Container Service for Kubernetes は、コントロールプレーン、ノード、ワークロード、負荷分散の高可用性 (HA) を提供します。
本ドキュメントのガイダンス
Container Service for Kubernetes のクラスター開発者および管理者を対象としています。本ドキュメントでは、HA クラスターの計画と構築に関する一般的な推奨事項を示します。実際の構成は、クラスター環境とビジネス要件に応じて異なります。本ドキュメントでは、クラスターのコントロールプレーンとデータプレーンの両方における HA 構成について説明します。
|
ドキュメント構成 |
保守担当 |
適用可能なクラスタータイプ |
|
ACK により管理されます。 |
ACK マネージドクラスター (Pro Edition、Basic Edition)、ACK Serverless クラスター (Pro Edition、Basic Edition)、ACK Edge クラスター、LINGJUN Clusters などの一部のマネージド ACK クラスターにのみ適用されます。ACK 専用クラスターや登録済みクラスターなどの他のクラスタータイプは対象外です (これらのコントロールプレーンはお客様が保守します) が、これらの構成を参考にすることができます。 |
|
|
お客様が保守します。 |
共通。 |
|
クラスターアーキテクチャの例
ACK クラスターは、コントロールプレーンと通常ノードまたは仮想ノードという 2 つの主要部分で構成されます。
-
コントロールプレーンは、ワークロードのスケジューリングや状態の維持など、クラスターを管理します。例としてACK マネージドクラスターがあります。ACK マネージドクラスターは、Kubernetes-on-Kubernetes アーキテクチャを使用して、Kube API Server、etcd、Kube Scheduler などのコントロールプレーンコンポーネントをホストします。
-
通常ノードまたは仮想ノード:ACK クラスターは通常ノード (ECS インスタンス) と仮想ノードをサポートします。ノードはワークロードを実行し、コンテナにリソースを提供します。
ACK クラスターは、デフォルトでマルチアベイラビリティーゾーン (マルチ AZ) の HA デプロイを提供します。次の図は、ACK マネージドクラスターのアーキテクチャを示しています。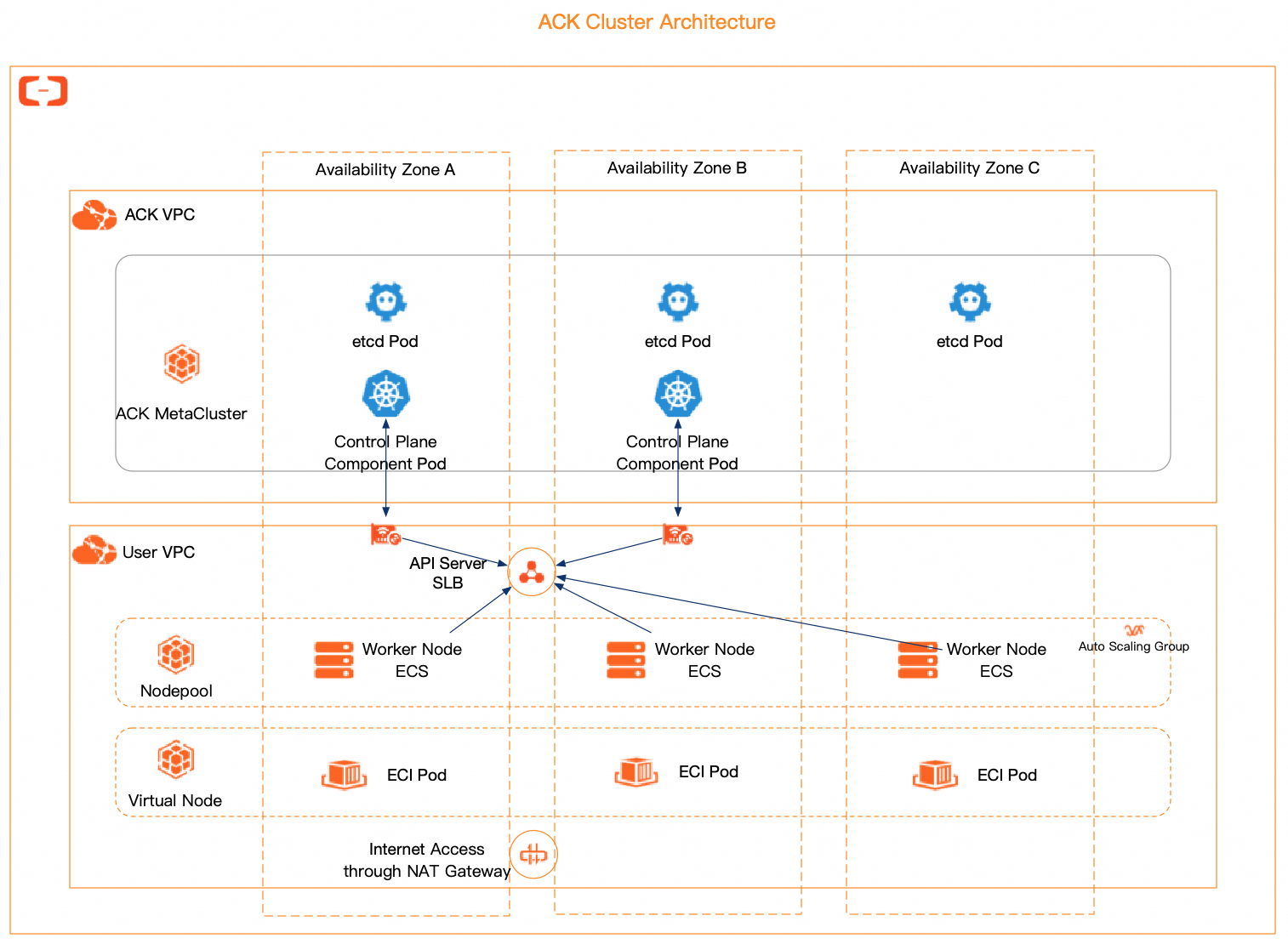
コントロールプレーンアーキテクチャの高可用性
ACK マネージドクラスター(Pro 版および Basic 版)、ACK Serverless クラスター(Pro 版および Basic 版)、ACK Edge クラスター、および LINGJUN クラスターなどのマネージド ACK クラスターでは、ACK がコントロールプレーンと、kube-apiserver、etcd、kube-scheduler などのコンポーネントを管理します。
-
マルチゾーンリージョン:すべてのマネージドコンポーネントは、マルチレプリカかつマルチ AZ での均等分散配置を採用し、単一ゾーンまたはノード障害時でもサービス継続性を確保します。
-
シングルゾーンリージョン:すべてのマネージドコンポーネントは、マルチレプリカかつ複数ノードへの分散配置を採用し、単一ノード障害時でもサービス継続性を確保します。
具体的には、etcd は少なくとも 3 つのレプリカで、kube-apiserver は少なくとも 2 つのレプリカで構成されます。すべての kube-apiserver レプリカは、Elastic Network Interface (ENI) を介してクラスター VPC に接続します。kubelet と Kube Proxy は、API Server の Classic Load Balancer (CLB) または ENI を介して kube-apiserver に接続します。
すべてのコアマネージドコンポーネントは、CPU やメモリなどのリソース使用率に基づいて弾性的にスケールし、API Server の要件を動的に満たしつつ、安定したサービスレベルアグリーメント (SLA) を保証します。
コントロールプレーンのデフォルトのマルチゾーン HA に加えて、データプレーンの HA を構成してください:ノードプールと仮想ノードの高可用性構成、ワークロードの高可用性構成、負荷分散の高可用性構成、アドオンの推奨構成。
ノードプールと仮想ノードの高可用性構成
ACK クラスターは通常ノード (ECS インスタンス) と仮想ノードをサポートし、アップグレード、スケーリング、運用保守などの操作を ノードプールで管理します。安定したトラフィックや予測可能なトラフィックには ECS インスタンスを使用し、突発的なトラフィックにはコスト削減のために 仮想ノードを使用してください。マネージドノードプールの概要をご参照ください。
