ACK Edgeクラスターを使用すると、複数のリージョンにあるコンピューティングリソースを一元管理できます。 これにより、クラウドネイティブアプリケーションの完全なライフサイクル管理と効率的なリソーススケジューリングを実装できます。 このトピックでは、ACK Edgeクラスターを使用して、複数のリージョンのECSリソースを一元管理する方法について説明します。
シナリオ
次のシナリオでは、ACK Edgeクラスターを使用して、複数のリージョンのECSリソースを一元管理できます。
複数の仮想プライベートクラウド (VPC) に分散しているECSインスタンスがあります。
複数のリージョンに分散しているECSインスタンスがあります。
複数のRAM (Resource Access Management) ユーザーによって作成されたECSインスタンスがあります。
複数のリージョンにまたがるアプリケーションの管理
次のシナリオで、複数のリージョンに分散した多数のECSインスタンスで同じビジネスを一元管理またはデプロイする場合は、ACK Edgeクラスターを作成し、ECSインスタンスをクラスターに追加できます。 詳細については、「例1: ACK Edgeクラスターを使用して複数のリージョンにまたがるアプリケーションを管理する」をご参照ください。
セキュリティ保護
分散コンピューティング環境を使用する場合、悪意のある攻撃やデータ漏洩からビジネスを保護する必要があります。 一般的な保護ソリューションは、分散リソースにネットワークセキュリティエージェントを展開することです。 この場合、ACK Edgeクラスターを使用して、エージェントを一元的にデプロイおよび管理できます。
分散ストレステストと合成モニタリング
大規模なビジネスでストレステストを実行する場合、ストレステストツールを使用して、複数のリージョンで同時にストレステストタスクを開始する必要があります。 この場合、リージョンにまたがるコンピューティングリソースにストレステストツールをインストールする必要があります。 リソースをACK Edgeクラスターに追加して、ストレステストツールをリソースに集中的にすばやくデプロイできます。
キャッシュアクセラレーション
分散キャッシュアクセラレーションシステムを使用する場合、各リージョンにキャッシュサービスをデプロイして、ネットワーク経由でのコンテンツ配信を高速化する必要があります。 この場合、ACK Edgeクラスターを使用して、分散キャッシュアクセラレーションシステムを複数のリージョンに集中的にデプロイおよび保守できます。

リージョン内のGPUリソース不足の問題を解決する
GPUリソースが不足しているリージョンにタスクをデプロイする場合、別のリージョンでGPU高速化ECSインスタンスを購入し、そのインスタンスをACK Edgeクラスターに追加できます。 これにより、クラスターはGPU高速化インスタンスにタスクをスケジュールできます。 詳細については、「例2: 別のリージョンで新しいGPU高速化ECSインスタンスを購入して、リージョンでGPUリソースが不足している場合にGPUリソースをスケールアウトする」をご参照ください。

メリット
費用対効果: このソリューションは、クラウドネイティブテクノロジーとの標準統合を提供し、分散アプリケーションのO&Mを最適化し、O&Mコストを削減します。
ゼロO&M: ACK EdgeクラスターのコントロールプレーンはAlibaba Cloudによって管理され、手動O&Mは必要ありません。さらに、Alibaba Cloudは、コントロールプレーンのサービスレベル契約 (SLA) 保証を提供しています。
高可用性: このソリューションは他のAlibaba Cloudサービスと統合され、柔軟性、ネットワーク、ストレージ、可観測性などのさまざまな機能を提供します。 これにより、アプリケーションの安定性が確保されます。 さらに、このソリューションは、エッジの自律性、クラウドエッジのO&Mチャネル、およびセルベースの管理を提供し、集中型のクラウドエッジ管理におけるO&M、安定性、およびビジネスコミュニケーションの要件を満たします。
高い互換性: このソリューションは、異なるオペレーティングシステムを使用する数十種類の異種計算リソースを統合できます。
高性能: このソリューションは、クラウドエッジ通信を最適化し、通信コストを削減します。 各ACKエッジクラスタは、数千のノードを含むことができる。
例
例1: ACK Edgeクラスターを使用して複数のリージョンにまたがるアプリケーションを管理する
環境準備
中央リージョンとしてリージョンを選択し、そのリージョンにACK Edgeクラスターを作成します。 詳細については、「ACK Edgeクラスターの作成」をご参照ください。
OpenKruiseをインストールします。 詳細については、「コンポーネント管理」をご参照ください。
ECSインスタンスが存在する各リージョンにエッジノードプールを作成し、ECSインスタンスをエッジノードプールに追加します。 詳細については、「エッジノードプールの作成」をご参照ください。
