CoreDNS は、Container Service for Kubernetes (ACK) クラスターにおける DNS ベースのサービス検出のデフォルトプラグインです。本トピックでは、CoreDNS ダッシュボードの表示方法、各メトリックの解釈方法、およびダッシュボードを活用した一般的な DNS 問題のトラブルシューティングについて説明します。
前提条件
作業を開始する前に、以下の項目を確認してください。
ack-arms-prometheus コンポーネントをインストールしていること。詳細については、「コンポーネントの管理」をご参照ください。
CoreDNS ダッシュボードの表示
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、対象のクラスターを見つけ、その名前をクリックします。左側のメニューで、[運用] > [Prometheus モニタリング] を選択します。
[Prometheus モニタリング] ページで、[ネットワークモニタリング] タブをクリックし、次に [CoreDNS] タブをクリックしてダッシュボードを表示します。
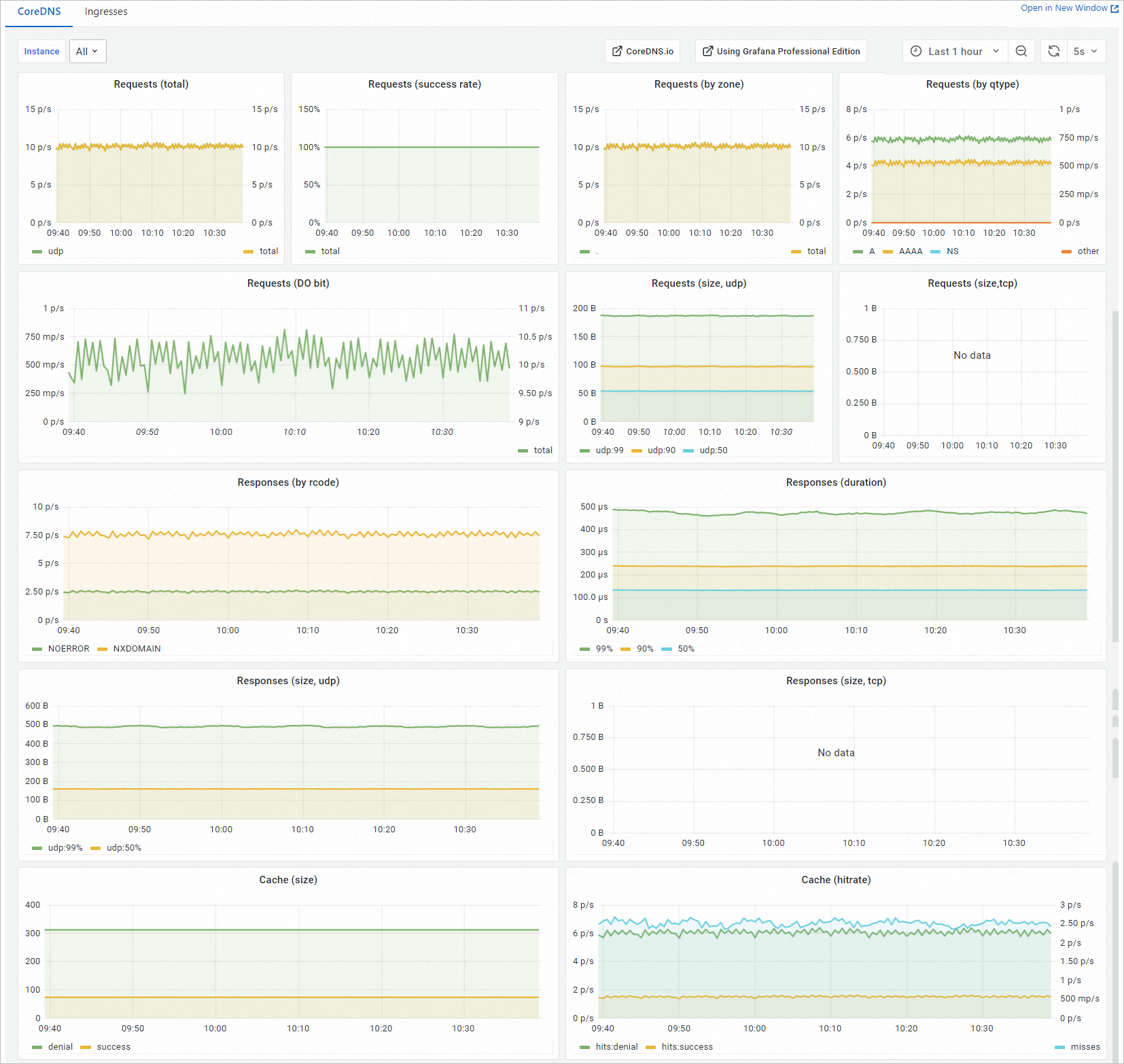
ダッシュボードメトリック
CoreDNS ダッシュボードは Prometheus クエリ言語 (PromQL) クエリに基づいて構築されており、リクエストスループット、応答動作、キャッシュパフォーマンスを表示します。メトリックは以下の 3 つのカテゴリに分類されています。
リクエストメトリック
| Metric | Unit | Description |
|---|---|---|
| Requests (total) | Requests/s | CoreDNS が 1 秒あたりに受信する DNS リクエストの総数。 |
| Requests (success rate) | % | NOERROR または NXDOMAIN を返したリクエストの割合。両方の応答コードは成功と見なされます。 |
| Requests (by zone) | Requests/s | DNS ゾーンごとに集計されたリクエストレート。 |
| Requests (by qtype) | Requests/s | DNS クエリタイプ(例:A、AAAA、MX)ごとに集計されたリクエストレート。 |
| Requests (DO bit) | Requests/s | DNSSEC OK (DO) ビットを含むクエリのリクエストレート。 |
| Requests (size, udp) | Bytes | CoreDNS が受信した各 UDP リクエストパケットのサイズ。 |
| Requests (size, tcp) | Bytes | CoreDNS が受信した各 TCP リクエストパケットのサイズ。 |
応答メトリック
| Metric | Unit | Description |
|---|---|---|
| Responses (by rcode) | Requests/s | DNS 応答コード(例:NOERROR、NXDOMAIN、SERVFAIL)ごとに集計された応答レート。 |
| Responses (duration) | Seconds | レスポンスレイテンシー(99 パーセンタイル、90 パーセンタイル、50 パーセンタイル)。 |
| Responses (size, udp) | Bytes | UDP 応答パケットサイズ(99 パーセンタイルおよび 50 パーセンタイル)。 |
| Responses (size, tcp) | Bytes | TCP 応答パケットサイズ(99 パーセンタイルおよび 50 パーセンタイル)。 |
キャッシュメトリック
| Metric | Unit | Description |
|---|---|---|
| Cache (size) | N/A | CoreDNS キャッシュ内のエントリ総数。 |
| Cache (hitrate) | % | キャッシュヒット率。 |
一般的な異常事象
以下の表は、重大度別に一般的な CoreDNS の異常事象、関連するメトリック、考えられる原因、および推奨される操作を示しています。
