Indeks pencarian menggunakan inverted index dan column store untuk mendukung kueri multi-dimensi dan analisis statistik pada data besar. Gunakan indeks pencarian untuk kueri kolom non-primary key, kueri boolean, kueri fuzzy, pencarian teks lengkap, pencarian vektor, serta agregasi seperti max, min, count, dan group by.
Informasi latar belakang
Indeks pencarian hanya berlaku untuk model tabel lebar.
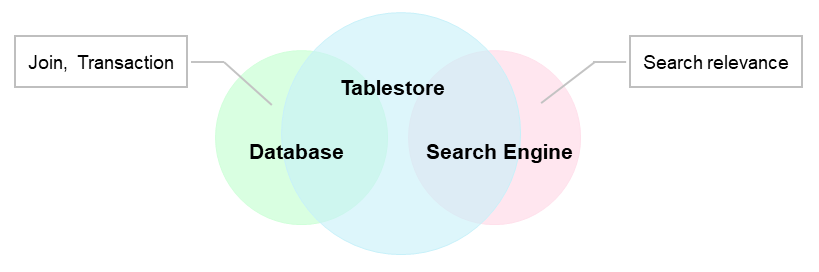
Indeks pencarian, database, dan mesin pencari semuanya mengatasi permasalahan kueri kompleks dalam data besar, tetapi berbeda dalam hal-hal berikut:
Kecuali untuk join, transaksi, dan analisis relevansi, Tablestore menyediakan fitur-fitur dari kedua sistem—database dan sistem pencarian. Tablestore menggabungkan keandalan data tingkat tinggi dari database dengan kemampuan kueri lanjutan dari sistem pencarian, sehingga menggantikan arsitektur umum database + search engine.
Jika skenario Anda tidak melibatkan join, transaksi, atau analisis relevansi yang kompleks, gunakan indeks pencarian Tablestore.
Ikhtisar indeks
Indeks pencarian menggunakan inverted index dan column store untuk menyelesaikan permasalahan kueri multi-dimensi dan analisis statistik pada data besar. Indeks ini mendukung kueri kolom non-primary key, kueri awalan (prefix), kueri fuzzy, kueri boolean, kueri bersarang (nested), kueri geografis (geo), pencarian teks lengkap, pencarian vektor, serta agregasi statistik (max, min, count, sum, avg, distinct_count, group_by, persentil, dan histogram).
Gambar berikut menunjukkan struktur inverted index, column store, dan indeks spasial multi-dimensi yang digunakan oleh indeks pencarian.
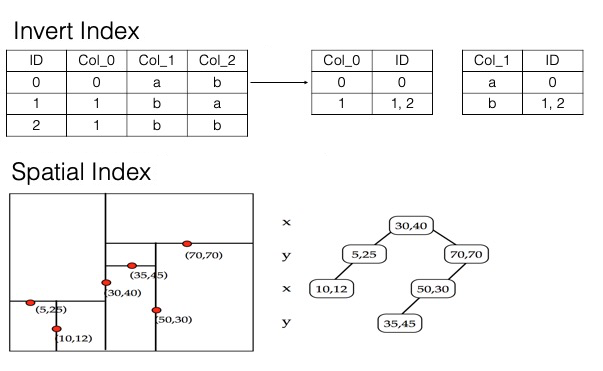
Berbeda dengan indeks database tradisional (seperti MySQL), indeks pencarian tidak dibatasi oleh aturan pencocokan prefiks paling kiri (leftmost prefix matching rule). Dalam sebagian besar kasus, Anda hanya memerlukan satu indeks pencarian per tabel. Misalnya, tabel siswa dengan kolom seperti nama, nomor induk siswa, jenis kelamin, kelas, dan alamat rumah hanya memerlukan satu indeks pencarian untuk mendukung kueri gabungan seperti siswa bernama John Doe di kelas tiga, siswa laki-laki yang alamat rumahnya berada dalam jarak 1 km, atau siswa di Kelas 2 Tingkat 3 yang tinggal di kawasan perumahan tertentu.
