大規模言語モデル(LLM)を使用してハイブリッドクラウド環境に弾性推論サービスをデプロイする場合、トラフィック分散が不均衡になり、データセンターで GPU 割り当ての問題が発生する可能性があります。これらの問題を解決するために、ACK Edge クラスタは、ハイブリッドクラウド環境に LLM を弾性推論サービスとしてデプロイするためのソリューションを提供します。このソリューションは、クラウドとデータセンターの GPU リソースを一元管理するのに役立ちます。このソリューションを使用すると、オフピーク時にはデータセンターのリソースを優先的に使用し、ピーク時にはクラウドのリソースを起動するようにビジネスを設定できます。このソリューションは、LLM を使用してデプロイされた推論サービスの運用コストを大幅に削減し、リソース供給を動的かつ柔軟に調整します。これにより、サービスの安定性が確保され、リソースのアイドル状態が防止されます。
ソリューションの概要
アーキテクチャ
このソリューションは、ACK Edge クラスタのクラウドエッジ連携機能に基づいて開発されています。このソリューションを使用すると、クラウドとデータセンターの計算リソースを一元管理し、計算タスクにリソースを動的に割り当てることができます。クラスタに LLM を推論サービスとしてデプロイした後、KServe を使用して、推論サービスのスケーリングポリシーを設定できます。
オフピーク時には、クラスタに ResourcePolicy を作成して、推論サービスの優先順位ベースのリソーススケジューリングを有効にできます。データセンターの計算リソースに、クラウドの計算リソースよりも高い優先順位を割り当てることができます。このようにして、推論サービスはオンプレミスの計算リソースを優先的に使用します。
ピーク時には、KServe は ACK Edge クラスタの監視機能を活用して、GPU 使用率とワークロードの状態をリアルタイムで監視できます。スケーリング条件が満たされると、KServe は推論サービスがデプロイされているポッドを動的にスケールアウトします。オンプレミスの GPU リソースが不足すると、システムはクラウドであらかじめ設定された弾性ノードプールによって提供される GPU リソースを推論サービスに割り当てます。これにより、サービスの安定性と継続性が確保されます。
推論リクエスト:多数の推論リクエスト
リソーススケジューリング:システムは、推論サービスをデータセンターのリソースプールに優先的にスケジュールします。
スケールアウトにクラウド上のリソースを使用する:データセンターのリソースが不足すると、システムはクラウドであらかじめ設定された弾性ノードプールによって提供されるリソースを推論サービスに割り当てます。
主要コンポーネント
このソリューションには、ACK Edge クラスタ、KServe、弾性ノードプール(ノードの自動スケーリング)、および ResourcePolicy(優先順位ベースのリソーススケジューリング)という主要コンポーネントが含まれています。
例
環境を準備します。
上記の操作が完了したら、クラスタ内のリソースを3つのタイプに分類し、リソースを次のノードプールに追加します。
タイプ
ノードプールのタイプ
説明
例
クラウド上の制御リソースプール
クラウド上
ACK Edge クラスタと KServe などの制御コンポーネントをデプロイするために使用されるクラウド上のノードプール。
default-nodepool
オンプレミスリソースプール
エッジ/専用
LLM を使用してデプロイされた推論サービスをホストするために使用されるデータセンターの計算リソース。
GPU-V100-Edge
クラウド上の弾性リソースプール
クラウド上
スケーラブルなリソースプールは、クラスタの GPU リソース要件を満たすために動的にスケーリングし、ピーク時に LLM を使用してデプロイされた推論サービスをホストできます。
GPU-V100-Elastic
AI モデルを準備します。
Object Storage Service(OSS)または NAS ファイルシステム(NAS)を使用して、モデルデータを準備できます。詳細については、「モデルデータを準備し、モデルデータを OSS バケットにアップロードする」をご参照ください。
リソースの優先順位を指定します。
ResourcePolicy を作成して、リソースの優先順位を指定します。この例では、ResourcePolicy の labelSelector パラメータは
app: isvc.qwen-predictorに設定されており、ResourcePolicy が適用されるアプリケーションを選択します。次の ResourcePolicy は、一致するポッドが最初にオンプレミスリソースプールにスケジュールされることを指定しています。オンプレミスリソースプールによって提供されるリソースが不足すると、システムは一致するポッドをクラウド上の弾性リソースプールにスケジュールします。ResourcePolicy の設定方法の詳細については、「優先順位ベースのリソーススケジューリングを設定する」をご参照ください。重要後でアプリケーションポッドを作成するときは、次の
labelSelectorと一致するラベルを追加して、ここで定義されているスケジューリングポリシーに関連付ける必要があります。apiVersion: scheduling.alibabacloud.com/v1alpha1 kind: ResourcePolicy metadata: name: qwen-chat namespace: default spec: selector: app: isvc.qwen-predictor # ResourcePolicy を適用するポッドのラベルを指定する必要があります。 strategy: prefer units: - resource: ecs nodeSelector: alibabacloud.com/nodepool-id: npxxxxxx # 値をオンプレミスリソースプールの ID に置き換えます。 - resource: elastic nodeSelector: alibabacloud.com/nodepool-id: npxxxxxy # 値をクラウド上のリソースプールの ID に置き換えます。LLM を推論サービスとしてデプロイします。
