Topik ini menjelaskan cara mengimplementasikan pencarian teks-ke-gambar secara real-time menggunakan DashVector dan ChineseCLIP, sebuah model pencarian multi-modal yang tersedia di ModelScope. Dalam contoh ini, dataset Multimodal Understanding and Generation Evaluation (MUGE) digunakan sebagai korpus gambar, memungkinkan pengguna mencari gambar yang paling mirip berdasarkan teks.
Proses keseluruhan
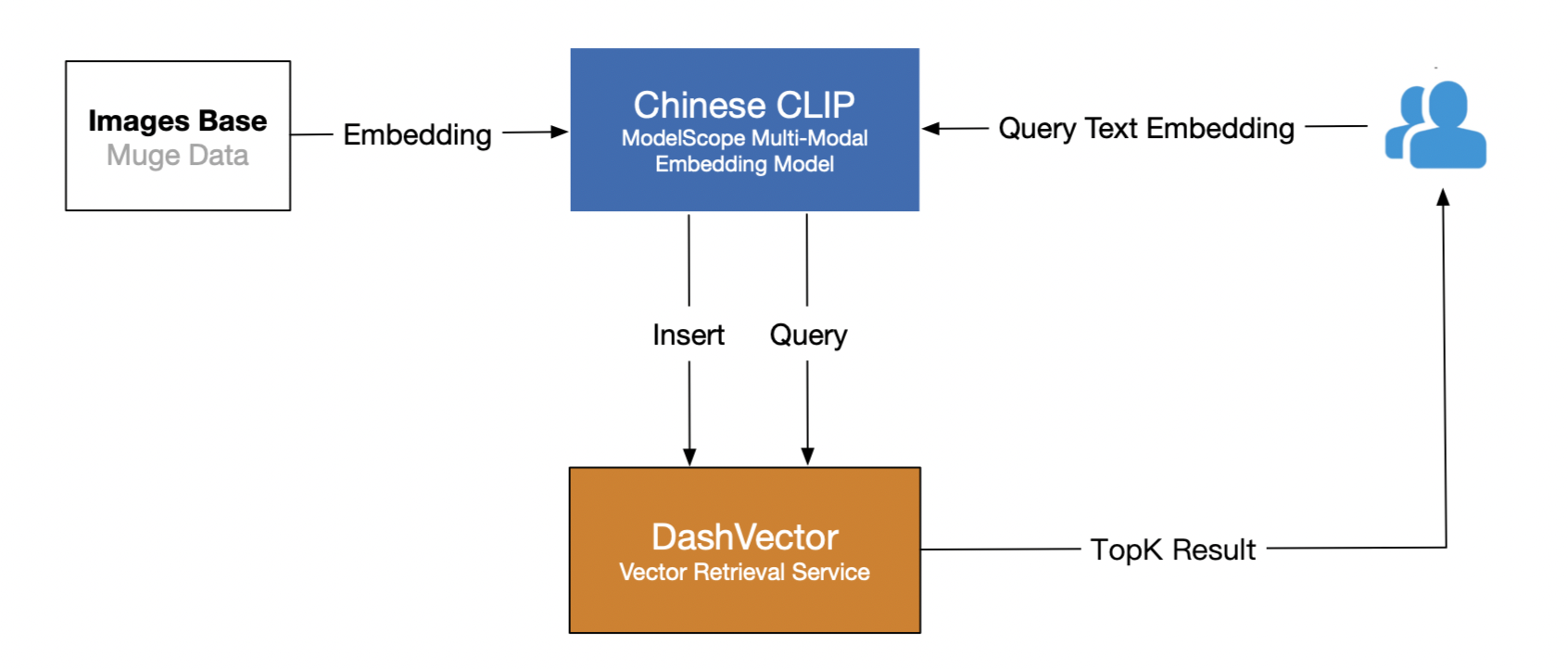
Proses ini terdiri dari dua langkah utama:
Hasilkan Penyematan Gambar dan Simpan di DashVector: Ubah dataset MUGE menjadi vektor dimensi tinggi menggunakan API penyematan dari model ChineseCLIP, lalu tulis vektor tersebut ke dalam DashVector.
Cari Gambar Berdasarkan Teks: Dapatkan penyematan teks kueri menggunakan model ChineseCLIP dan cari gambar serupa di DashVector.
Persiapan
1. Kunci API
Aktifkan DashVector. Untuk informasi lebih lanjut, lihat Aktifkan DashVector.
Buat Kunci API untuk DashVector. Untuk informasi lebih lanjut, lihat Kelola Kunci API.
2. Lingkungan
Dalam contoh ini, model ChineseCLIP terbaru Enormous (224 piksel) dari ModelScope digunakan. Model ini dilatih pada data skala besar berbahasa Tiongkok yang mencakup sekitar 0,2 miliar pasangan gambar-teks, unggul dalam pencarian gambar berdasarkan teks Tiongkok serta ekstraksi penyematan gambar dan kata. Dependensi lingkungan berikut diperlukan, seperti dijelaskan pada halaman detail model di ModelScope:
Python 3.7 atau lebih baru diperlukan.