Perbandingan indeks
Tablestore mendukung kueri primary key pada tabel data, ditambah dua jenis indeks untuk mempercepat kueri: secondary index dan search index. Tabel berikut membandingkan ketiga metode kueri tersebut.
|
Metode kueri |
Prinsip |
Skenario |
|
Primary key |
Tabel data berfungsi seperti peta besar. Anda hanya dapat mengkueri data berdasarkan primary key. |
Cocok untuk skenario di mana Anda mengetahui seluruh primary key atau awalan kunci (key prefix). |
|
Secondary index |
Membuat tabel indeks yang kolom primary key-nya memperluas kemampuan kueri tabel data ke kolom-kolom berbeda. |
Cocok untuk skenario di mana kolom kueri telah ditentukan sebelumnya, jumlah kolom sedikit, dan Anda mengetahui seluruh primary key atau awalan kunci. |
|
Search index |
Menggunakan struktur seperti inverted index, pohon BKD, dan column store untuk menyediakan kemampuan kueri yang kaya. |
Cocok untuk semua skenario kueri dan analisis di luar cakupan primary key dan secondary index: kueri kolom non-primary key, kueri boolean pada kolom apa pun, kueri relasi, pencarian teks lengkap, kueri geografis, kueri fuzzy, kueri bersarang, kueri nilai NULL, dan agregasi statistik. |
Skenario
Indeks pencarian banyak digunakan untuk kueri dan analisis data lintas sistem aplikasi. Tabel berikut mencantumkan skenario umum.
|
Sistem aplikasi |
Skenario contoh |
|
E-commerce platform |
Menerapkan kategorisasi produk dan penyaringan atribut untuk membantu pengguna mencari dan menyaring produk secara cepat. |
|
Aplikasi sosial |
Mengkueri hubungan pengikut dan pertemanan pengguna, atau merekomendasikan dan mencocokkan pengguna berdasarkan tag minat. |
|
Analisis log |
Menjalankan pencarian kata kunci dan kueri rentang waktu untuk cepat mengidentifikasi masalah dan menganalisis data log. |
|
Analitik data Internet of Things |
Mengkueri dan menganalisis data perangkat. Misalnya, menyaring dan menghitung data berdasarkan jenis perangkat atau lokasi geografis. |
|
Pemantauan kinerja aplikasi |
Mengagregasi dan mengkueri data metrik. Misalnya, menyaring dan merangkum data berdasarkan rentang waktu atau nama aplikasi. |
|
Layanan berbasis lokasi |
Menjalankan kueri geografis dan pencarian terdekat untuk memberikan informasi tentang toko, tempat wisata, dan layanan di sekitar pengguna. |
|
Mesin pencari teks |
Menjalankan pencarian teks lengkap dan pengurutan berdasarkan relevansi untuk cepat menemukan dokumen, artikel, dan konten lainnya. |
Fitur
Daftar fitur
Tabel berikut mencantumkan fitur-fitur indeks pencarian.
|
Fitur |
Deskripsi |
Dokumen |
|
Kueri pada kolom apa pun (termasuk kolom primary key dan non-primary key) |
Mengkueri data berdasarkan kolom apa pun. Cocok untuk sebagian besar skenario kueri. Jika kueri primary key atau awalan kunci tidak memenuhi kebutuhan Anda, buatlah indeks pencarian dengan bidang target dan kueri berdasarkan nilai kolom. |
Kueri indeks pencarian apa pun, seperti kueri dasar |
|
Kueri boolean |
Menggabungkan beberapa bidang untuk penyaringan efisien. Cocok untuk sistem pesanan, analisis log, dan persona pengguna. Dalam database relasional, tabel dengan puluhan bidang mungkin memerlukan ratusan indeks untuk mencakup semua kombinasi bidang. Kombinasi yang tidak tercakup menghasilkan kueri tidak efisien. Dengan Tablestore, satu indeks pencarian mencakup semua kombinasi bidang. Tambahkan bidang yang mungkin Anda kueri ke indeks, lalu bebas menggabungkannya menggunakan logika And, Or, dan Not. |
