マネージドノードプールは、Container Service for Kubernetes (ACK) におけるノードの運用保守(O&M)を自動化し、チームがアプリケーション開発に集中できるようにします。ACK が、お客様が定義したメンテナンスウィンドウ内で、オペレーティングシステム(OS)の共通脆弱性および暴露(CVE)パッチ適用、kubelet の更新、およびノードの再起動を代行します。
適用範囲
以下の条件に該当する場合、マネージドノードプールが適しています。
チームがノードの O&M よりもアプリケーション開発を優先する場合。 CVE パッチ適用、ランタイム更新、ノード修復などの作業を、手動で管理するのではなく、ACK に委任してください。
ワークロードがノードの変更を許容する場合。 Pod はノードの交換に対して非依存であり、データ損失なしで他のノードへ移行可能である必要があります。アプリケーションがノードローカルな状態に依存している場合は、マネージドノードプールの適用可否を検討してください。
仕組み
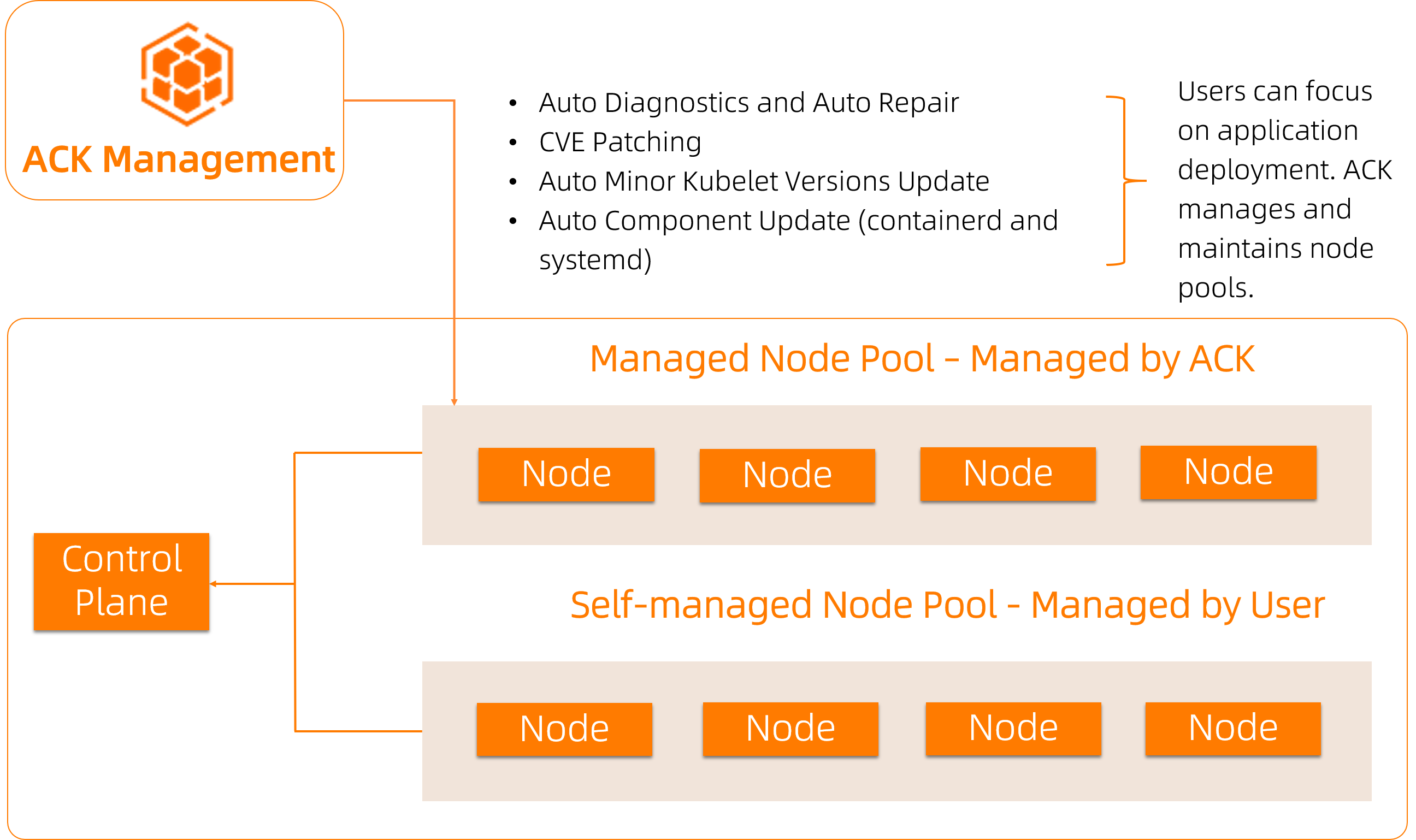
マネージドノードプールがノードの更新または修復が必要と判断すると、以下の処理を行います。
ノードをスケジュール不可としてマークします。
ノードから Pod をドレイン(排出)し、利用可能な他のノードへエビクション(強制移行)します。
必要な操作(システムディスクの置き換え、CVE パッチ適用、または再起動)を実行します。
ノードをサービスに戻します。
すべての自動化タスクは、設定したメンテナンスウィンドウ内で実行されます。メンテナンスウィンドウを設定するには、ACK コンソールの [ノードプール] ページに移動し、マネージドノードプールを選択し、[操作] 列の [マネージドノードプールの設定] をクリックします。
マネージドノードプールと通常のノードプールの比較
ACK は 2 種類のノードプールタイプを提供しています。両者を切り替えるには、[ノードプール] ページに移動し、ノードプールを見つけ、[アクション] 列で [マネージド型ノードプールを有効化] または [マネージド型ノードプールを無効化] をクリックします。
| 機能 | 通常のノードプール | マネージドノードプール |
|---|---|---|
| O&M | お客様による管理 | ACK による一部管理 |
| ノード修復 | 手動 | 自動 — 異常を検出し修復;ノード再起動動作は設定可能 |
| OS CVE パッチ適用 | 手動 | 自動 — 高・中・低の深刻度の脆弱性をカバー |
| minor kubelet バージョン更新 | 手動 | 自動 |
| containerd 更新 | 手動 | 自動 — containerd における OS CVE の重大な脆弱性はデフォルトでパッチ適用 |
| ECS システムイベントへの応答 | 手動 | 自動 — 下記の「ECS システムイベントへの応答」をご参照ください |
マネージドノードプールは O&M を簡素化しますが、すべての手動介入を不要にするものではありません。複雑なノード障害については、依然として手動でのトラブルシューティングが必要になる場合があります。詳細については、「マネージドノードプールの自動修復」をご参照ください。
注意事項
前提条件
マネージドノードプールを有効化する前に、以下の準備を行ってください。
