このトピックでは、Spark の動的リソース割り当て機能を構成および使用して、クラスタリソース使用効率の最大化、リソースアイドル時間の削減、タスク実行の柔軟性とシステム全体のパフォーマンスの向上を実現する方法について説明します。
動的リソース割り当てとは
動的リソース割り当ては、Spark が提供するメカニズムであり、ワークロードサイズに基づいてジョブが使用する計算リソースを動的に調整します。長時間アイドル状態のエグゼキュータは、ドライバによって自動的に解放され、リソースがクラスタに戻されます。特定のジョブが長時間スケジュールされている場合、ドライバはジョブを実行するために追加のエグゼキュータを要求します。動的リソース割り当て機能により、Spark はワークロードの変化に柔軟に対応し、リソース不足によるジョブ実行時間の過剰な増加や、リソース過剰によるリソースの浪費を回避できます。これにより、クラスタ全体のリソース使用率が向上します。
リソース割り当てポリシー
動的リソース割り当て機能を有効にして、ジョブがスケジュール待ちの場合、ドライバは追加のエグゼキュータを要求します。ジョブの待ち時間が spark.dynamicAllocation.schedulerBacklogTimeout パラメータの値を超えると、ドライバはエグゼキュータをバッチで要求します。このパラメータのデフォルト値は 1 秒です。spark.dynamicAllocation.sustainedSchedulerBacklogTimeout パラメータのデフォルト値は 1 秒です。残りのタスクをスケジュールする必要がある場合、ドライバは 1 秒ごとに追加のエグゼキュータを継続的に要求します。各バッチで要求されるエグゼキュータの数は指数関数的に増加します。たとえば、最初のバッチは 1 つのエグゼキュータを要求し、2 番目のバッチは 2 つのエグゼキュータを要求し、3 番目のバッチは 4 つのエグゼキュータを要求し、4 番目のバッチは 8 つのエグゼキュータを要求します。後続のバッチは、同じパターンでエグゼキュータを要求します。
リソース解放ポリシー
アイドル状態のエグゼキュータの場合、アイドル時間が spark.dynamicAllocation.executorIdleTimeout パラメータの値を超えると、ドライバはエグゼキュータを自動的に解放してリソース使用率を最適化します。このパラメータのデフォルト値は 60 秒です。
動的リソース割り当てを有効にする
Spark の動的リソース割り当て機能は、Standalone、YARN、Mesos、Kubernetes の実行モードで使用できます。デフォルトでは、この機能は無効になっています。動的リソース割り当て機能を有効にするには、spark.dynamicAllocation.enabled パラメータを true に設定し、以下の構成を実行します。
External Shuffle Service (ESS) を有効にする:
spark.shuffle.service.enabledをtrueに設定し、同じクラスタ内の各ワーカーノードで ESS を構成します。シャッフルデータの追跡を有効にする:
spark.dynamicAllocation.shuffleTracking.enabledをtrueに設定すると、Spark はシャッフルデータの場所とステータスを追跡し、データが失われないようにし、ビジネス要件に基づいて再計算できるようにします。ノードの廃止を有効にする:
spark.decommission.enabledおよびspark.storage.decommission.shuffleBlocks.enabledをtrueに設定すると、Spark は廃止されたノード上のシャッフルデータブロックを他の使用可能なノードにアクティブにコピーします。ShuffleDataIO プラグインを構成する:
spark.shuffle.sort.io.plugin.classパラメータを構成して、ShuffleDataIO プラグインクラスを指定します。シャッフルデータのカスタム I/O 操作を指定して、データをさまざまなストレージシステムに書き込むこともできます。
構成方法は、モードによって異なります。
スタンドアロンモードの Spark アプリケーション: ESS を有効にするだけで済みます。
Kubernetes 上の Spark:
Celeborn を Remote Shuffle Service (RSS) として使用しない場合、
spark.dynamicAllocation.shuffleTracking.enabledをtrueに設定して、シャッフルデータの追跡を有効にします。Celeborn を RSS として使用する:
Spark のバージョンが 3.5.0 以降の場合、
spark.shuffle.sort.io.plugin.classをorg.apache.spark.shuffle.celeborn.CelebornShuffleDataIOに設定して、ShuffleDataIO プラグインを構成します。Spark のバージョンが 3.5.0 より前の場合、Spark のバージョンにパッチを適用する必要があります。追加の構成は必要ありません。詳細については、「Spark の動的割り当てのサポート」をご参照ください。
Spark のバージョンが 3.4.0 以降の場合、
spark.dynamicAllocation.shuffleTracking.enabledをfalseに設定して、エグゼキュータがアイドル状態のときに解放されないようにすることをお勧めします。
