Pencarian vektor Tablestore (KnnVectorQuery) menggunakan vektor numerik untuk menjalankan kueri tetangga terdekat aproksimasi. Fitur ini menemukan item data yang paling mirip dalam set data berskala besar dan cocok untuk skenario seperti Generasi yang Diperkaya dengan Pengambilan Data (RAG), sistem rekomendasi, deteksi kemiripan, Pemrosesan bahasa alami, serta pencarian semantik.
Skenario
Pencarian vektor cocok untuk skenario seperti sistem rekomendasi, pengambilan gambar dan video, serta Pemrosesan bahasa alami dan pencarian semantik.
Generasi yang Diperkaya dengan Pengambilan Data (RAG)
RAG adalah kerangka kerja AI yang menggabungkan kemampuan pengambilan dengan model bahasa besar (Large Language Models/LLMs). RAG menggunakan pengambilan untuk meningkatkan akurasi keluaran LLM, terutama untuk data privat atau profesional. RAG banyak digunakan dalam skenario basis pengetahuan.
Sistem rekomendasi
Pada platform seperti e-commerce, media sosial, dan media streaming, Anda dapat mengenkripsi perilaku pengguna, preferensi, dan fitur konten ke dalam bentuk vektor. Pencarian vektor kemudian dapat dengan cepat menemukan produk, artikel, atau video yang sesuai dengan minat pengguna. Proses ini memungkinkan rekomendasi personalisasi dan meningkatkan kepuasan serta retensi pengguna.
Deteksi kemiripan (gambar, video, dan voice)
Di bidang seperti pengenalan gambar, video, voice, voiceprint, dan wajah, Anda dapat mengonversi data tidak terstruktur menjadi representasi vektor. Pencarian vektor kemudian dapat digunakan untuk dengan cepat menemukan target yang paling mirip. Misalnya, pada platform e-commerce, setelah pengguna mengunggah gambar, sistem dapat dengan cepat menemukan gambar produk dengan gaya, warna, atau pola yang serupa.
Pemrosesan bahasa alami dan pencarian semantik
Di bidang Pemrosesan bahasa alami (NLP), Anda dapat mengonversi teks menjadi representasi vektor, seperti penyematan Word2Vec atau Bidirectional Encoder Representations from Transformers (BERT). Pencarian vektor kemudian dapat digunakan untuk memahami semantik kueri dan menemukan dokumen, berita, atau pasangan tanya-jawab yang paling relevan secara semantik. Hal ini meningkatkan relevansi hasil pencarian dan pengalaman pengguna.
Graf pengetahuan dan Chat AI
Node dan hubungan graf pengetahuan dapat direpresentasikan sebagai vektor. Pencarian vektor dapat mempercepat penghubungan entitas, inferensi hubungan, dan kecepatan respons sistem Chat AI. Hal ini memungkinkan sistem memahami dan menjawab pertanyaan kompleks dengan lebih akurat.
Keunggulan utama
Biaya rendah
Mesin inti menggunakan teknologi DiskAnn yang telah dioptimalkan. Dibandingkan dengan algoritma Hierarchical Navigable Small World (HNSW), teknologi ini tidak perlu memuat seluruh data indeks ke dalam memori. Penggunaan memori kurang dari 10% untuk mencapai tingkat recall dan performa yang sebanding dengan algoritma graf HNSW. Hal ini secara signifikan mengurangi biaya keseluruhan dibandingkan sistem serupa.
Mudah digunakan
Pencarian vektor merupakan sub-fitur arsitektur tanpa server dari indeks pencarian. Anda tidak perlu membangun atau menerapkan sistem. Untuk memulai, cukup buat instans di Konsol Tablestore.
Fitur ini mendukung metode penagihan bayar sesuai pemakaian. Anda tidak perlu mengelola level penggunaan atau memperluas kapasitas. Sistem mendukung skalabilitas horizontal untuk sumber daya penyimpanan maupun komputasi. Pencarian vektor mendukung hingga ratusan miliar entri data, sedangkan pencarian non-vektor mendukung hingga sepuluh triliun entri data.