手順
Kubernetes DaemonSetまたはOpenKruise DaemonSetを使用して、ビジネスをデプロイおよび管理できます。
Kubernetes DaemonSetの使用
例
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
[DaemonSets] ページで、名前空間とデプロイ方法を選択し、アプリケーション名を入力し、[タイプ] を [DaemonSet] に設定し、画面の指示に従って作成を完了します。
DaemonSetの作成方法の詳細については、「DaemonSetの作成」をご参照ください。
ビジネスのアップグレード
[DaemonSets] ページで、作成したDaemonSetを見つけ、[操作] 列の [編集] をクリックします。 [編集] ページで、DaemonSetテンプレートを変更して、ビジネスのバージョンアップグレードまたは構成の更新を実行できます。
OpenKruise DaemonSetを使用する
例
ACKコンソールにログインします。 左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
[ポッド] ページで、[YAMLから作成] をクリックし、[サンプルテンプレート] ドロップダウンリストから [カスタム] を選択し、DaemonSetのYAMLテンプレートをコードエディターにコピーし、[作成] をクリックします。
ビジネスのアップグレード
On theクラスターページで、管理するクラスターの名前をクリックし、左側のナビゲーションウィンドウに表示されます。
[カスタムリソース] ページで、[リソースオブジェクト] をクリックし、作成したDaemonSetを見つけて、[操作] 列の [YAMLの編集] をクリックします。 DaemonSetテンプレートを変更して、ビジネスのバージョンアップグレードまたは構成更新を実行できます。
例2: 別のリージョンで新しいGPU高速化ECSインスタンスを購入し、GPUリソースが不足している場合にGPUリソースをスケールアウトする
環境準備
手順
この例では、推論サービスは、複数のリージョンに分散したECSインスタンスを含むACK Edgeクラスターにデプロイされています。 あるリージョンのGPUリソースが不足した場合、別のリージョンのGPUアクセラレーションインスタンスをクラスターに追加できます。 次に、新しく追加されたインスタンスに推論サービスをスケジュールできます。
推論サービスをデプロイし、サービスのステータスを表示します。
tensorflow-mnist.yamlという名前のファイルを作成します。
推論サービスをデプロイします。
kubectl apply -f tensorflow-mnist.yaml推論サービスの状態を確認してください。
kubectl get pods想定される出力:
NAME READY STATUS RESTARTS AGE tensorflow-mnist-664cf976d8-whrbc 0/1 pending 0 30s出力は、推論サービスが
保留中の状態であることを示しています。これは、GPUリソースが不足していることを示しています。
エッジノードプールを作成します。 詳細については、「エッジノードプールの作成」をご参照ください。
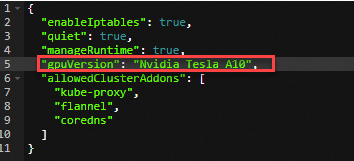
GPU高速化インスタンスをエッジノードとしてエッジノードプールに追加します。 詳細については、「GPUアクセラレーションノードの追加」をご参照ください。
エッジノードのステータスを表示します。
kubectl get nodes想定される出力:
NAME STATUS ROLES AGE VERSION cn-hangzhou.192.168.XX.XX Ready <none> 9d v1.30.7-aliyun.1 iz2ze21g5pq9jbesubr**** Ready <none> 8d v1.30.7-aliyun.1 izf8z0dko1ivt5kwgl4**** Ready <none> 8d v1.30.7-aliyun.1 izuf65ze9db2kfcethw**** Ready <none> 8d v1.30.7-aliyun.1 # Information about the newly added GPU-accelerated edge nodes.推論サービスの状態を確認してください。
kubectl get pods -owide想定される出力:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tensorflow-mnist-664cf976d8-whrbc 1/1 running 0 23m 10.12.XX.XX izuf65ze9db2kfcethw**** <none> <none>出力は、推論サービスが新しく追加されたGPUアクセラレーションノードの1つにスケジュールされ、正常にデプロイされたことを示しています。