この例では、Celeborn を RSS として使用しないシナリオを含め、Kubernetes モードで Spark の RSS を構成する方法について説明します。
前提条件
ack-spark-operator コンポーネント がインストールされていること。
説明この例では、デプロイに
spark.jobNamespaces=["spark"]が使用されています。別の名前空間が必要な場合は、ビジネス要件に基づいて名前空間フィールドを変更してください。ack-spark-history-server コンポーネント がデプロイされていること。
説明この例では、
nas-pvという名前の永続ボリューム (PV) とnas-pvcという名前の永続ボリューム要求 (PVC) が作成され、Spark History Server は NAS ファイルシステム (NAS) の/spark/event-logsパスから Spark イベントログを読み取るように構成されています。(オプション) ack-celeborn コンポーネント がデプロイされていること。
手順
Celeborn を RSS として使用しない
この例では、Spark 3.5.4 を使用しています。Celeborn を RSS として使用せず、動的リソース割り当てを有効にする場合は、次のパラメータを構成します。
動的リソース割り当てを有効にする:
spark.dynamicAllocation.enabledを"true"に設定します。シャッフルデータの追跡を有効にし、ESS に依存せずに動的リソース割り当てを実装する:
spark.dynamicAllocation.shuffleTracking.enabled: "true"。
spark-pagerank-dra.yamlという名前のファイルを作成し、次の内容をファイルにコピーします。このファイルは、SparkApplication を作成するために使用されます。apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: spark-pagerank-dra namespace: spark spec: type: Scala mode: cluster # <SPARK_IMAGE> を Spark イメージに置き換えます。 image: <SPARK_IMAGE> mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar mainClass: org.apache.spark.examples.SparkPageRank arguments: # <OSS_BUCKET> を OSS バケットの名前に置き換えます。 - oss://<OSS_BUCKET>/data/pagerank_dataset.txt - "10" sparkVersion: 3.5.4 hadoopConf: # OSS データにアクセスするには、oss:// 形式を使用します。 fs.AbstractFileSystem.oss.impl: org.apache.hadoop.fs.aliyun.oss.OSS fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem # OSS にアクセスするためのエンドポイント。<OSS_ENDPOINT> を OSS アクセスエンドポイントに置き換える必要があります。 # たとえば、中国 (北京) リージョンで OSS にアクセスするための内部エンドポイントは oss-cn-beijing-internal.aliyuncs.com です。 fs.oss.endpoint: <OSS_ENDPOINT> # 環境変数から OSS アクセス認証情報を取得します。 fs.oss.credentials.provider: com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider sparkConf: # ==================== # イベントログ # ==================== spark.eventLog.enabled: "true" spark.eventLog.dir: file:///mnt/nas/spark/event-logs # ==================== # 動的リソース割り当て # ==================== # 動的リソース割り当てを有効にする spark.dynamicAllocation.enabled: "true" # シャッフルファイルの追跡を有効にし、ESS に依存せずに動的リソース割り当てを実装します。 spark.dynamicAllocation.shuffleTracking.enabled: "true" # エグゼキュータ数の初期値。 spark.dynamicAllocation.initialExecutors: "1" # エグゼキュータの最小数。 spark.dynamicAllocation.minExecutors: "0" # エグゼキュータの最大数。 spark.dynamicAllocation.maxExecutors: "5" # エグゼキュータのアイドルタイムアウト期間。タイムアウト期間を超えると、エグゼキュータは解放されます。 