ApsaraDB for SelectDB adalah layanan gudang data real-time modern berbasis Apache Doris. Layanan ini menggunakan arsitektur cloud-native baru yang mendukung pemisahan komputasi-penyimpanan. Topik ini menjelaskan arsitektur dan prinsip dasar ApsaraDB for SelectDB.
Diagram Arsitektur
Komponen
Sistem aplikasi atau klien
Sistem aplikasi atau klien adalah layanan atau alat yang digunakan untuk mengakses ApsaraDB for SelectDB. ApsaraDB for SelectDB kompatibel dengan protokol koneksi MySQL dan sintaks SQL standar. Anda dapat menggunakan alat seperti MySQL CLI, driver Java Database Connectivity (JDBC), driver Open Database Connectivity (ODBC), dan alat visualisasi untuk mengakses instans ApsaraDB for SelectDB.
Untuk mengurangi dampak latensi jaringan dan ketidakstabilan, kami sarankan Anda menerapkan aplikasi atau klien di wilayah yang sama dengan instans ApsaraDB for SelectDB.
Instans
Sebuah instans ApsaraDB for SelectDB adalah unit dasar yang dapat dibeli dan digunakan untuk mengelola sumber daya di ApsaraDB for SelectDB. Setelah membeli instans, sumber daya dari instans tersebut dan kluster terkait menjadi milik akun Anda. ApsaraDB for SelectDB menggunakan arsitektur cloud-native yang mendukung pemisahan komputasi-penyimpanan. Arsitektur ini mencakup komponen seperti instans, kluster, dan penyimpanan. Instans digunakan untuk menerima permintaan dan berisi sekelompok frontend (FE). Kluster adalah sistem terdistribusi yang memproses permintaan dan berisi sekelompok backend (BE). Object Storage Service (OSS) digunakan sebagai sistem penyimpanan untuk penyimpanan data. FE dalam instans dihosting oleh ApsaraDB for SelectDB dan dapat diskalakan sesuai kebutuhan bisnis Anda. Anda tidak perlu mengelola FE. Dalam arsitektur pemisahan komputasi-penyimpanan ini, sumber daya dari beberapa instans ApsaraDB for SelectDB diisolasi secara fisik. Ini memungkinkan instans memenuhi persyaratan dalam skenario bisnis yang sepenuhnya independen atau berbeda dalam sensitivitas.
Berikut ini menjelaskan cara instans ApsaraDB for SelectDB memproses permintaan baca dan tulis:
Permintaan tulis: Untuk memulai permintaan tulis di ApsaraDB for SelectDB, Anda dapat menggunakan antarmuka tulis yang disediakan oleh ApsaraDB for SelectDB atau alat impor yang tersedia. Setelah permintaan diterima, instans meneruskan permintaan ke kluster yang ditentukan. Kluster tersebut kemudian memproses permintaan tulis untuk menulis data ke bucket OSS dan cache. Setelah data berhasil dipersistensikan di bucket OSS, pesan konfirmasi bahwa permintaan tulis telah berhasil diproses akan dikembalikan.
Permintaan kueri: Anda dapat mengeksekusi pernyataan SQL untuk memulai permintaan kueri di ApsaraDB for SelectDB. Setelah permintaan diterima, instans mengurai pernyataan SQL dalam permintaan tersebut, menggunakan pengoptimal cerdas untuk menghasilkan rencana eksekusi kueri yang efisien, lalu meneruskan permintaan ke kluster yang ditentukan. Kluster tersebut melakukan pemrosesan paralel masif (MPP) pada permintaan kueri, membaca data dari bucket OSS atau cache sesuai kebutuhan bisnis Anda, dan mengembalikan hasil melalui protokol MySQL setelah kueri selesai. Selama proses kueri, kluster memanfaatkan arsitektur eksekusi pipeline serta teknologi seperti pengindeksan, caching, dan vektorisasi untuk mempercepat kinerja kueri. Hal ini memberikan peningkatan signifikan dalam performa analisis data menggunakan ApsaraDB for SelectDB. Gambar berikut mengilustrasikan cara ApsaraDB for SelectDB memproses permintaan kueri.
