Layanan log memungkinkan Anda mengumpulkan dan menganalisis log akses NGINX. Topik ini menjelaskan cara memantau, menganalisis, mendiagnosis, serta mengoptimalkan akses ke situs web.
Prasyarat
Data log telah dikumpulkan. Untuk informasi lebih lanjut, lihat Kumpulkan Log Teks dalam Mode Konfigurasi NGINX.
Fitur pengindeksan telah diaktifkan dan dikonfigurasi. Untuk informasi lebih lanjut, lihat Buat Indeks.
Informasi latar belakang
NGINX adalah server HTTP gratis, open-source, dan berperforma tinggi yang dapat digunakan untuk membangun dan meng-host situs web. Log akses NGINX dapat dikumpulkan dan dianalisis. Dalam metode tradisional seperti CNZZ, skrip JavaScript disisipkan ke halaman frontend situs web dan dipicu ketika pengguna mengunjungi situs tersebut. Namun, metode ini hanya mencatat permintaan akses. Komputasi aliran, komputasi offline, dan analisis offline juga dapat digunakan untuk menganalisis log akses NGINX. Namun, metode-metode tersebut memerlukan lingkungan khusus dan sulit menyeimbangkan efisiensi waktu dengan fleksibilitas selama analisis log.
Di konsol Simple Log Service, Anda dapat membuat konfigurasi pengumpulan untuk mengumpulkan log akses NGINX menggunakan wizard impor data. Kemudian, Simple Log Service membuat indeks dan dasbor NGINX untuk membantu Anda mengumpulkan dan menganalisis log akses NGINX. Dasbor menampilkan metrik seperti Distribusi Alamat IP, Kode Status HTTP, Metode Permintaan, Statistik Page View (PV) dan Unique Visitor (UV), Trafik arah masuk dan arah keluar, User Agents, 10 URL Permintaan Teratas, 10 URI Teratas berdasarkan Jumlah Permintaan, dan 10 URI Teratas berdasarkan Latensi Permintaan. Anda dapat menggunakan pernyataan kueri untuk menganalisis latensi akses situs web Anda dan mengoptimalkan performa situs web secepat mungkin. Anda dapat membuat peringatan untuk melacak masalah performa, kesalahan server, dan perubahan trafik. Jika kondisi pemicu terpenuhi, notifikasi peringatan akan dikirim ke penerima yang ditentukan.
