複数の GPU ノードに分散された分散トレーニングワークロードは、勾配同期中にノード間通信オーバーヘッドが大幅に発生します。ACK は、スケジューリングフレームワークに基づいたトポロジー対応 GPU スケジューリングをサポートしています。これにより、物理相互接続トポロジーに基づいて GPU が選択され、高帯域幅の NVLink 接続を共有する GPU にワーカーが配置されることで、このオーバーヘッドが削減され、トレーニングスループットが最大化されます。このトピックでは、TensorFlow 分散トレーニングジョブにトポロジー対応 GPU スケジューリングを適用する方法と、通常 GPU スケジューリングとの結果の比較について説明します。
前提条件
開始する前に、以下を準備してください。
インスタンスタイプが [Elastic GPU Service] に設定された ACK Pro マネージドクラスター。詳しくは、「ACK マネージドクラスターの作成」をご参照ください。
Arena がインストール済み
トポロジー対応 GPU スケジューリングコンポーネントがインストールされていること。
コンポーネントのバージョンが以下の要件を満たしていること。
| コンポーネント | 必須バージョン | 確認コマンド |
|---|---|---|
| Kubernetes | 1.18.8 以降 | kubectl version --short |
| NVIDIA ドライバー | 418.87.01 以降 | nvidia-smi --query-gpu=driver_version --format=csv,noheader |
| NCCL (NVIDIA Collective Communications Library) | 2.7 以降 | python3 -c "import torch; print(torch.cuda.nccl.version())" |
| オペレーティングシステム | CentOS 7.6、CentOS 7.7、Ubuntu 16.04、Ubuntu 18.04、Alibaba Cloud Linux 2、Alibaba Cloud Linux 3 | cat /etc/os-release |
| GPU | V100 | nvidia-smi --query-gpu=name --format=csv,noheader |
前提条件は順番に完了してください。まず ACK Pro マネージドクラスターを作成し、次に Arena をインストールし、最後にトポロジー対応 GPU スケジューリングコンポーネントをインストールします。コンポーネントを順番通りにインストールしないと、失敗する可能性があります。
制限事項
トポロジー対応 GPU スケジューリングは、分散フレームワークでトレーニングされた Message Passing Interface (MPI) ジョブにのみ適用されます。
通常の GPU スケジューリングは、物理相互接続トポロジーを考慮せず、可用性のみに基づいて GPU を割り当てます。これは、ワーカーが低速なネットワークリンクのみで接続された異なるノード上の GPU に配置される可能性があり、GPU 間通信が主要なボトルネックとなることを意味します。トポロジー対応スケジューリングは、同じノード内で NVLink 接続を共有する GPU 上にワーカーをグループ化することでこれを解決し、勾配同期遅延を大幅に削減します。
Pod は、要求されたすべてのリソースが同時に満たされる場合にのみ作成されます (ギャングスケジューリング)。リソースが不足している場合、十分な GPU が利用可能になるまでジョブは保留状態のままになります。
ノードの構成
トポロジー対応 GPU スケジューリングを有効にするには、各ノードにラベルを付けます。
kubectl label node <your-node-name> ack.node.gpu.schedule=topologyノードでトポロジー対応スケジューリングを有効にすると、そのノードの通常の GPU スケジューリングは無効になります。通常の GPU スケジューリングに戻すには、以下を実行します。
kubectl label node <your-node-name> ack.node.gpu.schedule=default --overwriteジョブの送信
--gputopology=true と --gang を指定して MPI ジョブを送信します。
arena submit mpi --gputopology=true --gang <other-parameters>両方のフラグが必要です。--gputopology=true はトポロジー対応 GPU 選択を有効にし、--gang はすべてのワーカーが同時に開始するようにギャングスケジューリングを強制します。
例 1:VGG16 のトレーニング
この例のクラスターには 2 つのノードがあり、それぞれに 8 つの V100 GPU が搭載されています。
トポロジー対応 GPU スケジューリング
トレーニングジョブを送信します。
arena submit mpi \ --name=tensorflow-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod"ジョブステータスを確認します。
arena get tensorflow-topo-4-vgg16 --type mpijob期待される出力:
Name: tensorflow-topo-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 2m Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-topo-4-vgg16-launcher-lmhjl Running 2m true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-vgg16-worker-0 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-1 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-2 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-3 Running 2m false 1 cn-shanghai.192.168.16.1734 つのワーカーすべてが同じノードに配置され、その高帯域幅 GPU 相互接続を共有しています。
