ノン・ユニフォーム・メモリアクセス (NUMA) アーキテクチャでは、CPU と GPU 間の通信が頻繁に発生すると、ノード間アクセスが増加し、レイテンシが上昇して帯域幅が制限され、システムパフォーマンスが低下します。この問題に対処するため、Alibaba Cloud Container Service for Kubernetes (ACK) は Scheduler Framework に基づく NUMA トポロジー対応スケジューリングを提供します。この機能により、Pod を最適な NUMA ノードにスケジュールし、NUMA ノード間のクロスアクセスを削減することで、パフォーマンスを向上させます。
仕組み
NUMA ノードは、ノン・ユニフォーム・メモリアクセスシステムの基本単位です。NUMA セットは、1 つのワーカーノード上の複数のノードを統合し、リソースを効率的に割り当ててプロセッサのメモリ競合を軽減します。
GPU を 8 基搭載したマシンでは、通常複数の NUMA ノードが存在します。適切なコアバインディングや同一 NUMA ノード上での GPU-CPU のコロケーションが行われない場合、CPU 競合や NUMA ノード間通信によりパフォーマンスが低下します。
Kubernetes 標準では、kubelet の CPU および NUMA ポリシーを使用して単一マシン上でリソースをバインドしますが、クラスター全体では以下の制限があります。
スケジューラの非認識: Pod の QoS 要件に対してノードの残りリソースを評価できず、AdmissionError 状態となり、クラスターの安定性が損なわれる可能性があります。
配置の制御不能: トポロジーポリシーはノードプロセスのパラメーターに限定されるため、コロケーションワークロードに対してノードアフィニティを利用できません。
ポリシーの複雑さ: ノードは 1 つのポリシーのみをサポートするため、手動によるクラスターパーティション分割とラベル付けが必要となり、リソース利用率が低下します。
ACK では、ack-koordinator の gputopo-device-plugin および ack-koordlet を使用してノードの CPU/GPU トポロジー情報をレポートし、ワークロードの NUMA ポリシー宣言をサポートするトポロジー対応スケジューリングにより、これらの課題を解決します。次の図は、全体的なアーキテクチャを示しています。

前提条件
クラスター要件:
バージョン 1.24 以降の ACK Pro マネージドクラスター。クラスターをスペックアップする方法については、「Upgrade a cluster」をご参照ください。
ノード要件:
GPU アクセラレーション型スーパーコンピューティングクラスターおよび Lingjun ノード向けの sccgn7ex インスタンスファミリーのみがサポートされています。詳細については、「Instance families」をご参照ください。Lingjun ノードに関する情報については、「Manage LINGJUN Clusters and Lingjun nodes」をご参照ください。
トポロジー対応 GPU スケジューリングを有効化するノードには、ラベル
ack.node.gpu.schedule=topologyを手動で追加してください。詳細については、「Enable scheduling features」をご参照ください。
コンポーネント要件:
kube-scheduler コンポーネントのバージョンは 6.4.4 以降である必要があります。詳細については、「kube-scheduler」をご参照ください。kube-scheduler をスペックアップするには、ACK コンソールにログインし、ご利用のクラスター名をクリックして、 を選択します。
ack-koordinator アドオン (旧称 ack-slo-manager) がインストールされている必要があります。
ACK Lingjun クラスターの場合、ack-koordinator を直接インストールできます。
ACK Pro マネージドクラスターの場合、ack-koordinator のパラメーター設定時に、
agentFeaturesFeature Gate 内のNodeTopologyReportフィールドをtrueに設定する必要があります。
GPU トポロジー報告アドオン (gputopo-device-plugin) がインストールされている必要があります。このアドオンは、GPU から CPU への NUMA トポロジー情報を収集・報告するために必要です。インストール手順については、「Install the GPU topology-aware scheduling add-on」をご参照ください。
重要GPU トポロジー対応スケジューリング アドオンを ack-koordinator よりも先にインストールしている場合、ack-koordinator のインストール完了後にスケジューリングアドオンを再起動する必要があります。
制限事項
この機能は、CPU および GPU の NUMA アフィニティを統合的に提供するものであり、レガシーなスタンドアロンスケジューリングポリシーとは相互排他です。トポロジー対応 CPU スケジューリングまたはトポロジー対応 GPU スケジューリングのレガシー版を既に使用しているワークロードに対しては、この機能を有効にしないでください。