Saat melakukan pencarian vektor, mesin internal menggunakan Pengoptimal kueri untuk secara otomatis memilih algoritma dan jalur eksekusi terbaik. Anda dapat mencapai tingkat recall dan performa tinggi tanpa perlu menyetel banyak parameter. Hal ini secara signifikan menurunkan hambatan masuk dan memperpendek siklus pengembangan bisnis.
Anda dapat menggunakan pencarian vektor melalui SQL, SDK untuk berbagai bahasa seperti Java, Go, Python, dan Node.js, serta framework open source seperti LangChain, LangChain4J, dan LlamaIndex.
Ikhtisar fungsi
KnnVectorQuery menemukan item data yang paling mirip dalam set data berskala besar dengan menjalankan kueri tetangga terdekat aproksimasi pada vektor numerik.
Pencarian vektor mewarisi semua fitur indeks pencarian. Ini adalah layanan siap pakai dengan model bayar sesuai pemakaian yang tidak memerlukan penerapan sistem. Fitur ini mendukung pembuatan indeks berbasis aliran, sehingga data dapat dikueri hampir secara real-time setelah ditulis ke tabel. Fitur ini juga mendukung penambahan, pembaruan, dan penghapusan data dengan throughput tinggi. Performa kueri setara dengan sistem yang menggunakan algoritma HNSW.
Saat menggunakan fitur KnnVectorQuery untuk mengkueri data, Anda harus menentukan vektor kueri, bidang vektor yang akan dicari, dan jumlah tetangga terdekat (TopK) yang ingin diambil. Proses ini mengambil TopK vektor dari bidang vektor yang ditentukan yang paling mirip dengan vektor kueri Anda. Anda juga dapat menggabungkan kueri ini dengan fitur pencarian non-vektor lainnya untuk menyaring hasil.
Deskripsi bidang vektor
Sebelum menggunakan fitur KnnVectorQuery, Anda harus mengonfigurasi bidang vektor saat membuat indeks pencarian. Anda harus menentukan dimensi vektor, tipe data vektor, dan algoritma pengukuran jarak.
Tipe data bidang yang sesuai di tabel data harus berupa String. Tipe data di indeks pencarian harus berupa string array Float32. Untuk informasi lebih lanjut tentang konfigurasi bidang vektor, lihat tabel berikut.
Item konfigurasi | Deskripsi |
dimension | Dimensi vektor. Dimensi maksimum yang didukung adalah 4096. Nilai dimensi harus sesuai dengan dimensi vektor yang dihasilkan oleh sistem embedding hulu. Panjang array bidang vektor harus sama dengan parameter dimensi yang dikonfigurasi. Misalnya, jika nilai bidang vektor adalah string Catatan Hanya vektor padat yang didukung. Dimensi data bidang vektor dalam indeks pencarian harus konsisten dengan dimensi yang ditetapkan dalam skema saat indeks dibuat. Jika dimensinya lebih besar atau lebih kecil, pembuatan indeks untuk baris tersebut akan gagal. |
dataType | Tipe data vektor. Hanya Float32 yang didukung. Float32 tidak mendukung nilai ekstrem seperti NaN dan Infinite. Tipe data harus konsisten dengan tipe data vektor yang dihasilkan oleh sistem embedding hulu. Catatan Untuk menggunakan vektor dengan tipe data lain, submit a ticket untuk menghubungi kami. |
metricType | Algoritma untuk mengukur jarak antar vektor. Nilai yang valid meliputi euclidean, cosine, dan dot_product. Algoritma pengukuran jarak harus konsisten dengan algoritma yang direkomendasikan oleh sistem embedding hulu. Untuk informasi lebih lanjut, lihat Algoritma pengukuran jarak. |
Model atau versi sistem embedding yang berbeda menghasilkan vektor dengan properti berbeda, termasuk dimensi, tipe data, dan algoritma pengukuran jarak. Properti bidang vektor dalam sistem pencarian vektor (dimensi, tipe data, dan algoritma pengukuran jarak) harus sesuai dengan properti vektor yang dihasilkan oleh sistem embedding. Untuk informasi lebih lanjut tentang cara menghasilkan vektor, lihat Dua cara menghasilkan vektor.
