GPU トポロジー対応スケジューリングは、GPU アクセラレーテッドノードから最適な GPU の組み合わせを選択し、ワーカー間の通信オーバーヘッドを最小限に抑えます。Container Service for Kubernetes (ACK) は、Kubernetes スケジューリングフレームワークを使用してこの機能を実装しており、高帯域幅 GPU 相互接続に依存する分散トレーニングジョブに効果的です。
このトピックでは、ACK で GPU トポロジー対応スケジューリングを有効にし、Arena を使用して PyTorch 分散トレーニングジョブを実行する方法について説明します。
前提条件
開始する前に、以下を確認してください。
-
ACK Pro マネージドクラスター。詳細については、「ACK Pro マネージドクラスターを作成する」をご参照ください。
-
Arena がインストールされていること。詳細については、「Arena GitHub リポジトリ」をご参照ください。
-
ack-ai-installer がインストールされていること。詳細については、「ack-ai-installer のインストール」をご参照ください。
-
以下のバージョン要件を満たすノード。
コンポーネント 必須バージョン Kubernetes V1.18.8 以降 Helm 3.0 以降 Nvidia 418.87.01 以降 NVIDIA Collective Communications Library (NCCL) 2.7+ Docker 19.03.5 OS CentOS 7.6、CentOS 7.7、Ubuntu 16.04 および 18.04、Alibaba Cloud Linux 2 GPU V100
制限事項
-
GPU トポロジー対応スケジューリングは、分散フレームワークでトレーニングされた Message Passing Interface (MPI) ジョブにのみ適用されます。
-
ジョブが開始する前に、ジョブ内のすべての Pod が同時にスケジュール可能である必要があります。リソースが不十分な場合、すべてのリクエストされたリソースが利用可能になるまで、ジョブは保留状態のままになります。
ステップ 1: トポロジー対応スケジューリングのためにノードにラベルを付ける
トポロジー対応スケジューリングを有効にする各ノードに、ack.node.gpu.schedule=topology ラベルを追加します。
kubectl label node <your-node-name> ack.node.gpu.schedule=topologyトポロジー対応スケジューリング用にラベル付けされたノードは、同時に通常の GPU スケジューリングを使用できません。ノードを通常の GPU スケジューリングに復元するには、以下を実行します。
kubectl label node <your-node-name> ack.node.gpu.schedule=default --overwriteステップ 2: 分散トレーニングジョブの送信
--gputopology=true と --gang の両方のフラグを使用して MPI ジョブを送信します。--gang フラグはギャングスケジューリングを有効にし、すべてのワーカーが同時に割り当てられることを保証します。これにより、ノードの GPU が制限されている場合のデッドロックを防ぎます。
arena submit mpi --gputopology=true --gang <other-flags>(オプション) ベンチマークの例とパフォーマンス比較
以下の例では、VGG16 モデルと ResNet50 モデルを使用して、トポロジー対応スケジューリングと通常の GPU スケジューリング間のスループットを比較します。テスト環境では、それぞれ 8 つの V100 GPU を搭載した 2 台のサーバーを使用します。これらのベンチマークをご利用の環境で実行し、ワークロードの改善を評価してください。
VGG16 をトポロジー対応スケジューリングでトレーニングする
-
ジョブを送信します。
arena submit mpi \ --name=pytorch-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=64" -
ジョブのステータスを確認します。
arena get pytorch-topo-4-vgg16 --type mpijob予想される出力:
名前: pytorch-topo-4-vgg16 ステータス: 実行中 名前空間: default 優先度: 該当なし トレーナー: MPIJOB 実行時間: 11 秒 インスタンス: 名前 ステータス 経過時間 チーフノード GPU(要求) ノード ---- ------ --- -------- -------------- ---- pytorch-topo-4-vgg16-launcher-mnjzr 実行中 11 秒 true 0 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-0 実行中 11 秒 false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-1 実行中 11 秒 false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-2 実行中 11 秒 false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-3 実行中 11 秒 false 1 cn-shanghai.192.168.16.173 -
ジョブのログを表示します。
arena logs -f pytorch-topo-4-vgg16予想される出力:
Model: vgg16 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 205.5 img/sec per GPU Iter #1: 205.2 img/sec per GPU Iter #2: 205.1 img/sec per GPU Iter #3: 205.5 img/sec per GPU Iter #4: 205.1 img/sec per GPU Iter #5: 205.1 img/sec per GPU Iter #6: 205.3 img/sec per GPU Iter #7: 204.3 img/sec per GPU Iter #8: 205.0 img/sec per GPU Iter #9: 204.9 img/sec per GPU Img/sec per GPU: 205.1 +-0.6 Total img/sec on 4 GPU(s): 820.5 +-2.5
VGG16 を通常の GPU スケジューリングでトレーニングする
-
ジョブを送信します。
arena submit mpi \ --name=pytorch-4-vgg16 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=64" -
ジョブのステータスを確認します。
arena get pytorch-4-vgg16 --type mpijob予想される出力:
名前: pytorch-4-vgg16 ステータス: 実行中 名前空間: default 優先度: 該当なし トレーナー: MPIJOB 実行時間: 10秒 インスタンス: 名前 ステータス 経過時間 Chief ノード GPU(要求) ノード ---- ------ --- -------- -------------- ---- pytorch-4-vgg16-launcher-qhnxl 実行中 10秒 true 0 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-0 実行中 10秒 false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-1 実行中 10秒 false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-2 実行中 10秒 false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-3 実行中 10秒 false 1 cn-shanghai.192.168.16.173 -