Arena クライアントで次のコマンドを実行して、KServe を使用して LLM に基づく推論サービスをデプロイします。
arena serve kserve \ --name=qwen-chat \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1 \ --scale-metric=DCGM_CUSTOM_PROCESS_SM_UTIL \ --scale-target=50 \ --min-replicas=1 \ --max-replicas=3 \ --gpus=1 \ --cpu=4 \ --memory=12Gi \ --data="llm-model:/mnt/models/Qwen" \ "python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code --served-model-name qwen --model /mnt/models/Qwen --gpu-memory-utilization 0.95 --quantization gptq --max-model-len=6144"パラメータ
必須
説明
例
--nameはい
推論サービスの名前。グローバルに一意である必要があります。
qwen-chat
--imageはい
推論サービスイメージのアドレス。この例では、仮想大規模言語モデル(vLLM)推論フレームワークが使用されています。
kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1
--scale-metricいいえ
スケーリングメトリック。この例では、GPU 使用率メトリック
DCGM_CUSTOM_PROCESS_SM_UTILがスケーリングメトリックとして使用されています。詳細については、「HPA を設定する」をご参照ください。DCGM_CUSTOM_PROCESS_SM_UTIL
--scale-targetいいえ
スケーリングしきい値。この例では、スケーリングしきい値は 50% です。GPU 使用率が 50% を超えると、システムはポッドレプリカをスケーリングします。
50
--min-replicasいいえ
ポッドレプリカの最小数。
1
--max-replicasいいえ
ポッドレプリカの最大数。
3
--gpusいいえ
推論サービスによってリクエストされる GPU の数。デフォルト値:0。
1
--cpuいいえ
推論サービスによってリクエストされる vCore の数。
4
--memoryいいえ
推論サービスによってリクエストされるメモリのサイズ。
12Gi
--dataいいえ
推論サービスモデルのアドレス。この例では、モデルのボリュームは llm-model で、コンテナの /mnt/models/ ディレクトリにマウントされています。
"llm-model:/mnt/models/Qwen" \
"python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code --served-model-name qwen --model /mnt/models/Qwen --gpu-memory-utilization 0.95 --quantization gptq --max-model-len=6144"
弾性推論サービスがデプロイされているかどうかを確認します。
curl -H "Host: qwen-chat-default.example.com" \ # KServe によって自動的に作成された Ingress の詳細からアドレスを取得します。 -H "Content-Type: application/json" \ http://xx.xx.xx.xx:80/v1/chat/completions \ -X POST \ -d '{"model": "qwen", "messages": [{"role": "user", "content": "Hello"}], "max_tokens": 512, "temperature": 0.7, "top_p": 0.9, "seed": 10, "stop":["<|endoftext|>", "<|im_end|>", "<|im_start|>"]}ストレステストツール hey を使用して、大量のリクエストを推論サービスに送信し、ピーク時のトラフィックスパイクをシミュレートして、クラウド上のリソースが起動されるかどうかをテストします。
hey -z 2m -c 5 \ -m POST -host qwen-chat-default.example.com \ -H "Content-Type: application/json" \ -d '{"model": "qwen", "messages": [{"role": "user", "content": "Test"}], "max_tokens": 10, "temperature": 0.7, "top_p": 0.9, "seed": 10}' \ http://xx.xx.xx.xx:80/v1/chat/completionsリクエストがポッドに送信されると、推論サービスの GPU 使用率がスケーリングしきい値(50%)を超えます。この場合、HPA は事前に定義されたスケーリングルールに基づいてポッドをスケールアウトします。次の図は、推論サービス用に作成されたポッドの数が3つに増加したことを示しています。

ただし、テスト環境のデータセンターは 1 つの GPU しか提供していません。その結果、新しく作成された 2 つのポッドはスケジュールできず、
pending状態のままになります。この場合、cluster-autoscaler は 2 つのクラウド上の GPU アクセラレーテッドノードを自動的に起動して、2 つのpendingポッドをホストします。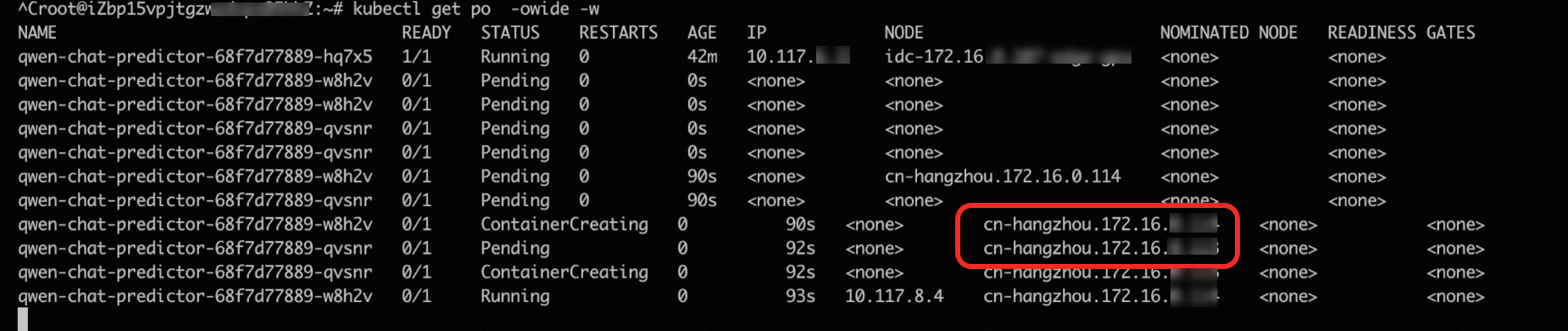
関連情報
推論サービスのデプロイ方法の詳細については、「Kubernetes に AI 推論サービスをデプロイする」をご参照ください。
ACK Edge クラスタのクラウド上の弾力性機能の詳細については、「クラウドの弾力性」をご参照ください。
エッジノードから OSS バケットへのアクセスを高速化する方法の詳細については、「Fluid を使用してエッジノードから OSS バケットへのアクセスを高速化する」をご参照ください。