Algoritma pengukuran jarak
Pencarian vektor mendukung algoritma pengukuran jarak berikut: euclidean, cosine, dan dot_product. Untuk informasi lebih lanjut, lihat tabel berikut. Skor yang lebih tinggi menunjukkan kemiripan yang lebih besar antara dua vektor.
MetricType | Rumus penilaian | Performa | Deskripsi |
Jarak Euclidean (euclidean) |
| Tinggi | Jarak Euclidean adalah jarak garis lurus antara dua vektor dalam ruang multidimensi. Untuk alasan performa, algoritma jarak Euclidean di Tablestore menghilangkan perhitungan akar kuadrat akhir. Skor yang lebih tinggi menunjukkan kemiripan yang lebih besar antara kedua vektor. |
Dot product (dot_product) |
| Tertinggi | Mengalikan koordinat yang bersesuaian dari dua vektor dengan dimensi yang sama, lalu menjumlahkan hasilnya. Skor dot product yang lebih tinggi menunjukkan kemiripan yang lebih besar antara dua vektor. Penting Vektor Float32 harus dinormalisasi sebelum ditulis ke tabel, misalnya menggunakan norma L2. Jika tidak, potensi masalah seperti hasil kueri buruk, pembuatan indeks vektor lambat, dan performa kueri buruk dapat terjadi. Untuk contoh normalisasi vektor, lihat Lampiran 2: Contoh normalisasi vektor. |
Cosine similarity (cosine) |
| Rendah | Kosinus sudut antara dua vektor dalam ruang vektor. Skor kemiripan kosinus yang lebih tinggi menunjukkan kemiripan yang lebih tinggi antara dua vektor. Ini sering digunakan untuk menghitung kemiripan data teks. Karena 0 tidak dapat digunakan sebagai pembagi, perhitungan kemiripan kosinus tidak dapat diselesaikan jika jumlah kuadrat vektor Float32 adalah 0. Penting Perhitungan cosine similarity cukup kompleks. Kami menyarankan agar Anda melakukan normalisasi vektor sebelum menulis data ke tabel, lalu menggunakan dot_product sebagai algoritma ukuran jarak. Untuk contoh normalisasi vektor, lihat Lampiran 2: Contoh normalisasi vektor. |



Catatan
Saat menggunakan vector search, perhatikan hal-hal berikut:
Berlaku batasan terhadap jumlah tipe bidang vektor, dimensi, dan properti lainnya. Untuk informasi selengkapnya, lihat Search index limits.
Search index dipartisi di sisi server. Setiap partisi mengembalikan TopK nearest neighbors-nya sendiri, dan hasil tersebut kemudian diagregasi di client node. Oleh karena itu, jika Anda menggunakan token untuk melakukan paginasi melalui seluruh data, jumlah total baris yang dikembalikan bergantung pada jumlah partisi di sisi server.
Saat ini, fitur vector search tersedia di wilayah-wilayah berikut: China (Hangzhou), China (Shanghai), China (Qingdao), China (Beijing), China (Zhangjiakou), China (Ulanqab), China (Shenzhen), China (Guangzhou), China (Chengdu), China (Hong Kong), Jepang (Tokyo), Singapura, Malaysia (Kuala Lumpur), Indonesia (Jakarta), Filipina (Manila), Thailand (Bangkok), Jerman (Frankfurt), Inggris (London), AS (Virginia), AS (Silicon Valley), SAU (Riyadh - Partner Region).
Prosedur
Gunakan model open source untuk mengonversi data di Tablestore menjadi vektor dan menyimpannya.
Tulis data vektor ke Tablestore.
Saat Anda membuat indeks pencarian, konfigurasikan bidang vektor.