Analisis akses ke situs web
Masuk ke konsol Simple Log Service.
Di bagian Proyek, klik yang ingin Anda kelola.

Di panel navigasi sisi kiri, pilih . Temukan Logstore dan klik ikon > di sebelahnya.
Klik ikon > di sebelah Visual Dashboards, lalu klik LogstoreName_Nginx_access_log.
Dasbor menampilkan metrik berikut:
Distribution of IP Addresses: Mengumpulkan statistik tentang distribusi alamat IP dengan mengeksekusi pernyataan SQL berikut:
* | select count(1) as c, ip_to_province(remote_addr) as address group by address limit 100HTTP Status Codes: Menghitung persentase setiap kode status HTTP yang dikembalikan dalam 24 jam terakhir dengan mengeksekusi pernyataan SQL berikut:
* | select count(1) as pv, status group by status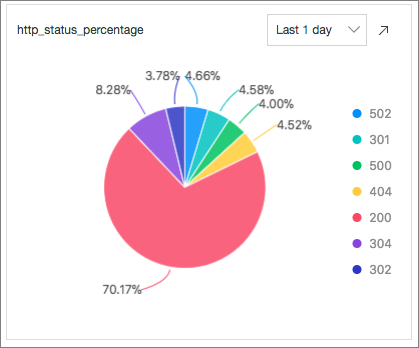
Request Methods: Menghitung persentase setiap metode permintaan yang digunakan dalam 24 jam terakhir dengan mengeksekusi pernyataan SQL berikut:
* | select count(1) as pv ,request_method group by request_method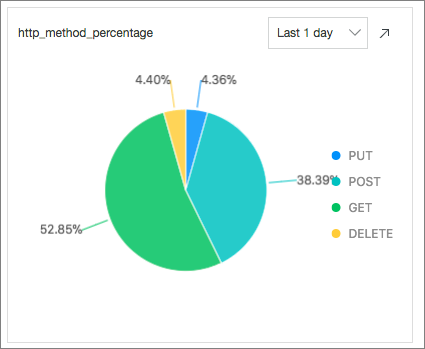
User Agents: Menghitung persentase setiap user agent yang digunakan dalam 24 jam terakhir dengan mengeksekusi pernyataan SQL berikut:
* | select count(1) as pv, case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end as http_user_agent group by case when http_user_agent like '%Chrome%' then 'Chrome' when http_user_agent like '%Firefox%' then 'Firefox' when http_user_agent like '%Safari%' then 'Safari' else 'unKnown' end order by pv desc limit 10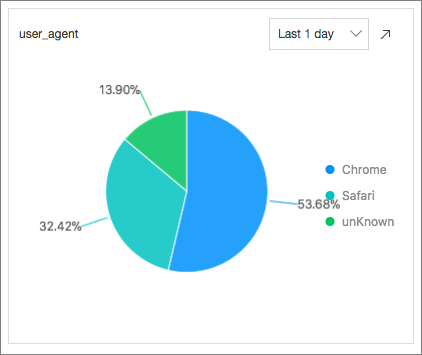
Top 10 Request URLs: Menunjukkan 10 URL permintaan teratas dengan PV terbanyak dalam 24 jam terakhir dengan mengeksekusi pernyataan SQL berikut:
* | select count(1) as pv , http_referer group by http_referer order by pv desc limit 10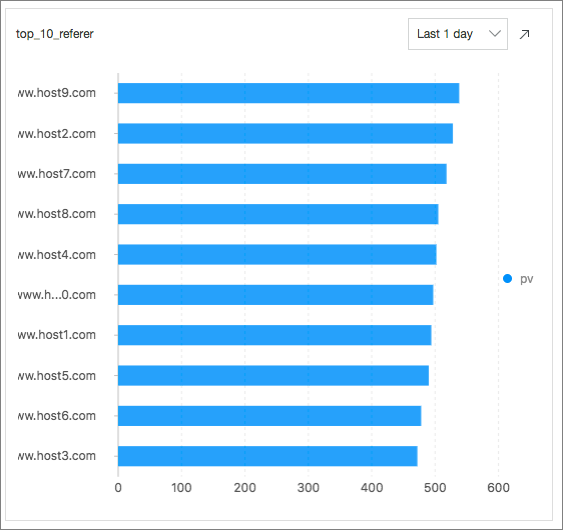
Inbound and Outbound Traffic: Mengumpulkan statistik terkait trafik arah masuk dan arah keluar dengan menjalankan pernyataan SQL berikut:
* | select sum(body_bytes_sent) as net_out, sum(request_length) as net_in ,date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 10000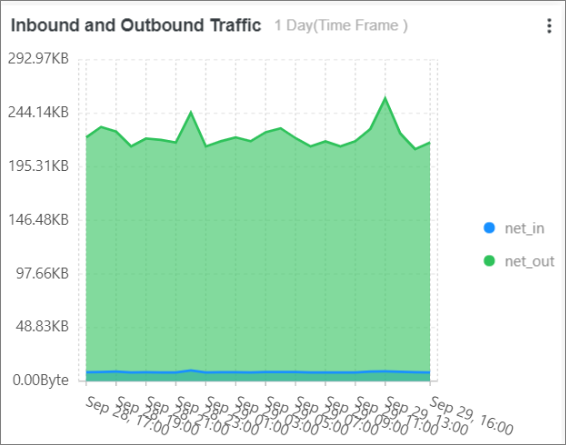
PV and UV Statistics: Menghitung jumlah PV dan UV dengan mengeksekusi pernyataan SQL berikut:
*| select approx_distinct(remote_addr) as uv ,count(1) as pv , date_format(date_trunc('hour', __time__), '%m-%d %H:%i') as time group by date_format(date_trunc('hour', __time__), '%m-%d %H:%i') order by time limit 1000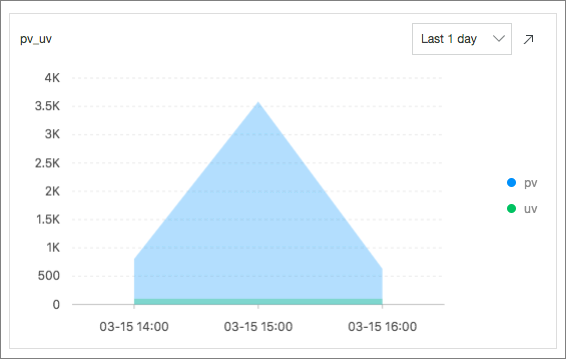
Predicted PV: Memprediksi jumlah PV dalam 4 jam ke depan dengan mengeksekusi pernyataan SQL berikut:
* | select ts_predicate_simple(stamp, value, 6, 1, 'sum') from (select __time__ - __time__ % 60 as stamp, COUNT(1) as value from log GROUP BY stamp order by stamp) LIMIT 1000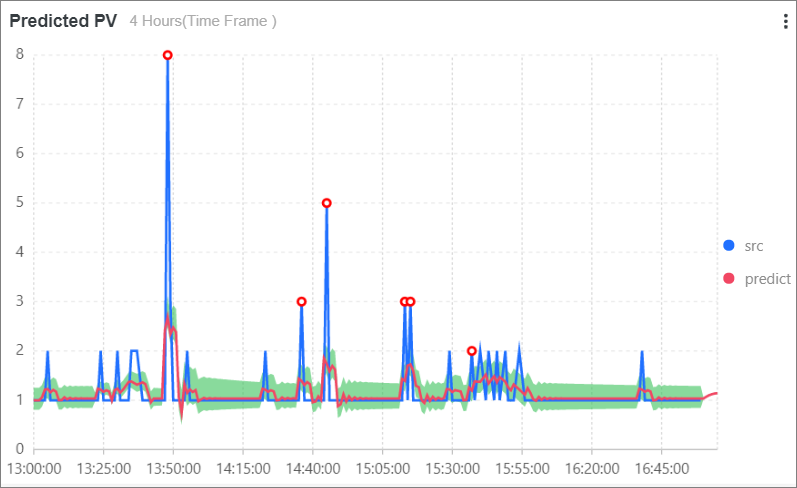
Top 10 URLs by Number of Requests: Menunjukkan 10 URL permintaan teratas dengan PV terbanyak dalam 24 jam terakhir dengan mengeksekusi pernyataan SQL berikut:
* | select count(1) as pv, split_part(request_uri,'?',1) as path group by path order by pv desc limit 10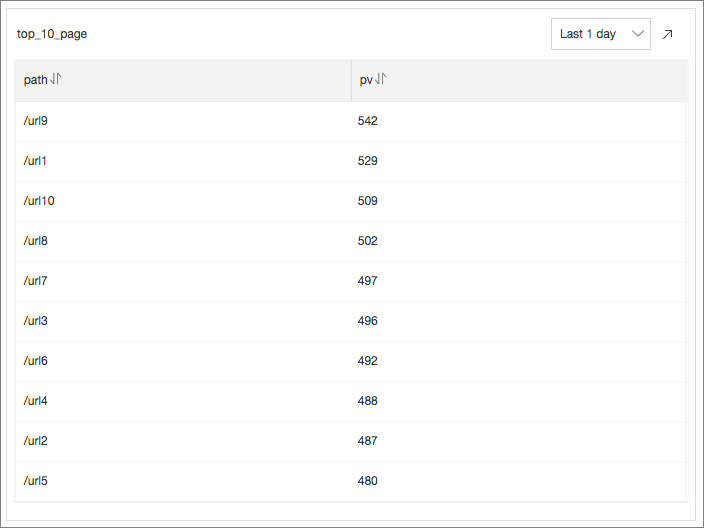
Mendiagnosis dan mengoptimalkan akses ke situs web
Selain beberapa metrik akses default, Anda juga harus mendiagnosis permintaan akses berdasarkan log akses NGINX. Ini memungkinkan Anda menemukan permintaan dengan latensi tinggi pada halaman tertentu. Anda dapat menggunakan fitur analisis cepat di halaman Pencarian & Analisis. Untuk informasi lebih lanjut, lihat Panduan untuk Kueri dan Analisis Log.