トレーニングログを表示します。
arena logs -f tensorflow-topo-4-vgg16期待される出力:
total images/sec: 991.92
通常の GPU スケジューリング
トポロジーフラグなしでトレーニングジョブを送信します。
arena submit mpi \ --name=tensorflow-4-vgg16 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod"ジョブステータスを確認します。
arena get tensorflow-4-vgg16 --type mpijob期待される出力:
Name: tensorflow-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 9s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-4-vgg16-launcher-xc28k Running 9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-0 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-1 Running 9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-vgg16-worker-2 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-3 Running 9s false 1 cn-shanghai.192.168.16.173ワーカーは 2 つのノードに分散され、各勾配同期ステップでノード間通信が必要です。
トレーニングログを表示します。
arena logs -f tensorflow-4-vgg16期待される出力:
total images/sec: 200.47
例 2:ResNet50 のトレーニング
トポロジー対応 GPU スケジューリング
トレーニングジョブを送信します。
arena submit mpi \ --name=tensorflow-topo-4-resnet50 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod"ジョブステータスを確認します。
arena get tensorflow-topo-4-resnet50 --type mpijob期待される出力:
Name: tensorflow-topo-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 8s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-topo-4-resnet50-launcher-7ln8j Running 8s true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-resnet50-worker-0 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-1 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-2 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-3 Running 8s false 1 cn-shanghai.192.168.16.173トレーニングログを表示します。
arena logs -f tensorflow-topo-4-resnet50期待される出力:
total images/sec: 1471.55
通常の GPU スケジューリング
トポロジーフラグなしでトレーニングジョブを送信します。
arena submit mpi \ --name=tensorflow-4-resnet50 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod"ジョブステータスを確認します。
arena get tensorflow-4-resnet50 --type mpijob期待される出力:
Name: tensorflow-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 9s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-4-resnet50-launcher-q24hv Running 9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-0 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-1 Running 9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-resnet50-worker-2 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-3 Running 9s false 1 cn-shanghai.192.168.16.173トレーニングログを表示します。
arena logs -f tensorflow-4-resnet50期待される出力:
total images/sec: 745.38
パフォーマンス比較
次のチャートは、トポロジー対応 GPU スケジューリングと通常の GPU スケジューリングにおける VGG16 および ResNet50 トレーニングのスループットを示しています。
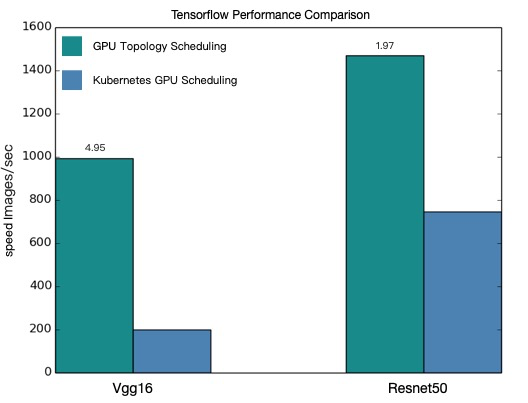
| モデル | トポロジー対応 (images/sec) | 通常 (images/sec) | 改善 |
|---|---|---|---|
| VGG16 | 991.92 | 200.47 | ~4.9x |
| ResNet50 | 1471.55 | 745.38 | ~2.0x |
このトピックのパフォーマンス値は理論値です。実際の結果は、ご利用のモデルアーキテクチャ、クラスター構成、およびネットワーク条件によって異なります。実際の効果を測定するには、上記の例をご自身のクラスターで実行してください。