ノードプールの高可用性構成
ノードの自動スケーリング、デプロイメントセット、マルチ AZ デプロイ、Kubernetes のトポロジー拡散制約を組み合わせて、障害ドメイン間でサービスを分離し、単一障害点を低減します。
ノードの自動スケーリングの構成
各ノードプールは Auto Scaling グループ (ESS) に関連付けられており、負荷スケジューリングまたはクラスターリソース層での手動および自動スケーリングをサポートします。Auto scaling および ノードの自動スケーリングの有効化をご参照ください。
デプロイメントセットの有効化
デプロイメントセットは、ECS インスタンスを物理サーバー間に分散し、同一筐体配置による障害を防ぎます。ノードプールにデプロイメントセットを指定すると、スケールアウトされたインスタンスが別々の物理マシンに配置され、ディザスタリカバリと可用性が向上します。ノードプールのデプロイメントセットに関するベストプラクティスをご参照ください。
マルチ AZ 分散の構成
ACK はマルチゾーンノードプールをサポートします。ノードプールの作成時に、異なるゾーンの複数の vSwitch を選択し、[スケーリングポリシー] を [分散バランスポリシー] に設定して、ECS インスタンスをゾーン間で均等に分散します。在庫切れによってリソースの偏りが発生した場合は、リバランス操作を実行してください。ノードの自動スケーリングの有効化をご参照ください。

トポロジー拡散制約の有効化
ノードの自動スケーリング、デプロイメントセット、マルチゾーン分散に Kubernetes の トポロジー拡散制約を組み合わせることで、障害ドメインの分離レベルを段階的に高められます。ACK ノードプールのノードには、kubernetes.io/hostname、topology.kubernetes.io/zone、topology.kubernetes.io/region などのトポロジーラベルが自動的に付与されます。これらの制約を使用して障害ドメイン間の Pod の分散を制御し、インフラ障害に対する耐性を向上させます。

ACK クラスターは トポロジーアウェアスケジューリング をサポートします。たとえば、トポロジードメインをまたいで Pod をリトライしたり、同一の低レイテンシーなデプロイメントセット内の ECS インスタンスに Pod をスケジューリングしたりできます。
仮想ノードの高可用性構成
ACK の仮想ノードは、基盤となる ECS サーバーを管理することなく、Elastic Container Instance (ECI) 上に Pod をスケジューリングします。ECI インスタンスはオンデマンドで作成され、秒単位の従量課金で課金されます。
急速な水平スケーリングやバッチ Job の起動により、ゾーン内のインスタンス在庫や vSwitch の IP アドレスが枯渇し、ECI の作成に失敗する場合があります。ACK Serverless クラスターのマルチゾーン機能により、ECI の作成成功率が向上します。
仮想ノードの ECI Profile を構成し、マルチゾーンデプロイのために異なるゾーンの vSwitch を指定します。
-
ECI は、すべての vSwitch に対して Pod 作成リクエストを分散します。
-
vSwitch の在庫が不足している場合、ECI は自動的に次の vSwitch を試行します。
kube-system/eci-profile ConfigMap の vSwitchIds フィールドを変更します。vSwitch ID をカンマ (,) 区切りで追加してください。変更は直ちに反映されます。マルチゾーン ECI Pod の作成をご参照ください。
kubectl -n kube-system edit cm eci-profileapiVersion: v1
data:
kube-proxy: "true"
privatezone: "true"
quota-cpu: "192000"
quota-memory: 640Ti
quota-pods: "4000"
regionId: cn-hangzhou
resourcegroup: ""
securitygroupId: sg-xxx
vpcId: vpc-xxx
vSwitchIds: vsw-xxx,vsw-yyy,vsw-zzz
kind: ConfigMapワークロードの高可用性構成
トポロジー拡散制約、Pod のアンチアフィニティ、PodDisruptionBudget (PDB)、自己修復を伴うヘルスチェックを構成して、Pod が稼働し続けるか、または障害から迅速に復旧するようにします。
トポロジー拡散制約の構成