spark.dynamicAllocation.executorIdleTimeout: 60s # データブロックをキャッシュしたエグゼキュータのアイドルタイムアウト期間。タイムアウト期間を超えると、エグゼキュータは解放されます。デフォルト値は infinity で、データブロックが解放されないことを指定します。 # spark.dynamicAllocation.cachedExecutorIdleTimeout: # ジョブが指定されたスケジュール時間を超えると、追加のエグゼキュータが要求されます。 spark.dynamicAllocation.schedulerBacklogTimeout: 1s # 各時間間隔の後、後続のバッチのエグゼキュータが要求されます。 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout: 1s driver: cores: 1 coreLimit: 1200m memory: 512m envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas serviceAccount: spark-operator-spark executor: cores: 1 coreLimit: "2" memory: 8g envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas volumes: - name: nas persistentVolumeClaim: claimName: nas-pvc restartPolicy: type: Never説明上記のサンプルジョブで使用される Spark イメージには、Hadoop OSS SDK の依存関係が含まれている必要があります。イメージをビルドするには、次の Dockerfile を使用し、イメージをイメージリポジトリにプッシュします。
ARG SPARK_IMAGE=spark:3.5.4 FROM ${SPARK_IMAGE} # Hadoop Aliyun OSS サポートの依存関係を追加します ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aliyun/3.3.4/hadoop-aliyun-3.3.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.17.4/aliyun-sdk-oss-3.17.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/jdom/jdom2/2.0.6.1/jdom2-2.0.6.1.jar ${SPARK_HOME}/jars次のコマンドを実行して、Spark ジョブを送信します。
kubectl apply -f spark-pagerank-dra.yaml期待される出力:
sparkapplication.sparkoperator.k8s.io/spark-pagerank-dra createdドライバログを表示します。
kubectl logs -n spark spark-pagerank-dra-driver | grep -a2 -b2 "Going to request"期待される出力:
3544-25/01/16 03:26:04 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using current context from users K8S config file 3674-25/01/16 03:26:06 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances 3848:25/01/16 03:26:06 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 1, known: 0, sharedSlotFromPendingPods: 2147483647. 4026-25/01/16 03:26:06 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs 4106-25/01/16 03:26:06 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script -- 10410-25/01/16 03:26:15 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (192.168.95.190, executor 1, partition 0, PROCESS_LOCAL, 9807 bytes) 10558-25/01/16 03:26:15 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.95.190:34327 (size: 12.5 KiB, free: 4.6 GiB) 10690:25/01/16 03:26:16 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2, known: 1, sharedSlotFromPendingPods: 2147483647. 10868-25/01/16 03:26:16 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2 for resource profile id: 0) 11030-25/01/16 03:26:16 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCsログは、ドライバが 03:26:06 と 03:26:16 にエグゼキュータを要求していることを示しています。