Hitung latensi rata-rata dan latensi tertinggi setiap 5 menit untuk mendapatkan latensi keseluruhan dengan mengeksekusi pernyataan SQL berikut:
* | select from_unixtime(__time__ -__time__% 300) as time, avg(request_time) as avg_latency , max(request_time) as max_latency group by __time__ -__time__% 300Temukan halaman yang diminta dengan latensi tertinggi dan optimalkan kecepatan respons halaman tersebut dengan mengeksekusi pernyataan SQL berikut:
* | select from_unixtime(__time__ - __time__% 60) , max_by(request_uri,request_time) group by __time__ - __time__%60Bagilah semua permintaan menjadi 10 kelompok berdasarkan latensi akses dan hitung jumlah permintaan berdasarkan rentang latensi yang berbeda dengan mengeksekusi pernyataan SQL berikut:
* |select numeric_histogram(10,request_time)Hitung 10 permintaan teratas dengan latensi tertinggi dan latensi setiap permintaan dengan mengeksekusi pernyataan SQL berikut:
* | select max(request_time,10)Optimalkan halaman yang diminta dengan latensi tertinggi.
Asumsikan bahwa halaman /url2 memiliki latensi tertinggi. Untuk mengoptimalkan kecepatan respons halaman /url2, hitung metrik berikut untuk halaman /url2: jumlah PV dan UV, jumlah kali setiap metode permintaan digunakan, jumlah kali setiap kode status HTTP dikembalikan, jumlah kali setiap jenis browser digunakan, latensi rata-rata, dan latensi tertinggi.
request_uri:"/url2" | select count(1) as pv, approx_distinct(remote_addr) as uv, histogram(method) as method_pv, histogram(status) as status_pv, histogram(user_agent) as user_agent_pv, avg(request_time) as avg_latency, max(request_time) as max_latencyBandingkan PV hari ini dan kemarin:
* | select diff [1] as today, round((diff [3] -1.0) * 100, 2) as growth FROM ( SELECT compare(pv, 86400) as diff FROM ( SELECT COUNT(1) as pv FROM log ) )Hitung perbandingan harian PV hari ini dan kemarin:
* | select t, diff [1] as today, diff [2] as yestoday, diff [3] as percentage from( select t, compare(pv, 86400) as diff from ( select count(1) as pv, date_format(from_unixtime(__time__), '%H:%i') as t from log group by t limit 10000 ) group by t order by t limit 10000 )
Buat aturan peringatan
Anda dapat membuat aturan peringatan untuk melacak masalah performa, kesalahan server, dan perubahan trafik. Untuk informasi lebih lanjut, lihat Konfigurasikan Aturan Peringatan.
Peringatan Server
Fokuskan pada kesalahan server dengan kode status HTTP 500. Anda dapat mengeksekusi pernyataan SQL berikut untuk menanyakan nomor kesalahan c per satuan waktu dan atur kondisi pemicu aturan peringatan menjadi c > 0.
status:500 | select count(1) as cCatatanUntuk layanan dengan trafik akses tinggi, kesalahan 500 bisa terjadi sesekali. Dalam kasus ini, Anda dapat mengatur parameter Notification Trigger Threshold menjadi 2. Ini menunjukkan bahwa peringatan hanya dipicu ketika kondisi terpenuhi dua kali berturut-turut.
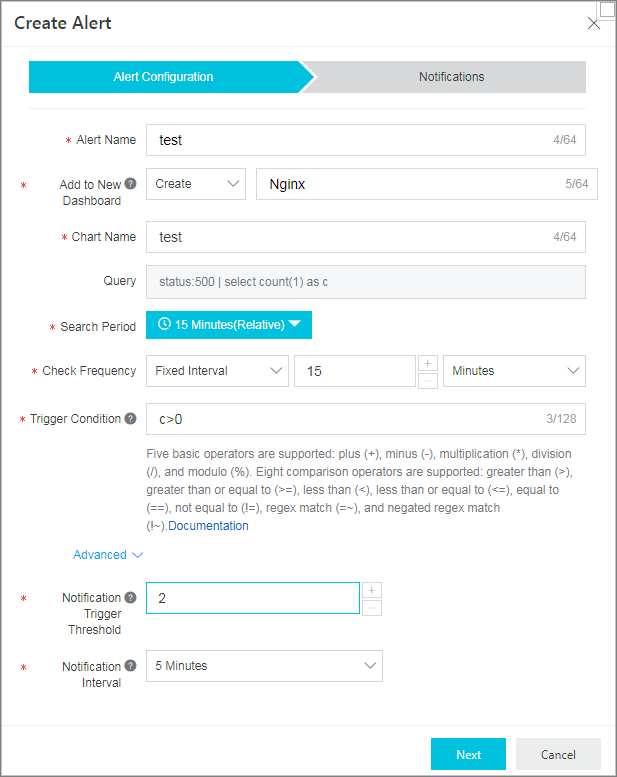
Peringatan Performa
Anda dapat membuat aturan peringatan jika latensi meningkat saat server berjalan. Misalnya, Anda dapat menghitung latensi semua permintaan tulis
Postdari operasi/adduserdengan mengeksekusi pernyataan SQL berikut. Lalu atur aturan peringatan menjadi l > 300000. Ini menunjukkan bahwa peringatan dikirim ketika latensi rata-rata melebihi 300 ms.Method:Post and URL:"/adduser" | select avg(Latency) as lAnda dapat menggunakan nilai latensi rata-rata untuk membuat peringatan. Namun, nilai latensi tinggi dirata-ratakan menjadi nilai lebih rendah, sehingga ini mungkin tidak mencerminkan situasi sebenarnya. Anda dapat menggunakan persentil dalam statistik matematika (latensi tertinggi adalah 99%) sebagai kondisi pemicu.