|
|
Kueri geografis |
Perangkat seluler telah menjadikan data lokasi geografis semakin berharga. Aplikasi untuk jejaring sosial, pengiriman makanan, olahraga, dan Internet of Vehicles (IoV) semuanya memerlukan kueri berbasis lokasi. Indeks pencarian mendukung fitur kueri geografis berikut:
Jika aplikasi Anda memerlukan kueri berbasis lokasi, indeks pencarian Tablestore menyediakan solusi terpadu tanpa perlu database atau sistem pencarian tambahan. |
|
|
Indeks teks lengkap |
Menemukan data yang berisi frasa tertentu. Cocok untuk analitik data besar, pencarian konten, manajemen pengetahuan, analisis media sosial, analisis log, sistem Chat AI, tinjauan kepatuhan, dan rekomendasi personalisasi. Indeks pencarian menggunakan tokenisasi untuk pencarian teks lengkap. Indeks ini menyediakan relevansi BM25 dasar tetapi tidak mendukung relevansi kustom. Untuk kebutuhan pencarian relevansi kompleks, gunakan sistem pencarian khusus; jika tidak, indeks pencarian sudah cukup. Tersedia lima jenis tokenisasi: satu kata, pembatas (delimiter), semantik minimum, semantik maksimum, dan fuzzy. Untuk menyorot kata kunci dalam hasil, gunakan fitur ringkasan dan penyorotan (summary and highlighting). |
|
|
Pencarian vektor |
Indeks pencarian mendukung pencarian vektor untuk kueri tetangga terdekat perkiraan (approximate nearest neighbor) yang efisien pada dataset berskala besar. Cocok untuk Generasi yang Diperkaya dengan Pengambilan Data (RAG), sistem rekomendasi, deteksi kemiripan (gambar, video, dan suara), serta Pemrosesan bahasa alami. |
|
|
Kueri fuzzy |
Indeks pencarian menyediakan kueri wildcard, awalan (prefix), dan akhiran (suffix) untuk pencocokan fuzzy dalam berbagai skenario.
|
|
|
Kueri keberadaan kolom (kueri NULL) |
Memeriksa apakah suatu kolom memiliki nilai null. Cocok untuk pemeriksaan integritas data dan pembersihan data. |
|
|
Kueri bersarang |
Selain struktur datar, data aplikasi sering kali memiliki struktur bersarang multi-level. Misalnya, sistem pelabelan gambar menyimpan gambar dengan beberapa entitas (rumah, mobil, orang), masing-masing dengan posisi, ukuran, dan bobot (skor) berbeda. Setiap gambar dipetakan ke beberapa tag, dan setiap tag memiliki nama serta skor bobot. Untuk menyaring gambar berdasarkan kondisi tag, gunakan kueri tipe bersarang (nested type query). Tag gambar disimpan dalam format JSON: Kueri tipe bersarang menangani data dengan hubungan logis multi-level, memberikan fleksibilitas untuk pemodelan data kompleks. Untuk struktur data bersarang kompleks (seperti JSON), gunakan fitur ringkasan dan penyorotan untuk menemukan informasi yang diperlukan secara tepat. |
|
|
Deduplikasi |
Indeks pencarian menghapus duplikat hasil kueri untuk meningkatkan keragaman. Deduplikasi membatasi seberapa sering nilai atribut tertentu muncul dalam satu set hasil. Misalnya, saat mencari |
|
|
Pengurutan |
Tablestore secara default mengurutkan data berdasarkan primary key dalam urutan alfabetis. Untuk mengurutkan berdasarkan bidang lain, gunakan fitur pengurutan indeks pencarian. Indeks pencarian mendukung urutan menaik atau menurun, pengurutan satu kondisi, dan pengurutan multi-kondisi. Semua pengurutan bersifat global. Secara default, hasil indeks pencarian diurutkan berdasarkan primary key dalam urutan alfabetis. |
|
|
Jumlah total baris |
Saat mengkueri data dengan indeks pencarian, Anda dapat mengembalikan jumlah baris yang cocok. Ini berguna untuk validasi data dan operasi.