| Severity | Anomaly | Where to look | Likely causes | What to do |
|---|---|---|---|---|
| Critical | SERVFAIL 応答レートが高い | Responses (by rcode) | 上流 DNS サーバーが到達不能 | CoreDNS ログを確認し、SERVFAIL 応答をトリガーしているドメイン名を特定したうえで、上流 DNS の接続性をトラブルシューティングしてください。「CoreDNS ログの収集と分析」をご参照ください。 |
| Critical | レスポンスレイテンシーが高い | Responses (duration) | 多数のアプリケーションが外部ドメイン名を解決している | Responses (duration) チャートの 99 パーセンタイルレイテンシーを確認し、レイテンシーの原因を特定してください。 |
| Warning | リクエストレートが急増している | Requests (total) | アプリケーショントラフィックの急増、または過剰な DNS クエリを発生させる誤ったアプリケーション設定 | CoreDNS ログで最も頻繁にアクセスされているドメイン名を確認し、増加が予期されたものかどうかを判断してください。予期されたものである場合は、CoreDNS の Pod 数を増やすことでスケーリングしてください(「CoreDNS の高可用性の確保」をご参照ください)。また、DNS トラフィックをオフロードするために NodeLocal DNSCache を有効にしてください。ログ分析の手順については、「CoreDNS ログの収集と分析」をご参照ください。 |
自己管理型 Prometheus 向けのメトリック
ARMS を有効化していない場合は、自己管理型 Prometheus インスタンスを使用して CoreDNS をモニタリングします。以下の表は、CoreDNS 1.9.3 で利用可能な CoreDNS メトリックの一覧です。完全な一覧については、CoreDNS メトリックドキュメントをご参照ください。
| Metric | Data type | Labels | Description |
|---|---|---|---|
requests_total | Counter | server, zone, proto, family, type | DNS クエリ総数。 |
request_duration_seconds | Histogram | server, zone | DNS クエリ応答時間。 |
request_size_bytes | Histogram | server, zone, proto | DNS クエリパケットサイズ。ヒストグラムバケットのしきい値(バイト):0、100、200、300、400、511、1023、2047、4095、8291、16000、32000、48000、64000。 |
do_requests_total | Counter | server, zone | DO ビットを含む DNS クエリの総数。 |
response_size_bytes | Histogram | server, zone, proto | DNS 応答パケットサイズ。ヒストグラムバケットのしきい値(バイト):0、100、200、300、400、511、1023、2047、4095、8291、16000、32000、48000、64000。 |
responses_total | Counter | server, zone, rcode, plugin | DNS 応答総数。 |
panics_total | Counter | — | CoreDNS のパニック発生総数。 |
plugin_enabled | Gauge | server, zone, name | プラグインが有効かどうか。 |
https_responses_total | Counter | server, status | DNS-over-HTTPS (DoH) クエリ総数。 |