トポロジー拡散制約により、ノードおよびゾーン間で Pod を均等に分散し、アプリケーションの可用性を向上させます。これは Deployment、StatefulSet、DaemonSet、Job、CronJob などのワークロードタイプに適用されます。
maxSkew.topologyKey を設定して、ゾーン間でワークロードを均等に分散するなど、トポロジードメイン間の Pod 分散を制御します。次に例を示します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-run-per-zone
spec:
replicas: 3
selector:
matchLabels:
app: app-run-per-zone
template:
metadata:
labels:
app: app-run-per-zone
spec:
containers:
- name: app-container
image: app-image
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: app-run-per-zonePod のアンチアフィニティの構成
Pod アンチアフィニティにより、同一ノードへの Pod のスケジューリングを防ぎ、障害分離を向上させます。次に例を示します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-run-per-node
spec:
replicas: 3
selector:
matchLabels:
app: app-run-per-node
template:
metadata:
labels:
app: app-run-per-node
spec:
containers:
- name: app-container
image: app-image
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- app-run-per-node
topologyKey: "kubernetes.io/hostname"トポロジー拡散制約を使用して、ノードあたり 1 つの Pod に制限することもできます。topologyKey: "kubernetes.io/hostname" を指定すると、各ノードがトポロジードメインとして扱われます。
次の例では、maxSkew を 1、topologyKey を "kubernetes.io/hostname"、whenUnsatisfiable を DoNotSchedule に設定し、ノード間の Pod 数の差を最大 1 に制限して均等に分散します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app-image
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: my-appPodDisruptionBudget の構成
PodDisruptionBudget (PDB) は、ノードのメンテナンスまたは障害発生時に利用可能なレプリカの最小数を定義し、同時に終了されるレプリカが多すぎることを防ぎます。次に例を示します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-with-pdb
spec:
replicas: 3
selector:
matchLabels:
app: app-with-pdb
template:
metadata:
labels:
app: app-with-pdb
spec:
containers:
- name: app-container
image: app-container-image
ports:
- containerPort: 80
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: pdb-for-app
spec:
minAvailable: 2
selector:
matchLabels:
app: app-with-pdb
Pod のヘルスチェックと自己修復の構成
livenessProbe、readinessProbe、startupProbe を再起動ポリシーとともに構成してコンテナのヘルスを監視し、自己修復を有効にします。次に例を示します。
apiVersion: v1
kind: Pod
metadata:
name: app-with-probe
spec:
containers:
- name: app-container
image: app-image
livenessProbe:
httpGet:
path: /health
port: 80