Konfigurasikan tipe, dimensi, dan algoritma ukuran jarak bidang vektor tersebut.
Gunakan Pencarian vektor untuk melakukan kueri data.
Penagihan
Selama pratinjau publik, Anda tidak dikenai biaya untuk item yang dapat ditagih terkait fitur KNN vector query. Biaya tetap berlaku untuk item yang dapat ditagih lainnya sesuai aturan penagihan yang berlaku.
Saat Anda menggunakan indeks pencarian untuk mengkueri data, Anda akan dikenakan biaya untuk throughput baca yang dikonsumsi. Untuk informasi lebih lanjut, lihat Item yang dapat ditagih dari indeks pencarian.
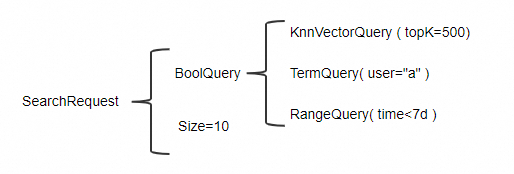
Lampiran 1: Penggunaan dengan BoolQuery
Anda dapat menggabungkan KnnVectorQuery dan BoolQuery dengan berbagai cara untuk mendapatkan hasil yang berbeda. Bagian ini menjelaskan dua kasus penggunaan umum. Contoh ini mengasumsikan skenario di mana filter mencocokkan jumlah data yang kecil.
Misalkan sebuah tabel berisi 100 juta gambar. Seorang pengguna memiliki total 50.000 gambar, tetapi hanya 50 di antaranya yang ditambahkan dalam 7 hari terakhir. Pengguna ingin menggunakan pencarian berdasarkan gambar untuk menemukan 10 gambar paling mirip dari yang ditambahkan dalam 7 hari terakhir. Tabel berikut menunjukkan bagaimana penggunaan BoolQuery di dalam filter KnnVectorQuery dapat memenuhi kebutuhan ini.
Penggunaan gabungan | Diagram kondisi kueri | Deskripsi |
Gunakan BoolQuery di dalam filter KnnVectorQuery |
| KnnVectorQuery mengenai baris-baris yang memenuhi kondisi BoolQuery dan mengembalikan baris paling mirip TopK. Respons SearchRequest mengembalikan `Size` baris pertama dari hasil TopK tersebut. Dalam contoh ini, KnnVectorQuery pertama-tama menggunakan filter untuk memilih semua 50 gambar milik pengguna "a" dari 7 hari terakhir. Kemudian, sistem menemukan 10 gambar paling mirip dari ke-50 gambar tersebut dan mengembalikannya. |
Gunakan KnnVectorQuery di dalam BoolQuery |
| Setiap subkueri dalam BoolQuery dieksekusi terlebih dahulu, lalu irisan dari seluruh hasil subkueri dihitung. Dalam contoh ini, KnnVectorQuery mengembalikan 500 gambar paling mirip dari 100 juta gambar dalam tabel. Selanjutnya, sistem secara berurutan mencari 10 gambar milik pengguna "a" dari 7 hari terakhir. Namun, 500 gambar teratas mungkin tidak mencakup seluruh 50 gambar milik pengguna "a" dari 7 hari terakhir. Oleh karena itu, metode kueri ini mungkin tidak menemukan 10 gambar paling mirip dari 7 hari terakhir, bahkan bisa jadi tidak mengembalikan data sama sekali. |

Lampiran 2: Contoh normalisasi vektor
Kode berikut menunjukkan contoh normalisasi vektor:
public static float[] l2normalize(float[] v, boolean throwOnZero) {
double squareSum = 0.0f;
int dim = v.length;
for (float x : v) {
squareSum += x * x;
}
if (squareSum == 0) {
if (throwOnZero) {
throw new IllegalArgumentException("can't normalize a zero-length vector");
} else {
return v;
}
}
double length = Math.sqrt(squareSum);
for (int i = 0; i < dim; i++) {
v[i] /= length;
}
return v;
}