Spark History Server を使用してログを表示します。詳細については、「Spark History Server を使用して Spark ジョブに関する情報を表示する」をご参照ください。
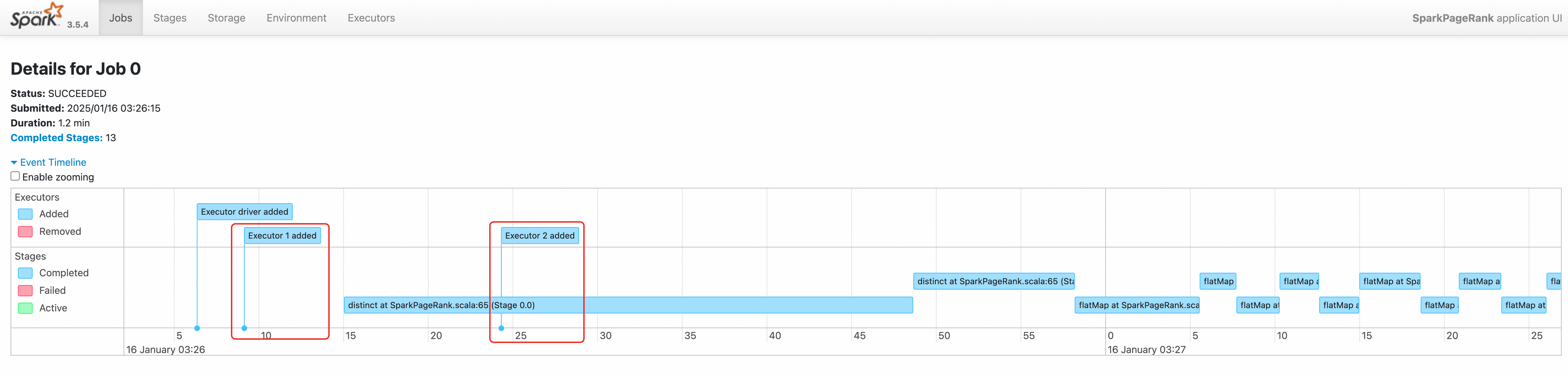
ジョブのイベントタイムラインは、2 つのエグゼキュータが順番に作成されていることを示しています。
Celeborn を RSS として使用する
この例では、Spark 3.5.4 を使用しています。Celeborn を RSS として使用し、動的リソース割り当てを有効にする場合は、次のパラメータを構成します。
動的リソース割り当てを有効にする:
spark.dynamicAllocation.enabledを"true"に設定します。Spark 3.5.0 以降では、
spark.shuffle.sort.io.plugin.classをorg.apache.spark.shuffle.celeborn.CelebornShuffleDataIOに設定します。アイドル状態のエグゼキュータが確実にできるだけ早く解放されるようにする:
spark.dynamicAllocation.shuffleTracking.enabledを"false"に設定します。
spark-pagerank-celeborn-dra.yamlという名前のファイルを作成し、次の内容をファイルにコピーします。このファイルは、SparkApplication を作成するために使用されます。apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: spark-pagerank-celeborn-dra namespace: spark spec: type: Scala mode: cluster # <SPARK_IMAGE> を Spark イメージに置き換えます。イメージには JindoSDK が含まれている必要があります。 image: <SPARK_IMAGE> mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar mainClass: org.apache.spark.examples.SparkPageRank arguments: # <OSS_BUCKET> を OSS バケットの名前に置き換えます。 - oss://<OSS_BUCKET>/data/pagerank_dataset.txt - "10" sparkVersion: 3.5.4 hadoopConf: # OSS データにアクセスするには、oss:// 形式を使用します。 fs.AbstractFileSystem.oss.impl: org.apache.hadoop.fs.aliyun.oss.OSS fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem # OSS にアクセスするためのエンドポイント。<OSS_ENDPOINT> を OSS アクセスエンドポイントに置き換える必要があります。 # たとえば、中国 (北京) リージョンで OSS にアクセスするための内部エンドポイントは oss-cn-beijing-internal.aliyuncs.com です。 fs.oss.endpoint: <OSS_ENDPOINT> # 環境変数から OSS アクセス認証情報を取得します。 fs.oss.credentials.provider: com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider sparkConf: # ==================== # イベントログ # ==================== spark.eventLog.enabled: "true" spark.eventLog.dir: file:///mnt/nas/spark/event-logs # ==================== # Celeborn # 参照: https://github.com/apache/celeborn/blob/main/README.md#spark-configuration # ==================== # シャッフルマネージャのクラス名は 0.3.0 で変更されました。 # 0.3.0 より前: `org.apache.spark.shuffle.celeborn.RssShuffleManager` # 0.3.0 以降: `org.apache.spark.shuffle.celeborn.SparkShuffleManager` spark.shuffle.manager: org.apache.spark.shuffle.celeborn.SparkShuffleManager # Java シリアライザは再配置をサポートしていないため、kryo シリアライザを使用する必要があります spark.serializer: org.apache.spark.serializer.KryoSerializer # Celeborn マスターノードのレプリカ数に基づいて、このパラメータを構成します。 