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
startupProbe:
exec:
command:
- cat
- /tmp/ready
initialDelaySeconds: 20
periodSeconds: 15
restartPolicy: Always負荷分散の高可用性構成
Server Load Balancer (SLB) インスタンスのプライマリゾーンとセカンダリゾーンを指定し、トポロジーヒントを有効にして、サービスの安定性と障害分離を向上させます。
CLB インスタンスのプライマリゾーンとセカンダリゾーンの指定
CLB は、ほとんどのリージョンで複数ゾーンにまたがってデプロイされ、データセンター間のディザスタリカバリを実現します。Service アノテーションを使用して CLB インスタンスのプライマリゾーンとセカンダリゾーンを指定し、ノードプールの ECS インスタンスのゾーンに合わせることで、ゾーン間のデータ転送を削減します。CLB をサポートするリージョンとゾーンおよび CLB インスタンス作成時にプライマリゾーンとセカンダリゾーンを指定するをご参照ください。
次に例を示します。
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-master-zoneid: "cn-hangzhou-b"
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-slave-zoneid: "cn-hangzhou-i"
name: nginx
namespace: default
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancerトポロジーヒントの有効化
Kubernetes 1.23 では、ゾーン間トラフィックを削減し、ネットワークパフォーマンスを向上させるために、トポロジーアウェアルーティング (トポロジーヒント) が導入されました。
Service でこの機能を有効にします。ゾーン内に十分なエンドポイントがある場合、EndpointSlice コントローラーはトポロジーヒントに基づいてリクエスト元に近いエンドポイントへのルーティングを優先し、同一ゾーン内でトラフィックを完結させてコストを削減します。Topology Aware Routing をご参照ください。
アドオンの推奨構成
ACK は、クラスター機能を拡張するためのさまざまなアドオンを提供します。アドオンの概要とリリースノートおよび アドオンの管理をご参照ください。
Nginx Ingress Controller の適切なデプロイ
Nginx Ingress Controller を異なるノードに分散して、リソース競合と単一障害点を防ぎます。パフォーマンスと安定性を高めるために、専用ノードの使用を推奨します。
OOM によるトラフィック中断を防ぐために、Nginx Ingress Controller のリソース制限は避けてください。制限が必要な場合は、CPU を少なくとも 1000m、メモリを少なくとも 2 GiB に設定します。Nginx Ingress Controller の使用推奨事項をご参照ください。
ALB Ingress または MSE Ingress コントローラーの場合は、作成時に複数ゾーンを構成してください。クラウドネイティブゲートウェイの作成、ALB Ingress を作成して Service を公開する、Nginx Ingress、ALB Ingress、MSE Ingress の比較をご参照ください。
CoreDNS の適切なデプロイ
CoreDNS のレプリカを異なるゾーンおよびノードに分散して、単一障害点を回避します。CoreDNS はデフォルトでノード単位の弱いアンチアフィニティを使用しますが、リソース不足によりレプリカが 1 つのノードに集中する場合があります。この場合は、Pod を削除して再スケジューリングしてください。
DNS の QPS とレイテンシーを維持するために、CoreDNS ノードに十分な CPU とメモリがあることを確認してください。DNS のベストプラクティスをご参照ください。
関連ドキュメント
-
ワーカーノードには、より大きな ECS インスタンスタイプを使用してください。推奨 ECS インスタンスタイプ構成をご参照ください。
-
大規模な ACK マネージドクラスター Pro Edition のデプロイ (通常 500 ノードまたは 10,000 Pod を超える場合) については、大規模クラスターの使用推奨事項をご参照ください。
-
ノードとノードプールのベストプラクティスをご参照ください。
-
Auto scaling のベストプラクティスをご参照ください。