:
repository: registry-vpc.cn-beijing.aliyuncs.com/eric-dev/stable-diffusion-ipex
pullPolicy: IfNotPresent
tag: "v0.1.5" # 公式の stabilityai/sdxl-turbo モデルをバンドル
tagOnlyApi: "v0.1.5-lite" # API 専用イメージ。モデルを手動でマウントする必要があります (useCustomModels を参照)
# プライベートコンテナイメージをプルするための認証情報。
imagePullSecrets: []
# コンテナ内で生成された画像の出力パス。
outputDirPath: /tmp/sd
# volumes.models PVC を介してマウントされたカスタムモデルを使用する場合は true に設定します。
# false の場合、image.tag イメージ (モデルを含む) が使用されます。
useCustomModels: false
volumes:
# 画像出力パス用のボリューム。
output:
name: output-volume
emptyDir: {}
# カスタムモデル用のボリューム。useCustomModels: true の場合にのみ有効。
# マウントパスの stabilityai/sdxl-turbo サブディレクトリにモデルを配置します。
models:
name: data-volume
persistentVolumeClaim:
claimName: models-oss-pvc
# または、ホストパスを使用します:
# models:
# hostPath:
# path: /data/models
# type: DirectoryOrCreate
# Service の設定。
service:
type: ClusterIP
port: 5000
# コンテナのリソースリミットとリクエスト。
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24Gi
# ワークロードの更新戦略。
strategy:
type: RollingUpdate
# スケジューリングの設定。
nodeSelector: {}
tolerations: []
affinity: {}
# コンテナのセキュリティ設定。
securityContext:
capabilities:
drop:
- ALL
runAsNonRoot: true
runAsUser: 1000
# Horizontal Pod Autoscaler (HPA) の設定。
# https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 90手順2:サービスのデプロイ
-
Helm を使用して、IPEX で高速化された Stable Diffusion XL Turbo サービスをデプロイします。
helm install stable-diffusion-ipex \ https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz \ -f values.yaml期待される出力:
NAME: stable-diffusion-ipex LAST DEPLOYED: Mon Jan 22 20:42:35 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None -
モデルがロードされるまで約 10 分待ち、Pod が実行中であることを確認してください。
kubectl get pod | grep stable-diffusion-ipex期待される出力:
stable-diffusion-ipex-65d98cc78-vmj49 1/1 Running 0 1m44s
実行されると、サービスはポート 5000 で Text-to-Image API を公開します。パラメーターについては、「API リファレンス」をご参照ください。
手順3:サービスのテスト
-
サービスポートをローカルマシンにポートフォワードします。
kubectl port-forward svc/stable-diffusion-ipex 5000:5000期待される出力:
Forwarding from 127.0.0.1:5000 -> 5000 Forwarding from [::1]:5000 -> 5000 -
生成リクエストを送信します。サポートされているサイズ:
512x512および1024x1024。512x512 画像curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1}'期待される出力:
{ "averageImageGenerationTimeSeconds": 2.0333826541900635, "generationTimeSeconds": 2.0333826541900635, "id": "9ae43577-170b-45c9-ab80-69c783b41a70", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "512x512", "step": 4 } }, "output": [ { "latencySeconds": 2.0333826541900635, "url": "http://127.0.0.1:5000/images/9ae43577-170b-45c9-ab80-69c783b41a70/0_0.png" } ], "status": "success" }1024x1024 画像
curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1, "size": "1024x1024"}'期待される出力:
{ "averageImageGenerationTimeSeconds": 8.635204315185547, "generationTimeSeconds": 8.635204315185547, "id": "ac341ced-430d-4952-b9f9-efa57b4eeb60", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "1024x1024", "step": 4 } }, "output": [ { "latencySeconds": 8.635204315185547, "url": "http://127.0.0.1:5000/images/ac341ced-430d-4952-b9f9-efa57b4eeb60/0_0.png" } ], "status": "success" }ブラウザで
urlを開くと、生成された画像が表示されます。
パフォーマンスベンチマーク
g8i インスタンスタイプでの平均生成時間 (batch: 1、step: 4)。結果は参考用です。
| インスタンスタイプ | Pod のリクエスト/リミット (vCPU) | 平均所要時間 — 512x512 | 平均所要時間 — 1024x1024 |
|---|---|---|---|
| ecs.g8i.4xlarge (16 vCPU, 64 GiB) | 14/16 | 2.2s | 8.8s |
| ecs.g8i.8xlarge (32 vCPU, 128 GiB) | 24/32 | 1.3s | 4.7s |
| ecs.g8i.12xlarge (48 vCPU, 192 GiB) | 32/32 | 1.1s | 3.9s |
推奨:ecs.g8i.8xlarge は、コストとスループットのバランスが最も優れています。step=4、batch=16 の設定で、1.2 画像/秒を生成します。
(オプション) 手順4:TDX 機密 VM ノードプールへの移行
デプロイされたサービスを TDX 機密 VM ノードプールに移行することで、ハードウェアベースのメモリ分離と暗号化を実現できます。コードの変更は不要です。
前提条件
ACK クラスターに、次の設定を持つ TDX 機密 VM ノードプールが存在すること。
-
インスタンスタイプ:16 vCPU 以上。推奨:
ecs.g8i.4xlarge。 -
ディスク容量:ノードあたり 200 GiB 以上。
-
ノードラベル:
nodepool-label=tdx-vm-pool。
詳細については、「TDX 機密 VM をサポートするノードプールの作成」をご参照ください。
サービスの移行
-
次のノードセレクターを使用して
tdx_values.yamlを作成します。異なるラベル値を使用した場合は、tdx-vm-poolを置き換えてください。nodeSelector: nodepool-label: tdx-vm-pool -
Helm リリースをアップグレードして、Pod を TDX ノードプールに再スケジュールします。
helm upgrade stable-diffusion-ipex \ https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz \ -f tdx_values.yaml期待される出力:
Release "stable-diffusion-ipex" has been upgraded. Happy Helming! NAME: stable-diffusion-ipex LAST DEPLOYED: Wed Jan 24 16:38:04 2024 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: None -
約 10 分待ち、Pod が TDX ノードプールで実行されていることを確認してください。
kubectl get pod | grep stable-diffusion-ipex期待される出力:
stable-diffusion-ipex-7f8c4f88f5-r478t 1/1 Running 0 1m44s -
「手順3:サービスのテスト」を繰り返し、モデルが TDX ノードプールで動作することを確認してください。
API リファレンス
デプロイ後、サービスはポート 5000 で REST API を公開します。
リクエスト構文
POST /api/text2imageリクエストパラメーター
リクエストの例
レスポンスパラメーター
レスポンスの例
パフォーマンス比較
g8i ノードプールは AMX と IPEX を使用して CPU 推論を高速化します。ベンチマークでは ecs.g8i.8xlarge (32 vCPU、128 GiB) と lambda-diffusers ベンチマークツールを使用しています。結果は参考用です。
CPU アクセラレーションのベンチマーク
| インスタンスタイプ | モデル | Step | コマンド |
|---|---|---|---|
| ecs.g8i.8xlarge (32 vCPU, 128 GiB) | sdxl-turbo | 4 | python sd_pipe_sdxl_turbo.py --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 4 --prompt "A panda listening to music with headphones. highly detailed, 8k" |
| ecs.g8i.8xlarge (32 vCPU, 128 GiB) | stable-diffusion-2-1-base | 30 | python sd_pipe_infer.py --model /data/models/stable-diffusion-2-1-base --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 30 --prompt "A panda listening to music with headphones. highly detailed, 8k" |
パフォーマンス結果 (画像/秒):
| 設定 | スループット |
|---|---|
| ecs.g8i.8xlarge, step=4, batch=16 (sdxl-turbo) | 1.2 画像/秒 |
| ecs.g8i.8xlarge, step=30, batch=16 (sd-2-1-base) | 0.14 画像/秒 |
GPU アクセラレーションのベンチマーク
GPU ベンチマークは、Lambda Diffusers Benchmarking inference からのものです。実際の結果は異なる場合があります。
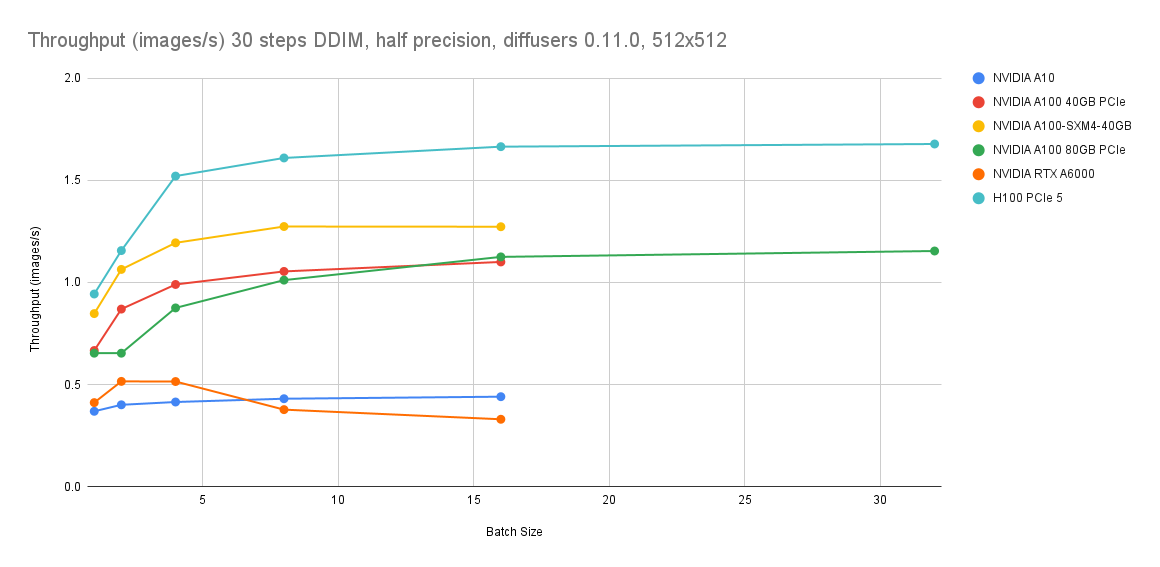
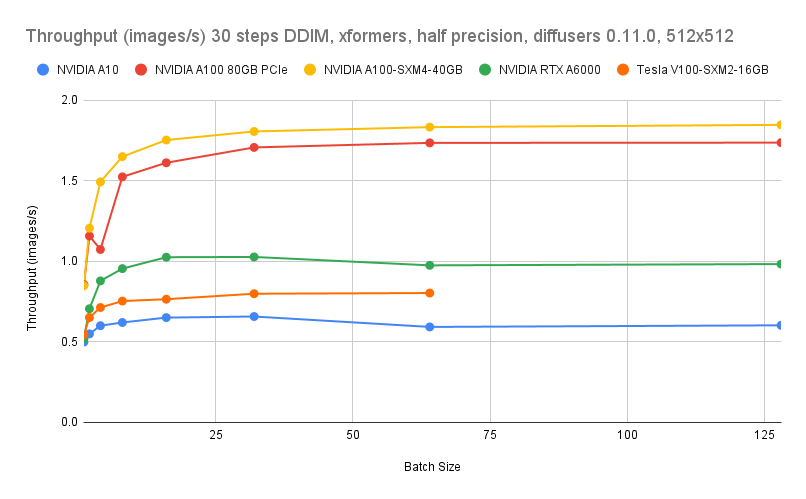
コスト比較
これらの見積もりは、g8i CPU インスタンスと ecs.gn7i-c8g1.2xlarge (GPU) を比較したものです。現在の価格については、Elastic Compute Service ページの [料金] タブをご参照ください。
| インスタンスタイプ | ecs.gn7i-c8g1.2xlarge とのコスト比較 | step=4, batch=16 でのスループット |
|---|---|---|
| ecs.g8i.8xlarge | 9% 低い | 1.2 画像/秒 |
| ecs.g8i.4xlarge | >53% 低い | 0.5 画像/秒 |
コスト削減と 1 画像/秒を超えるスループットの両方が必要な場合は、ecs.g8i.8xlarge を使用します。コスト削減や大規模な CPU リソース供給が優先事項であり、0.5 画像/秒のスループットで要件を満たす場合は ecs.g8i.4xlarge を使用します。