CPU と GPU のコロケーションのみがサポートされます。
アプリケーション Pod 内のすべてのコンテナについて、CPU リクエストは整数値(単位:コア)である必要があり、かつリクエスト値とリミット値が一致している必要があります。
アプリケーション Pod 内のコンテナが GPU リソースをリクエストする際は、
aliyun.com/gpuを使用し、かつ物理 GPU カード単位で指定する必要があります。
課金
この機能を使用するには Cloud-Native AI Suite のインストールが必要であり、追加料金が発生する場合があります。詳細については、「Billing of the cloud-native AI suite」をご参照ください。
ワーカーノードリソース: ack-koordinator はワーカーノード上でセルフマネージドコンポーネントとして実行され、CPU およびメモリを消費します。インストール時に各モジュールのリソースリクエストを構成してください。
Prometheus 監視メトリクス: ack-koordinator は、リソースプロファイリングや詳細スケジューリングなどの機能のために Prometheus 形式で監視メトリクスを公開します。インストール時に Enable Prometheus Metrics for ACK-Koordinator を選択し、Alibaba Cloud Prometheus を使用する場合、これらのメトリクスはカスタムメトリクスとして扱われ、クラスター規模およびアプリケーション数に応じた料金が発生します。このオプションを有効にする前に、Prometheus 課金ドキュメントを確認し、無料クォータおよび課金ポリシーを理解してください。課金および使用量クエリを通じて使用量を監視することも可能です。
NUMA トポロジー対応スケジューリングの使用
Pod の仕様に以下のアノテーションを追加することで、NUMA トポロジー対応スケジューリングを有効化できます。
apiVersion: v1
kind: Pod
metadata:
name: example
annotations:
cpuset-scheduler: required # CPU バインディングを有効化
scheduling.alibabacloud.com/numa-topology-spec: | # この Pod の NUMA トポロジー要件を指定
{
"numaTopologyPolicy": "SingleNUMANode",
"singleNUMANodeExclusive": "Preferred"
}
spec:
containers:
- name: example
image: ghcr.io/huggingface/text-generation-inference:1.4
resources:
limits:
aliyun.com/gpu: '4'
cpu: '24'
requests:
aliyun.com/gpu: '4'
cpu: '24'次の表は、NUMA トポロジー対応スケジューリングのパラメーターについて説明しています。
パラメーター | 説明 |
| CPU とデバイスのコロケーションを要求する Pod を指定します。 現在サポートされている値は |
| Pod のスケジューリング時に使用する NUMA 配置ポリシーです。
|
| NUMA ノード上での Pod 配置における排他ポリシーを定義します。 説明 NUMA ノードタイプ:
|
パフォーマンス比較
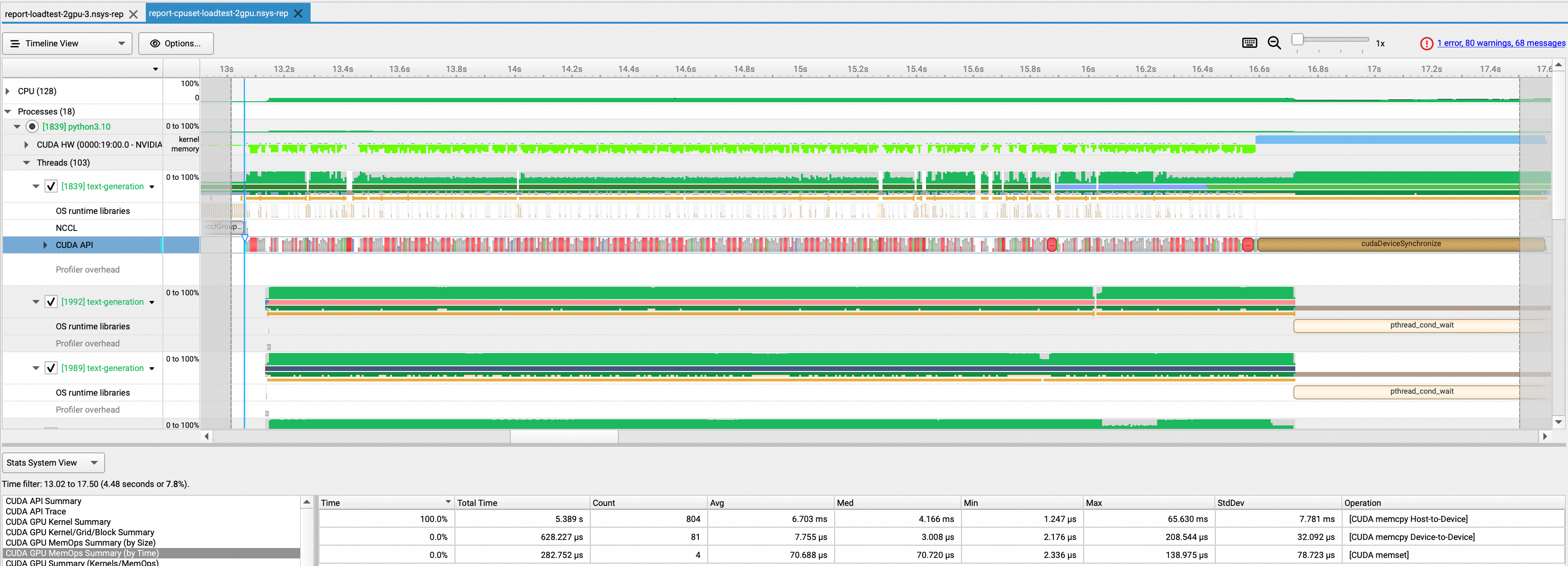
本セクションでは、モデルロード時間の測定を通じて NUMA トポロジー対応スケジューリングによるパフォーマンス向上を示します。本テストでは、text-generation-inference ツールを使用して 4 枚の GPU カード上でモデルをロードし、NVIDIA Nsight Systems を用いてコアバインディング有効化前後の GPU ロード速度の変化を測定します。
本実験では Lingjun ノード、text-generation-inference v1.4 (TGI ダウンロードページより入手可能)、および NVIDIA Nsight Systems (NSight ツールダウンロードページより入手可能) を使用しています。
テスト結果は使用ツールおよび環境によって異なります。本例のパフォーマンスデータは NVIDIA Nsight Systems を使用して収集したものであり、実際の結果は異なる場合があります。
トポロジー対応スケジューリングなし
次の YAML は、トポロジー対応スケジューリングを無効にした同一シナリオにおけるアプリケーション構成を示しています。
モデルのロードに 15.9 秒かかりました。

トポロジー対応スケジューリングあり
次の YAML は、トポロジー対応スケジューリングを有効にした同一シナリオにおけるアプリケーション構成を示しています。
この機能を有効にするには、GPU リソースリクエストを標準の nvidia.com/gpu から aliyun.com/gpu に変更する必要があります。これにより、専用スケジューラが GPU-CPU NUMA アフィニティを識別・管理できるようになります。
モデルのロードに 5.4 秒かかり、ベースラインと比較して 66 % 向上しました。