ジョブのログを表示します。
arena logs -f pytorch-4-vgg16予想される出力:
Model: vgg16 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 113.1 img/sec per GPU Iter #1: 109.5 img/sec per GPU Iter #2: 106.5 img/sec per GPU Iter #3: 108.5 img/sec per GPU Iter #4: 108.1 img/sec per GPU Iter #5: 111.2 img/sec per GPU Iter #6: 110.7 img/sec per GPU Iter #7: 109.8 img/sec per GPU Iter #8: 102.8 img/sec per GPU Iter #9: 107.9 img/sec per GPU Img/sec per GPU: 108.8 +-5.3 Total img/sec on 4 GPU(s): 435.2 +-21.1
ResNet50 をトポロジー対応スケジューリングでトレーニングする
-
ジョブを送信します。
arena submit mpi \ --name=pytorch-topo-4-resnet50 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=resnet50 --batch-size=64" -
ジョブのステータスを確認します。
arena get pytorch-topo-4-resnet50 --type mpijob予想される出力:
名前: pytorch-topo-4-resnet50 ステータス: 実行中 名前空間: default 優先度: N/A トレーナー: MPIJOB 期間: 8s インスタンス: 名前 ステータス 経過時間 チーフ GPU(要求) ノード ---- ------ --- -------- -------------- ---- pytorch-topo-4-resnet50-launcher-x7r2n 実行中 8s true 0 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-0 実行中 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-1 実行中 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-2 実行中 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-3 実行中 8s false 1 cn-shanghai.192.168.16.173 -
ジョブのログを表示します。
arena logs -f pytorch-topo-4-resnet50予想される出力:
Model: resnet50 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 331.0 img/sec per GPU Iter #1: 330.6 img/sec per GPU Iter #2: 330.9 img/sec per GPU Iter #3: 330.4 img/sec per GPU Iter #4: 330.7 img/sec per GPU Iter #5: 330.8 img/sec per GPU Iter #6: 329.9 img/sec per GPU Iter #7: 330.5 img/sec per GPU Iter #8: 330.4 img/sec per GPU Iter #9: 329.7 img/sec per GPU Img/sec per GPU: 330.5 +-0.8 Total img/sec on 4 GPU(s): 1321.9 +-3.2
ResNet50 を通常の GPU スケジューリングでトレーニングする
-
ジョブを送信します。
arena submit mpi \ --name=pytorch-4-resnet50 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=resnet50 --batch-size=64" -
ジョブのステータスを確認します。
arena get pytorch-4-resnet50 --type mpijob予想される出力:
名前: pytorch-4-resnet50 ステータス: 実行中 名前空間: default 優先度: 該当なし トレーナー: MPIJOB 実行時間: 10 秒 インスタンス: 名前 ステータス 経過時間 チーフ GPU(要求) ノード ---- ------ --- -------- -------------- ---- pytorch-4-resnet50-launcher-qw5k6 実行中 10 秒 true 0 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-0 実行中 10 秒 false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-1 実行中 10 秒 false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-2 実行中 10 秒 false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-3 実行中 10 秒 false 1 cn-shanghai.192.168.16.173 -
ジョブのログを表示します。
arena logs -f pytorch-4-resnet50予想される出力:
Model: resnet50 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 313.1 img/sec per GPU Iter #1: 312.8 img/sec per GPU Iter #2: 313.0 img/sec per GPU Iter #3: 312.2 img/sec per GPU Iter #4: 313.7 img/sec per GPU Iter #5: 313.2 img/sec per GPU Iter #6: 313.6 img/sec per GPU Iter #7: 313.0 img/sec per GPU Iter #8: 311.3 img/sec per GPU Iter #9: 313.6 img/sec per GPU Img/sec per GPU: 313.0 +-1.3 Total img/sec on 4 GPU(s): 1251.8 +-5.3
パフォーマンス比較
以下の図は、両方のモデルにおけるトポロジー対応スケジューリングと通常の GPU スケジューリング間のスループットを比較したものです。
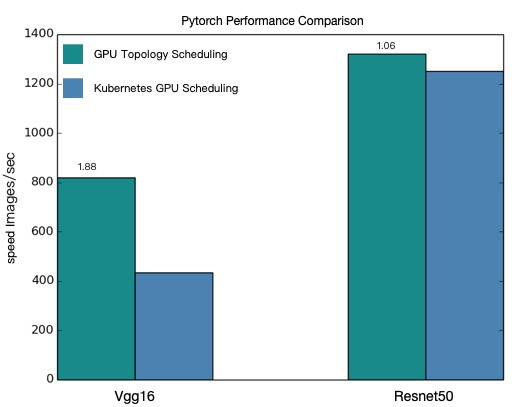
GPU トポロジー対応スケジューリングは、VGG16 と ResNet50 の両方の分散トレーニングジョブでより高いスループットを提供します。
このトピックのパフォーマンス値は理論値です。GPU トポロジー対応スケジューリングのパフォーマンスは、ご利用のモデルアーキテクチャとクラスター構成によって異なります。実際のパフォーマンス統計が優先されます。
次のステップ
-
詳細については、「GPU トポロジー対応スケジューリングの概要」をご参照ください。