spark.celeborn.master.endpoints: celeborn-master-0.celeborn-master-svc.celeborn.svc.cluster.local,celeborn-master-1.celeborn-master-svc.celeborn.svc.cluster.local,celeborn-master-2.celeborn-master-svc.celeborn.svc.cluster.local # オプション: hash, sort # ハッシュシャッフルライターは、(パーティション数) * (celeborn.push.buffer.max.size) * (spark.executor.cores) のメモリを使用します。 # シャッフルパーティション数が大きい場合、ソートハッシュライターはハッシュシャッフルライターよりも少ないメモリを使用するため、ソートハッシュライターを使用してみてください。 spark.celeborn.client.spark.shuffle.writer: hash # サーバー側のデータレプリケーションを有効にするには、`spark.celeborn.client.push.replicate.enabled` を true に設定することをお勧めします # ワーカーが 1 つしかない場合は、この設定を false にする必要があります # Celeborn が HDFS を使用している場合は、この設定を false に設定することをお勧めします spark.celeborn.client.push.replicate.enabled: "false" # Spark AQE のサポートは、Spark 3 でのみテストされています spark.sql.adaptive.localShuffleReader.enabled: "false" # パフォーマンスを向上させるために、aqe サポートを有効にすることをお勧めします spark.sql.adaptive.enabled: "true" spark.sql.adaptive.skewJoin.enabled: "true" # Spark のバージョンが 3.5.0 以降の場合、動的リソース割り当てをサポートするためにこのパラメータを構成します。 spark.shuffle.sort.io.plugin.class: org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO spark.executor.userClassPathFirst: "false" # ==================== # 動的リソース割り当て # 参照: https://spark.apache.org/docs/latest/job-scheduling.html#dynamic-resource-allocation # ==================== # 動的リソース割り当てを有効にする spark.dynamicAllocation.enabled: "true" # シャッフルファイルの追跡を有効にし、ESS に依存せずに動的リソース割り当てを実装します。 # Spark のバージョンが 3.4.0 以降の場合、Celeborn を RSS として使用するときにこの機能を無効にすることをお勧めします。 spark.dynamicAllocation.shuffleTracking.enabled: "false" # エグゼキュータ数の初期値。 spark.dynamicAllocation.initialExecutors: "1" # エグゼキュータの最小数。 spark.dynamicAllocation.minExecutors: "0" # エグゼキュータの最大数。 spark.dynamicAllocation.maxExecutors: "5" # エグゼキュータのアイドルタイムアウト期間。タイムアウト期間を超えると、エグゼキュータは解放されます。 spark.dynamicAllocation.executorIdleTimeout: 60s # データブロックをキャッシュしたエグゼキュータのアイドルタイムアウト期間。タイムアウト期間を超えると、エグゼキュータは解放されます。デフォルト値は infinity で、データブロックが解放されないことを指定します。 # spark.dynamicAllocation.cachedExecutorIdleTimeout: # ジョブが指定されたスケジュール時間を超えると、追加のエグゼキュータが要求されます。 spark.dynamicAllocation.schedulerBacklogTimeout: 1s # 各時間間隔の後、後続のバッチのエグゼキュータが要求されます。 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout: 1s driver: cores: 1 coreLimit: 1200m memory: 512m envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas serviceAccount: spark-operator-spark executor: cores: 1 coreLimit: "1" memory: 4g envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas volumes: - name: nas persistentVolumeClaim: claimName: nas-pvc restartPolicy: type: Never説明上記のサンプルジョブで使用される Spark イメージには、Hadoop OSS SDK の依存関係が含まれている必要があります。イメージをビルドするには、次の Dockerfile を使用し、イメージをイメージリポジトリにプッシュします。