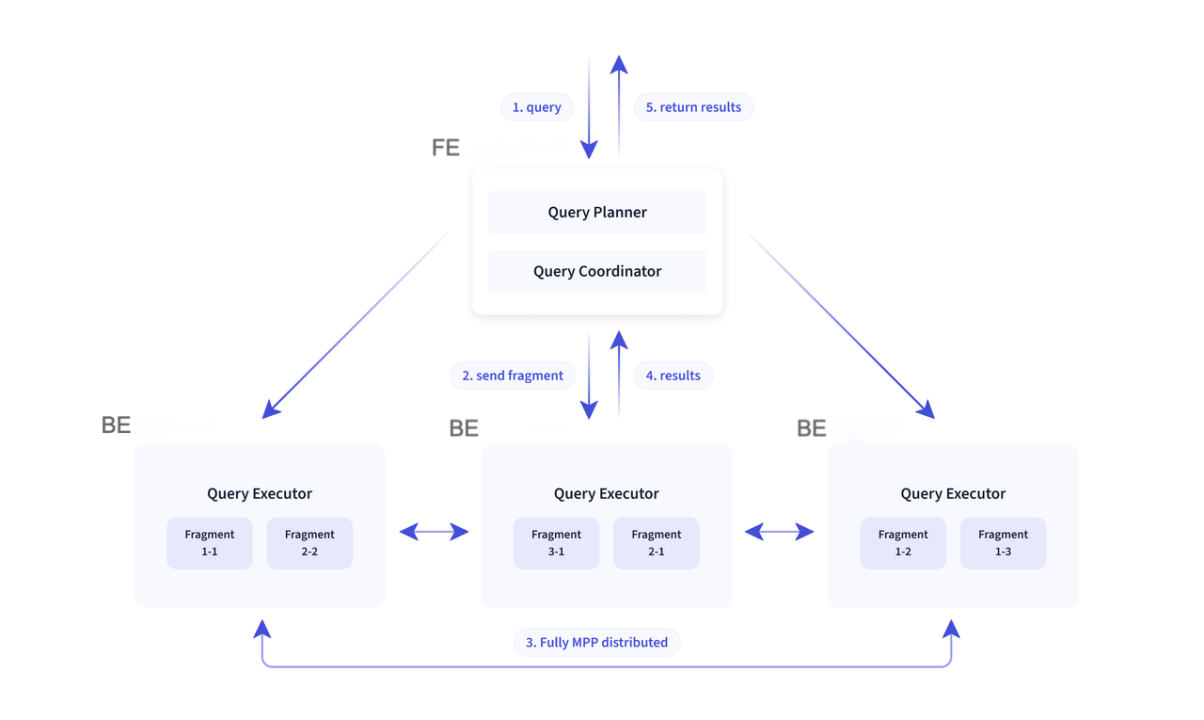
Kluster
Kluster di ApsaraDB for SelectDB adalah sistem terdistribusi yang berisi satu atau lebih backend (BE). Setiap BE dilengkapi dengan sumber daya komputasi dan cache. Dalam arsitektur pemisahan komputasi-penyimpanan, waktu akses ke OSS relatif lama sehingga caching diperkenalkan untuk mempercepat akses data. ApsaraDB for SelectDB mendukung mekanisme caching multi-level seperti cache berbasis memori dan disk. Kluster dapat diskalakan secara fleksibel. Selama penskalaan, cache dipra-ambil dan dimigrasi untuk memastikan analisis yang lancar.
ApsaraDB for SelectDB mendukung arsitektur multi-kluster. Sebuah instans dapat berisi beberapa kluster, mirip dengan antrian komputasi atau kelompok dalam arsitektur terdistribusi klasik. Beberapa kluster dalam instans yang sama memiliki fitur berikut:
Berbagi data: Beberapa kluster berbagi dan mengakses data OSS yang mendasarinya, menghilangkan kebutuhan untuk penyimpanan data yang berlebihan.