Method:Post and URL:"/adduser" | select approx_percentile(Latency, 0.99) as p99Anda dapat menghitung latensi setiap menit dalam sehari (1.440 menit), persentil latensi ke-50, dan persentil latensi ke-90.
* | select avg(Latency) as l, approx_percentile(Latency, 0.5) as p50, approx_percentile(Latency, 0.99) as p99, date_trunc('minute', time) as t group by t order by t desc limit 1440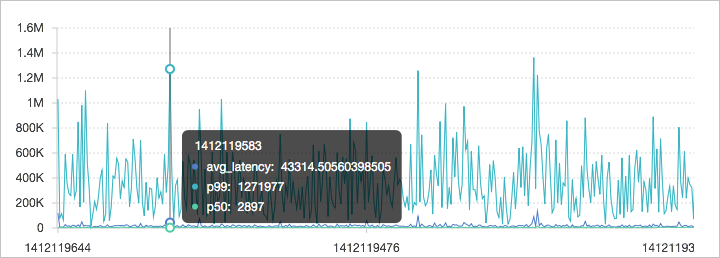
Peringatan Trafik
Penurunan atau peningkatan mendadak trafik dalam periode waktu singkat adalah abnormal. Anda dapat menghitung rasio perubahan trafik dan membuat aturan peringatan untuk memantau perubahan trafik mendadak. Perubahan trafik mendadak dideteksi berdasarkan metrik berikut:
Periode waktu sebelumnya: Membandingkan data dalam periode waktu saat ini dengan periode waktu sebelumnya.
Periode waktu yang sama pada hari sebelumnya: Membandingkan data dalam periode waktu saat ini dengan periode waktu yang sama pada hari sebelumnya.
Periode waktu yang sama pada minggu sebelumnya: Membandingkan data dalam periode waktu saat ini dengan periode waktu yang sama pada minggu sebelumnya.
Jendela terakhir digunakan dalam contoh berikut untuk menghitung rasio perubahan trafik. Dalam contoh ini, rentang waktu diatur menjadi 5 menit.
Tentukan jendela perhitungan.
Tentukan jendela 1 menit untuk menghitung ukuran trafik masuk dalam satu menit ini.
* | select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15Hasilnya menunjukkan bahwa rata-rata trafik masuk didistribusikan secara merata di setiap jendela.
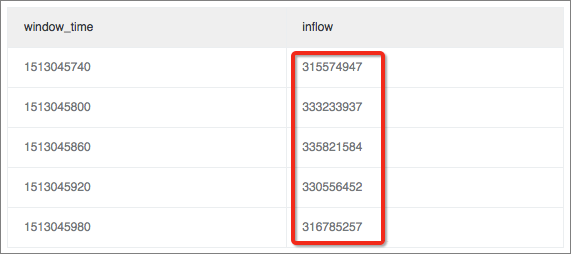
Hitung perbedaan nilai dalam jendela.
Hitung perbedaan antara ukuran trafik maksimum atau minimum dan ukuran trafik rata-rata dalam jendela. Metrik max_ratio digunakan sebagai contoh.