Security Center (OS CVE のパッチ適用に必要): Security Center の Ultimate エディションを購入し、十分なサーバー保護クォータがあることを確認してください。ACK は OS CVE のパッチ適用に追加料金を請求しません。「Security Center の購入」および「機能と特徴」をご参照ください。
(推奨)イベントセンター: マネージドノードプールの活動に関するアラート通知を受信するために、イベントセンターを有効化することを推奨します。詳細については、「イベントモニタリング」をご参照ください。
(推奨)ack-node-problem-detector: ノードの異常検知を有効化するために、
ack-node-problem-detectorをインストールしてください。詳細については、「ack-node-problem-detector」をご参照ください。
ノード更新時の動作
マネージドノードプールでは、ノードの更新時にシステムディスクを置き換えます。
更新後に、以前のシステムディスク上のデータは削除されます。ノードにマウントされたデータディスクは影響を受けません。
データの永続化にはシステムディスクを使用しないでください。
ノードのドレイン
システムディスクを置き換える前に、ACK は kubectl cordon コマンドまたは ACK コンソール を使用してノードを停止し、すべての Pod をエビクションします。この処理により、Pod が再起動され、接続保持中のセッションが中断される可能性があります。
中断を最小限に抑えるには:
バックエンドサービスを複数のノードにまたがる複数のレプリカでデプロイします。
重要なアプリケーションについては、エビクション時の可用性を確保するため、Container Service コンソール および Pod Disruption Budgets(PDB) を設定します。
自動修復時の動作
マネージドノードプールは、ノードの状態を継続的にモニターします。ACK は、以下のいずれかの条件が満たされた場合にノードを再起動します。
ノードが 10 分以上、状態を報告していない場合。
ノードは
NotReady状態です。
ACK がノードを再起動すると、そのノード上の Pod も再起動されます。
ECS システムイベントへの応答
SystemMaintenance.Reboot イベントに対して、ACK は自動的に応答します。
ACK がイベントを受信し、内部通知を送信します。
ACK が対象ノードをドレイン(Pod を利用可能な他のノードへ移行)し、Elastic Compute Service(ECS)インスタンスを再起動します。
実行タイミング: ECS が指定したスケジュール時刻より前にメンテナンスウィンドウが設定されている場合、ACK はそのウィンドウ内で応答を実行します。それ以外の場合は、スケジュール時刻の 1 時間前に対応します。
ドレイン失敗時の挙動: ACK は、インスタンスを強制的に再起動しません。
ノードのドレイン中に可用性を確保するため、重要なアプリケーションには PDB の設定を推奨します。詳細については、「PDB のドキュメント」をご参照ください。
次のステップ
ノードプールの管理 — ノードプール内のノードの作成、表示、変更、スケーリング、削除、および管理方法について説明します。
ノードプールの O&M — ノードプールの更新、自動修復、および OS CVE パッチ適用について説明します。
ノードプールのベストプラクティス — デプロイメントセット、プリエンプティブルインスタンス、およびフリーノードの追加について説明します。