Isolasi komputasi: Sumber daya komputasi dan cache dari beberapa kluster sepenuhnya independen. Anda dapat menggunakan kluster ini untuk mengisolasi beban kerja yang berbeda. Data dicache berdasarkan karakteristik aksesnya.
Pembacaan dan penulisan data simultan: Operasi pembacaan dan penulisan dapat dilakukan secara paralel dalam arsitektur multi-kluster. Setelah data ditulis, data tersebut dapat segera diquery di semua kluster.
Berdasarkan fitur-fitur ini, arsitektur multi-kluster umumnya digunakan dalam skenario di mana Anda ingin mengisolasi pembacaan data dari penulisan data, mengisolasi data online dari data offline, atau mengisolasi lingkungan produksi dari lingkungan pengujian.
Penyimpanan
ApsaraDB for SelectDB menggunakan layanan OSS yang andal dan hemat biaya sebagai sistem penyimpanan untuk penyimpanan data persisten. Karena keandalan tinggi yang melekat pada OSS, ApsaraDB for SelectDB tidak perlu memelihara replika data dalam sistem gudang data terdistribusi. Dengan memanfaatkan keterjangkauan OSS, biaya penyimpanan per unit SelectDB berkurang lebih dari 90% dibandingkan solusi gudang data tradisional.
Saat menggunakan ApsaraDB for SelectDB, Anda tidak perlu memesan sumber daya penyimpanan. Anda dikenakan biaya berdasarkan model bayar sesuai penggunaan. Anda juga dapat menggunakan paket penyimpanan untuk lebih mengurangi biaya penyimpanan.
Untuk meningkatkan kinerja analisis, sistem penyimpanan dan komputasi ApsaraDB for SelectDB terintegrasi secara mendalam satu sama lain.
Organisasi data: Untuk meningkatkan efisiensi akses data, ApsaraDB for SelectDB mengorganisasikan data secara detail halus.
Pembagian data: Data dibagi berdasarkan waktu atau nilai hash, memanfaatkan sepenuhnya kekuatan pemrosesan kluster terdistribusi dan memfasilitasi pemangkasan data selama kueri.
Penyimpanan baris-kolom hibrid: Penyimpanan kolom default mendukung analisis efisien dari sejumlah besar data, sedangkan penyimpanan baris dapat digunakan untuk mendukung kueri titik berkinerja tinggi.
Indeks ekstensif: Berbagai indeks dan kondisi filter digunakan untuk menempatkan data secara tepat, meningkatkan kinerja kueri secara signifikan.
Model data: ApsaraDB for SelectDB menyediakan model data yang dioptimalkan untuk skenario analisis data tipikal.
Model unik: Cocok untuk skenario yang memerlukan kunci utama unik atau pembaruan efisien, seperti analisis pesanan e-commerce dan data atribut pengguna.
Model agregasi: Cocok untuk skenario di mana semua catatan data asli dipertahankan, seperti analisis log dan analisis tagihan.
Model duplikat: Cocok untuk skenario statistik agregasi yang menggunakan pra-agregasi untuk meningkatkan kinerja kueri, seperti analisis lalu lintas situs web dan laporan kustom.
Ekosistem eksternal
ApsaraDB for SelectDB dapat diintegrasikan dengan sumber data pihak ketiga dan alat visualisasi dalam ekosistem eksternal untuk meningkatkan kinerja analisis data.
Berbagai alat impor data: Gunakan alat ini untuk mengimpor data dari berbagai sumber data, seperti sumber data Alibaba Cloud dan sumber data yang dikelola sendiri, ke ApsaraDB for SelectDB. Untuk informasi lebih lanjut, lihat Alat impor data.
Alat integrasi data visual yang berlimpah: ApsaraDB for SelectDB dapat diintegrasikan dengan mulus dengan alat visualisasi yang kompatibel dengan MySQL untuk meningkatkan efisiensi pengembangan data dan analisis visual. Untuk informasi lebih lanjut, lihat Visualisasi data.
Kueri federasi: ApsaraDB for SelectDB dapat diintegrasikan dengan danau data dan database eksternal berdasarkan kemampuan kueri federasi. Untuk informasi lebih lanjut, lihat Danau gudang.