|
|
|
Agregasi statistik |
Indeks pencarian menyediakan fungsi agregasi umum: Max, Min, Avg, Sum, Count, DistinctCount, GroupBy, Persentil, dan Histogram. Fungsi-fungsi ini memenuhi kebutuhan statistik dasar untuk analisis ringan. |
Wilayah yang didukung
Saat ini, fitur indeks pencarian tersedia di wilayah-wilayah berikut: Tiongkok (Hangzhou), Tiongkok (Shanghai), Tiongkok (Qingdao), Tiongkok (Beijing), Tiongkok (Zhangjiakou), Tiongkok (Ulanqab), Tiongkok (Shenzhen), Tiongkok (Guangzhou), Tiongkok (Chengdu), Tiongkok (Hong Kong), Jepang (Tokyo), Singapura, Malaysia (Kuala Lumpur), Indonesia (Jakarta), Filipina (Manila), Thailand (Bangkok), Jerman (Frankfurt), Inggris (London), AS (Silicon Valley), AS (Virginia), SAU (Riyadh - Partner Region), dan . Fitur pencarian vektor belum didukung di wilayah AS (Silicon Valley).
Pemulihan bencana
Di wilayah yang memiliki kemampuan pemulihan bencana antar-zona, indeks pencarian menyediakan penyimpanan redundan zona secara default. Data disimpan di beberapa zona dalam satu wilayah. Jika satu zona gagal, layanan baca dan tulis tetap berjalan tanpa gangguan.
Saat ini, indeks pencarian mendukung penyimpanan redundan zona di wilayah-wilayah berikut: Tiongkok (Hangzhou), Tiongkok (Shanghai), Tiongkok (Beijing), Tiongkok (Zhangjiakou), Tiongkok (Ulanqab), Tiongkok (Shenzhen), Tiongkok (Hong Kong), Jepang (Tokyo), Singapura, Indonesia (Jakarta), Jerman (Frankfurt), dan .
Siklus Hidup Data
Jika tabel data Anda tidak memiliki operasi UpdateRow, Anda dapat menggunakan TTL indeks pencarian. Manajemen siklus hidup.
Jika Anda hanya perlu menyimpan data untuk periode tertentu dan bidang waktu tidak perlu diperbarui, terapkan TTL dengan melakukan sharding tabel berdasarkan waktu.
|
Dimensi |
Sharding tabel berdasarkan waktu |
|
Prinsip |
Lakukan sharding tabel berdasarkan interval tetap (hari, minggu, bulan, atau tahun). Buat indeks pencarian untuk setiap tabel dan simpan tabel data sesuai durasi yang diperlukan. Misalnya, untuk menyimpan data selama enam bulan, simpan data setiap bulan dalam tabel terpisah (tabel_1 hingga tabel_6) dengan indeks pencarian masing-masing. Setiap bulan, hapus tabel dari enam bulan sebelumnya. Saat mengkueri, jika rentang waktu berada dalam satu tabel, kueri hanya tabel tersebut. Jika mencakup beberapa tabel, kueri masing-masing dan gabungkan hasilnya. |
|
Aturan |
Satu tabel (satu indeks) tidak boleh melebihi 50 miliar baris. Performa kueri optimal jika jumlah baris tetap di bawah 20 miliar. |
|
Keuntungan |
|
Versi data
Indeks pencarian tidak mendukung beberapa versi data. Anda tidak dapat membuat indeks pencarian untuk tabel data yang memiliki beberapa versi yang diaktifkan.
Pada tabel versi tunggal, jika Anda menyesuaikan timestamp untuk setiap penulisan, menulis data dengan nomor versi lebih kecil setelah yang lebih besar dapat menimpa versi yang lebih besar.
Data yang dikembalikan oleh permintaan Search dan ParallelScan tidak selalu mencakup properti timestamp.
Batasan
Indeks pencarian menyinkronkan data dari tabel data secara asinkron, sehingga kueri real-time tidak dimungkinkan. Latensi tipikal berada dalam 3 detik. Batasan indeks pencarian.
Penagihan
Indeks pencarian dikenai biaya berdasarkan storage space yang digunakan oleh data indeks dan sumber daya komputasi yang dikonsumsi untuk kueri dan analisis. Ikhtisar penagihan.