# Instal dashvector.
pip3 install dashvector
# Instal modelscope.
# Anda harus menginstal modelscope 0.3.7 atau lebih baru. Secara default, versi modelscope yang Anda instal lebih baru dari 0.3.7. Setelah instalasi, periksa versi yang telah diinstal.
# Anda dapat menginstal modelscope dengan memperbarui image atau menjalankan perintah berikut:
pip3 install --upgrade modelscope -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# Instal decord secara terpisah.
# pip3 install decord
# Instal dependensi yang diperlukan untuk menginstal modelscope.
# pip3 install torch torchvision opencv-python timm librosa fairseq transformers unicodedata2 zhconv rapidfuzz3. Data
Dalam contoh ini, dataset validasi MUGE digunakan sebagai dataset gambar untuk pembuatan penyematan, yang dapat diperoleh melalui API dataset dari ModelScope.
from modelscope.msdatasets import MsDataset
dataset = MsDataset.load("muge", split="validation")Prosedur
Anda harus mengganti your-xxx-api-key dengan Kunci API Anda dan your-xxx-cluster-endpoint dengan Titik Akhir kluster Anda dalam kode contoh agar kode dapat berjalan dengan benar.
1. Hasilkan penyematan gambar dan simpan di DashVector
Dataset validasi MUGE berisi informasi multi-modal dari 30.588 gambar. Dalam contoh ini, penyematan gambar asli diekstraksi menggunakan model ChineseCLIP dan disimpan di DashVector. Gambar asli juga dikodekan dan disimpan di DashVector untuk memudahkan tampilan gambar. Contoh kode:
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException, DashVectorCode
from PIL import Image
import base64
import io
def image2str(image):
image_byte_arr = io.BytesIO()
image.save(image_byte_arr, format='PNG')
image_bytes = image_byte_arr.getvalue()
return base64.b64encode(image_bytes).decode()
if __name__ == '__main__':
# Inisialisasi klien DashVector.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Buat koleksi dengan menentukan nama koleksi dan jumlah dimensi vektor. Pada model Enormous dari ChineseCLIP, jumlah dimensi vektor adalah 1.024.
rsp = client.create('muge_embedding', 1024)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# Hasilkan dan simpan penyematan gambar secara batch.
collection = client.get('muge_embedding')
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-enormous-patch14_zh',
model_revision='v1.0.0')
ds = MsDataset.load("muge", split="validation")
BATCH_COUNT = 10
TOTAL_DATA_NUM = len(ds)
print(f"Mulai mengindeks data validasi muge, total ukuran data: {TOTAL_DATA_NUM}, ukuran batch:{BATCH_COUNT}")
idx = 0
while idx < TOTAL_DATA_NUM:
batch_range = range(idx, idx + BATCH_COUNT) if idx + BATCH_COUNT <= TOTAL_DATA_NUM else range(idx, TOTAL_DATA_NUM)
images = [ds[i]['image'] for i in batch_range]
# Hasilkan penyematan gambar dengan menggunakan model ChineseCLIP.
image_embeddings = pipe.forward({'img': images})['img_embedding']
image_vectors = image_embeddings.detach().cpu().numpy()
collection.insert(
[
Doc(
id=str(img_id),
vector=img_vec,
fields={'png_img': image2str(img)}
)
for img_id, img_vec, img in zip(batch_range, image_vectors, images)
]
)
idx += BATCH_COUNT
print("Selesai mengindeks data validasi muge")
Dalam kode sebelumnya, model berjalan di CPU secara default. Jika model berjalan di GPU, performanya dapat ditingkatkan hingga berbagai tingkat berdasarkan performa GPU.
2. Cari gambar berdasarkan teks
Dapatkan vektor teks menggunakan model ChineseCLIP. Kemudian, cari gambar serupa menggunakan API pencarian DashVector. Contoh kode:
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException
from PIL import Image
import base64
import io
def str2image(image_str):
image_bytes = base64.b64decode(image_str)
return Image.open(io.BytesIO(image_bytes))
def multi_modal_search(input_text):
# Inisialisasi klien DashVector.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Dapatkan koleksi yang menyimpan penyematan terkait.
collection = client.get('muge_embedding')
# Dapatkan penyematan teks kueri.
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-enormous-patch14_zh', model_revision='v1.0.0')
text_embedding = pipe.forward({'text': input_text})['text_embedding'] # Tensor 2D, [Jumlah kata dalam teks, Dimensi fitur]
text_vector = text_embedding.detach().cpu().numpy()[0]
# Cari di DashVector.
rsp = collection.query(text_vector, topk=3)
image_list = list()
for doc in rsp:
image_str = doc.fields['png_img']
image_list.append(str2image(image_str))
return image_list
if __name__ == '__main__':
text_query = "戴眼镜的狗"
images = multi_modal_search(text_query)
for img in images:
# Catatan: Anda mungkin perlu menginstal penampil gambar di Server Linux agar fungsi show() bekerja.
# Kami merekomendasikan untuk menjalankan kode pada server yang mendukung Jupyter Notebook.
img.show()
Gambar berikut dikembalikan setelah kode sebelumnya dijalankan.