ARG SPARK_IMAGE=spark:3.5.4 FROM ${SPARK_IMAGE} # Hadoop Aliyun OSS サポートの依存関係を追加します ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aliyun/3.3.4/hadoop-aliyun-3.3.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.17.4/aliyun-sdk-oss-3.17.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/jdom/jdom2/2.0.6.1/jdom2-2.0.6.1.jar ${SPARK_HOME}/jars # Celeborn の依存関係を追加します ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/celeborn/celeborn-client-spark-3-shaded_2.12/0.5.3/celeborn-client-spark-3-shaded_2.12-0.5.3.jar ${SPARK_HOME}/jars次のコマンドを実行して、SparkApplication を送信します。
kubectl apply -f spark-pagerank-celeborn-dra.yaml期待される出力:
sparkapplication.sparkoperator.k8s.io/spark-pagerank-celeborn-dra createdドライバログを表示します。
kubectl logs -n spark spark-pagerank-celeborn-dra-driver | grep -a2 -b2 "Going to request"期待される出力:
3544-25/01/16 03:51:28 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using current context from users K8S config file 3674-25/01/16 03:51:30 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances 3848:25/01/16 03:51:30 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 1, known: 0, sharedSlotFromPendingPods: 2147483647. 4026-25/01/16 03:51:30 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs 4106-25/01/16 03:51:30 INFO CelebornShuffleDataIO: Loading CelebornShuffleDataIO -- 11796-25/01/16 03:51:41 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (192.168.95.163, executor 1, partition 0, PROCESS_LOCAL, 9807 bytes) 11944-25/01/16 03:51:42 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.95.163:37665 (size: 13.3 KiB, free: 2.1 GiB) 12076:25/01/16 03:51:42 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2, known: 1, sharedSlotFromPendingPods: 2147483647. 12254-25/01/16 03:51:42 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2 for resource profile id: 0) 12416-25/01/16 03:51:42 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCsコマンド出力は、ドライバが
03:51:30に 1 つのエグゼキュータリソースを、03:51:42に別のエグゼキュータリソースを要求していることを示しています。Spark History Server を使用してログを表示します。詳細については、「Spark History Server を使用して Spark ジョブに関する情報を表示する」をご参照ください。
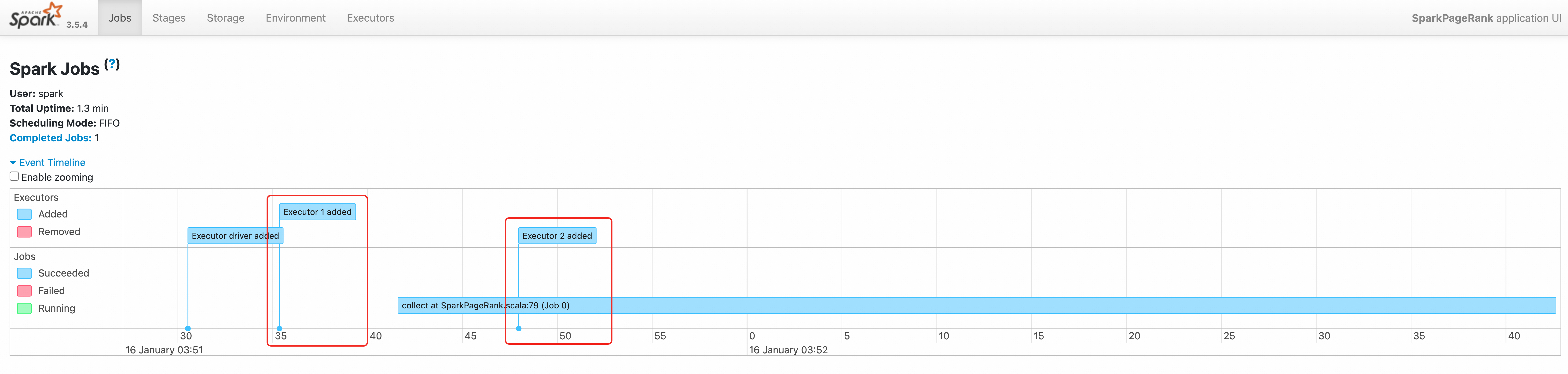
ジョブのイベントタイムラインは、2 つのエグゼキュータが順番に作成されていることを示しています。