Pengembangan dan integrasi
Referensi API
Indeks pencarian menyediakan operasi API untuk manajemen indeks dan kueri data. Kueri data mencakup API Search umum dan API ParallelScan untuk ekspor data. ParallelScan mengorbankan beberapa fitur (pengurutan, agregasi) demi performa dan throughput yang lebih tinggi.
|
Kategori |
API |
Deskripsi |
|
Manajemen indeks |
Membuat indeks pencarian. |
|
|
Memperbarui konfigurasi indeks pencarian, termasuk masa hidup data (TTL) dan skema indeks. |
||
|
Mendapatkan deskripsi detail indeks pencarian. |
||
|
Menampilkan daftar indeks pencarian. |
||
|
Menghapus indeks pencarian. |
||
|
Kueri data |
API kueri lengkap. Mendukung semua fitur indeks pencarian termasuk fungsi kueri, pengurutan, dan agregasi statistik. Hasil dikembalikan dalam urutan yang ditentukan.
|
|
|
API ekspor data dengan dukungan pemindaian paralel. Mencakup semua fungsi kueri tetapi tidak menyertakan pengurutan dan agregasi statistik. Mengembalikan semua data yang cocok dengan kecepatan lebih tinggi. Dengan konkurensi tunggal, throughput ParallelScan adalah 5x lebih tinggi daripada API Search.
Saat mengekspor data dengan beberapa permintaan konkuren, gunakan API ComputeSplits untuk mendapatkan konkurensi maksimum untuk satu permintaan ParallelScan. |
Metode integrasi
Anda dapat menggunakan SDK atau alat CLI berikut untuk bekerja dengan indeks pencarian.
FAQ
-
Bagaimana cara memilih antara secondary index dan search index?
-
Mengapa saya tidak dapat mengambil data menggunakan API Search dari indeks pencarian?
-
Apa perbedaan antara menggunakan API GetRange dan API Search untuk kueri rentang?
-
Apakah Tablestore mendukung kueri yang mirip dengan 'in' dan 'between...and' di database relasional?
-
Bagaimana cara meningkatkan 'limit' untuk API Search dari indeks pencarian menjadi 1.000?
-
Mengapa CU baca yang dicadangkan dihasilkan saat saya menggunakan indeks pencarian?
-
Apakah konfigurasi CU baca yang dicadangkan untuk indeks pencarian dapat disesuaikan?
-
Bagaimana cara melihat data metering untuk indeks pencarian?
Referensi
-
Untuk mengkueri dan menganalisis data dengan SQL, gunakan fitur kueri SQL Tablestore.
CatatanAnda juga dapat menganalisis data di Tablestore menggunakan mesin komputasi seperti MaxCompute, Spark, Hive, HadoopMR, Function Compute, atau Flink. Ikhtisar komputasi dan analisis.
Lampiran: Pemetaan SQL
Beberapa fitur indeks pencarian dipetakan ke fungsi SQL. Tabel berikut mencantumkan pemetaan tersebut.
|
SQL |
Indeks pencarian |
Dokumentasi indeks pencarian |
|
Show |
DescribeSearchIndex |
|
|
Select |
Parameter ColumnsToGet dalam kueri apa pun |
Kueri indeks pencarian apa pun, seperti kueri dasar |
|
From |
Parameter IndexName dalam kueri apa pun Penting
Hanya mendukung satu indeks. Beberapa indeks belum didukung. |
Kueri indeks pencarian apa pun, seperti kueri dasar |
|
Where |
Kondisi dalam kueri apa pun |
Kueri indeks pencarian apa pun, seperti kueri dasar |
|
Order by |
Parameter sort dalam kueri apa pun |
|
|
Limit |
Parameter limit dalam kueri apa pun |
|
|
Delete |
|
|
|
Like |
WildcardQuery |
|
|
And |
Operator dan dalam BoolQuery |
|
|
Or |
operator = or dalam BoolQuery |
|
|
Not |
BoolQuery(mustNotQueries) |
|
|
Between |
RangeQuery |
|
|
Null |
ExistsQuery |
|
|
In |
TermsQuery |
|
|
Min |
Agregasi: min |
|
|
Max |
Agregasi: max |
|
|
Avg |
Agregasi: avg |
|
|
Count |
Agregasi: count |
|
|
Count(distinct) |
Agregasi: distinctCount |
|
|
Sum |
Agregasi: sum |
|
|
Group By |
GroupBy |