Nilai max_ratio yang dihitung adalah 1,02. Anda dapat mengatur aturan peringatan menjadi max_ratio > 1,5. Ini menunjukkan bahwa peringatan dikirim ketika rasio perubahan melebihi 50%.
* | select max(inflow)/avg(inflow) as max_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)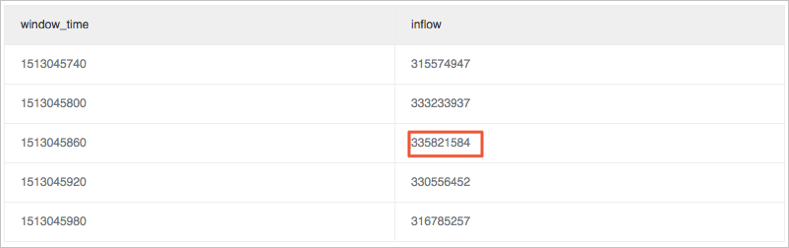
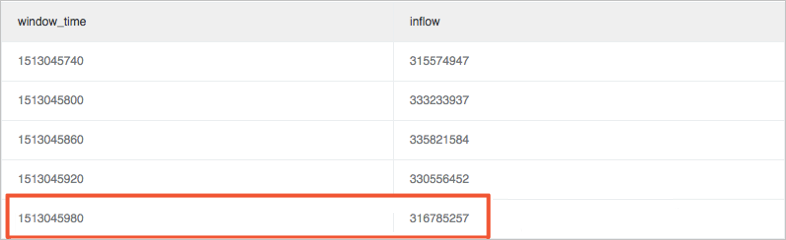
Hitung metrik latest_ratio untuk memeriksa apakah nilai terbaru berfluktuasi.
Gunakan fungsi max_by untuk menghitung ukuran trafik maksimum dalam jendela. Dalam contoh ini, latest_ratio adalah 0,97.
* | select max_by(inflow, window_time)/1.0/avg(inflow) as latest_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)CatatanHasil perhitungan fungsi max_by adalah tipe karakter. Harus dikonversi ke tipe numerik. Untuk menghitung rasio relatif perubahan, Anda dapat mengganti klausa SELECT dengan (1.0-max_by(inflow, window_time)/1.0/avg(inflow)) as latest_ratio.
Hitung rasio fluktuasi. Ini adalah rasio perubahan antara nilai saat ini dan nilai sebelumnya dari jendela.
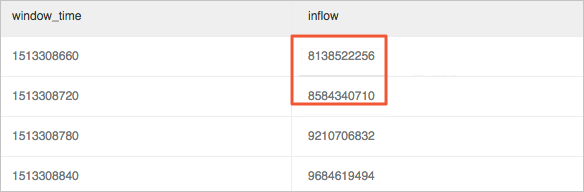
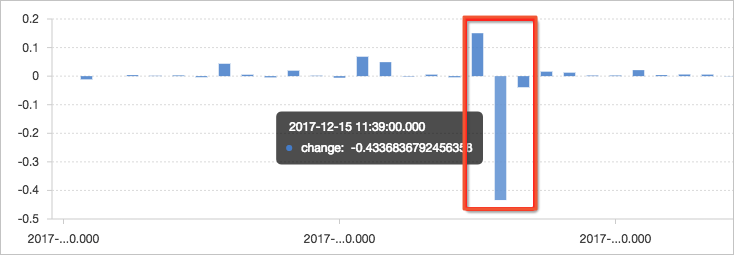
Gunakan fungsi jendela (lag) untuk perhitungan. Ekstrak trafik masuk saat ini dan trafik masuk siklus sebelumnya untuk menghitung perbedaan menggunakan lag(inflow, 1, inflow)over(). Lalu, bagi nilai perbedaan yang dihitung dengan nilai saat ini untuk mendapatkan rasio perubahan. Dalam contoh ini, penurunan yang cukup besar terjadi pada trafik pada pukul 11:39, dengan rasio perubahan lebih dari 40%.
CatatanUntuk menentukan rasio perubahan absolut, Anda dapat menggunakan fungsi ABS untuk menghitung nilai absolut dan menyatukan hasil perhitungan.
* | select (inflow- lag(inflow, 1, inflow)over() )*1.0/inflow as diff, from_unixtime(window_time) from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)